




一、基本介绍
DataCollator是huggingface提供的transformers库中的数据整理器,主要用来将数据集中的数据处理成batch的形式。
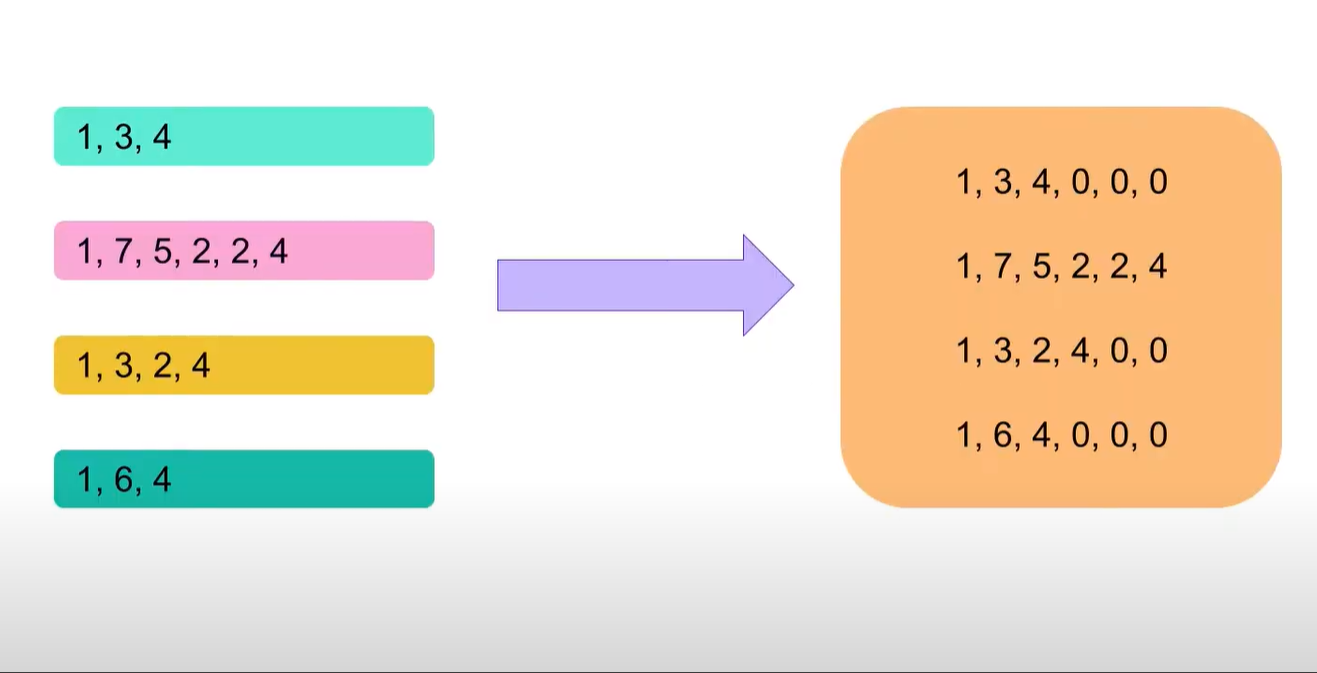
二、 transformers.default_data_collator
default_data_collator是transformers中最基础且通用的数据整理器,他是一个函数,它知识简单的将数据打包成batch,不会进行任何的padding和truncation。
features = [
{"input_ids": [101, 2345, 6789, 102], "label": 1},
{"input_ids": [101, 3456, 7890, 4321, 102], "label": 0}
]
像这样的数据输入到default_data_collator中就会报错,因为input_ids的长度不一致,而default_data_collator又不会进行padding,就会报错。
使用default_data_collator的情况是所有样本都已经被padding到相同长度,不需要进行额外处理(如masking)等,仅仅需要打包成batch。
导入包
from transformers import default_data_collator
参数
default_data_collator(features: list, return_tensors: str = "pt")
features:包含多个样本的列表,每一个样本是一个dictreturn_tensors:是返回数据的格式,pt代表返回pytorch的tensor张量。
三、 DefaultDataCollator
DefaultDataCollator是类形式的的数据整理器,它和上面default_data_collator的功能相同,但是是以类的形式实现的,它也不会进行padding处理,需要输入的数据长度是一样的。
由于不会进行默认padding,所以基本很少使用。
导入包
from transformer import DefaultDataCollator
参数
DefaultDataCollator(return_tensors='pt')
使用
features = [
{"input_ids": [101, 2345, 6789, 2345, 102], "label": 1},
{"input_ids": [101, 3456, 7890, 4321, 102], "label": 0}
]
from transformers import DefaultDataCollator
collator = DefaultDataCollator(return_tensors='pt') # 指定返回 PyTorch 张量
batch = collator(features)
print(batch)
输出
{
'input_ids': tensor([[101, 2345, 6789, 2345, 102],
[101, 3456, 7890, 4321, 102]]),
'labels': tensor([1, 0])
}
四、 DataCollatorWithPadding
这是一个动态padding的数据整理器类,它会使一个batch中所有样本的长度相同。
需要注意的是DataCollatorWithPadding只对input进行padding,而不对label进行padding
class transformers.DataCollatorWithPadding(
tokenizer: PreTrainedTokenizerBase,
padding: Union[bool, str, PaddingStrategy] = True,
max_length: Optional[int] = None,
pad_to_multiple_of: Optional[int] = None,
return_tensors: str = 'pt'
)
参数
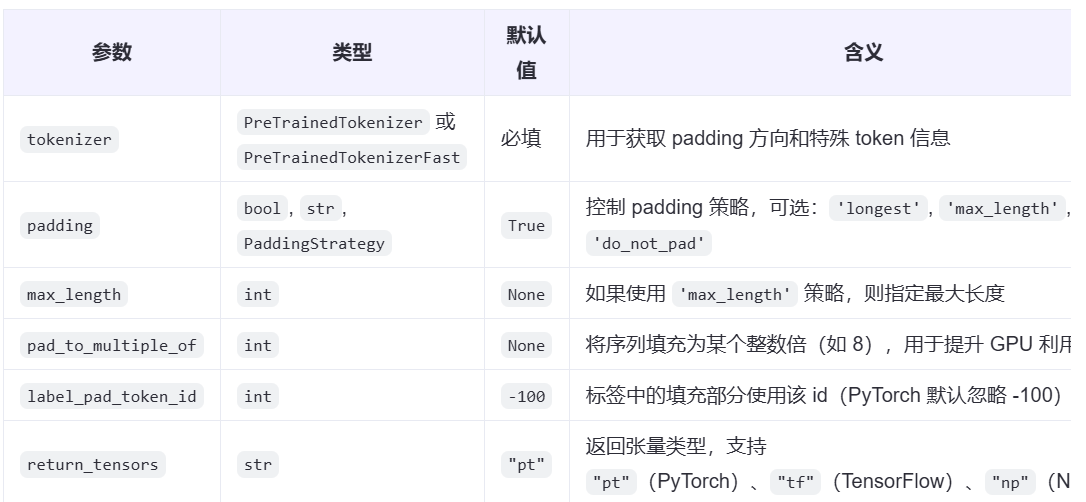
tokenizer:传入一个tokenizer。padding:有三种参数可以选择bool为True的话默认padding到batch中的最大长度,‘max_length’:填充到指定的 max_length,False不做padding。max_length:如果 padding=‘max_length’,则所有序列都会被填充或截断到该长度。
如果没有设置,则使用模型允许的最大输入长度。pad_to_multiple_of:将序列长度向上填充为某个整数的倍数,比如 8、64 等。return_tensors:“pt”:返回 PyTorch 张量、“tf”:返回 TensorFlow 张量、“np”:返回 NumPy 数组。
五、 DataCollatorForTokenClassification
适用于token级别的序列标注任务,如命名实体识别,继承了DataCollatorWithPadding的功能,同时能够对齐标签的长度。
参数
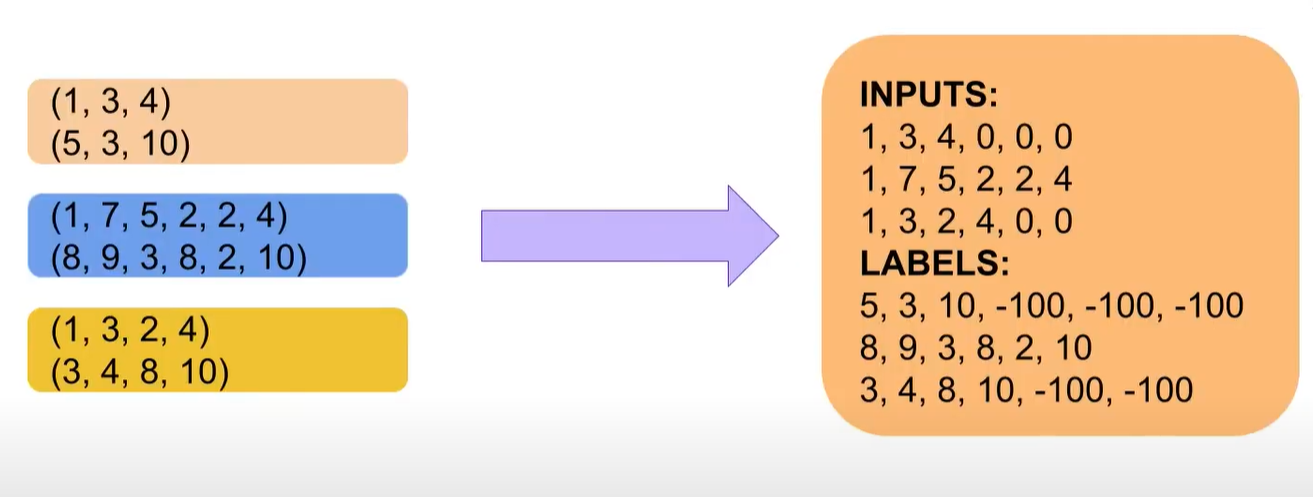
六、 DataCollatorForSeq2Seq
专门为Seq2Seq任务设置的数据整理器,适用于翻译、摘要生成等encoder-decoder等任务。
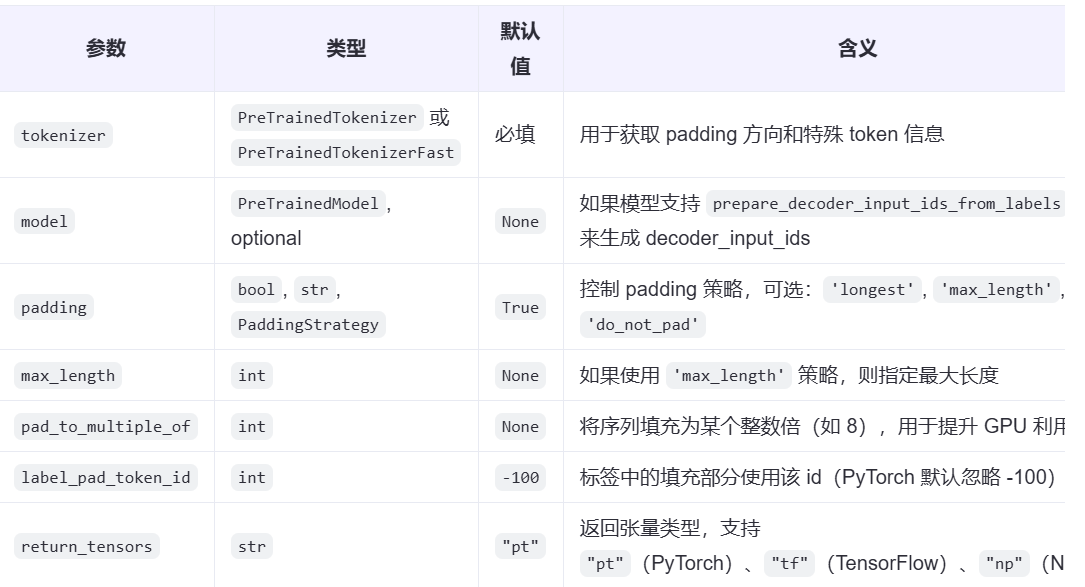
class transformers.DataCollatorForSeq2Seq(
tokenizer: PreTrainedTokenizerBase,
model: Optional[Any] = None,
padding: Union[bool, str, PaddingStrategy] = True,
max_length: Optional[int] = None,
pad_to_multiple_of: Optional[int] = None,
label_pad_token_id: int = -100,
return_tensors: str = 'pt'
)
参数
features = [
{
"input_ids": [101, 2345, 6789, 102],
"labels": [2, 3, 4, 5, 6]
},
{
"input_ids": [101, 3456, 7890, 4321, 102],
"labels": [3, 4, 5, 6, 7, 8]
}
]
from transformers import DataCollatorForSeq2Seq
collator = DataCollatorForSeq2Seq(
tokenizer=tokenizer,
model=model, # 可选,如果你用了像 BART 或 T5 这样的模型
padding="longest",
label_pad_token_id=-100,
return_tensors="pt"
)
batch = collator(features)
print(batch.keys())
# 输出:dict_keys(['input_ids', 'attention_mask', 'labels', 'decoder_input_ids'])
输出结果:
{
'input_ids': tensor([[101, 2345, 6789, 102, 0],
[101, 3456, 7890, 4321, 102]]),
'attention_mask': tensor([[1, 1, 1, 1, 0],
[1, 1, 1, 1, 1]]),
'labels': tensor([[-100, 2, 3, 4, 5], # 第一个样本只有4个真实 label
[3, 4, 5, 6, 7, 8]]), # 第二个样本有6个 label
'decoder_input_ids': tensor([[ 2, 3, 4, 5, 0], # decoder_input_ids 自动构造
[ 3, 4, 5, 6, 7]])
}
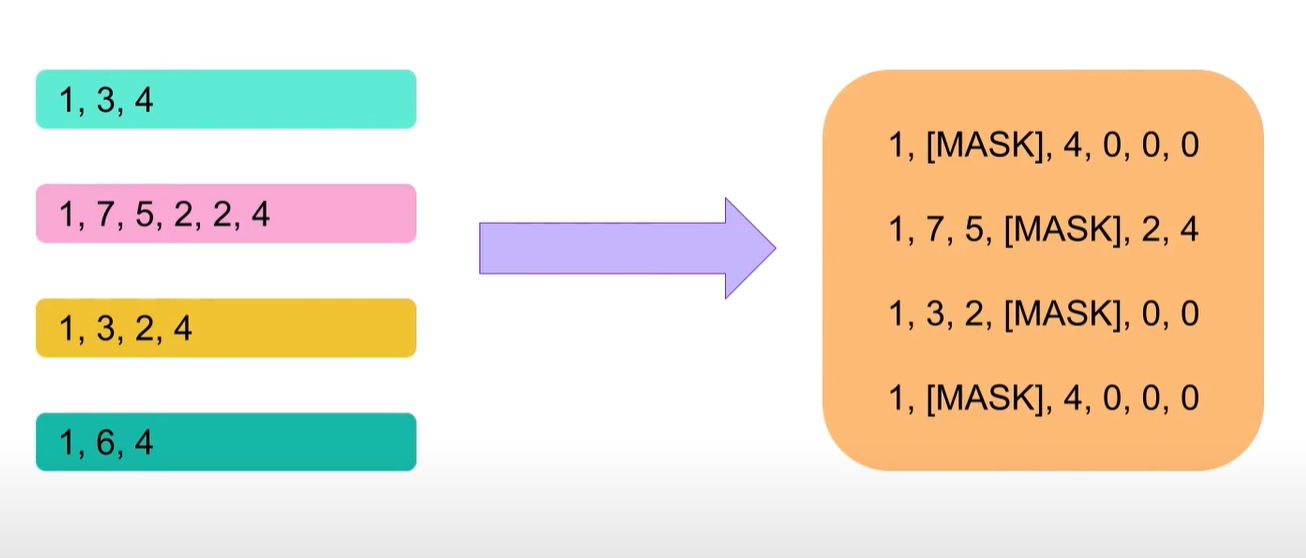
七、 DataCollatorForLanguageModeling
这个数据整理器适用于类似Bert的掩码语言模型。
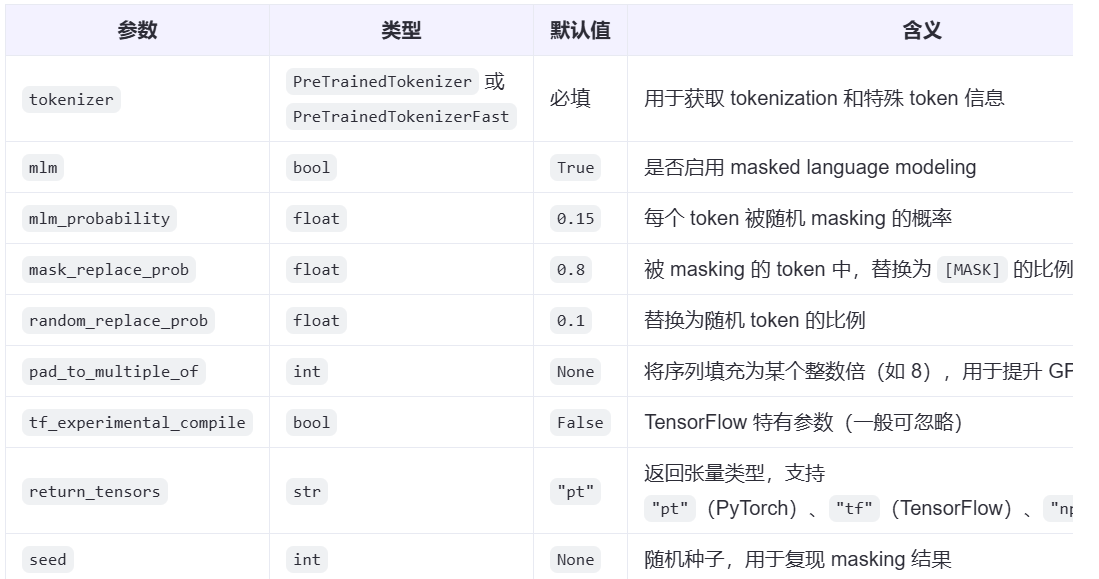
class transformers.DataCollatorForLanguageModeling(
tokenizer: PreTrainedTokenizerBase,
mlm: bool = True,
mlm_probability: float = 0.15,
mask_replace_prob: float = 0.8,
random_replace_prob: float = 0.1,
pad_to_multiple_of: Optional[int] = None,
tf_experimental_compile: bool = False,
return_tensors: str = 'pt',
seed: Optional[int] = None
)
八、 总结
transformers中的datacollator主要用于对数据进行padding、truncation并打包成一个batch。上面是常用的一些datacollator还有一些不太常用的datacollator可以参考huggingface官方文档。

















 1101
1101

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









