







Downloader Middleware
-> 下载中间件
当Engine把从Scheduler获取到Request发送给Downloader的过程中、以及Downloader把Response发送会Engine的过程中、Request和Response都会经过Downloader Middlewares的处理。
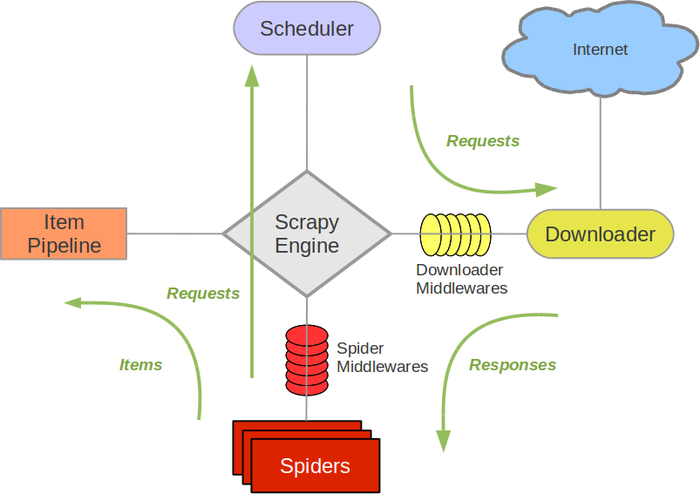
总结:Downloader Middleware在整个框架中起到以下作用
- Engine从Scheduler获取到Request发送给Downloader,在Request在发送到Downloader之前、Downloader Middleware可以对Request进行修改
- Downloader执行Request后生成的Response、在Response被Engine发送到Spider之前、Downloader可以对Response进行修改。
功能示例:
- 修改User-Agen
- 处理重定向
- 设置代理
- 失败重连
- 设置cookie等。
使用
scrapy已经提供了许多Downloader Middleware、他们被DOWNLOADER_MIDDLEWARES_BASE所定义
DOWNLOADER_MIDDLEWARES = {
"scrapy.downloadermiddlewares.offsite.OffsiteMiddleware": 50,
"scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware": 100,
"scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware": 300,
"scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware": 350,
"scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware": 400,
"scrapy.downloadermiddlewares.useragent.UserAgentMiddleware": 500,
"scrapy.downloadermiddlewares.retry.RetryMiddleware": 550,
"scrapy.downloadermiddlewares.ajaxcrawl.AjaxCrawlMiddleware": 560,
"scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware": 580,
"scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware": 590,
"scrapy.downloadermiddlewares.redirect.RedirectMiddleware": 600,
"scrapy.downloadermiddlewares.cookies.CookiesMiddleware": 700,
"scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware": 750,
"scrapy.downloadermiddlewares.stats.DownloaderStats": 850,
"scrapy.downloadermiddlewares.httpcache.HttpCacheMiddleware": 900,
}
这是一个字典的样式、键值代表了Scrapy内置的Downloader Middleware的名称、键值代表的是调用的优先级、数字越小越靠近Engine、数字越大越靠近Downloader
默认情况下Scrapy已经默认开启了DOWNLOADER_MIDDLEWARES、例如RetryMiddleware带有自动重试功能、RedirectMiddleware带有自动处理重定向的功能。
原理(如何实现Downloader Middleware?)
其实每一个Downloader Middleware都可以通过定义process_request、process_response方法来处理Request和Response。
注意:如果想自定义Downloader Middleware中间件不应该修改DOWNLOADER_MIDDLEWARES变量而是通过
DOWNLOADER_MIDDLEWARES添加自定义的中间件即可。若想要禁用DOWNLOADER_MIDDLEWARES中的某个中间件、在DOWNLOADER_MIDDLEWARES变量中设置None即可。
自定义Downloader Middleware
主要实现以下三个方法
- process_request(request,spider)
- process_respone(request,response,spider)
- process_excepition(request,excepition,spider)
只需要实现至少一种方法即可。
实战项目
目标网址:
url = www.httpbin.org
# 新建项目
scrapy startproject scrapydownloadermiddlewaredome
cd scrapydownloadermiddlewaredome
scrapy genspider httpbin www.httpbin.org
# spider.py
import scrapy
class HttpbinSpider(scrapy.Spider):
name = "httpbin"
allowed_domains = ["www.httpbin.org"]
# 修改url为:https://www.httpbin.org/get
start_urls = ["https://www.httpbin.org/get"]
def parse(self, response):
print(response.text)
运行:
scrapy crawl httpbin
输出:
{
"args": {},
"headers": {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "en",
"Host": "www.httpbin.org",
"User-Agent": "Scrapy/2.12.0 (+https://scrapy.org)",
"X-Amzn-Trace-Id": "Root=1-67fcfb5a-1369717c219da2247a5dde09"
},
"origin": "154.19.47.141",
"url": "https://www.httpbin.org/get"
}
注意其中User-Agent字段为:“Scrapy/2.12.0 (+ https://scrapy.org )”、是Scrapy内置的UserAgentMiddleware设置的。
在DOWNLOADER_MIDDLEWARES的默认配置中
"scrapy.downloadermiddlewares.useragent.UserAgentMiddleware": 500,
由于默认使用UserAgentMiddleware中间件、且User-Agent默认为:“Scrapy/2.12.0 (+ https://scrapy.org )”、在实际项目中很容易被检查到所以要修改User-Agent、有两种方式:
- 修改setting里面的USER_AGENT变量
- 通过Downloader Middleware的process_request方法来修改
一般简单的需求推荐第一种方法

如果想要更灵活的设置、比如随机User-Agent就需要借助Downloader Middleware了
在middlewares.py中添加RandomUserAgentMiddleware类,代码如下:
#middlewares.py
class RandomUserAgentMiddleware():
def __init__(self):
self.user_agents = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/135.0.0.0 Safari/537.36",
"Mozilla/5.0(test)"
]
def process_request(self, request, spider):
request.headers["User-Agent"] = random.choice(self.user_agents)
写完代码还没完、要配置setting.py文件、把DOWNLOADER_MIDDLEWARES取消注释、添加我们自定义的中间件

重新运行、结果如下:
{
"args": {},
"headers": {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "en",
"Host": "www.httpbin.org",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/135.0.0.0 Safari/537.36",
"X-Amzn-Trace-Id": "Root=1-67fd00c7-19e13edb062080500891e03f"
},
"origin": "154.19.47.141",
"url": "https://www.httpbin.org/get"
}
当然也可以修改代理什么的、对Request进行自定义处理、原理如上。
注意:自定义的Downloader Middleware的中间件默认值为None、返回其它值会造成递归报错!

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









