







Item Pipeline简介
https://natsume-1316988601.cos.ap-chengdu.myqcloud.co 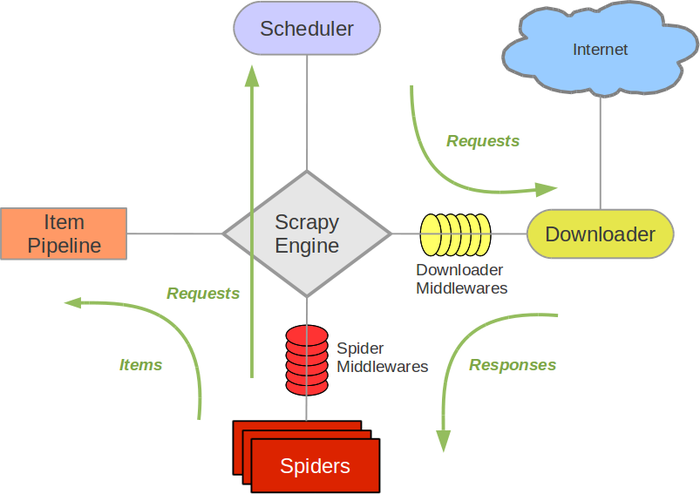
Item Pipeline即项目管道、它的调用发生在Spider产生Item对象之后。当Spider处理完Response、Item就会被Engine传递给Item Pipeline。被定义的Item Pipeline就会被按顺序依次被调用,完成一连串的处理过程、比如数据清洗、数据存储。
Item Pipeline主要有以下功能:
- 清洗HTML数据
- 验证爬取的数据,检查爬取字段
- 查重、去重
- 将爬取到的结果存储起来。
核心方法
自定义Item Pipeline方法必须实现的方法如下:
- process_item(item,spider)
被定义的Item Pipeline会默认调用这个方法对Item进行处理、必须数据处理以及写入数据库等操作。
process_item必须返回Item类型或者抛出一个DropItem异常
其他实用方法(可以不定义):
- open_spider(spider)
当Spider开启的时候被自动调用,我们可以做一些初始化的方法,如开启数据库连接等。其中Spider参数就是被开启的Spider对象。 - close_spider(spider)
该方法在Spider关闭的时候调用、这里可以做一下收尾工作如:关闭数据库连接等。其中Spider参数就是被关闭的Spider对象。 - from_crawler(cls,crawler)
该方法是一个类方法、用@classmethod标识。它接收一个crawler参数。通过crawler对象我们可以拿到所有Scrapy的所有组件如:全局配置信息。然后可以在这个方法里创建一个Pipeline实例。参数cls就是Class,最后返回一个Class实例
实战
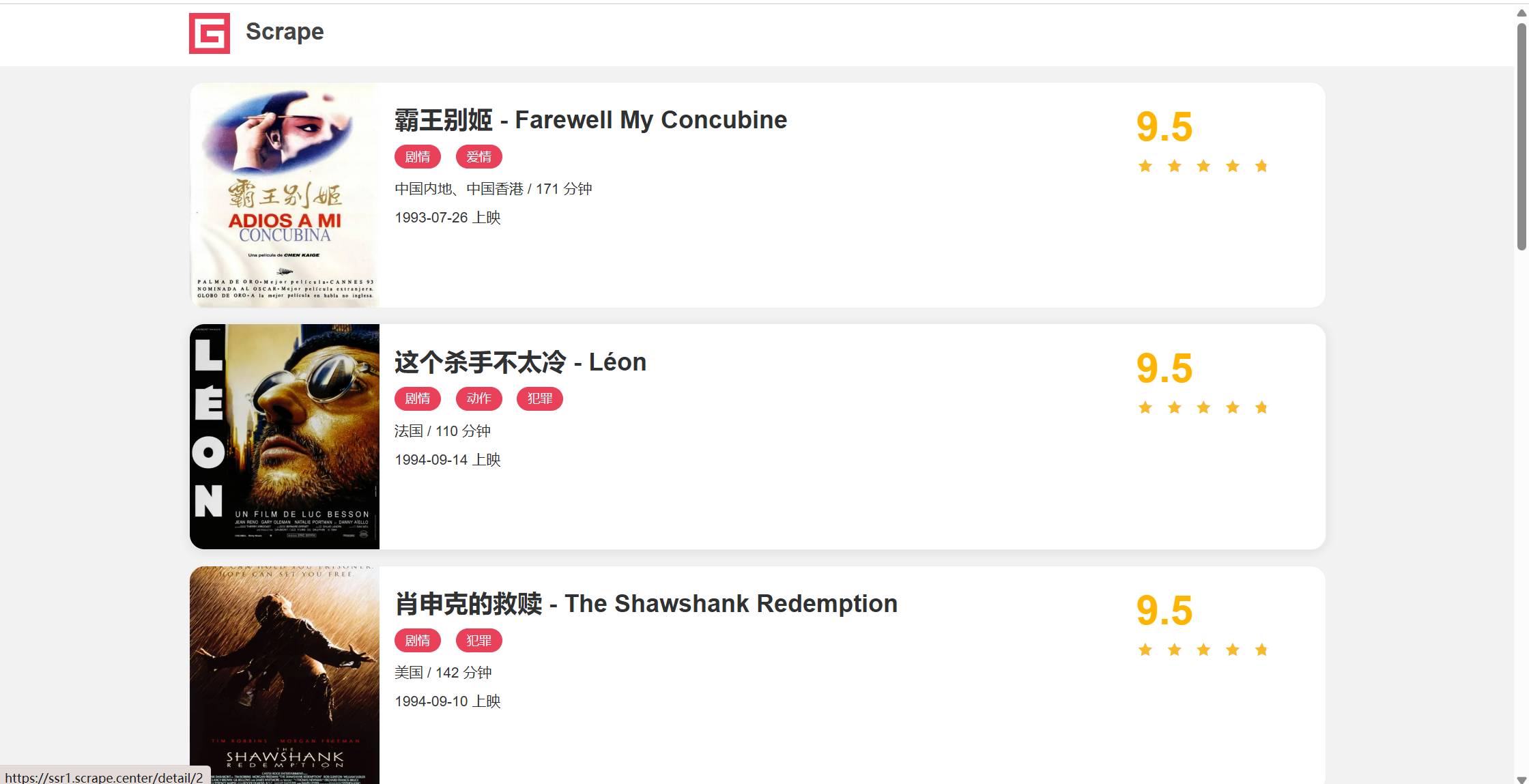
url:ssr1.scrape.center
先新建一个scrapy项目
scrapy startproject scrapyitempipelinedemo
cd scrapyitempipelinedemo
# 创建一个Spider爬虫类
scrapy genspider scrape ssr1.scrape.center
先爬取列表页(示例站点总共10页、第11页没数据)
先爬取10页
from typing import Iterable
import scrapy
from scrapy import Request
class ScrapeSpider(scrapy.Spider):
name = "scrape"
allowed_domains = ["ssr1.scrape.center"]
start_url = "https://ssr1.scrape.center"
max_page = 10
def start_requests(self) -> Iterable[Request]:
for i in range(1, self.max_page + 1):
url = f'{self.start_url}/page/{i}'
yield Request(url, callback=self.parse_index)
def parse_index(self, response):
print(response)
在这里我们先声明了最大爬取限制max_page,然后实现了start_requests方法、让其自定义构建了10个初始请求并将回调函数设置为parse_index、并打印Response对象。
# 部分输出
2025-04-18 16:15:27 [scrapy.core.engine] DEBUG: https://ssr1.scrape.center/page/3> (referer: None)
<200 https://ssr1.scrape.center/page/3>
2025-04-18 16:15:28 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://ssr1.scrape.center/page/4> (referer: None)
<200 https://ssr1.scrape.center/page/4>
2025-04-18 16:15:28 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://ssr1.scrape.center/page/5> (referer: None)
<200 https://ssr1.scrape.center/page/5>
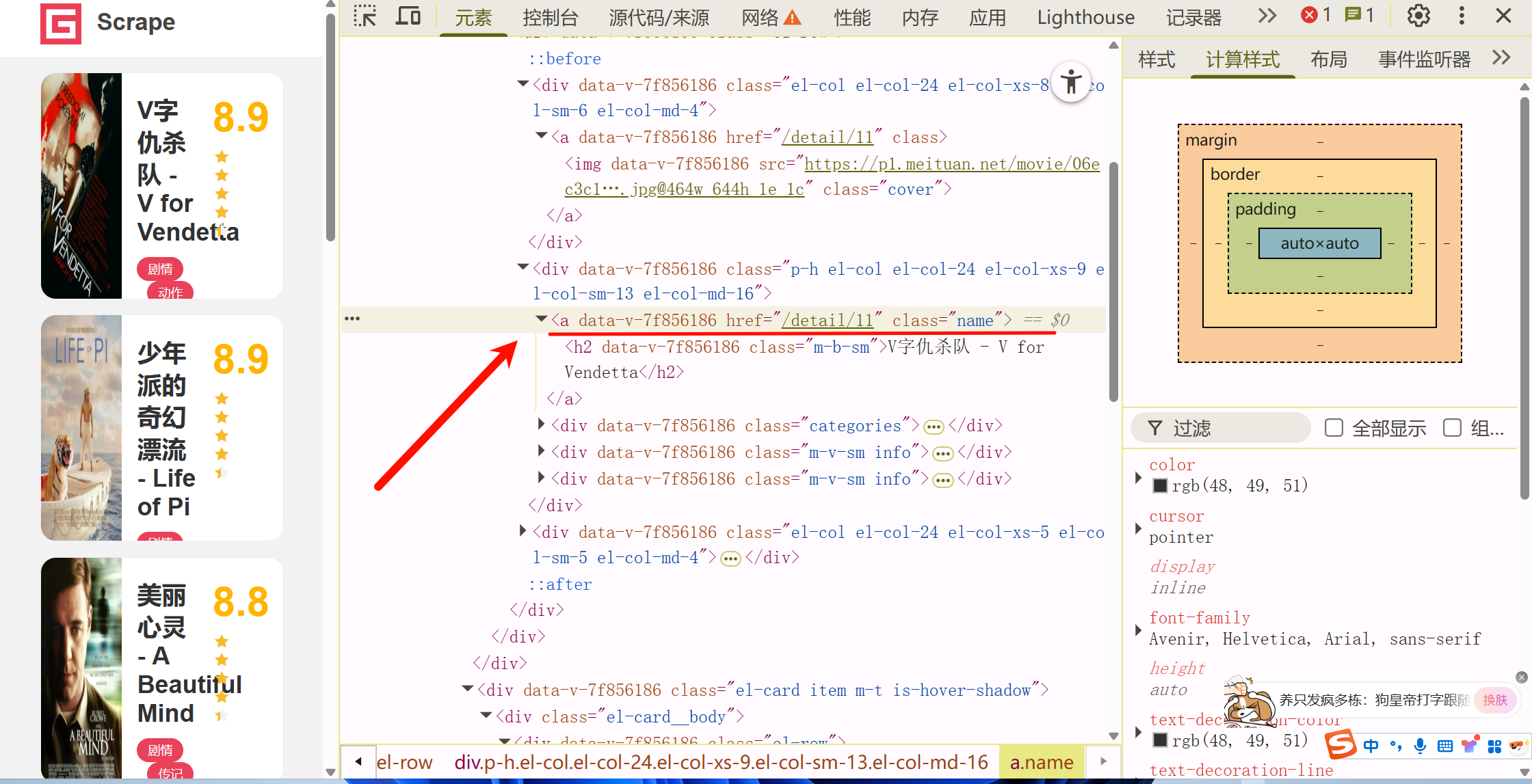
接着我们再pase函数里对response的内容进行解析、提取每部电影的详情页连接
如图所示对应的css为:.item .name
parse_index方法改写如下:
def parse_index(self, response):
for item in response.css('.item'):
href = item.css('.name::attr(href)').extract_first()
url = response.urljoin(href)
yield Request(url, callback=self.parse_detail)
def parse_detail(self, response):
print(response)
部分输出
2025-04-18 16:38:59 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://ssr1.scrape.center/detail/25> (referer: https://ssr1.scrape.center/page/3)
<200 https://ssr1.scrape.center/detail/25>
2025-04-18 16:38:59 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://ssr1.scrape.center/detail/22> (referer: https://ssr1.scrape.center/page/3)
2025-04-18 16:38:59 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://ssr1.scrape.center/detail/96> (referer: https://ssr1.scrape.center/page/10)
我们对parse_index进行改写、先遍历每个怕个卡片、获取卡片里的详情页url 通过拼接得到完整的url 并回调到parse_detail方法并打印出来。
现在parse_detail返回的Response返回的就是每一个卡片的详情页了。
提取电影信息
提取电影的名字、类别、评分、简介、导演、演员等信息
# spiders/spider.py
from scrapy import Request, Spider
from scrapyitempipelinedemo.items import MovieItem
class ScrapeSpider(Spider):
name = 'scrape'
allowed_domains = ['ssr1.scrape.center']
base_url = 'https://ssr1.scrape.center'
max_page = 10
def start_requests(self):
for i in range(1, self.max_page + 1):
url = f'{self.base_url}/page/{i}'
yield Request(url, callback=self.parse_index)
def parse_index(self, response):
for item in response.css('.item'):
href = item.css('.name::attr(href)').extract_first()
url = response.urljoin(href)
yield Request(url, callback=self.parse_detail)
def parse_detail(self, response):
item = MovieItem()
item['name'] = response.xpath('//div[contains(@class, "item")]//h2/text()').extract_first()
item['categories'] = response.xpath('//button[contains(@class, "category")]/span/text()').extract()
item['score'] = response.css('.score::text').re_first('[\d\.]+')
item['drama'] = response.css('.drama p::text').extract_first().strip()
item['directors'] = []
directors = response.xpath('//div[contains(@class, "directors")]//div[contains(@class, "director")]')
for director in directors:
director_image = director.xpath('.//img[@class="image"]/@src').extract_first()
director_name = director.xpath('.//p[contains(@class, "name")]/text()').extract_first()
item['directors'].append({
'name': director_name,
'image': director_image
})
item['actors'] = []
actors = response.css('.actors .actor')
for actor in actors:
actor_image = actor.css('.actor .image::attr(src)').extract_first()
actor_name = actor.css('.actor .name::text').extract_first()
item['actors'].append({
'name': actor_name,
'image': actor_image
})
yield item
# items.py
import scrapy
class MovieItem(scrapy.Item):
name = scrapy.Field()
categories = scrapy.Field()
score = scrapy.Field()
drama = scrapy.Field()
directors = scrapy.Field()
actors = scrapy.Field()
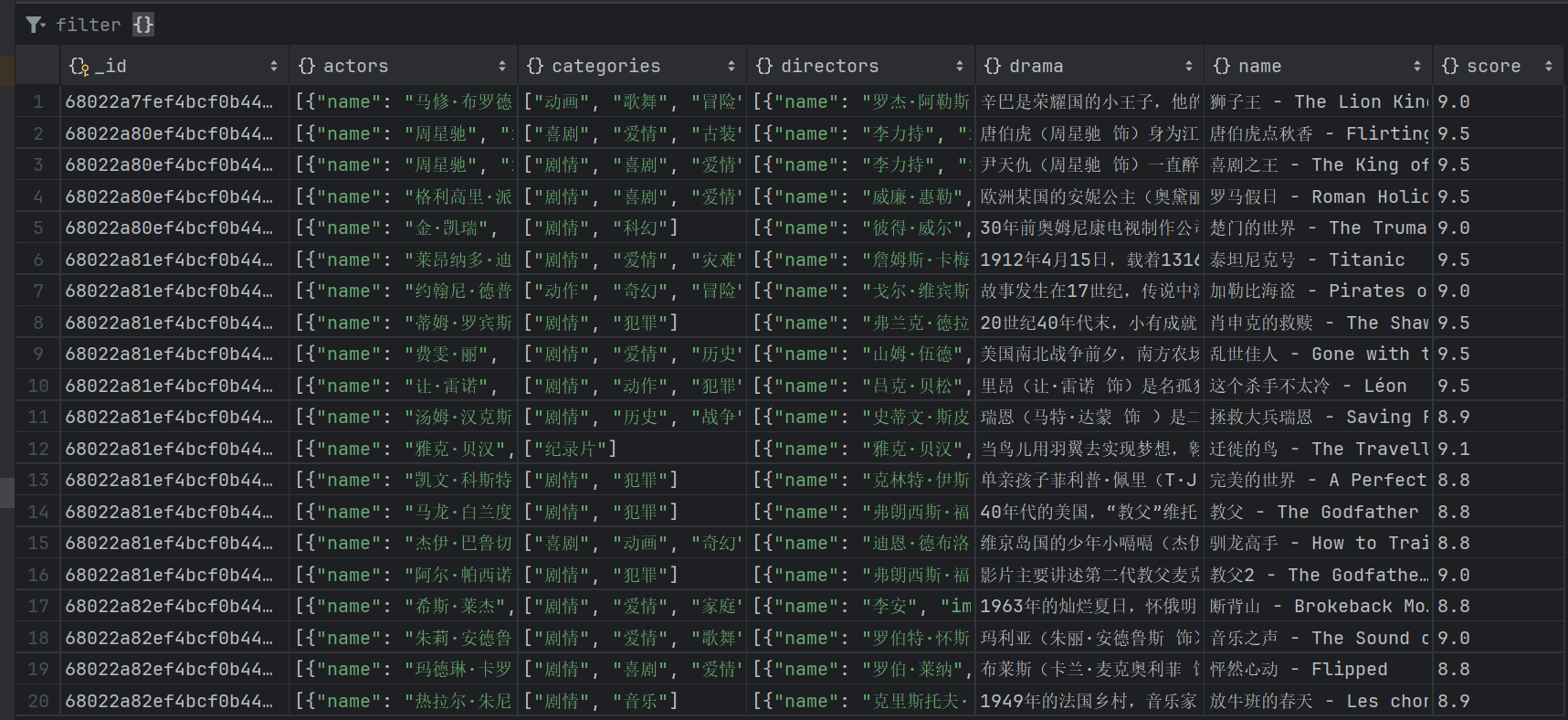
运行结果如图所示:
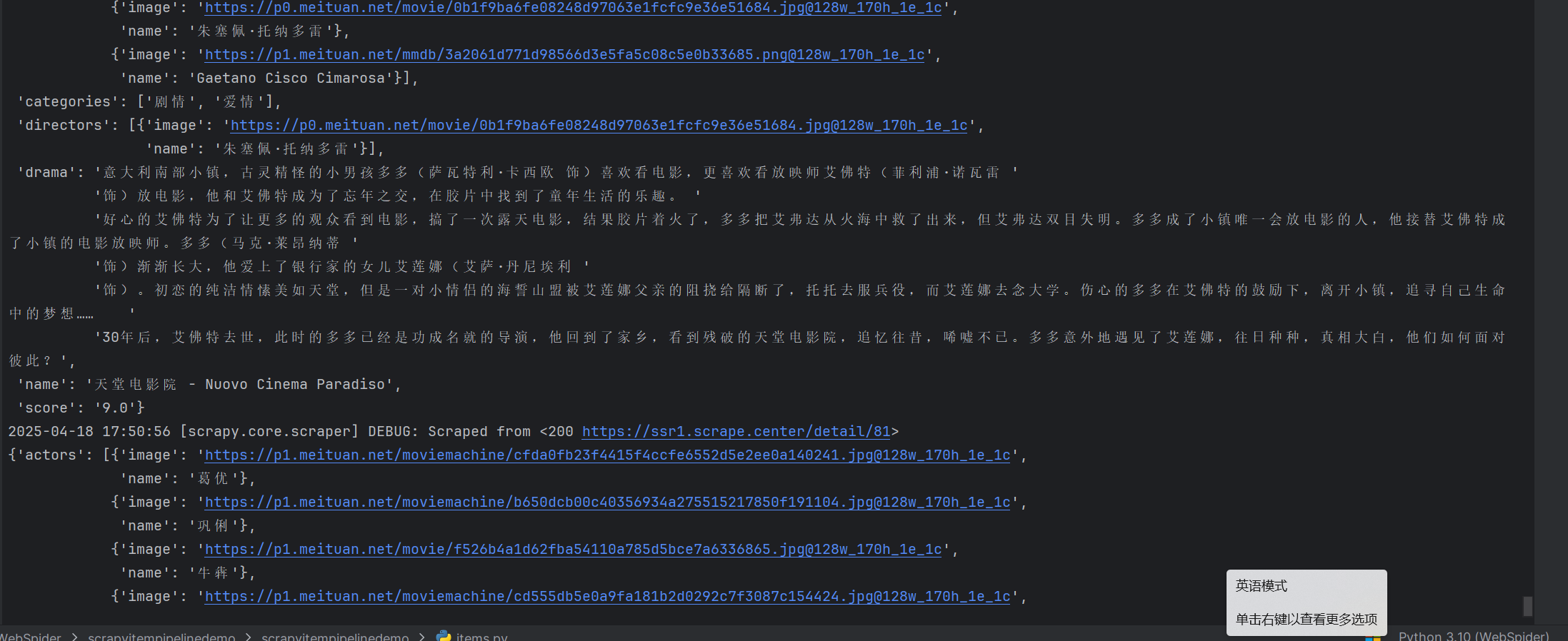
如此我们就获取到我们要的信息了。
mongoDB持续化存储
# pipelines.py
import pymongo
class MongoDBPipeline(object):
@classmethod
def from_crawler(cls, crawler):
cls.connection_string = crawler.settings.get('MONGODB_CONNECTION_STRING')
cls.database = crawler.settings.get('MONGODB_DATABASE')
cls.collection = crawler.settings.get('MONGODB_COLLECTION')
return cls()
def open_spider(self, spider):
self.client = pymongo.MongoClient(self.connection_string)
self.db = self.client[self.database]
def process_item(self, item, spider):
self.db[self.collection].update_one({
'name': item['name']
}, {
'$set': dict(item)
}, True)
return item
def close_spider(self, spider):
self.client.close()
# setting.py
ITEM_PIPELINES = { "scrapyitempipelinedemo.pipelines.MongoDBPipeline": 300,
}
MONGODB_CONNECTION_STRING = 'mongodb://localhost:27017'
MONGODB_DATABASE = 'spider'
MONGODB_COLLECTION = 'movies'
注意:自定义的管道别忘了在配置文件里定义!!!
这样就把数据存到mongoDB了


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









