







Scrapy框架知识手册 - 从零到一
一、初识Scrapy
1、Scrapy简介
Scrapy是一个使用Python开发的(基于Twisted框架)开源网络爬虫框架,目前由Scrapinghub Ltd维护。
Scrapy简单易用、灵活易拓展,任何人都可以根据需求方便的修改。它的开发社区活跃,并且是跨平台的,在Linux、 MaxOS以及Windows平台都可以使用。
Scrapy用途广泛,可以用于数据挖掘、监测和自动化。
2、网络爬虫原理
网络爬虫是指:在互联网上自动爬取网站内容信息的程序,也被称作网络蜘蛛或网络机器人。
大型的爬虫程序被广泛应用于搜索引擎、数据挖掘等领域,个人用户或企业也可以利用爬虫收集对自身有价值的数据。
3、网络爬虫的基本流程
任何爬虫程序都遵循这三个基本流程:请求数据、解析数据和保存数据。
请求数据
请求的数据除了普通HTML页面之外,还有JSON数据、字符串数据、图片、视频、音频等等。
解析数据
当整个数据被请求后得到,对数据内容进行分析,并筛选出需要的内容。
保存数据
将数据以某种格式保存起来,如:写入文件中(csv、json)等,或保存到数据库(MySQL、MongoDB)等等。
二、Scrapy安装与创建
1、安装
直接pip安装
pip install scrapy
查看版本
# cmd或shell下
C:\Users\Administrator>python
>>>import scrapy
>>>scrapy.__version__
# 或者 scrapy.version_info
# 显示安装的版本号
(2.1.0)
2、查看命令
直接运行scrapy,查看提示指令
C:\Users\Administrator>scrapy
Scrapy 2.1.0 - no active project
Usage:
scrapy <command> [options] [args]
Available commands:
# 运行快速基准测试。(检测电脑性能)
bench Run quick benchmark test
# 通过Scrapy下载器获取一个URL。(将源代码下载下来,并显示出来)
fetch Fetch a URL using the Scrapy downloader
# 使用预定义模板生成一个爬虫程序。(创建一个新的spider文件)
genspider Generate new spider using pre-defined templates
# 运行一个独立的爬虫程序(不创建一个项目)。(直接scrapy runspider <爬虫文件名>,与crawl启动爬虫不同)
runspider Run a self-contained spider (without creating a project)
# 获得配置信息
settings Get settings values
# 交互式抓取控制台。(进入scrapy的交互模式)
shell Interactive scraping console
# 创建爬虫项目
startproject Create new project
# 打印Scrapy框架版本
version Print Scrapy version
# 将URL在浏览器中打开,就像在Scrapy中看见的那样
view Open URL in browser, as seen by Scrapy
[ more ] More commands available when run from project directory
# 使用scrapy <指令> -h 可以看见更多关于指令的信息
Use "scrapy <command> -h" to see more info about a command
3、主要命令
- 创建项目:
scrapy startproject <项目名> - 创建爬虫:
scrapy genspider <爬虫名> <域名> - 运行爬虫:
scrapy crawl <爬虫名>
三、Scrapy简单实现
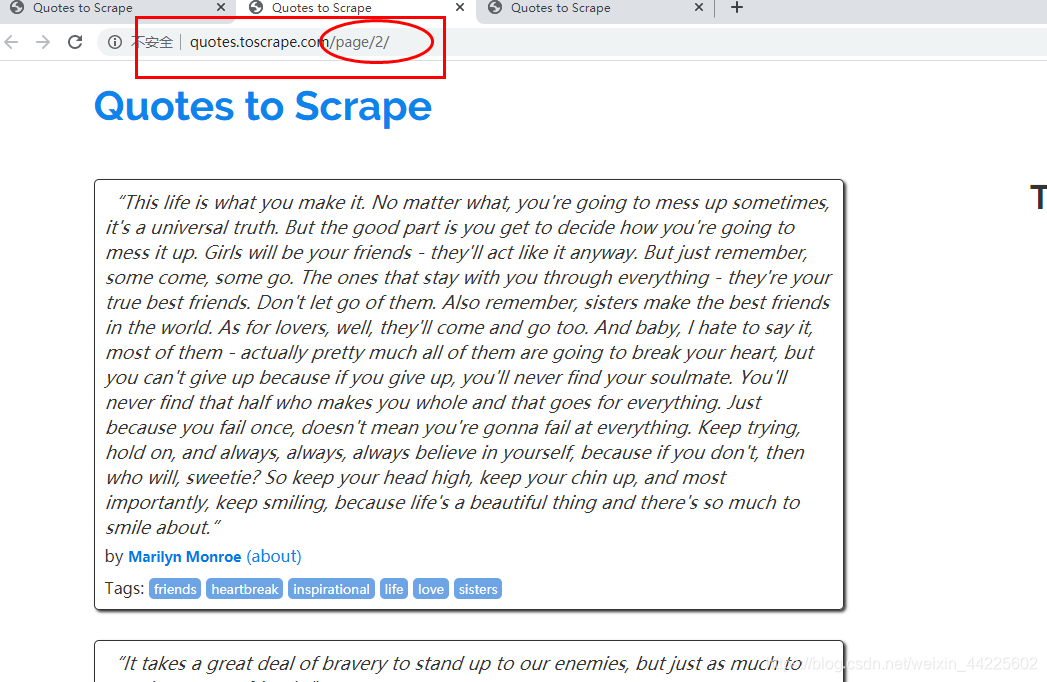
英文名言警句网站 http://quotes.toscrape.com
1、项目创建
>scrapy startproject quotes
New Scrapy project 'quotes', using template directory 'd:\pycharm\webcrawler\venv\lib\site-packages\scrapy\templates\project', created in:
D:\XXXXXX\quotes
You can start your first spider with:
cd quotes
scrapy genspider example example.com
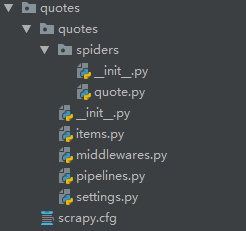
2、创建爬虫
切换到项目中,即按照提示,切换到quotes文件夹中去
>scrapy genspider quote toscrape.com
Created spider 'quote' using template 'basic' in module:
quotes.spiders.quote
结果展示:
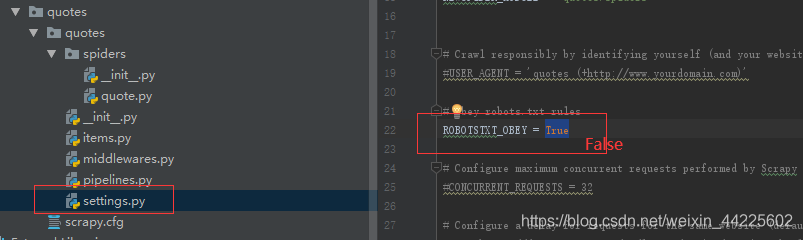
3、更改robot协议
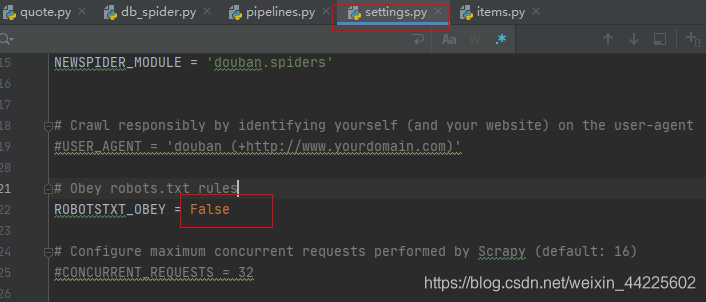
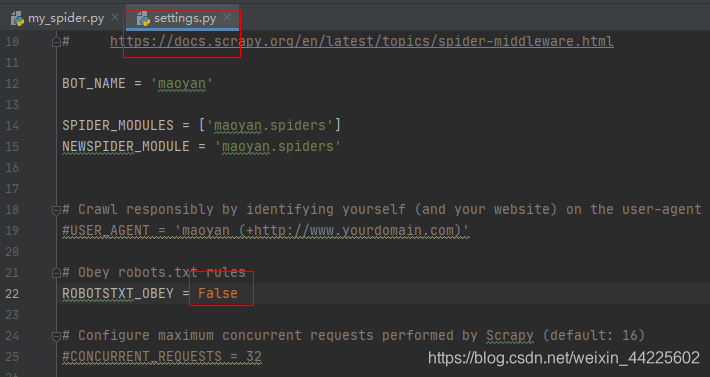
将setting中的,是否遵循robot选项,True改变为False
4、分析页面
使用Chrome浏览器的开发者工具,分析页面
每一个内容都存在于标签<div class=“quote”>…</div>中
内容:
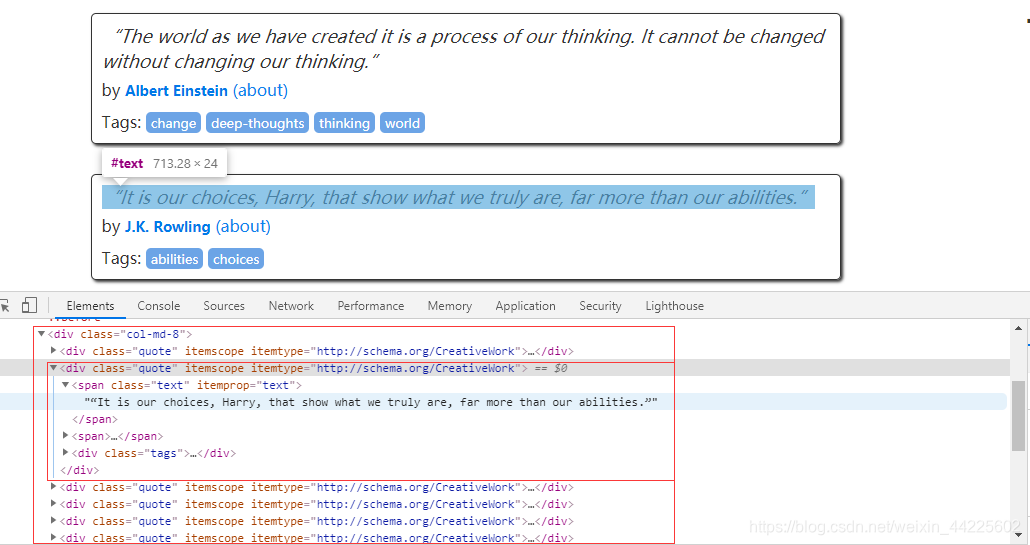
查看翻页:
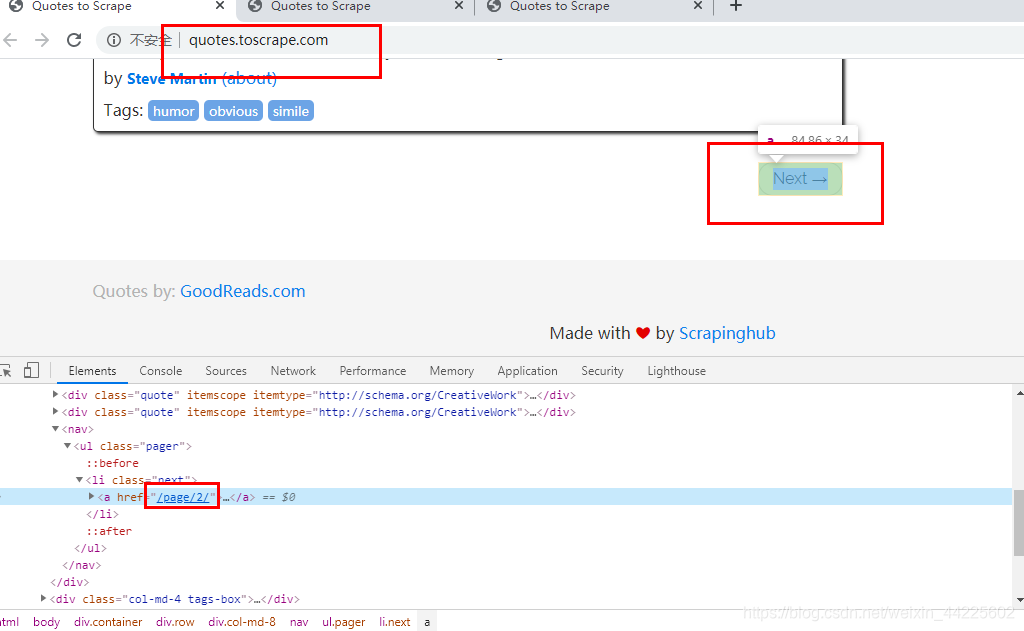
完整的URL:
5、编写spider
查看quotes.py文件
更改start_urls为’http://quotes.toscrape.com/’
Spider 是用户编写用于从单个网站(或者一些网站)爬取数据的类。
为了创建一个Spider,必须继承spider.Spider类,并且定义以下三个属性:
- name。在genspider时创建的,用于区别Spider。该名字必须是唯一的,不可以为不同Spider设定相同的名字。
- allowed_domains。是爬虫能抓取的域名,爬虫只能在这个域名下抓去网页。可以不设置。
- start_urls。可迭代类型,列表也可以是列表推导式。包含了Spider在启动时进行爬取的url列表。因此,第一个页面必须设置进来,而后续的URL则从初始的URL获取到的数据中提取。
- parse()。回调函数。是Spider的一个方法,被调用时,该方法中的response,是每个start_urls完成下载后生成的Response对象将会作为唯一的参数传递给该函数。也可以通过其他函数来接收。
页面解析主要完成下面两个任务:- 直接提取页面中的数据(re、XPath、CSS选择器),生成item。
- 生成需要进一步处理的URL的Request对象,即提取页面中的链接,并产生对链接页面的下载请求。
页面解析函数通常为一个生成器函数,每一项从页面中提取的数据以及每一个对链接页面的下载请求都由yield语句交给Scrapy引擎。
6、解析页面
分析页面获取:名言,作者,标签,这三个属性。
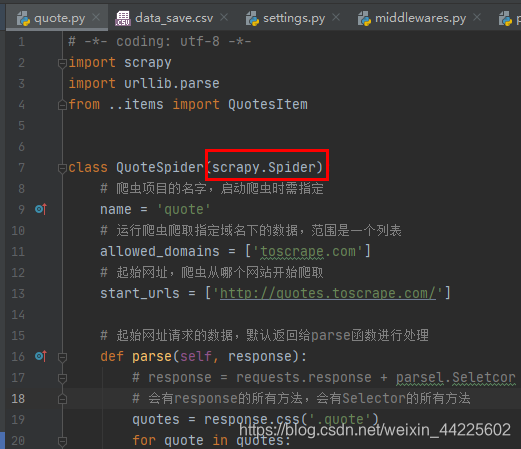
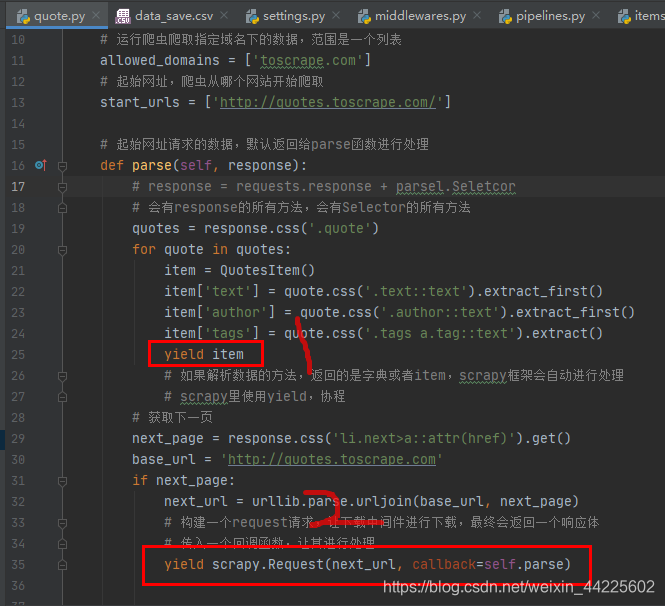
quote.py
# -*- coding: utf-8 -*-
import scrapy
import urllib.parse
from ..items import QuotesItem
class QuoteSpider(scrapy.Spider):
# 爬虫项目的名字,启动爬虫时需指定
name = 'quote'
# 运行爬虫爬取指定域名下的数据,范围是一个列表
allowed_domains = ['toscrape.com']
# 起始网址,爬虫从哪个网站开始爬取
start_urls = ['http://quotes.toscrape.com/']
# 起始网址请求的数据,默认返回给parse函数进行处理
def parse(self, response):
# response = requests.response + parsel.Seletcor
# 会有response的所有方法,会有Selector的所有方法
quotes = response.css('.quote')
for quote in quotes:
item = QuotesItem()
item['text'] = quote.css('.text::text').extract_first()
item['author'] = quote.css('.author::text').extract_first()
item['tags'] = quote.css('.tags a.tag::text').extract()
yield item
# 如果解析数据的方法,返回的是字典或者item,scrapy框架会自动进行处理
# scrapy里使用yield,协程
# 获取下一页
next_page = response.css('li.next>a::attr(href)').get()
base_url = 'http://quotes.toscrape.com'
if next_page:
next_url = urllib.parse.urljoin(base_url, next_page)
# 构建一个request请求,让下载中间件进行下载,最终会返回一个响应体
# 传入一个回调函数,让其进行处理
yield scrapy.Request(next_url, callback=self.parse)
items.py
# -*- coding: utf-8 -*-
import scrapy
class QuotesItem(scrapy.Item):
# define the fields for your item here like:
text = scrapy.Field()
author = scrapy.Field()
tags = scrapy.Field()
piplelines.py 数据保存
class QuotesPipeline(object):
def process_item(self, item, spider):
with open('data_save.csv', 'a', encoding='utf-8')as f:
f.write(item['text']+','+item['author']+','+','.join(item['tags']))
f.write('\n')
return item
取消settings文件中的注释

注意:
- response.css()可以直接提取响应内容
- start_urls可以直接写多个网址,以列表格式分隔开。
- extract_first()是提取内容,提取的是第一个内容,不是列表,而是字符串。extract()是提取多个内容,以列表形式保存的多个字符串内容。不使用这两个方法,则得到的是对象。
7、运行爬虫
在quote项目名目录下运行爬虫
直接即可:
scrapy crawl quote
不取消注释settings.py中关于ITEM_PIPELINES字典数据时,也可以通过指令,保存为csv文件(该保存仅供测试,或者简单保存):
scrapy crawl quote -o quotes.csv
-o支持多种格式保存,添加上后缀即可。
爬虫的运行过程:
Scrapy为Spider的start_urls属性中的每一个URL创建了scrapy.Request对象,并将parse方法作为回调函数(callback)赋值给了Request。
Request对象经过调度,执行生成scrapy.http.Response对象并送回给Spider的parse()方法处理。
四、Scrapy框架结构
1、Scrapy结构
项目结构:(一步步展开)

quotes/: 总项目quotes/quotes/: 该项目的python模块。内部添加及更改代码。quotes/scrapy.cfg: 项目的配置文件
quotes/quotes/spiders/: 放置spider代码的目录.quotes/quotes/items.py: 项目中的item文件.quotes/quotes/middlewares.py: 爬虫中间件、下载中间件(处理请求体与响应体)quotes/quotes/pipelines.py: 项目中的pipelines文件.quotes/quotes/settings.py: 项目的设置文件.
quotes/quotes/spiders/quote.py: quote爬虫程序
2、Scrapy原理(数据流动)
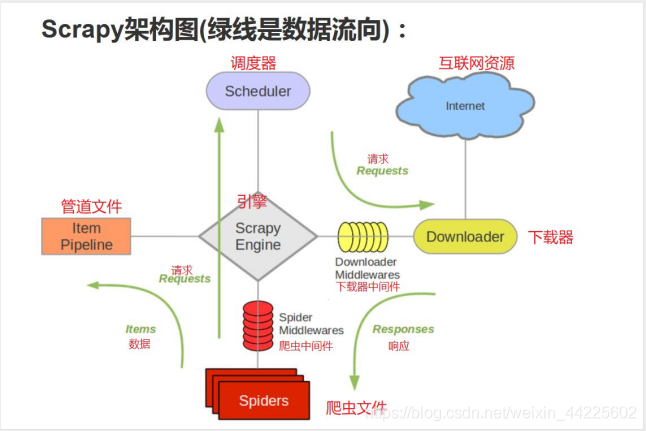
| 序号 | 组件 | 作用 |
|---|---|---|
| 1 | Scrapy Engine(引擎) | 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。 |
| 2 | Spider(爬虫) | 负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器)。 |
| 3 | Spider Middlewares(Spider中间件) | 可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests) |
| 4 | Scheduler(调度器) | 负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。 |
| 5 | Downloader Middlewares(下载中间件) | 可以当作是一个可以自定义扩展下载功能的组件。 |
| 6 | Downloader(下载器) | 负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理。 |
| 7 | Item Pipeline(管道) | 负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方。 |
3、Scrapy各个组件的介绍
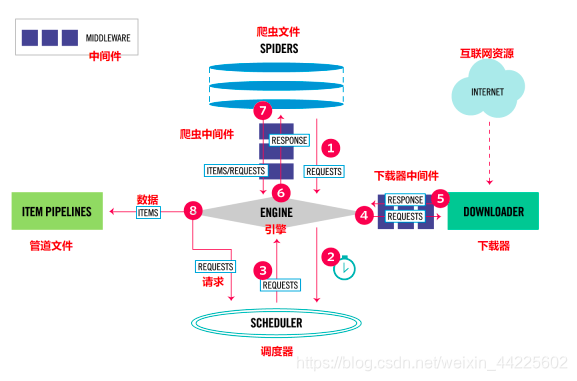
- Engine。引擎,处理整个系统的数据流处理、触发事务,是整个框架的核心。
- Items。项目数据,它定义了爬取结果的数据结构,爬取的数据会被赋值成该Item对象。
- Scheduler。调度器,接受引擎发过来的请求并将其加入队列中,在引擎再次请求的时候将请求提供给引擎。
- Downloader。下载器,下载网页内容,并将网页内容返回给蜘蛛。
- Spiders。 蜘蛛,其内定义了爬取的逻辑和网页的解析规则,它主要负责解析响应并生成器结果和新的请求。
- Item Pipeline。项目管道,负责处理由蜘蛛从网页中抽取的项目,它的主要任务是清洗、验证和存储数据。
- Downloader Middlewares。下载器中间件,位于引擎和下载器之间的钩子框架,主要处理引擎与下载器之间的请求及响应。
- Spider Middlewares。 蜘蛛中间件,位于引擎和蜘蛛之间的钩子框架,主要处理蜘蛛输入的响应和输出的结果及新的请求。
五、Scrapy的基本使用
1、spiders文件之spider.Spider(SPIDERS-爬虫文件)
Spider 类定义了如何爬取某个(或某些)网站。包括了爬取的动作(例如:是否跟进链接)以及如何从网页的内容中提取结构化数据(爬取item)。 换句话说,Spider就是定义爬取的动作及分析某个网页(或者是有些网页)的地方。
对spider来说,爬取的循环类似下文:
-
以初始的URL初始化Request,并设置回调函数。 当该request下载完毕并返回时,将生成response,并作为参数传给该回调函数。
spider中初始的request是通过调用 start_requests()来获取的。 start_requests() 读取 start_urls 中的URL, 并以 parse 为回调函数生成 Request。
-
在回调函数内分析返回的(网页)内容,返回 Item 对象或者 Request 或者一个包括二者的可迭代容器。见下1、2。 返回的Request对象之后会经过Scrapy处理,下载相应的内容,并调用设置的callback函数(函数可相同)。
-
在回调函数内,可以使用 选择器(Selectors) (可以使用BeautifulSoup, lxml 或者想用的任何解析器) 来分析网页内容,并根据分析的数据生成item。
-
最后,由spider返回的item将被存到数据库(由某些 Item Pipeline处理)或使用 Feed exports存入到文件中。
虽然该循环对任何类型的spider都(多少)适用,但Scrapy仍然为了不同的需求提供了多种默认spider。 之后将讨论这些spider。
1.1、Spider
scrapy.spider.Spider 是最简单的spider。每个其他的spider必须继承自该类(包括Scrapy自带的其他spider以及自己编写的spider)。 其仅仅请求给定的 start_urls / start_requests ,并根据返回的结果(resulting responses)调用 spider 的 parse 方法。
1.1.1、name
定义 spider 名字的字符串(string)。spider 的名字定义了 Scrapy 如何定位(并初始化) spider ,所以其必须是唯一的。 不过您可以生成多个相同的 spider 实例(instance),这没有任何限制。 name 是 spider 最重要的属性,而且是必须的。
如果该 spider 爬取单个网站(single domain),一个常见的做法是以该网站(domain)(加或不加后缀 )来命名 spider 。 例如,如果 spider 爬取 mywebsite.com ,该spider通常会被命名为 mywebsite 。
1.1.2、allowed_domains
可选。包含了spider允许爬取的域名(domain)列表(list)。 当 OffsiteMiddleware 启用时, 域名不在列表中的URL不会被跟进。
1.1.3、start_urls
URL 列表。当没有制定特定的 URL 时,spider 将从该列表中开始进行爬取。 因此,第一个被获取到的页面的 URL 将是该列表之一。 后续的 URL 将会从获取到的数据中提取。
1.1.4、start_requests()
该方法必须返回一个可迭代对象(iterable)。该对象包含了spider用于爬取的第一个 Request。
当 spider 启动爬取并且未制定 URL 时,该方法被调用。 当指定了URL时,make_requests_from_url() 将被调用来创建 Request 对象。 该方法仅仅会被 Scrapy 调用一次,因此您可以将其实现为生成器。
该方法的默认实现是使用 start_urls 的url生成 Request。
如果您想要修改最初爬取某个网站的Request对象,您可以重写(override)该方法。 例如,如果您需要在启动时以 POST 登录某个网站,你可以这么写:
def start_requests(self):
return [scrapy.FormRequest("http://www.example.com/login",
formdata={
'user': 'john', 'pass': 'secret'},
callback=self.logged_in)]
def logged_in(self, response):
## here you would extract links to follow and return Requests for
## each of them, with another callback
pass
1.1.5、parse
当response没有指定回调函数时,该方法是Scrapy处理下载的response的默认方法。
parse 负责处理response并返回处理的数据以及(/或)跟进的URL。 Spider 对其他的Request的回调函数也有相同的要求。
该方法及其他的Request回调函数必须返回一个包含 Request 及(或) Item 的可迭代的对象。
参数: response– 用于分析的response
1.1.6、closed(reason)
当spider关闭时,该函数被调用。
1.2、启动方式
1.2.1、start_urls
start_urls 是一个列表,同上。
1.2.2、start_requests
使用start_requests() 重写start_urls,要使用Request()方法自己发送请求:
def start_requests(self):
"""重写 start_urls 规则"""
yield scrapy.Request(url='http://quotes.toscrape.com/page/1/', callback=self.parse)
1.2.3、scrapy.Request
scrapy.Request 是一个请求对象,创建时必须制定回调函数。
1.2.4、数据保存
注意:这种保存方式,仅供测试。
可以使用 -o 将数据保存为常见的格式(根据后缀名保存)
支持的格式有下面几种:
- json
- jsonlines
- jl
- csv
- xml
- marshal
- pickle
使用方式:
scrapy crawl quotes -o datas.json
1.2.5、URL拼接
使用urllib包中的parse库中的urljoin方法
import urllib.parse
urllib.parse.urljoin('http://quotes.toscrape.com/', '/page/2/')
Out[6]: 'http://quotes.toscrape.com/page/2/'
urllib.parse.urljoin('http://quotes.toscrape.com/page/2/', '/page/3/')
Out[7]: 'http://quotes.toscrape.com/page/3/'
2、Scrapy框架案例
1、豆瓣250
网站链接:豆瓣电影 Top 250
1.1、创建项目
>scrapy startproject douban
You can start your first spider with:
cd douban
scrapy genspider example example.com
>cd douban
>scrapy genspider db_spider douban.com
修改起始URL:
改为网站链接
settings.py文件中,修改robot协议:
1.2、分析网页
(1) 数据:
ol标签下的所有li标签
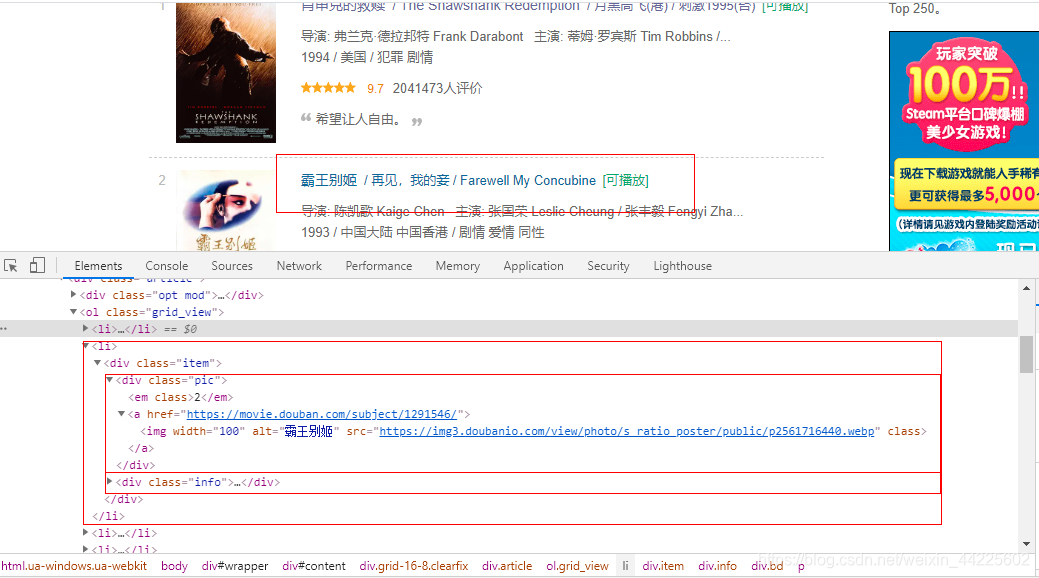
获取:pic–图片 title–标题 director–导演 star–评分 quote–格言
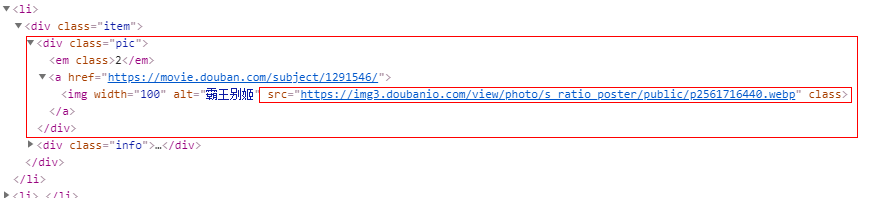
图片:
标题:
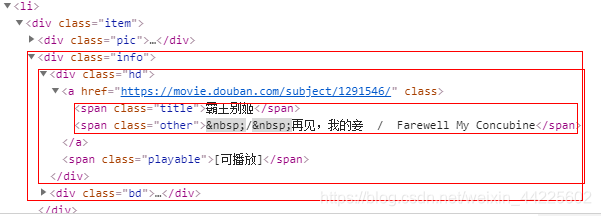
导演:
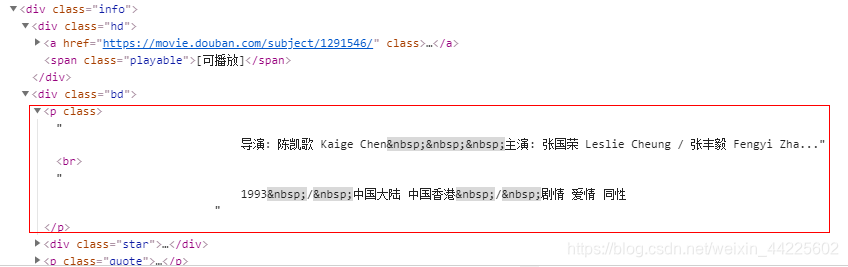
评分:
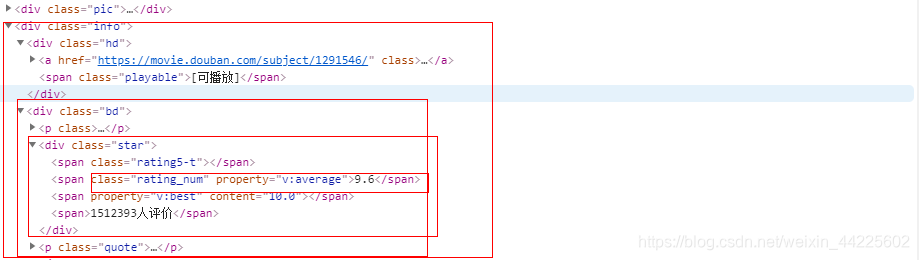
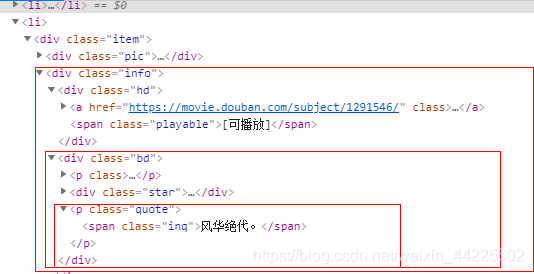
格言:
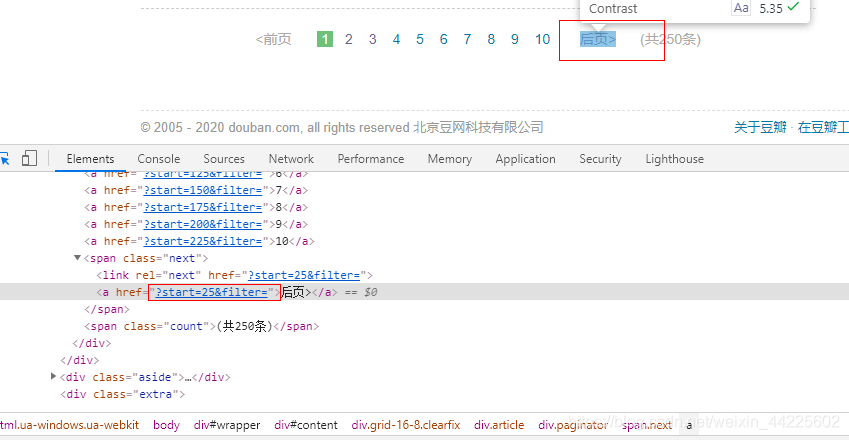
(2) 翻页:
1.3、构建Scrapy
(1) items.py
import scrapy
class DoubanItem(scrapy.Item):
# define the fields for your item here like:
pic = scrapy.Field()
title = scrapy.Field()
director = scrapy.Field()
star = scrapy.Field()
quote = scrapy.Field()
(2) db_spider.py
# -*- coding: utf-8 -*-
import scrapy
import urllib.parse
from ..items import DoubanItem
class DbSpiderSpider(scrapy.Spider):
name = 'db_spider'
allowed_domains = ['douban.com']
start_urls = ['https://movie.douban.com/top250']
def parse(self, response):
lis = response.css('ol.grid_view li')
for li in lis:
item = DoubanItem()
item['pic'] = li.css('div.pic img::attr(src)').extract_first()
item['title'] = li.css('div.info span.title::text').extract()
item['director'] = li.css('div.info div.bd>p::text').extract()
item['star'] = li.css('div.star span.rating_num::text').extract_first()
item['quote'] = li.css('p.quote span.inq::text').extract_first()
yield item
next_page = response.css('span.next a::attr(href)').extract_first()
next_url = urllib.parse.urljoin(response.url, next_page)
if next_page:
yield scrapy.Request(next_url, callback=self.parse)
(3) pipelines.py
class DoubanPipeline(object):
def process_item(self, item, spider):
direcctor_c = (','.join(item['director'])).strip().replace('\n', '').replace(' ', '').replace(',,' ,'')
with open('douban250.csv', 'a', encoding='utf8') as f:
f.write(item['pic']+','+','.join(item['title'])+','+direcctor_c + ',' +
item['star']+','+item['quote'])
f.write('\n')
return item
(4) settings.py
修改请求头:

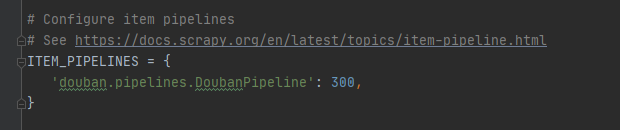
取消注释ITEM_PIPELINES:
1.4、运行Scrapy
scrapy crawl db_spider
结果:

2、猫眼100
网站链接:猫眼Top 100 榜
1.1、创建项目
>scrapy startproject maoyan
You can start your first spider with:
cd maoyan
scrapy genspider example example.com
>cd maoyan
>scrapy genspider my_spider maoyan.com
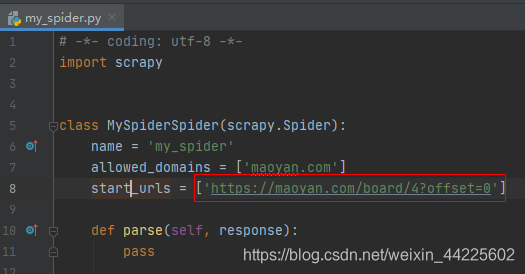
修改起始URL:
改为网站链接
settings.py文件中,修改robot协议:
1.2、分析网页
(1) 数据:
dl标签下的所有dd标签
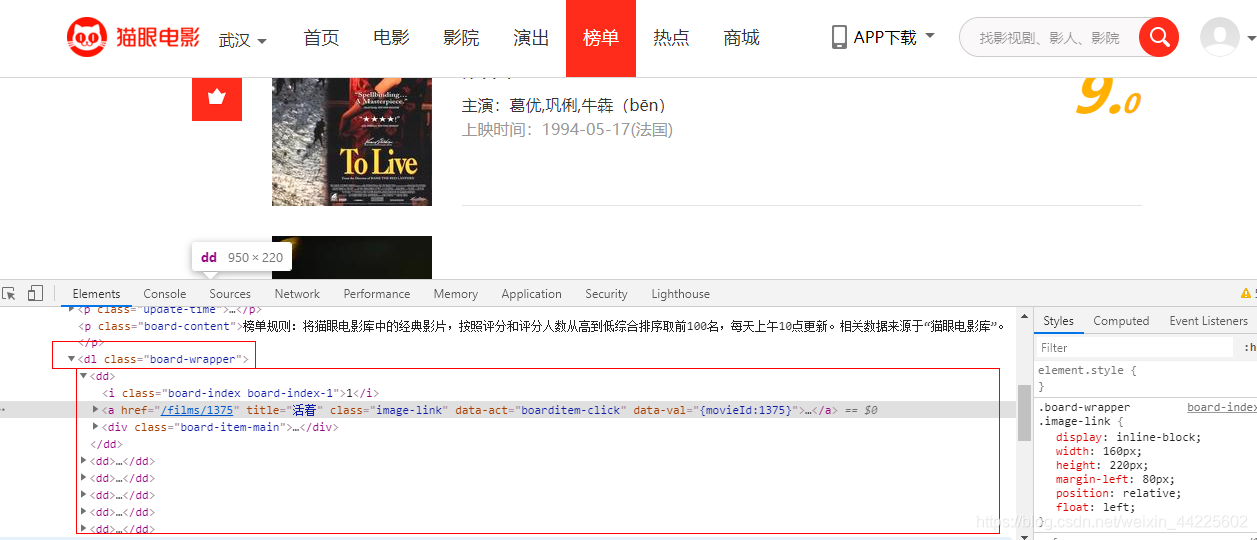
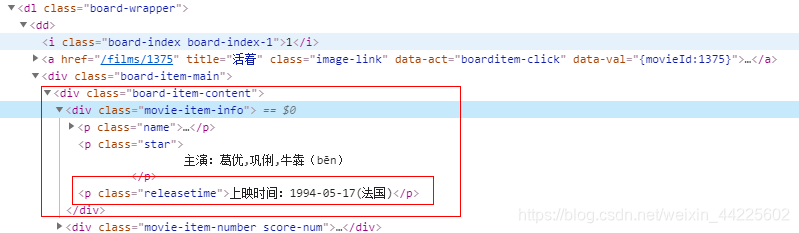
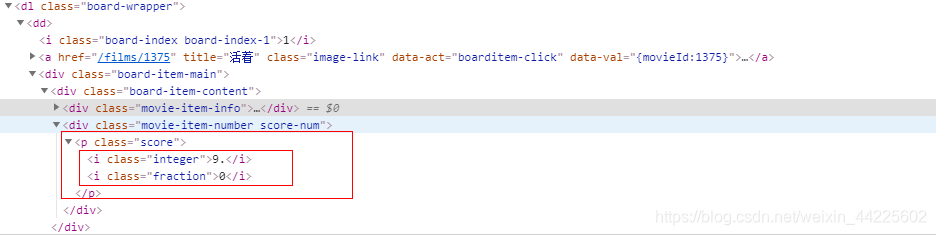
获取:title - 标题、img - 图像、star - 明星、time - 放映时间、score - 评分
title - 标题 和 img - 图像

star - 明星
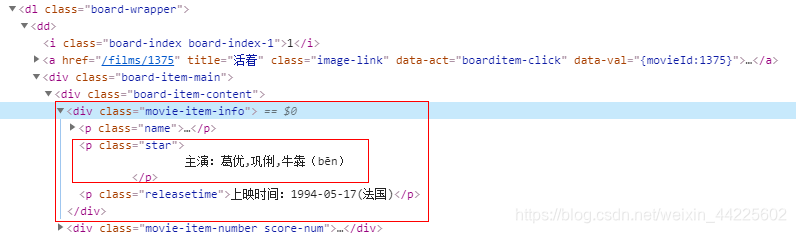
time - 放映时间
score - 评分
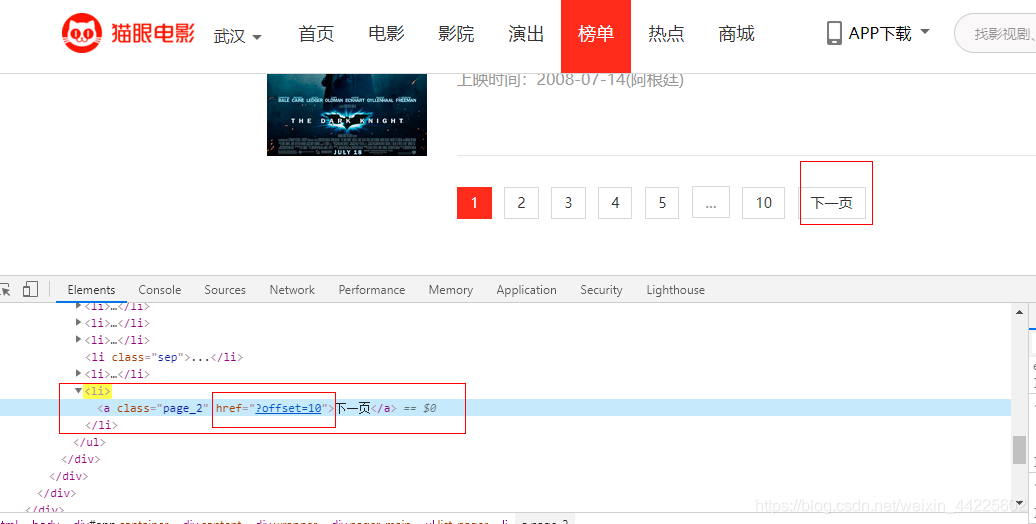
翻页:
1.3、构建Scrapy
(1) items.py
import scrapy
class MaoyanItem(scrapy.Item):
# define the fields for your item here like:
title = scrapy.Field()
img = scrapy.Field()
star = scrapy.Field()
time = scrapy.Field()
score = scrapy.Field()
(2) my_spider.py
# -*- coding: utf-8 -*-
import scrapy
import urllib.parse
import re
from ..items import MaoyanItem
class MySpiderSpider(scrapy.Spider):
name = 'my_spider'
allowed_domains = ['maoyan.com']
start_urls = ['https://maoyan.com/board/4?offset=0']
def parse(self, response):
dds = response.css('dl.board-wrapper dd')
# print(response.text)
for dd in dds:
item = MaoyanItem()
item['title'] = dd.css('img.board-img::attr(alt)').get()
# 注意这里为data-src而不是网页中的src
item['img'] = dd.css('img.board-img::attr(data-src)').get()
item['star'] = dd.css('p.star::text').get()
item['time'] = dd.css('p.releasetime::text').get()
item['score'] = dd.css('p.score i::text').getall()
yield item
# print(response.url)
# https://maoyan.com/board/4?offset=0
base_url = response.url.split('?')[0]
next_page = response.css('ul.list-pager li:nth-last-child(1) a::attr(href)').get()
next_url = urllib.parse.urljoin(base_url, next_page)
if next_page:
yield scrapy.Request(next_url, callback=self.parse)
注意:
网站上的HTML和IDE中的HTML有属性名的不同,以IDE中的属性名为标准
比如:图片链接属性名,在网站中为src而IDE中为data-src。

(3) pipelines.py
class MaoyanPipeline(object):
def process_item(self, item, spider):
star = item['star'].strip().replace('\n', '').replace(' ', '')
with open('maoyan100.csv', 'a', encoding='utf-8')as f:
f.write(item['title']+','+item['img']+','+star+','+item['time']+',' + ''.join(item['score']))
# f.write(item['img'])
f.write('\n')
return item
(2) settings.py
取消注释ITEM_PIPELINES
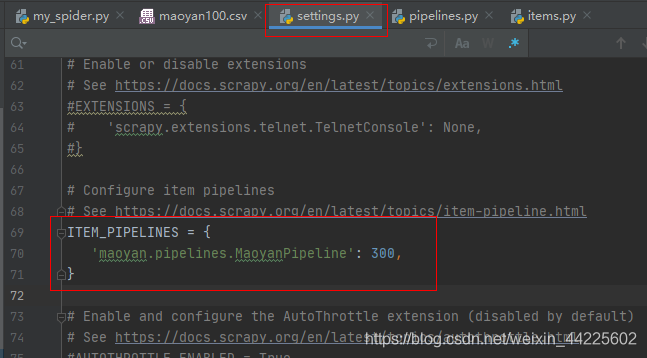
设置请求头:
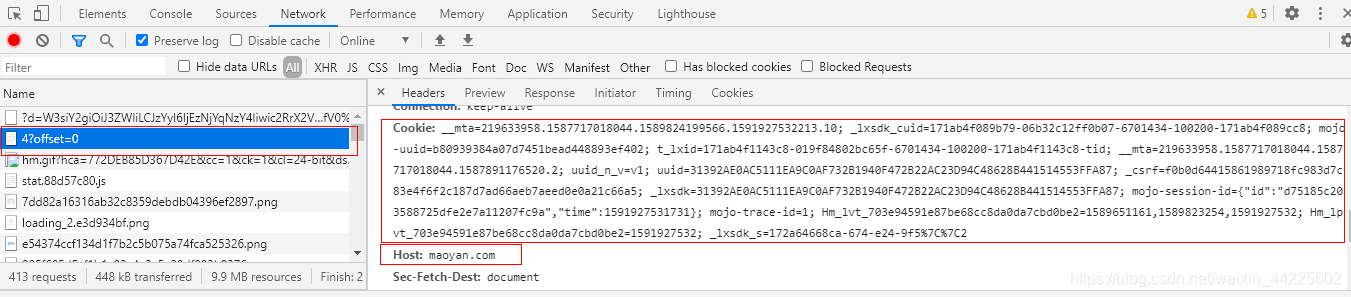
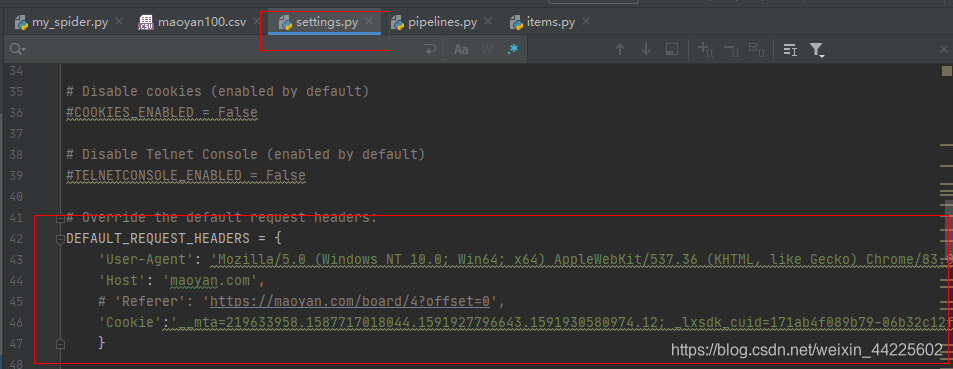
1.4、运行Scrapy
scrapy crawl db_spider
结果:

五、Scrapy的进阶使用
1、scrapy.Request - 返回请求
Request对象用来描述一个HTTP请求,下面是其构造器方法的参数列表:
Request(url, callback=None, method='GET', headers=None, body=None,
cookies=None, meta=None, encoding='utf-8', priority=0,
dont_filter=False, errback=None, flags=None, cb_kwargs=None)
- url(字符串)–此请求的URL
- callback(callable)–将以请求的响应(一旦下载)作为第一个参数调用的函数。有关更多信息,请参见下面的将其他数据传递给回调函数。如果“请求”未指定回调,parse() 则将使用“Spider” 方法。请注意,如果在处理过程中引发异常,则会调用errback。
- method(字符串)–此请求的HTTP方法。默认为
'GET'。 - meta(dict)– Request.meta属性的初始值。如果给出,则在此参数中传递的字典将被浅表复制。
- headers(dict)–请求头。dict值可以是字符串(对于单值标头)或列表(对于多值标头)。如果
None作为值传递,则将根本不发送HTTP标头。
以前面的格言网站为例子:
import scrapy
from urllib import parse
class QuotesSpider(scrapy.Spider):
name = 'quotes3'
allowed_domains = ['toscrape.com']
start_urls = ['http://quotes.toscrape.com/page/1/']
def parse(self, response):
quotes = response.css('.quote')
for quote in quotes:
text = quote.css('.text::text').extract_first()
auth = quote.css('.author::text').extract_first()
tages = quote.css('.tags a::text').extract()
yield dict(text=text, auth=auth, tages=tages)
next_url = response.css('.next a::attr(href)').extract_first()
next_url = parse.urljoin 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1936
1936

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









