







Spider Middleware位于Spider和Engine之间,当Download生成Response之后会发送给Spider、在发送给Spider之前,Response会先经过Spider Middleware处、当Spider处理生成Item和Request之后,Item和Request还会经过Spider Middleware的处理。
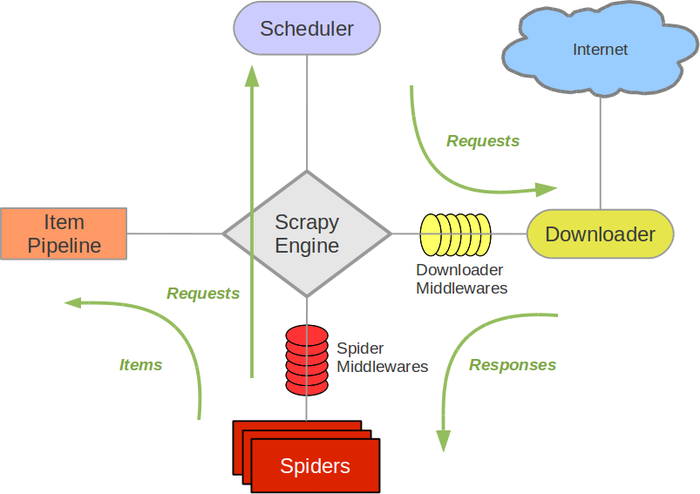
Spider Middleware有以下几个用处:
- Downloader 生成Response之后、Engine会将其发送给Spider进行解析,在此之前可以对Response进行处理
- Spider在生成Request之后会发送给Engine、然后Request会被转发到Scheduler,在Request发送给Engine之前可以借助Spider Middleware对Request进行处理
- Spider生成Item之后会被发送到Engine,然后Item会被转发到Item Pipeline,在Engine在转发Item之前、可以借助Spider Middleware对Item进行处理
总结:Spider Middleware可以处理Spider的Response和Spider输出的Item以及Request。
自定义Spider Middleware
同样、scrapy已经内置了很多Spider Middleware、与Downloader Middleware类似、它们被定义在SPIDER_MIDDLEWARES_BASE变量中。同样自定义的Spider Middleware要放在SPIDER_MIDDLEWARES变量里、如果要禁用默认的Spider Middleware中间件、在SPIDER_MIDDLEWARES变量里设置为None即可。
默认的Spider Middleware
# 默认值:
SPIDER_MIDDLEWARES_BASE = {
"scrapy.spidermiddlewares.httperror.HttpErrorMiddleware": 50,
"scrapy.spidermiddlewares.referer.RefererMiddleware": 700,
"scrapy.spidermiddlewares.urllength.UrlLengthMiddleware": 800,
"scrapy.spidermiddlewares.depth.DepthMiddleware": 900,
}
# 自定义Spider Middleware
SPIDER_MIDDLEWARES = {
pass
}
核心方法
我们想要拓展scrapy内置的基础的Spider Middleware、只需要实现以下几个方法即可
-
process_spider_input(response, spider)
当Response通过Spider Middleware时、该方法被调用、处理该Response有两个参数
-
process_spider_output(response, result, spider)
当Spider处理Response返回结果时、该方法被调用、有三个参数
-
process_spider_exception(response, exception,spider)
当Spider或Spider Middleware的process_spider_input方法抛出异常时、该方法被调用
-
process_start_requests(start_requests,spider)
process_start_requests方法以Spider启动的Request为参数调用,执行的过程类至于process_spider_output,只不过他没有关联的Response并且必须返回Request、有两个参数:
- start_requests (
Request的可迭代对象) – 起始请求 - spider (
Spider对象) – 起始请求所属的蜘蛛
- start_requests (
实战
老样子新建一个scrapy项目
scrapy startproject scrapyspidermiddlewaredemo
cd scrapyspidermiddlewaredemo
scrapy genspider httpbin www.httpbin.org
目录如下:
E:.
│ scrapy.cfg
│
└─scrapyspidermiddlewaredemo
│ items.py
│ middlewares.py
│ pipelines.py
│ settings.py
│ __init__.py
│
├─spiders
│ │ httpbin.py
│ │ __init__.py
│ │
│ └─__pycache__
│ __init__.cpython-313.pyc
│
└─__pycache__
settings.cpython-313.pyc
__init__.cpython-313.pyc
__pycache__文件忽略
import scrapy
from scrapy import Request
class HttpbinSpider(scrapy.Spider):
name = "httpbin"
allowed_domains = ["www.httpbin.org"]
start_url = "https://www.httpbin.org/get"
def parse(self, response):
print(response.text)
def start_requests(self):
for i in range(5):
url = f'{self.start_url}?query={i}'
yield Request(url, callback=self.parse)
我们重构了start_requests方法、构造了几个Request、回调方法还是pase方法,并将Response的文本打印出来
运行:
scrapy crawl httpbin
部分输出:
{
"args": {
"query": "4"
},
"headers": {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "en",
"Host": "www.httpbin.org",
"User-Agent": "Scrapy/2.12.0 (+https://scrapy.org)",
"X-Amzn-Trace-Id": "Root=1-67fe6950-3e2f549a0f1c8d490fe814ae"
},
"origin": "154.19.47.141",
"url": "https://www.httpbin.org/get?query=4"
}
可以看到scrapy发送的Request的内容被传输了"url": " https://www.httpbin.org/get?query=4"
另外定义一个Item、取四个字段
import scrapy
class DemoItem(scrapy.Item):
origin = scrapy.Field()
headers = scrapy.Field()
args = scrapy.Field()
url = scrapy.Field()
同时把Spider中parse方法中返回的Response的内容转化为对应的DemoItem、parse修改如下:
def parse(self, response):
item = DemoItem(**response.json())
yield item
部分输出:
{'args': {'query': '1'},
'headers': {'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'en',
'Host': 'www.httpbin.org',
'User-Agent': 'Scrapy/2.12.0 (+https://scrapy.org)',
'X-Amzn-Trace-Id': 'Root=1-67fe6b9d-484a868b441c8bee787d9d81'},
'origin': '154.19.47.141',
'url': 'https://www.httpbin.org/get?query=1'}
运行后、scrapy就会产生对应的DemoItem了、可以看到原本的json类型被输出为DemoItem类型。
接下来实现对一个Spider Middleware、对Response、Item、Request的处理。
在Middlewares.py中重新声明一个CustomizeMiddleware类(自定义中间件)
代码如下:
class CustomizeMiddleware:
def process_start_requests(self,start_requests,spider):
for request in start_requests:
url = request.url
url += '&name=xiaoming'
request = request.replace(url=url)
yield request
注意、我们还要在setting中配置我们自定义的中间件
# setting.py
SPIDER_MIDDLEWARES = {
"scrapyspidermiddlewaredemo.middlewares.CustomizeMiddleware": 543,
}
这样我们自定义处理Request的中间件就写好了。
运行、输出如下:
{'args': {'name': 'xiaoming', 'query': '4'},
'headers': {'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'en',
'Host': 'www.httpbin.org',
'User-Agent': 'Scrapy/2.12.0 (+https://scrapy.org)',
'X-Amzn-Trace-Id': 'Root=1-67fe6f41-5a7bbd934298f2885bfb0506'},
'origin': '154.19.47.141',
'url': 'https://www.httpbin.org/get?query=4&name=xiaoming'}
可以看到Request的url被修改了
对Response和ite的改写
在CustomizeMiddleware类中新增如下定义:
def process_spider_input(self,response,spider):
response.status = 201
def process_spider_output(self,response,result,spider):
for i in result:
if isinstance(i,DemoItem):
i['origin'] = None
yield i
对于process_spider_output来说、输出就是Request或Item、但是两者混在一起了、添加一个if判断、如果是DemoItem实例就把origin这是为None、当然这里还可以对Request做类似的处理
另外再pase方法中输出Response状态码
print('Status:', response.status)
重新运行、部分输出如下:
Status: 201
2025-04-15 22:49:05 [scrapy.core.scraper] DEBUG: Scraped from <201 https://www.httpbin.org/get?query=2&name=xiaoming>
{'args': {'name': 'xiaoming', 'query': '2'},
'headers': {'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'en',
'Host': 'www.httpbin.org',
'User-Agent': 'Scrapy/2.12.0 (+https://scrapy.org)',
'X-Amzn-Trace-Id': 'Root=1-67fe71dc-31f320d35573ad0d087c2a9a'},
'origin': None,
'url': 'https://www.httpbin.org/get?query=2&name=xiaoming'}
可以看到Response的状态码修改为了201,origin为None,
亲学习到此结束、早点休息。

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









