







scrapy入门
目标地址
url = https://quotes.toscrape.com/
命令行创建scrapy项目
scrapy startproject scrapytutorial
# 创建一个spider自定义类
cd scrapytutorial
scrapy genspider quotes
项目目录如下:
│ scrapy.cfg
│
└─scrapytutorial
│ items.py
│ middlewares.py
│ pipelines.py
│ settings.py
│ __init__.py
│
├─spiders
│ │ quotes.py
│ │ __init__.py
│ │
│ └─__pycache__
│ __init__.cpython-310.pyc
│
└─__pycache__
settings.cpython-310.pyc
__init__.cpython-310.pyc
创建Item
Item.py
import scrapy
class QuoteItem(scrapy.Item):
"""
定义要爬取的字段
"""
text = scrapy.Field()
author = scrapy.Field()
tags = scrapy.Field()
定义要爬取的字段
解析respnse
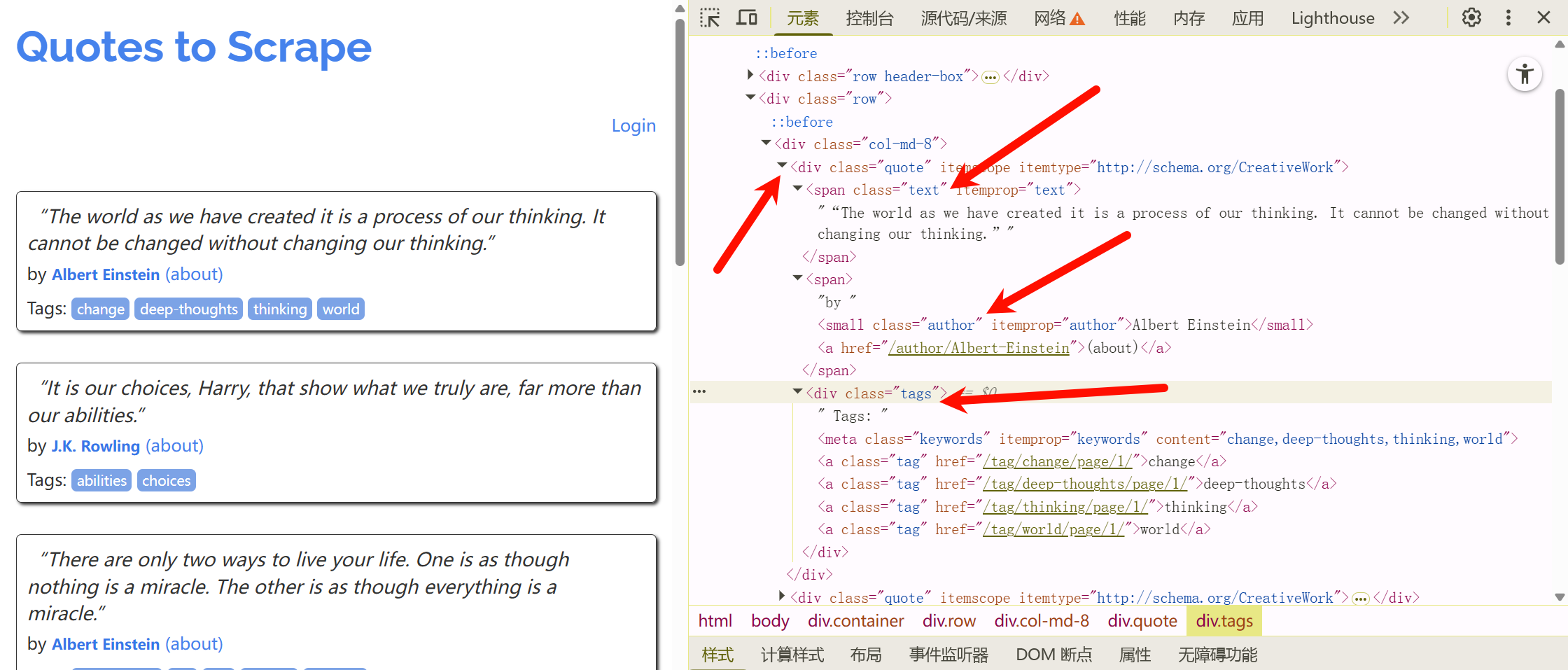
quotes.py
class QuotesSpider(scrapy.Spider):
name = "quotes"
allowed_domains = ["quotes.toscrape.com"]
start_urls = ["https://quotes.toscrape.com/"]
def parse(self, response):
quotes = response.css(".quote")
for quote in quotes:
text = quote.css('.text::text').extract_first()
author = quote.css('.author::text').extract_first()
tags = quote.css('.tags .tag::text').extract()
使用scrapy提供的css或xpath选择器进行信息提取
使用Item
Item类至于一个字典本质是一个类。所以再使用的时候要实例化。
# quotes.py
import scrapy
from ..items import QuoteItem
class QuotesSpider(scrapy.Spider):
name = "quotes"
allowed_domains = ["quotes.toscrape.com"]
start_urls = ["https://quotes.toscrape.com/"]
def parse(self, response):
quotes = response.css(".quote")
for quote in quotes:
item = QuoteItem()
item['text'] = quote.css('.text::text').extract_first()
item['author'] = quote.css('.author::text').extract_first()
item['tags'] = quote.css('.tags .tag::text').extract()
yield item
每一个QuoteItem代表一条名言、包含名言内容、作者和标签
处理nextPage
再处理完一个页面后我们需要构造下一个页面的request
scrapy提供了一个Request(url,callback)
- url:目标页面的连接
- callback:回调方法
# quotes.py
import scrapy
from ..items import QuoteItem
class QuotesSpider(scrapy.Spider):
name = "quotes"
allowed_domains = ["quotes.toscrape.com"]
start_urls = ["https://quotes.toscrape.com/"]
def parse(self, response):
quotes = response.css(".quote")
for quote in quotes:
item = QuoteItem()
item['text'] = quote.css('.text::text').extract_first()
item['author'] = quote.css('.author::text').extract_first()
item['tags'] = quote.css('.tags .tag::text').extract()
yield item
# 获取下一页连接
next = response.css('.pager .next a::attr(href)').extract_first()
# urljoin 将相对URL拼接为绝对URL /page/2 ---> https://quotes.toscrape.com/page/2/
url = response.urljoin(next)
yield scrapy.Request(url=url, callback=self.parse)
运行
scrapy crawl quotes
# 保存为json格式文件
scrapy crawl quotes -o quotes.json
# 每一个Itemw为一个json文件 jl(jsonline)
scrapy crawl quotes -o quotes.jl
or
scrapy crawl quotes -o quotes.jsonlines
输出格式
scrapy提供Feed Exports
- name.csv
- name.xml
- name.pickle
- name.marshal
- ftp://…
Item Pipeline数据清洗
Item Pipeline为项目管道、当Item生成后、它会自动送到Item Pipeline处进行处理。
- 清洗html数据
- 验证爬取数据、检查爬取字段
- 查重、丢弃重复内容
- 将结果保存到数据库
实现
定义一个类并实现process_item方法即可、启用Item Pipeline后会自动调用这个方法。
process_item方法必须返回包含数据的字典或Item对象、或者抛出DropItem异常
process_item(item,spider)
每次生成的Item都会作为参数传递过来、另一个参数就是Spider实例。
需求
筛掉text长度大于50的Item、并保存起来
# pipeline
from scrapy.exceptions import DropItem
class TextPipeline:
def __init__(self):
self.limit = 50
def process_item(self, item, spider):
if item['text']:
if len(item['text']) > self.limit:
item['text'] = item['text'][0:self.limit].rstrip() + "..."
return item
else:
return DropItem("missing text")
# settings.py
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
"scrapytutorial.pipelines.TextPipeline": 300,
}
如果需要保存到数据库、在pipeline.py再添加一个数据库类

















 64万+
64万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









