







官方网站当然是huggingface,但是...你懂得,国内基本下载得巨慢。
于是,有需求就有了产品。
这个是huggingface的镜像网站,如果在huggingface中可以直接下载(不需要申请)的模型文件,在这里同样可以直接下载,速度快得多了。如果windows就直接点下载图标就可以了。如果要申请的话,申请之后可以创建一个新的token用命令行下载。
如果是linux,可以先用下面的命令clone整个仓库的小文件(大文件一般不会直接下载好)
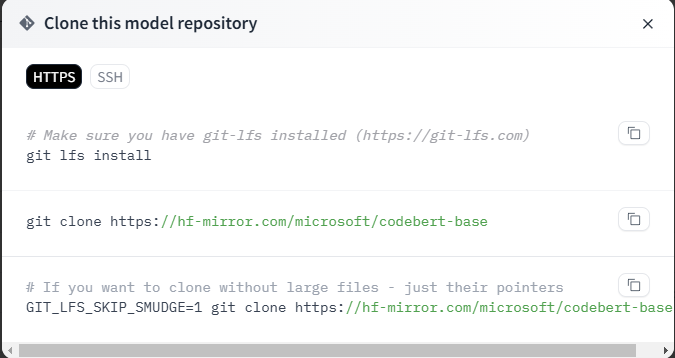
然后,用wget下载大模型。把鼠标放在下载图标处,然后右键一下,就出现复制链接地址,复制了然后wget就OK,下载好之后记得改个文件名。

当然,还有第二种方式,可以自由选择。
1、pip install -U huggingface hub
2、export HF_ENDPOINT=https://hf-mirror.com【LINUX】
$env:HF ENDPOINT ="https://hf-mirror.com'【Windows】
3、huggingface-cli download --resume-download 模型名 --local-dir 本地下载目录


















 478
478

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











