







 本文探讨了归一化在数据预处理中的关键作用,包括线性归一化、标准差标准化、非线性归一化以及BatchNormalization、WeightNormalization的区别。重点阐述了归一化如何提升模型收敛速度,解决饱和问题,统一量纲,以及在深度神经网络中的实际应用案例。
本文探讨了归一化在数据预处理中的关键作用,包括线性归一化、标准差标准化、非线性归一化以及BatchNormalization、WeightNormalization的区别。重点阐述了归一化如何提升模型收敛速度,解决饱和问题,统一量纲,以及在深度神经网络中的实际应用案例。
归一化含义
归一化的具体作用是归纳统一样本的统计分布性。归一化在
0-1
之间是统计的概率分布, 归一化在-1--+1
之间是统计的坐标分布。归一化有同一、统一和合一的意思。无论是为了建模还是为了计算,首先基本度量单位要同一,神经网络是以样本在事件中的统计分别几率来进行训练(概率计算)和预测的,且 sigmoid
函数的取值是
0
到
1
之间的,网络最后一个节点的输出也是如此,所以经常要对样本的输出归一化处理。归一化是统一在 0-1
之间的统计概率分布,当所有样本的输入信号都为正值时,与第一隐含层神经元相连的权值只能同时增加或减小,从而导致学习速度很慢。另外在数据中常存在奇异样本数据,奇异样本数据存在所引起的网络训练时间增加,并可能引起网络无法收敛。为了避免出现这种情况及后面数据处理的方便,加快网络学习速度,可以对输入信号进行归一化,使得所有样本的输入信号其均值接近于 0
或与其均方差相比很小。
为什么要归一化
(
1
)为了后面数据处理的方便,归一化的确可以避免一些不必要的数值问题。
(2)为了程序运行时收敛加快。 下面图解。
(3)同一量纲。样本数据的评价标准不一样,需要对其量纲化,统一评价标准。这算是应用层面的需求。
(4)避免神经元饱和。啥意思?就是当神经元的激活在接近
0
或者
1
时会饱和,在这些区域,梯度几乎为 0
,这样,在反向传播过程中,局部梯度就会接近
0
,这会有效地“杀死”
梯度。
(5)保证输出数据中数值小的不被吞食
为什么归一化能提高求解最优解速度
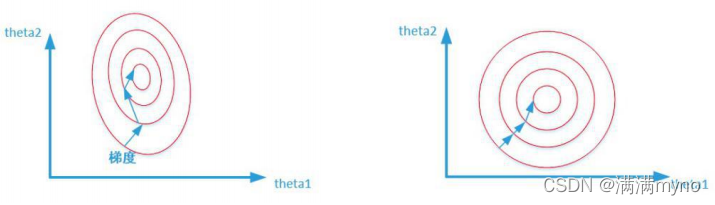
两张图代表数据是否均一化的最优解寻解过程(圆圈可以理解为等高线)。左图表示未经归一化操作的寻解过程,右图表示经过归一化后的寻解过程。
当使用梯度下降法寻求最优解时,很有可能走“之字型”路线(垂直等高线走),从而导致需要迭代很多次才能收敛;而右图对两个原始特征进行了归一化,其对应的等高线显得很圆,在梯度下降进行求解时能较快的收敛。
因此如果机器学习模型使用梯度下降法求最优解时,归一化往往非常有必要,否则很难收敛甚至不能收敛。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 6329
6329

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











