







在数值计算中,求解线性方程组是一个常见的问题。本文将介绍如何使用 Gauss-Seidel 方法、最速下降法和共轭梯度法来求解系数矩阵为 20 阶 Pascal 矩阵的线性方程组,并分析它们的收敛性。可以根据自己的需求修改所需求解的矩阵。
此次文章创作来源于电子科技大学数值分析研究生课程的第二次作业,如题:

一、问题描述
我们需要求解一个线性方程组 ,其中系数矩阵 是一个 20 阶的 Pascal 矩阵,右侧向量 给定。
二、方法介绍
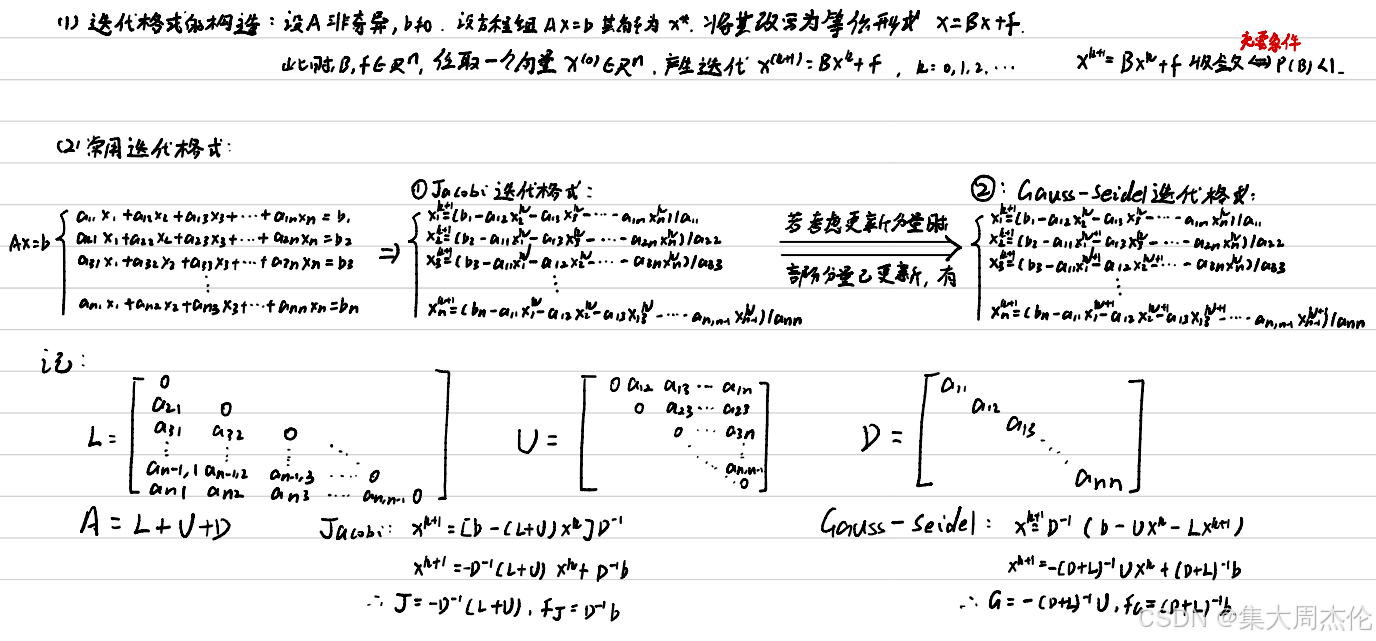
1. Gauss-Seidel 方法
Gauss-Seidel 方法是一种迭代法,它利用系数矩阵的特殊结构,在每次迭代中依次更新解向量的各个分量。在更新某一个分量时,使用已经更新过的分量值,而不是像 Jacobi 方法那样使用上一轮迭代的所有旧值。
算法步骤如下:
- 创建 20 阶 Pascal 矩阵:
- 通过两层循环,使用 Pascal 矩阵的递推公式生成完整的 Pascal 矩阵。
- 初始化一个全 1 的20×20矩阵。
- 计算 Gauss-Seidel 迭代矩阵G:
- 将系数矩阵A分解为对角矩阵D、严格下三角矩阵L和严格上三角矩阵U。
- 计算G = -np.linalg.inv(D + L).dot(U)。
- 分析收敛性:
- 计算G矩阵的特征值和特征向量,取特征值的绝对值以确定收敛性。若最大特征值大于等于 1,则判断该矩阵方程组不收敛;若最大特征值小于 1,则进行下一步求解。
- 求解方程组:
- 若满足收敛条件,使用以下迭代步骤求解方程组:
- 初始化解向量x为零向量(或给定的初始解向量)。
- 对于每次迭代:
- 遍历方程组的每个方程(对应矩阵的每一行):
- 计算当前方程中,已更新的变量部分(对应矩阵的前i列)的乘积sum1 = np.dot(A[i, :i], x[:i])。
- 计算当前方程中,上一轮迭代的未更新变量部分(对应矩阵的后n-i-1列)的乘积sum2 = np.dot(A[i, i + 1:], x_old[i + 1:])。
- 更新当前变量x[i] = (b[i] - sum1 - sum2) / A[i, i]。
- 检查收敛性,如果当前解与上一轮解的无穷范数之差小于收敛容差,则返回解向量;否则继续下一轮迭代。
- 若满足收敛条件,使用以下迭代步骤求解方程组:
算法原理说明:
2. 最速下降法
最速梯度法是一种基于梯度下降的迭代方法,旨在最小化目标函数。其基本思想是:在每次迭代中,根据当前解的梯度信息,计算一个新的解,使得目标函数的值朝着最小方向下降。
算法步骤如下:
- 创建 20 阶 Pascal 矩阵和右侧常数向量b:
- 与 Gauss-Seidel 方法中创建 Pascal 矩阵和b的步骤相同。
- 求解方程组:
- 初始化解向量x为零向量(或给定的初始解向量)。
- 计算初始残差向量residual_vector = b - np.dot(A, x)。
- 对于每次迭代:
- 保存旧解向量x_old = x.copy()。
- 计算temp_value = np.dot(A, residual_vector)。
- 计算步长alpha = np.dot(residual_vector.T, residual_vector) / np.dot(residual_vector.T, temp_value)。
- 更新解向量x = x_old + alpha * residual_vector。
- 更新残差向量residual_vector = residual_vector - alpha * temp_value。
- 检查收敛性,如果当前解与上一轮解的无穷范数之差小于收敛阈值,则返回解向量;否则继续下一轮迭代。
算法原理说明:最速下降法的基本思想是沿着负梯度方向进行搜索,因为在局部范围内负梯度方向是函数下降最快的方向。然而,最速下降法在接近最优解时收敛速度会变慢。
数学语言迭代方程式:
3. 共轭梯度法
共轭梯度法是一种更为高效的迭代方法,特别适用于大型稀疏线性方程组。其核心在于通过构造一组共轭方向,确保每次迭代的方向是相互正交的,从而加速收敛。迭代方式与最速梯度法相似,仅是改变了迭代方向,可以证明对于n阶非奇异矩阵Ax=b方程组,迭代n次以内必定可以求出精确解。
算法步骤如下:
- 创建 20 阶 Pascal 矩阵和右侧常数向量b:
- 与前面方法中创建 Pascal 矩阵和b的步骤相同。
- 求解方程组:
- 初始化解向量x为零向量(或给定的初始解向量)。
- 计算初始残差向量residual_vector = b - np.dot(A, x)。
- 初始化梯度方向为残差向量gradient_direction = residual_vector.copy()。
- 对于每次迭代:
- 保存旧解向量x_old = x.copy()。
- 计算temp_value = np.dot(A, gradient_direction)。
- 计算步长alpha = np.dot(residual_vector.T, gradient_direction) / np.dot(gradient_direction.T, temp_value)。
- 更新解向量x = x_old + alpha * gradient_direction。
- 更新残差向量residual_vector = residual_vector - alpha * temp_value。
- 计算调整因子beta = -np.dot(residual_vector.T, temp_value) / np.dot(gradient_direction.T, temp_value)。
- 更新梯度方向gradient_direction = residual_vector + beta * gradient_direction。
- 检查收敛性,如果当前解与上一轮解的无穷范数之差小于收敛容忍度,则返回解向量;否则继续下一轮迭代。
数学语言迭代方程式:
三、代码实现
以下是使用 Python 和 NumPy库 实现三种方法的代码:
1. Gauss-Seidel 方法:
import numpy as np
def gauss_seidel(A, b, x0=None, tol=1e-6, max_iterations=100000):
"""
使用 Gauss-Seidel 迭代法求解线性方程组 Ax = b。
参数:
- A : numpy.ndarray
系数矩阵。
- b : numpy.ndarray
右侧常数向量。
- x0 : numpy.ndarray, optional
初始解向量。如果未提供,则默认为零向量。
- tol : float, optional
收敛容差。默认值为 1e-10。
- max_iterations : int, optional
最大迭代次数。默认值为 100000。
返回:
- x : numpy.ndarray
方程组的解向量。
"""
n = len(b)
if x0 is None:
x0 = np.zeros(n)
x = x0.copy()
for iteration in range(max_iterations):
x_old = x.copy()
for i in range(n):
# 计算A的前 i 列的乘积
sum1 = np.dot(A[i, :i], x[:i])
# 计算A的后 n-i-1 列的乘积
sum2 = np.dot(A[i, i + 1:], x_old[i + 1:])
# 迭代更新 x[i] 的值
x[i] = (b[i] - sum1 - sum2) / A[i, i]
# 检查收敛性,如果满足收敛条件则返回解
if np.linalg.norm(x - x_old, ord=np.inf) < tol:
print(f"收敛于迭代 {iteration + 1}")
return x
# 如果未收敛,则提示
print("未收敛")
return x
def gauss_seidel_matrix(A):
"""
计算 Gauss-Seidel 方法的迭代矩阵 G。
参数:
- A : numpy.ndarray
系数矩阵。
返回:
- G : numpy.ndarray
Gauss-Seidel 迭代矩阵。
"""
# 分解 A 为对角矩阵 D 和严格下、上三角矩阵 L 和 U
D = np.diag(np.diag(A)) # 对角矩阵 D
L = np.tril(A, -1) # 严格下三角矩阵 L
U = np.triu(A, 1) # 严格上三角矩阵 U
# 计算 G 矩阵
G = -np.linalg.inv(D + L).dot(U)
return G
# 创建一个 20 阶 Pascal 矩阵
n = 20
pascal_matrix = np.ones((n, n))
for i in range(1, n):
for j in range(1, n):
# 使用 Pascal 矩阵的递推公式生成矩阵
pascal_matrix[i, j] = pascal_matrix[i-1, j] + pascal_matrix[i, j-1]
# 计算 Gauss-Seidel 迭代矩阵 G
G = gauss_seidel_matrix(pascal_matrix)
# 计算 G 矩阵的特征值和特征向量
eigenvalues, eigenvectors = np.linalg.eig(G)
eigenvalues = eigenvalues.__abs__() # 取绝对值以确定收敛性
# 创建解向量 b
b = np.array([
20, 210, 1540, 8855, 42504,
177100, 657800, 2220075, 6906900, 20030010,
54627300, 141120525, 347373600, 818809200, 1855967520,
4059928950, 8597496600, 17672631900, 35345263800, 68923264410
])
b = b.reshape(-1, 1)
# 判断 G 的谱半径是否小于 1,以确定收敛性
if eigenvalues.max() >= 1:
print(f"最大特征值 {eigenvalues.max()} 不小于 1,故该矩阵方程组不收敛")
else:
# 如果满足收敛条件,则调用 Gauss-Seidel 方法求解
solution = gauss_seidel(pascal_matrix, b)
print("解为:")
print(solution)
2. 最速下降法
import numpy as np
def gradient_descent(A, b, x0=None, tol=1e-6, max_iterations=int(1e6)):
"""
使用最速下降法求解线性方程组 Ax = b。
参数:
A : numpy.ndarray
系数矩阵。
b : numpy.ndarray
右侧向量。
x0 : numpy.ndarray, optional
初始解向量,默认为零向量。
tol : float, optional
收敛阈值,默认 1e-6。
max_iterations : int, optional
最大迭代次数,默认 1e6。
返回:
numpy.ndarray
求解结果向量 x。
"""
n = len(b) # 线性方程组的维度
if x0 is None:
x0 = np.zeros((A.shape[0], 1)) # 初始化解向量为全零
residual_vector = b - np.dot(A, x0) # 计算初始残差
x = x0.copy() # 当前解向量
for iteration in range(max_iterations):
x_old = x.copy() # 保存旧解
temp_value = np.dot(A, residual_vector) # 计算 A * 残差向量
# 计算步长 alpha
alpha = np.dot(residual_vector.T, residual_vector) / np.dot(residual_vector.T, temp_value)
x = x_old + alpha * residual_vector # 更新解向量
residual_vector = residual_vector - alpha * temp_value # 更新残差向量
# 检查收敛性
if np.linalg.norm(x - x_old, ord=np.inf) < tol:
print(f"收敛于迭代 {iteration + 1}")
return x # 返回求解出的解向量
print("未收敛")
return x # 返回当前解向量
# 创建一个 20 阶 Pascal 矩阵
n = 20
pascal_matrix = np.ones((n, n)) # 初始化为全 1 矩阵
# 使用 Pascal 矩阵的递推公式生成矩阵
for i in range(1, n):
for j in range(1, n):
pascal_matrix[i, j] = pascal_matrix[i - 1, j] + pascal_matrix[i, j - 1]
# 创建解向量 b
b = np.array([
20, 210, 1540, 8855, 42504,
177100, 657800, 2220075, 6906900, 20030010,
54627300, 141120525, 347373600, 818809200, 1855967520,
4059928950, 8597496600, 17672631900, 35345263800, 68923264410
]).reshape(-1, 1) # 将 b 转换为列向量
# 调用最速下降法
solution = gradient_descent(pascal_matrix, b)
print("解为:")
print(solution)
3. 共轭梯度法:
import numpy as np
def conjugate_gradient(A, b, x0=None, tol=1e-6, max_iterations=20):
"""
共轭梯度法求解线性方程组 Ax = b.
参数:
A (ndarray): 系数矩阵。
b (ndarray): 常数向量。
x0 (ndarray, optional): 初始解向量。默认为全零向量。
tol (float, optional): 收敛容忍度。默认为 1e-6。
max_iterations (int, optional): 最大迭代次数。默认为 20。
返回:
x (ndarray): 求解出的解向量。
"""
n = len(b) # 方程组的维度
if x0 is None:
x0 = np.zeros((A.shape[0], 1)) # 初始化解向量为全零
residual_vector = b - np.dot(A, x0) # 计算初始残差
x = x0.copy() # 当前解向量
gradient_direction = residual_vector.copy() # 初始化梯度方向为残差
for iteration in range(max_iterations):
x_old = x.copy() # 保存旧解
temp_value = np.dot(A, gradient_direction) # 计算 A * 梯度方向
alpha = np.dot(residual_vector.T, gradient_direction) / np.dot(gradient_direction.T, temp_value) # 计算步长
x = x_old + alpha * gradient_direction # 更新解向量
residual_vector = residual_vector - alpha * temp_value # 更新残差向量
beta = -np.dot(residual_vector.T, temp_value) / np.dot(gradient_direction.T, temp_value) # 计算调整因子
gradient_direction = residual_vector + beta * gradient_direction # 更新梯度方向
# 检查收敛性
if np.linalg.norm(x - x_old, ord=np.inf) < tol:
print(f"收敛于迭代 {iteration + 1}")
return x # 返回求解出的解向量
print("未收敛")
return x # 返回当前解向量
# 创建一个 20 阶 Pascal 矩阵
n = 20
pascal_matrix = np.ones((n, n)) # 初始化为全 1 矩阵
# 使用 Pascal 矩阵的递推公式生成矩阵
for i in range(1, n):
for j in range(1, n):
pascal_matrix[i, j] = pascal_matrix[i - 1, j] + pascal_matrix[i, j - 1]
# 创建解向量 b
b = np.array([
20, 210, 1540, 8855, 42504,
177100, 657800, 2220075, 6906900, 20030010,
54627300, 141120525, 347373600, 818809200, 1855967520,
4059928950, 8597496600, 17672631900, 35345263800, 68923264410
]).reshape(-1, 1) # 将 b 转换为列向量
# 调用共轭梯度法
solution = conjugate_gradient(pascal_matrix, b)
print("解为:")
print(solution)

















 1547
1547

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









