







 本文总结了自学《西瓜书》的心得,涵盖数据集、模型评估、参数调优等核心概念。讲解了错误率、精度、混淆矩阵、F1分数与ROC曲线等性能指标,帮助理解分类任务的评估方法。特别强调了过拟合与欠拟合,以及常用的评估技巧如留出法、交叉验证和自助法。
本文总结了自学《西瓜书》的心得,涵盖数据集、模型评估、参数调优等核心概念。讲解了错误率、精度、混淆矩阵、F1分数与ROC曲线等性能指标,帮助理解分类任务的评估方法。特别强调了过拟合与欠拟合,以及常用的评估技巧如留出法、交叉验证和自助法。
自学西瓜书总结笔记,间断补充学校课程。
常用基础术语
- 数据集data set
- 示例instance / 样本sample
- 属性attribute / 特征feature
- 属性值 attribute value
- 属性空间attribute space / 样本空间sample space / 输入空间
- 训练集 / 训练样本 / 训练数据 / 测试集 / 测试样本 / 测试数据
- 模型 / 学习器
- 假设 hypothesis:习得模型对应了关于数据的某种潜在的规律
- 预测prediction
- 标记label / 样例example / 标记空间label space / 输出空间:关于示例结果的信息
- 分类classification
二分类binary classification:正类positive class & 负类negative class
多分类multi-class classification - 回归regression
- 聚类clustering——簇cluster
- 监督学习 supervised learning / 无监督学习 unsupervised learning
- 泛化 generalization:学得模型可以适用于新样本的能力
通常假设样本空间中每个样本都是独立同分布的,一般而言,训练的样本越多,就有更大可能获得强泛化模型 - 归纳学习 inductive learning:从样例中学习
- 归纳偏好 inductive bias:
任何一个有效的机器学习算法必有其归纳偏好
奥卡姆剃刀Occam`s razor:若有多个假设与观察一致,则选最简单的那一个
模型评估与选择
- 错误率 error rate:m个样本中有a个样本分类错误,E=a/m
- 精度 accuracy:1 - a/m
- 训练误差 train error / 经验误差empirical error
- 泛化误差 generalization error
希望得到泛化误差最小的学习器。 - 过拟合overfitting / 欠拟合 underfitting
评估方法
- 留出法 hold-out:
D分为S&T - 交叉验证法 cross validation:
D分为k个A1,A2,A3,…,Ak;A1作为测试集,A2 ~ Ak作为训练集;A2作为测试集,A1,A3 ~ Ak作为训练集…依此类推
esp:留一法 leave-one-out:即分割的每个子集只有一个样本 | 数据集较大的时候,训练m个模型的计算开销可能是难以忍受的 - 自助法 bootstrapping:
step1:D中随机采样生成D’ 【D中约有36.8%样本未出现在采样数据集中】
step2:D‘ 作为训练集,D\D’ 作为测试集
Advantage:适用于数据集较小、难以有效划分训练/测试集时;可以从初始数据集中产生多个不同的训练集,对于集成学习等方法有很大好处
Shortcoming:产生的数据集改变了原始数据集的分布,会引入估计偏差
调参 parameter tuning
性能度量 performance measure
回归任务常用——均方误差:即预测结果与真实标记的差值的平方的算术平均值
混淆矩阵:错误率&精度&查准率&查全率
首先来看一下分类结果的可能出现情况(有点类似统计学里面的 typeⅠerror & typeⅡ error)。
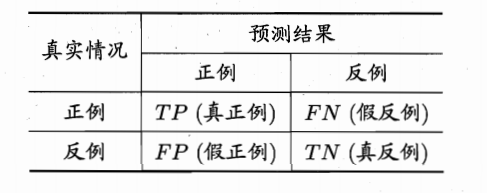
- 错误率:分类错误的样本数 / 总样本数
(FP+FN) / (TP+TN+FP+FN) - 精度:分类正确的样本数 / 总样本数
(TP+TN) / (TP+TN+FP+FN) - 查准率 precision:“预测出来的要是正确的”【如希望推荐内容确实是用户所感兴趣的】
TP / (TP+FP) - 查全率 recall:“能把正确的都预测出来”【逃犯信息检索时,尽可能少漏掉逃犯】
TP / (TP+FN) - P-R曲线:如果一个learner的P-R曲线完全包住另一条,就意味着性能更优;如下图中A优于C
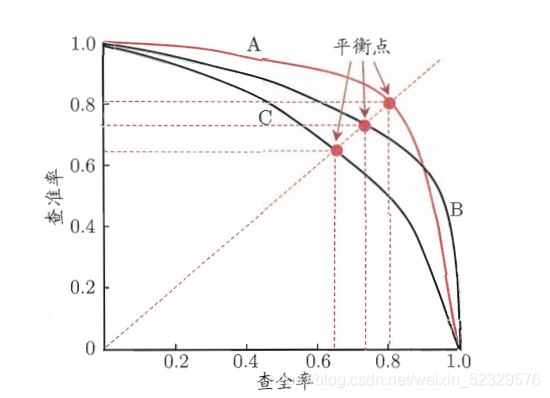
进阶性能度量
-
平衡点 break-event point,BEP:当查全率=查准率时的取值
-
F1:
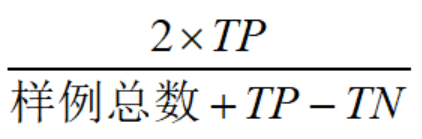
-
Fβ: 可以表达出对查准率和查全率的偏好
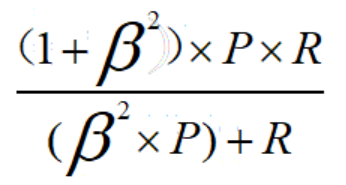
β的不同取值的意义如下:

-
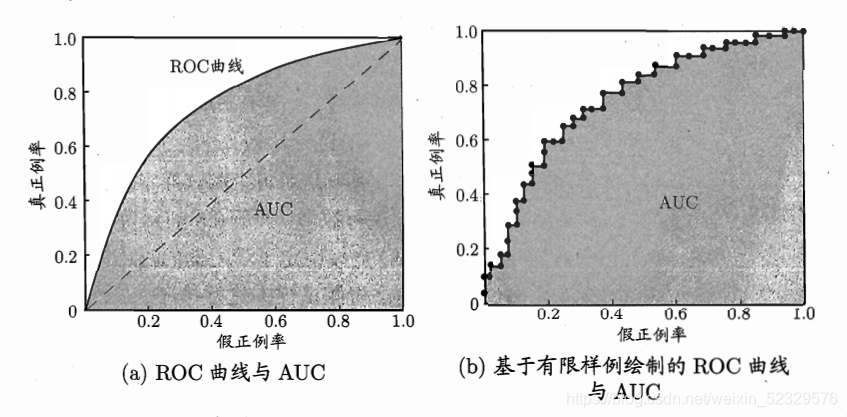
ROC:受试者工作特征曲线 receiver operating characteristic
纵轴:真正例率 True Positive Rate,TPR = TP / (TP+FN)
横轴:假正例率 False Postive Rate, FPR = FP / (TN+FP)
ROC曲线越接近左上角,该分类器的性能越好
-
AUC
被定义为ROC曲线下的面积,显然这个面积的数值不会大于1。又由于ROC曲线一般都处于y=x这条直线的上方,所以AUC的取值范围在0.5和1之间

















 998
998

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









