






 本文详细介绍了PVRCNN在OpenPCDet框架下的实现过程,包括数据预处理、anchor生成、MeanVFE、VoxelBackbone、height compression、Voxel Set Abstraction、BaseBackbone、AnchorHeadSingle、PointHeadSimple以及PVRCNN Head的各个步骤。通过这些步骤,实现了3D目标检测的关键技术,如特征提取、点云到BEV视图的转换、Set Abstraction模块的应用以及ROI池化等。
本文详细介绍了PVRCNN在OpenPCDet框架下的实现过程,包括数据预处理、anchor生成、MeanVFE、VoxelBackbone、height compression、Voxel Set Abstraction、BaseBackbone、AnchorHeadSingle、PointHeadSimple以及PVRCNN Head的各个步骤。通过这些步骤,实现了3D目标检测的关键技术,如特征提取、点云到BEV视图的转换、Set Abstraction模块的应用以及ROI池化等。
1.数据预处理
pcdet/datasets/kitti/kitti_dataset.py下__getitem__函数
def __getitem__(self, index):
# index = 4
if self._merge_all_iters_to_one_epoch:
index = index % len(self.kitti_infos)
info = copy.deepcopy(self.kitti_infos[index])
sample_idx = info['point_cloud']['lidar_idx']
img_shape = info['image']['image_shape']
calib = self.get_calib(sample_idx)
get_item_list = self.dataset_cfg.get('GET_ITEM_LIST', ['points'])
input_dict = {
'frame_id': sample_idx,
'calib': calib,
}
if 'annos' in info:
annos = info['annos']
annos = common_utils.drop_info_with_name(annos, name='DontCare')
loc, dims, rots = annos['location'], annos['dimensions'], annos['rotation_y']
gt_names = annos['name']
gt_boxes_camera = np.concatenate([loc, dims, rots[..., np.newaxis]], axis=1).astype(np.float32)
gt_boxes_lidar = box_utils.boxes3d_kitti_camera_to_lidar(gt_boxes_camera, calib)
input_dict.update({
'gt_names': gt_names,
'gt_boxes': gt_boxes_lidar
})
if "gt_boxes2d" in get_item_list:
input_dict['gt_boxes2d'] = annos["bbox"]
road_plane = self.get_road_plane(sample_idx)
if road_plane is not None:
input_dict['road_plane'] = road_plane
if "points" in get_item_list:
points = self.get_lidar(sample_idx)
'''
1.将点云数据从激光雷达坐标系转换为相机坐标系中的矩形坐标
2.表示只保留视场(Field of View,FOV)内的点云数据,即位于相机视野中的数据
'''
if self.dataset_cfg.FOV_POINTS_ONLY:
pts_rect = calib.lidar_to_rect(points[:, 0:3])
fov_flag = self.get_fov_flag(pts_rect, img_shape, calib)
points = points[fov_flag]
input_dict['points'] = points
if "images" in get_item_list:
input_dict['images'] = self.get_image(sample_idx)
if "depth_maps" in get_item_list:
input_dict['depth_maps'] = self.get_depth_map(sample_idx)
if "calib_matricies" in get_item_list:
input_dict["trans_lidar_to_cam"], input_dict["trans_cam_to_img"] = kitti_utils.calib_to_matricies(calib)
input_dict['calib'] = calib
此时input_dict为当前索引对应的信息,最重要的是FOV视角内的点云数据和点云形式的标注框形式
data_dict = self.prepare_data(data_dict=input_dict)
data_dict['image_shape'] = img_shape
return data_dict

其中prepare_data函数中对数据主要做了三个操作(yaml中配置)
- 数据增强(真值框采样、随机全局翻转、旋转、缩放等)
- 通道维数选择(从输入的维度中选择需要的维度作为输出,在此代码中输出维数=输入维数)
- 数据处理(去除视野范围外的点、打乱点的顺序,将点云转换成体素)
2.生成anchor
pcdet/models/dense_heads/target_assigner/anchor_generator.py下的generate_anchors函数
def generate_anchors(self, grid_sizes):
assert len(grid_sizes) == self.num_of_anchor_sets
# 1.初始化
all_anchors = []
num_anchors_per_location = []
# 2.三个类别的先验框逐类别生成
for grid_size, anchor_size, anchor_rotation, anchor_height, align_center in zip(
grid_sizes, self.anchor_sizes, self.anchor_rotations, self.anchor_heights, self.align_center):
# 每个位置产生2个anchor,这里的2代表两个方向
# 2.三个类别的先验框逐类别生成
num_anchors_per_location.append(len(anchor_rotation) * len(anchor_size) * len(anchor_height))
if align_center:
x_stride = (self.anchor_range[3] - self.anchor_range[0]) / grid_size[0]
y_stride = (self.anchor_range[4] - self.anchor_range[1]) / grid_size[1]
x_offset, y_offset = x_stride / 2, y_stride / 2
else:
# 计算每个网格的在点云空间中的实际大小,将每个anchor映射回实际点云
x_stride = (self.anchor_range[3] - self.anchor_range[0]) / (grid_size[0] - 1)
y_stride = (self.anchor_range[4] - self.anchor_range[1]) / (grid_size[1] - 1)
x_offset, y_offset = 0, 0
x_shifts = torch.arange(
self.anchor_range[0] + x_offset, self.anchor_range[3] + 1e-5, step=x_stride, dtype=torch.float32,
).cuda()
y_shifts = torch.arange(
self.anchor_range[1] + y_offset, self.anchor_range[4] + 1e-5, step=y_stride, dtype=torch.float32,
).cuda()
z_shifts = x_shifts.new_tensor(anchor_height)
num_anchor_size, num_anchor_rotation = anchor_size.__len__(), anchor_rotation.__len__()
anchor_rotation = x_shifts.new_tensor(anchor_rotation)
anchor_size = x_shifts.new_tensor(anchor_size)
# 调用meshgrid生成网格坐标
# meshgrid可以理解为在原来的维度上进行扩展,例如:
# x原来为(216,)-->(216,1, 1)--> (216,248,1)
# y原来为(248,)--> (1,248,1)--> (216,248,1)
# z原来为 (1, ) --> (1,1,1) --> (216,248,1)
x_shifts, y_shifts, z_shifts = torch.meshgrid([
x_shifts, y_shifts, z_shifts
]) # [x_grid, y_grid, z_grid]
anchors = torch.stack((x_shifts, y_shifts, z_shifts), dim=-1) # [x, y, z, 3]
anchors = anchors[:, :, :, None, :].repeat(1, 1, 1, anchor_size.shape[0], 1)
anchor_size = anchor_size.view(1, 1, 1, -1, 3).repeat([*anchors.shape[0:3], 1, 1])
anchors = torch.cat((anchors, anchor_size), dim=-1)
anchors = anchors[:, :, :, :, None, :].repeat(1, 1, 1, 1, num_anchor_rotation, 1)
anchor_rotation = anchor_rotation.view(1, 1, 1, 1, -1, 1).repeat([*anchors.shape[0:3], num_anchor_size, 1, 1])
anchors = torch.cat((anchors, anchor_rotation), dim=-1) # [x, y, z, num_size, num_rot, 7]
anchors = anchors.permute(2, 1, 0, 3, 4, 5).contiguous()
#anchors = anchors.view(-1, anchors.shape[-1])
anchors[..., 2] += anchors[..., 5] / 2 # shift to box centers
all_anchors.append(anchors)
return all_anchors, num_anchors_per_location
3.Meanvfe
pcdet/models/backbones_3d/vfe/mean_vfe.py中的forward函数
主要功能:提取voxel内点云特征(对一个voxel内的所有点求平均值)
def forward(self, batch_dict, **kwargs):
"""
Args:
batch_dict:
voxels: (num_voxels, max_points_per_voxel, C)
voxel_num_points: optional (num_voxels)
**kwargs:
Returns:
vfe_features: (num_voxels, C)
"""
voxel_features, voxel_num_points = batch_dict['voxels'], batch_dict['voxel_num_points']
# 求每个voxel内 所有点的和
points_mean = voxel_features[:, :, :].sum(dim=1, keepdim=False)
# 正则化项, 保证每个voxel中最少有一个点,防止除0
normalizer = torch.clamp_min(voxel_num_points.view(-1, 1), min=1.0).type_as(voxel_features)
points_mean = points_mean / normalizer
batch_dict['voxel_features'] = points_mean.contiguous()
return batch_dict
4.Voxelbackbonx8x
pcdet/models/backbones_3d/spconv_backbone.py中的forward函数
**功能:**多层次提取voxel特征
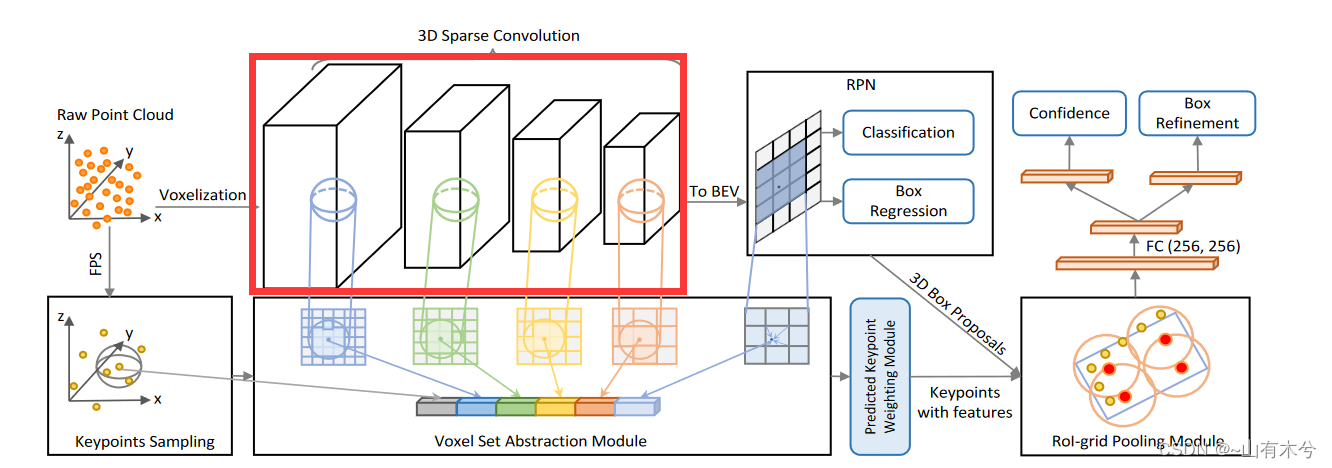
def forward(self, batch_dict):
"""
Args:
batch_dict:
batch_size: int
vfe_features: (num_voxels, C)
voxel_coords: (num_voxels, 4), [batch_idx, z_idx, y_idx, x_idx]
Returns:
batch_dict:
encoded_spconv_tensor: sparse tensor
"""
voxel_features, voxel_coords = batch_dict['voxel_features'], batch_dict['voxel_coords']
batch_size = batch_dict['batch_size']
input_sp_tensor = spconv.SparseConvTensor(
features=voxel_features,
indices=voxel_coords.int(),
spatial_shape=self.sparse_shape,
batch_size=batch_size
)
x = self.conv_input(input_sp_tensor)
x_conv1 = self.conv1(x)
x_conv2 = self.conv2(x_conv1)
x_conv3 = self.conv3(x_conv2)
x_conv4 = self.conv4(x_conv3)
# for detection head
# [200, 176, 5] -> [200, 176, 2]
out = self.conv_out(x_conv4)
batch_dict.update({
'encoded_spconv_tensor': out,
'encoded_spconv_tensor_stride': 8
})
batch_dict.update({
'multi_scale_3d_features': {
'x_conv1': x_conv1,
'x_conv2': x_conv2,
'x_conv3': x_conv3,
'x_conv4': x_conv4,
}
})
batch_dict.update({
'multi_scale_3d_strides': {
'x_conv1': 1,
'x_conv2': 2,
'x_conv3': 4,
'x_conv4': 8,
}
})
return batch_dict
5.heightcompression
pcdet/models/backbones_2d/map_to_bev/height_compression.py
功能:压缩voxel至BEV视图
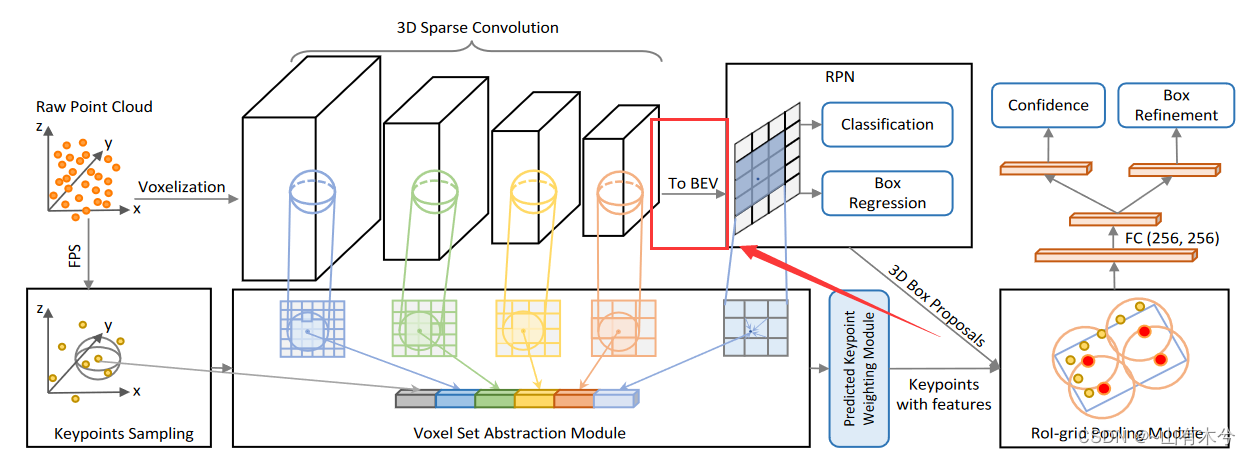
def forward(self, batch_dict):
"""
Args:
batch_dict:
encoded_spconv_tensor: sparse tensor
Returns:
batch_dict:
spatial_features:
"""
encoded_spconv_tensor = batch_dict['encoded_spconv_tensor']
spatial_features = encoded_spconv_tensor.dense()
N, C, D, H, W = spatial_features.shape
spatial_features = spatial_features.view(N, C * D, H, W)
batch_dict['spatial_features'] = spatial_features
batch_dict['spatial_features_stride'] = batch_dict['encoded_spconv_tensor_stride']
return batch_dict
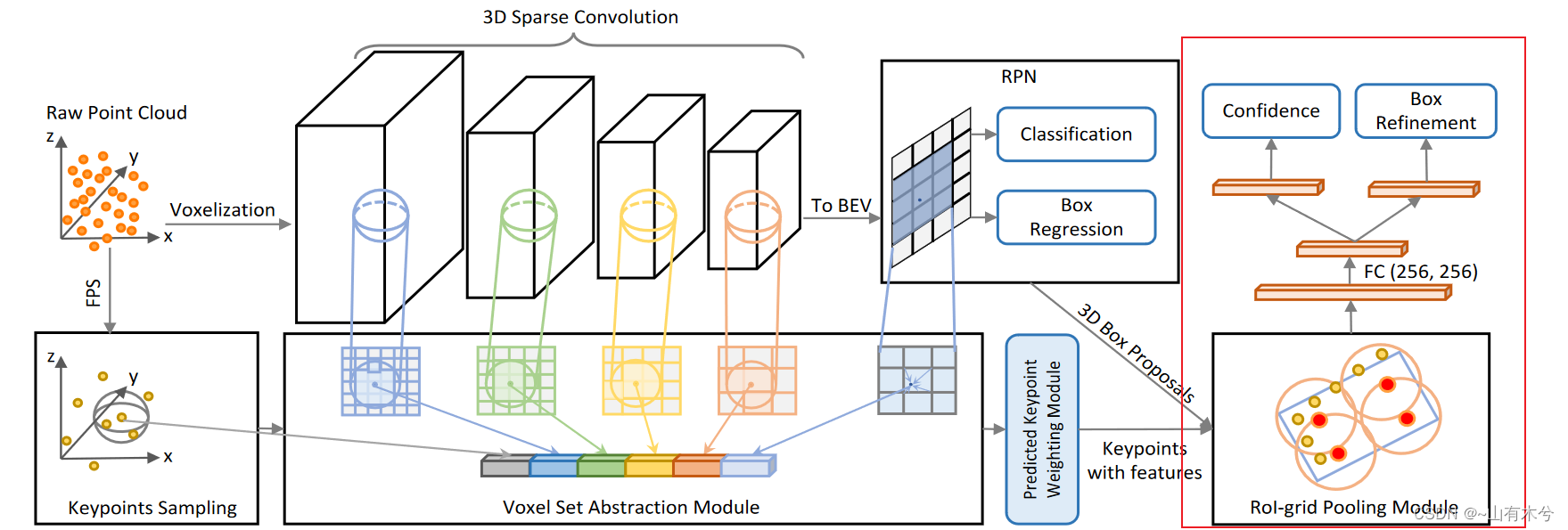
6.Voxel set Abstraction
pcdet/models/backbones_3d/pfe/voxel_set_abstraction.py
功能:执行Set Abstration模块以聚合特征
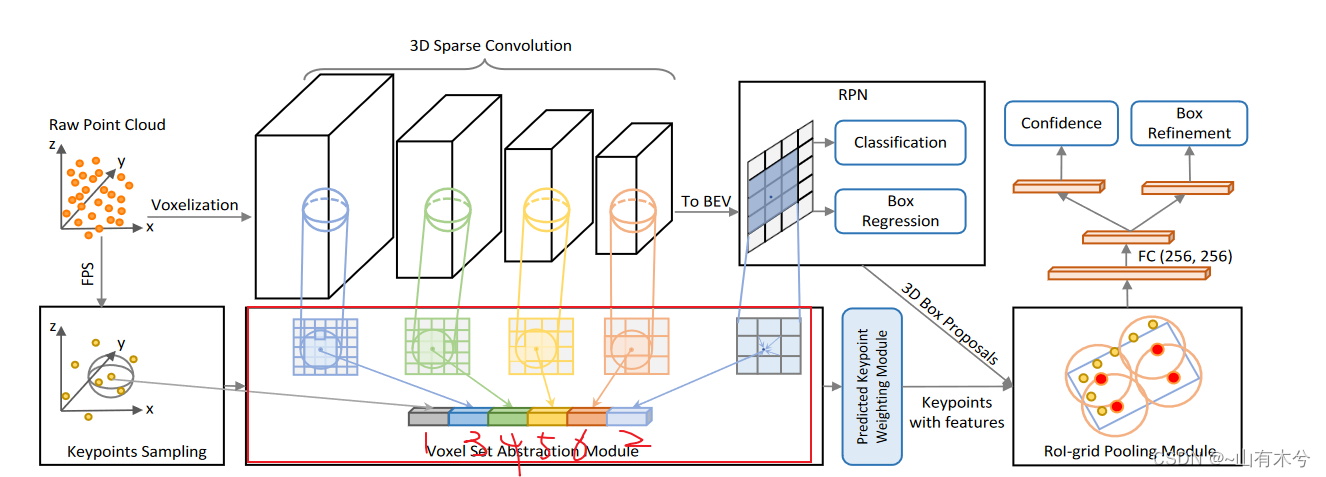
代码实现内容:
- 通过FPS获得关键点(kitti数据集中设置是2048个)
- 首先对关键点通过SA模块聚合特征,拼接到第一处
- 对BEV视图通过SA模块聚合特征,拼接到第二处
- 对经过不同比例稀疏卷积下采样的voxel分别进行VSA聚合,拼接到后面的位置
def forward(self, batch_dict):
"""
Args:
batch_dict:
batch_size:
keypoints: (B, num_keypoints, 3)
multi_scale_3d_features: {
'x_conv4': ...
}
points: optional (N, 1 + 3 + C) [bs_idx, x, y, z, ...]
spatial_features: optional
spatial_features_stride: optional
Returns:
point_features: (N, C)
point_coords: (N, 4)
"""
'''
通过最远点采样,获取每一帧点云的关键点
'''
keypoints = self.get_sampled_points(batch_dict)
'''
Extended VSA中对BEV插值SA操作
'''
point_features_list = []
if 'bev' in self.model_cfg.FEATURES_SOURCE:
# 通过对BEV的特征进行插值获取关键点的特征数据
point_bev_features = self.interpolate_from_bev_features(
keypoints, batch_dict['spatial_features'], batch_dict['batch_size'],
bev_stride=batch_dict['spatial_features_stride']
)
point_features_list.append(point_bev_features)
batch_size = batch_dict['batch_size']
new_xyz = keypoints[:, 1:4].contiguous()
new_xyz_batch_cnt = new_xyz.new_zeros(batch_size).int()
for k in range(batch_size):
new_xyz_batch_cnt[k] = (keypoints[:, 0] == k).sum()
if 'raw_points' in self.model_cfg.FEATURES_SOURCE:
raw_points = batch_dict['points']
pooled_features = self.aggregate_keypoint_features_from_one_source(
batch_size=batch_size, aggregate_func=self.SA_rawpoints,
xyz=raw_points[:, 1:4],
xyz_features=raw_points[:, 4:].contiguous() if raw_points.shape[1] > 4 else None,
xyz_bs_idxs=raw_points[:, 0],
new_xyz=new_xyz, new_xyz_batch_cnt=new_xyz_batch_cnt,
filter_neighbors_with_roi=self.model_cfg.SA_LAYER['raw_points'].get('FILTER_NEIGHBOR_WITH_ROI', False),
radius_of_neighbor=self.model_cfg.SA_LAYER['raw_points'].get('RADIUS_OF_NEIGHBOR_WITH_ROI', None),
rois=batch_dict.get('rois', None)
)
point_features_list.append(pooled_features)
"""
====================================
VSA中对不同尺度3D CNN的voxel-wise的操作
1x, 2x, 4x, 8x
====================================
POOL_RADIUS为该层对应的采样半径,
NSAMPLE为半径内最大的采样点数
x_conv1:
DOWNSAMPLE_FACTOR: 1
MLPS: [[16, 16], [16, 16]]
POOL_RADIUS: [0.4, 0.8]
NSAMPLE: [16, 16]
x_conv2:
DOWNSAMPLE_FACTOR: 2
MLPS: [[32, 32], [32, 32]]
POOL_RADIUS: [0.8, 1.2]
NSAMPLE: [16, 32]
x_conv3:
DOWNSAMPLE_FACTOR: 4
MLPS: [[64, 64], [64, 64]]
POOL_RADIUS: [1.2, 2.4]
NSAMPLE: [16, 32]
x_conv4:
DOWNSAMPLE_FACTOR: 8
MLPS: [[64, 64], [64, 64]]
POOL_RADIUS: [2.4, 4.8]
NSAMPLE: [16, 32]
=====================================
"""
for k, src_name in enumerate(self.SA_layer_names):
cur_coords = batch_dict['multi_scale_3d_features'][src_name].indices
cur_features = batch_dict['multi_scale_3d_features'][src_name].features.contiguous()
xyz = common_utils.get_voxel_centers(
cur_coords[:, 1:4], downsample_times=self.downsample_times_map[src_name],
voxel_size=self.voxel_size, point_cloud_range=self.point_cloud_range
)
pooled_features = self.aggregate_keypoint_features_from_one_source(
batch_size=batch_size, aggregate_func=self.SA_layers[k],
xyz=xyz.contiguous(), xyz_features=cur_features, xyz_bs_idxs=cur_coords[:, 0],
new_xyz=new_xyz, new_xyz_batch_cnt=new_xyz_batch_cnt,
filter_neighbors_with_roi=self.model_cfg.SA_LAYER[src_name].get('FILTER_NEIGHBOR_WITH_ROI', False),
radius_of_neighbor=self.model_cfg.SA_LAYER[src_name].get('RADIUS_OF_NEIGHBOR_WITH_ROI', None),
rois=batch_dict.get('rois', None)
)
point_features_list.append(pooled_features)
point_features = torch.cat(point_features_list, dim=-1)
batch_dict['point_features_before_fusion'] = point_features.view(-1, point_features.shape[-1])
point_features = self.vsa_point_feature_fusion(point_features.view(-1, point_features.shape[-1]))
batch_dict['point_features'] = point_features # (BxN, C)
batch_dict['point_coords'] = keypoints # (BxN, 4)
return batch_dict
7.basebackbone
pcdet/models/backbones_2d/base_bev_backbone.py中的forward函数
参照pointpillars的检测头对下采样后的特征进行反卷积后拼接在一起
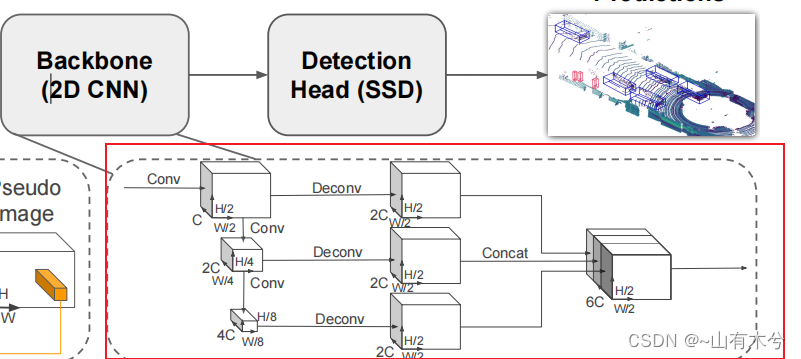
def forward(self, data_dict):
"""
Args:
data_dict:
spatial_features
Returns:
"""
spatial_features = data_dict['spatial_features']
ups = []
ret_dict = {}
x = spatial_features
for i in range(len(self.blocks)):
x = self.blocks[i](x)
stride = int(spatial_features.shape[2] / x.shape[2])
ret_dict['spatial_features_%dx' % stride] = x
if len(self.deblocks) > 0:
ups.append(self.deblocks[i](x))
else:
ups.append(x)
if len(ups) > 1:
x = torch.cat(ups, dim=1)
elif len(ups) == 1:
x = ups[0]
if len(self.deblocks) > len(self.blocks):
x = self.deblocks[-1](x)
data_dict['spatial_features_2d'] = x
return data_dict
8.AnchorheadAingle
pcdet/models/dense_heads/anchor_head_single.py中的forward函数
功能:
生成6个anchor(每个类别两个anchor,包含两个方向)的类别、微调框参数、方向预测参数
训练模式:
计算之前生成的anchor与每个GT计算IOU
并为每个anchor分配最大的IOU对应的GT
并将生成的参数,包括微调框参数微调生成的anchor数
测试模式:
将生成的参数直接生成的anchor上作为逼近GT的anchor
理解
def forward(self, data_dict):
# spatial_features_2d 维度 (batch_size, 512, 200, 176)
spatial_features_2d = data_dict['spatial_features_2d']
# 每个点上面6个先验框的类别预测 --> (batch_size, 18, 200, 176)
cls_preds = self.conv_cls(spatial_features_2d)
# 每个坐标点上面6个先验框的参数预测 --> (batch_size, 42, 200, 176) 其中每个先验框需要预测7个参数,分别是(x, y, z, w, l, h, θ)
box_preds = self.conv_box(spatial_features_2d)
# 维度调整,将类别放置在最后一维度 [N, H, W, C] --> (batch_size, 200, 176, 18)
cls_preds = cls_preds.permute(0, 2, 3, 1).contiguous()
# 维度调整,将先验框调整参数放置在最后一维度 [N, H, W, C] --> (batch_size ,200, 176, 42)
box_preds = box_preds.permute(0, 2, 3, 1).contiguous()
self.forward_ret_dict['cls_preds'] = cls_preds
self.forward_ret_dict['box_preds'] = box_preds
# 进行方向分类预测
if self.conv_dir_cls is not None:
#每个先验框都要预测为两个方向中的其中一个方向 --> (batch_size, 12, 200, 176)
dir_cls_preds = self.conv_dir_cls(spatial_features_2d)
# 将先验框方向预测结果放到最后一个维度中 [N, H, W, C] --> (batch_size, 248, 216, 12)
dir_cls_preds = dir_cls_preds.permute(0, 2, 3, 1).contiguous()
self.forward_ret_dict['dir_cls_preds'] = dir_cls_preds
else:
dir_cls_preds = None
"""
如果是在训练模式的时候,需要对每个先验框分配GT来计算loss
"""
if self.training:
targets_dict = self.assign_targets(
gt_boxes=data_dict['gt_boxes']
)
self.forward_ret_dict.update(targets_dict)
# 如果不是训练模式,则直接生成进行box的预测
if not self.training or self.predict_boxes_when_training:
batch_cls_preds, batch_box_preds = self.generate_predicted_boxes(
batch_size=data_dict['batch_size'],
cls_preds=cls_preds, box_preds=box_preds, dir_cls_preds=dir_cls_preds
)
data_dict['batch_cls_preds'] = batch_cls_preds
data_dict['batch_box_preds'] = batch_box_preds
data_dict['cls_preds_normalized'] = False
return data_dict
9.PointHeadSimple
pcdet/models/dense_heads/point_head_simple.py中的forward函数
功能:预测关键点是前景还是背景,并通过softmax函数计算非负概率
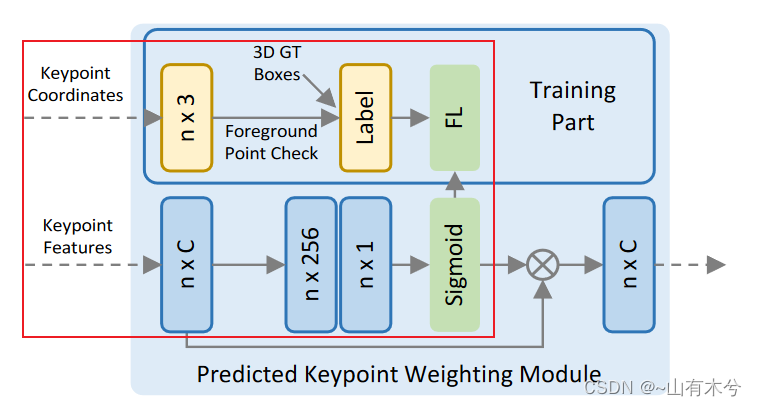
def forward(self, batch_dict):
"""
Args:
batch_dict:
batch_size:
point_features: (N1 + N2 + N3 + ..., C) or (B, N, C)
point_features_before_fusion: (N1 + N2 + N3 + ..., C)
point_coords: (N1 + N2 + N3 + ..., 4) [bs_idx, x, y, z]
point_labels (optional): (N1 + N2 + N3 + ...)
gt_boxes (optional): (B, M, 8)
Returns:
batch_dict:
point_cls_scores: (N1 + N2 + N3 + ..., 1)
point_part_offset: (N1 + N2 + N3 + ..., 3)
"""
if self.model_cfg.get('USE_POINT_FEATURES_BEFORE_FUSION', False):
point_features = batch_dict['point_features_before_fusion']
else:
point_features = batch_dict['point_features']
point_cls_preds = self.cls_layers(point_features) # (total_points, num_class)
ret_dict = {
'point_cls_preds': point_cls_preds,
}
point_cls_scores = torch.sigmoid(point_cls_preds)
batch_dict['point_cls_scores'], _ = point_cls_scores.max(dim=-1)
if self.training:
targets_dict = self.assign_targets(batch_dict)# 训练模型下,需要对关键点预测进行target assignment, 前景为1, 背景为0,(这里前景应该是关键点落入groud truth框内的点?)
ret_dict['point_cls_labels'] = targets_dict['point_cls_labels']# 存储所有关键点属于前背景的mask
self.forward_ret_dict = ret_dict
return batch_dict
其中特征和前景点概率相乘实现在pcdet/models/roi_heads/pvrcnn_head.py中的roi_grid_pool函数

10.PVRCNN Head
pcdet/models/roi_heads/pvrcnn_head.py中的forward函数
功能:
- 生成一定数目的proposal
- 计算proposal和GT的IOU值,并为每一个proposal分配一个最大值IOU的GT框
- 进行ROI池化(666大小的池化,聚合特征)
- 对经过ROI pooling之后的proposal进行类别置信度预测和框回归参数
def forward(self, batch_dict):
"""
:param input_data: input dict
:return:
"""
targets_dict = self.proposal_layer(
batch_dict, nms_config=self.model_cfg.NMS_CONFIG['TRAIN' if self.training else 'TEST']
)
if self.training:
targets_dict = batch_dict.get('roi_targets_dict', None)
if targets_dict is None:
targets_dict = self.assign_targets(batch_dict)
batch_dict['rois'] = targets_dict['rois']
batch_dict['roi_labels'] = targets_dict['roi_labels']
# RoI aware pooling
pooled_features = self.roi_grid_pool(batch_dict) # (BxN, 6x6x6, C)
grid_size = self.model_cfg.ROI_GRID_POOL.GRID_SIZE
batch_size_rcnn = pooled_features.shape[0]
pooled_features = pooled_features.permute(0, 2, 1).\
contiguous().view(batch_size_rcnn, -1, grid_size, grid_size, grid_size) # (BxN, C, 6, 6, 6)
shared_features = self.shared_fc_layer(pooled_features.view(batch_size_rcnn, -1, 1))
rcnn_cls = self.cls_layers(shared_features).transpose(1, 2).contiguous().squeeze(dim=1) # (B, 1 or 2)
rcnn_reg = self.reg_layers(shared_features).transpose(1, 2).contiguous().squeeze(dim=1) # (B, C)
if not self.training:
batch_cls_preds, batch_box_preds = self.generate_predicted_boxes(
batch_size=batch_dict['batch_size'], rois=batch_dict['rois'], cls_preds=rcnn_cls, box_preds=rcnn_reg
)
batch_dict['batch_cls_preds'] = batch_cls_preds
batch_dict['batch_box_preds'] = batch_box_preds
batch_dict['cls_preds_normalized'] = False
else:
targets_dict['rcnn_cls'] = rcnn_cls
targets_dict['rcnn_reg'] = rcnn_reg
self.forward_ret_dict = targets_dict
return batch_dict


















 992
992

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









