







 博客围绕迭代自适应动态规划展开,针对一般最优控制难获解析解的问题,介绍了值迭代方法。阐述了值迭代基本思想与实现过程,证明了迭代收敛性,还指出系统存在ui不一定使系统稳定的问题,并提及改进值迭代方法,如推广初始条件等。
博客围绕迭代自适应动态规划展开,针对一般最优控制难获解析解的问题,介绍了值迭代方法。阐述了值迭代基本思想与实现过程,证明了迭代收敛性,还指出系统存在ui不一定使系统稳定的问题,并提及改进值迭代方法,如推广初始条件等。
自适应动态规划
2. 迭代自适应动态规划
面对的问题:
一般最优控制很难直接得到解析解,因此需要想办法得到数值解:
原先应用Bellman最优原理时,最后一步 N N N时刻状态已知,但当最后一步变成无限域的第 ∞ \infty ∞步时,应该怎么求解最优性能指标(找到方程的解)?
解决方式:
可以通过值迭代和策略迭代的方法实现求解。
2.1 值迭代基本思想
如何迭代?
从Bellman动态规划算法出发,目的是求解最优控制下的性能指标(值函数):
V ( x k ) = m i n u k [ g D ( x k , u k ) + V ( x k + 1 ) ] V(x_k)=min_{u_k}[g_D(x_k,u_k)+V(x_{k+1})] V(xk)=minuk[gD(xk,uk)+V(xk+1)]
对于该方程的解,求解思想是:固定 x k x_k xk,能否将其改写成 V ( x k ) = f ( V ) V(x_k)=f(V) V(xk)=f(V)的形式,利用迭代计算逼近最优解 V V V?
实现:
给定任意初值 V 0 V_0 V0时,若通过 x = f ( x ) x=f(x) x=f(x)的无限次迭代
V 1 ( x k ) = f ( V 0 ( x k ) ) V 2 ( x k ) = f ( V 1 ( x k ) ) . . . V ∞ ( x k ) = V N − 1 ( x k ) V_1(x_k)=f(V_0(x_k))\\ V_2(x_k)=f(V_1(x_k))\\ ...\\ V_\infty(x_k)= V_{N-1}(x_k) V1(xk)=f(V0(xk))V2(xk)=f(V1(xk))...V∞(xk)=VN−1(xk)
最终收敛,则必定达到最优解 V ( x k ) = f ( V ) V(x_k)=f(V) V(xk)=f(V)。
(本质上是神经网络更新权重)
2.2 值迭代的实现过程
根据值迭代的基本思想,先推导 x = f ( x ) x=f(x) x=f(x)的实现过程:
令近似的初始值函数为:
V 0 ( ⋅ ) ≡ 0 V_0(·)≡0 V0(⋅)≡0
初始迭代控制率为:
u 0 ( x k ) = a r g m i n u k [ g D ( x k , u k ) + V 0 ( x k + 1 ) ] u_0(x_k)=argmin_{u_k}[g_D(x_k,u_k)+V_0(x_{k+1})] u0(xk)=argminuk[gD(xk,uk)+V0(xk+1)]
由 x k + 1 = f ( x k , u k ) x_{k+1}=f(x_k,u_k) xk+1=f(xk,uk),根据Bellman最优原理,可得迭代的近似性能指标函数:
V 1 ( x k ) = g D ( x k , u 0 ( x k ) ) + V 0 ( f D ( x k , u 0 ( x k ) ) ) V_1(x_k)\\=g_D(x_k,u_0(x_k))+V_0(f_D(x_k,u_0(x_k))) V1(xk)=gD(xk,u0(xk))+V0(fD(xk,u0(xk)))
进而,推广到 i = 1 , 2 , . . . , k i=1,2,...,k i=1,2,...,k,获得迭代控制率:
u i ( x k ) = a r g m i n u k [ g D ( x k , u k ) + V i ( x k + 1 ) ] u_i(x_k)=argmin_{u_k}[g_D(x_k,u_k)+V_i(x_{k+1})] ui(xk)=argminuk[gD(xk,uk)+Vi(xk+1)]
(原理上是括号里的函数对 u k u_k uk求偏导,得到函数最小时 u k u_k uk的形式)
和更新性能指标函数:
V i + 1 ( x k ) = g D ( x k , u i ( x k ) ) + V i ( f D ( x k , u i ( x k ) ) ) V_{i+1}(x_k)\\=g_D(x_k,u_i(x_k))+V_i(f_D(x_k,u_i(x_k))) Vi+1(xk)=gD(xk,ui(xk))+Vi(fD(xk,ui(xk)))
原理:
由于在k时刻下的状态 x k x_k xk不变,且满足关系 x k + 1 = f ( x k , u k ) x_{k+1}=f(x_k,u_k) xk+1=f(xk,uk),因此对于k时刻下的不同的近似控制率 u i u_i ui,可以得到不同的 x k + 1 x_{k+1} xk+1和 V ( x k + 1 ) V(x_{k+1}) V(xk+1),进而可以得到不同的近似性能指标函数 V i ( x k ) V_i(x_k) Vi(xk),当找到最优控制率时,无论怎么迭代最优性能指标应该接近,即迭代过程中的 V i → ∞ ( x k ) V_{i\rightarrow\infty}(x_k) Vi→∞(xk)应与前一步 V i → ∞ − 1 ( x k ) V_{i\rightarrow\infty-1}(x_k) Vi→∞−1(xk)约等,即收敛,找到了Bellman最优方程的解,同时相当于找到了 k k k时刻的最优控制率和最优性能指标(值函数)。
其流程图如下:
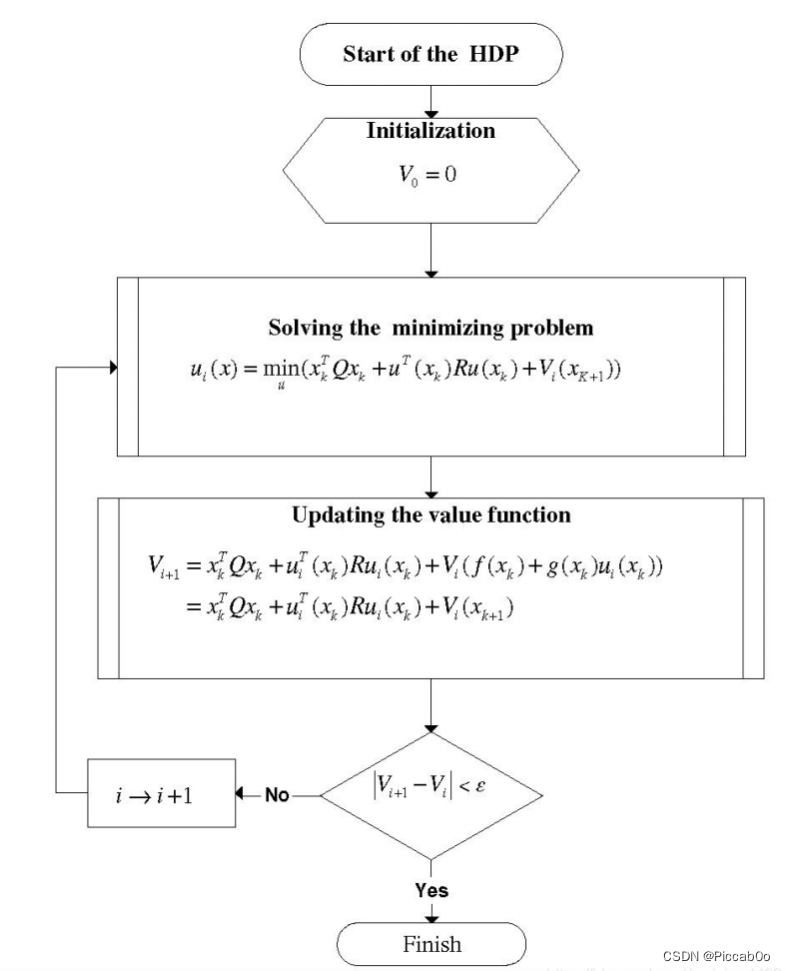
2.3 证明迭代的收敛性以应用
为了使用值迭代,还需要证明其收敛性:
即只需要证明:“函数序列{ V i V_i Vi}是单调非减且有上界的”,则极限 V ∞ ( x k ) V_\infty(x_k) V∞(xk)一定存在,并且其会收敛到最优控制下的值函数 V ( x k ) V(x_k) V(xk),即满足:
l i m i → ∞ V i ( x k ) = V ( x k ) lim_{i\rightarrow\infty}V_i(x_k)=V(x_k) limi→∞Vi(xk)=V(xk)
一般,有三种方法证明,此处使用辅助函数法:
① 辅助函数 Λ \Lambda Λ:证明有界
对于任意控制率 μ i ( x k ) \mu_i(x_k) μi(xk)及对应的性能指标:
Λ i + 1 ( x k ) = g D ( x k , μ i ( x k ) ) + Λ i ( x k + 1 ) \Lambda_{i+1}(x_k)=g_D(x_k,\mu_i(x_k))+\Lambda_{i}(x_{k+1}) Λi+1(xk)=gD(xk,μi(xk))+Λi(xk+1)
其中, Λ 0 = V 0 = 0 \Lambda_0=V_0=0 Λ0=V0=0, ∀ i \forall i ∀i,可以证明出最优性能指标满足:
V i ( x k ) ≤ Λ i ( x k ) V_i(x_k)\leq\Lambda_i(x_k) Vi(xk)≤Λi(xk)
证:
根据Bellman最优原理,有最优性能指标:
V i + 1 ( x k ) = m i n [ g D ( x k , u k ) + V i ( x k + 1 ) ] V_{i+1}(x_k)=min[g_D(x_k,u_k)+V_i(x_{k+1})] Vi+1(xk)=min[gD(xk,uk)+Vi(xk+1)]
= g D ( x k , u i ) + V i ( x k + 1 ) =g_D(x_k,u_i)+V_i(x_{k+1}) =gD(xk,ui)+Vi(xk+1)
≤ g D ( x k , u i ) + Λ i ( x k + 1 ) = Λ i + 1 ( x k ) \leq g_D(x_k,u_i)+\Lambda_i(x_{k+1})=\Lambda_{i+1}(x_k) ≤gD(xk,ui)+Λi(xk+1)=Λi+1(xk)
得证。
② 辅助函数 Z Z Z:证明有上界
若系统可控,则存在上界 Y Y Y使得: 0 ≤ V i ( x k ) ≤ Y 0 \leq V_i(x_k) ≤ Y 0≤Vi(xk)≤Y
证:
对于容许控制率,其满足两个条件:
1)将容许控制率应用于系统,系统是稳定的;
2) 系统的性能指标 J = Σ i = 0 ∞ ( X T Q X + U i T R U i ) < Y < ∞ J=\Sigma_{i=0}^\infty (X^TQX+U_i^TRU_i)<Y<\infty J=Σi=0∞(XTQX+UiTRUi)<Y<∞
令 η \eta η是容许控制率,则有:
Z i + 1 ( x k ) = g D ( x k , η ) + Z i ( x k + 1 ) Z_{i+1}(x_k)=g_D(x_k,\eta)+Z_i(x_{k+1}) Zi+1(xk)=gD(xk,η)+Zi(xk+1)
Z i ( x k ) = g D ( x k , η ) + Z i − 1 ( x k + 1 ) Z_i(x_k)=g_D(x_k,\eta)+Z_{i-1}(x_{k+1}) Zi(xk)=gD(xk,η)+Zi−1(xk+1)
两者做差有:
Z i + 1 ( x k ) − Z i ( x k ) = Z i ( x k + 1 ) − Z i − 1 ( x k + 1 ) Z_{i+1}(x_k)-Z_i(x_k)=Z_i(x_{k+1})-Z_{i-1}(x_{k+1}) Zi+1(xk)−Zi(xk)=Zi(xk+1)−Zi−1(xk+1)
= Z i − 1 ( x k + 2 ) − Z i − 2 ( x k + 2 ) = . . . = Z 1 ( x k + i ) − Z 0 ( x k + i ) =Z_{i-1}(x_{k+2})-Z_{i-2}(x_{k+2})=...=Z_1(x_{k+i})-Z_0(x_{k+i}) =Zi−1(xk+2)−Zi−2(xk+2)=...=Z1(xk+i)−Z0(xk+i)
因此可得:
Z i + 1 ( x k ) = Z i ( x k ) + Z 1 ( x k + i ) Z_{i+1}(x_k)=Z_i(x_k)+Z_1(x_{k+i}) Zi+1(xk)=Zi(xk)+Z1(xk+i)
Z i ( x k ) = Z i − 1 ( x k ) + Z 1 ( x k + i − 1 ) Z_i(x_k)=Z_{i-1}(x_k)+Z_1(x_{k+i-1}) Zi(xk)=Zi−1(xk)+Z1(xk+i−1)
. . . ... ...
Z 1 ( x k ) = Z 0 ( x k ) + Z 1 ( x k ) Z_1(x_k)=Z_0(x_k)+Z_1(x_{k}) Z1(xk)=Z0(xk)+Z1(xk)
对上式累加可得:
Z i + 1 ( x k ) = Σ j = 0 i Z 1 ( x k + j ) Z_{i+1}(x_k)=\Sigma_{j=0}^iZ_1(x_{k+j}) Zi+1(xk)=Σj=0iZ1(xk+j)
又因为:
Z 1 ( x k ) = g D ( x k , η ( x k ) ) Z_1(x_k)=g_D(x_k,\eta(x_k)) Z1(xk)=gD(xk,η(xk))
因此,当 i → ∞ i\rightarrow\infty i→∞时,有:
Z ∞ ( x k ) = Σ j = 0 ∞ g D ( x k + j , η ( x k + j ) ) Z_\infty(x_k)=\Sigma_{j=0}^\infty g_D(x_{k+j},\eta(x_{k+j})) Z∞(xk)=Σj=0∞gD(xk+j,η(xk+j))
对于容许控制率, J J J一定有界,因此上式一定满足:
Z ∞ ( x k ) < Y < ∞ Z_\infty(x_k)<Y<\infty Z∞(xk)<Y<∞
进一步的有:
V i ( x k ) ≤ Z i ( x k ) < Y V_i(x_k)\leq Z_i(x_k)<Y Vi(xk)≤Zi(xk)<Y
得证。
③ 辅助函数 ϕ \phi ϕ:证明单调递增
∀ i , x k \forall i,x_k ∀i,xk,有 V i ( x k ) ≤ V i + 1 ( x k ) V_i(x_k)\leq V_{i+1}(x_k) Vi(xk)≤Vi+1(xk)
对辅助函数:
ϕ i + 1 ( x k ) = g D ( x k , u i + 1 ( x k ) ) + ϕ i ( x k + 1 ) \phi_{i+1}(x_k)=g_D(x_k,u_{i+1}(x_k))+\phi_i(x_{k+1}) ϕi+1(xk)=gD(xk,ui+1(xk))+ϕi(xk+1)
令 ϕ 0 ( x k ) = 0 \phi_0(x_k)=0 ϕ0(xk)=0,则:
V 1 ( x k ) = g D ( x k , u 0 ) + V 0 ( x k + 1 ) ≥ ϕ 0 ( x k ) V_1(x_k)=g_D(x_k,u_0)+V_0(x_{k+1})\geq\phi_0(x_k) V1(xk)=gD(xk,u0)+V0(xk+1)≥ϕ0(xk)
假设 V l ≥ ϕ l − 1 V_l\geq\phi_{l-1} Vl≥ϕl−1,对 l = 1 , 2 , . . . l=1,2,... l=1,2,...
因为: V i + 1 ( x k ) = m i n [ g D + V i ] ≥ m i n [ g D + V i − 1 ] = V i ( x k ) V_{i+1}(x_k)=min[g_D+V_i]\geq min[g_D+V_{i-1}]=V_i(x_k) Vi+1(xk)=min[gD+Vi]≥min[gD+Vi−1]=Vi(xk)
则对:
V l + 1 ( x k ) = g D ( x k , u l ) + V l ( x k + 1 ) V_{l+1}(x_k)=g_D(x_k,u_l)+V_l(x_{k+1}) Vl+1(xk)=gD(xk,ul)+Vl(xk+1)
ϕ l ( x k ) = g D ( x k , u l ) + V l − 1 ( x k + 1 ) \phi _l(x_k)=g_D(x_k,u_l)+V_{l-1}(x_{k+1}) ϕl(xk)=gD(xk,ul)+Vl−1(xk+1)
对于最优控制 V l V_l Vl,一定有: V l + 1 ( x k ) ≥ ϕ l ( x k ) ≥ V l ( x k ) V_{l+1}(x_k)\geq\phi_l(x_k)\geq V_l(x_k) Vl+1(xk)≥ϕl(xk)≥Vl(xk)
得证。
2.4 系统的问题
u i u_i ui不一定能使系统稳定,只有迭代次数足够多的时候才有可能使系统稳定
2.5改进值迭代方法:
经典值迭代方法中,初始条件 V 0 ( x k ) = 0 V_0(x_k)=0 V0(xk)=0,可以证明:
V i ( x k ) → V ( x k ) V_i(x_k)\to V(x_k) Vi(xk)→V(xk)
u i ( x k ) → u ∗ ( x k ) u_i(x_k)\to u^*(x_k) ui(xk)→u∗(xk)
广义值迭代将初始条件推广至任意的正半定函数:
V 0 ( x k ) = Φ ( x k ) V_0(x_k)=\Phi(x_k) V0(xk)=Φ(xk)
我们的目的是让Vi逼近J*,没必要找Vi和Vi+1的关系
因此能不能找到J*上界和下界δ,两界收敛,则Vi+1出来了
难点是系数不一样,让系数一样凑系数
若F>=0满足成立,则式子成立
再来一次,找一找有没有统一的规律


















 3356
3356

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









