




MYSQL数据库基础
- 数据库(DataBase):是一个按数据结构来存储和管理数据的计算机软件系统,数据库就是一些文件
- 数据库管理系统(DBMS):是专门用于管理数据库的计算机系统软件。数据库管理系统能够为数据库提供数据的定义、建立、维护、查询、和统计等操作功能,并完成对数据完整性、安全性进行控制的功能
- 数据库应用系统(DBAS):就是使用数据库技术的系统数据库应用系统有很多,基本上所有的信息系统都是数据库应用系统。它通常由软件、数据库和数据管理员组成。
- 数据管理员(DBA):负责创建、监控和维护整个数据库,使数据能被任何有权使用的人有效使用。数据库管理员一般是由业务水平较高,资历较深的人员担任
主流的关系型数据库
• Oracle:运行稳定、可移植性高、功能齐全、性能超群,适用于大型企业
• DB2:速度快、可靠性好、适用于海量数据、恢复性极强,适用于大中型企业
• MySQL:开源、体积小、速度快,适用于中小型企业
• SQL server:全面高效、界面友好易操作,但是不跨平台,适用于中小型企业
SQL是一种结构化查询语言(Structure Query Language),它是国际
标准化组织采纳的标准数据库语言。
SQL语言分类
- • 数据定义语言DDL:用于创建,修改,删除数据库中的各种对象(数据库、表、视图、索引等),常用命令有CREATE,ALTER,DROP
- • 数据操作语言DML:用于操作数据库表中的记录,常用命令有INSERT,UPDATE,DELETE
- • 数据查询语言DQL:用于查询数据库表中的记录,基本结构:SELECT <字段名> FROM <表或视图名> WHERE <查询条件>
- • 数据控制语言DCL:用于定义数据库访问权限和安全级别,常用命令:GRANT,REVOKE
SQL书写要求
• SQL语句可以单行或多行书写,用分号结尾
• SQL关键字用空格分隔,也可以用缩进来增强语句的可读性
• SQL对大小写不敏感
• 用#或-- 单行注释,用/* */多行注释,注释语句不可执行
数据定义语言DDL
数据库的增删改查
- 查看数据库:show databases;
- 创建数据库:create databases 数据库名称;
数据库名称不能与SQL关键字相同,也不能重复 - 选择使用数据库:use 数据库名称
- 删除数据库:drop database 数据库名称
数据库基本结构
- 数据库:组织、存储和管理相关数据的集合,同一个数据库管理中数据库名必须唯一
- 表:由固定列数和任意行数构成的二维表结构的数据集,同一个数据库中表名必须唯一
- 字段:一列即为一个字段,同一个表中字段名必须唯一
- 记录:一行即为一条记录
- 以字段为基本存储和计算单位,每个字段的数据类型必须一致
数据表的增删查改
- 创建数据表:create table 表名
!建立表之前先选择进入数据库:use 数据库名称 - 查看所有表:show tables
- 查看表结构:desc 表名
- 删除数据表:drop table 表名
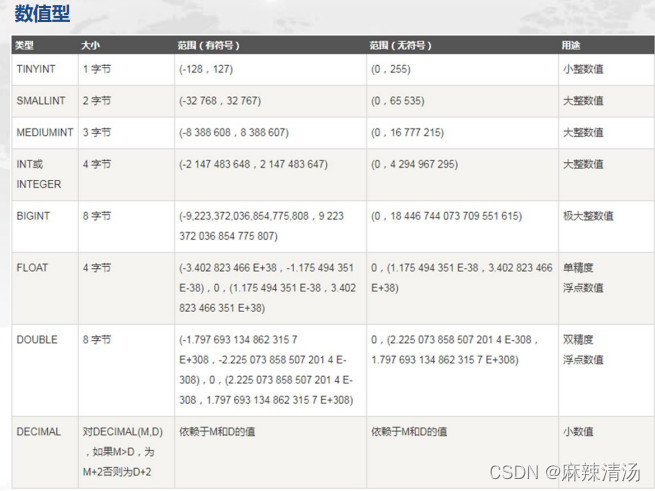
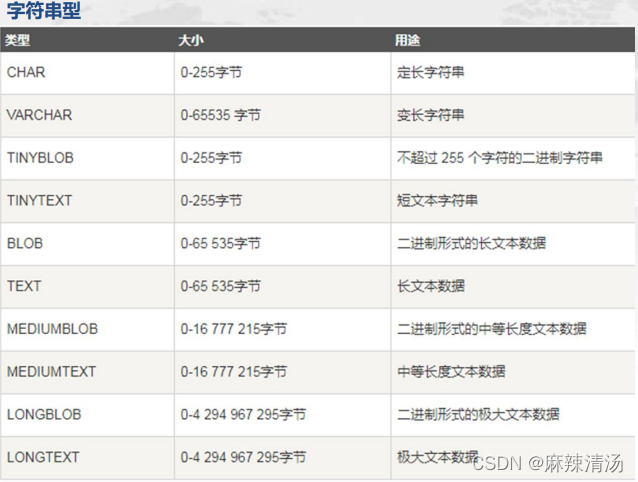
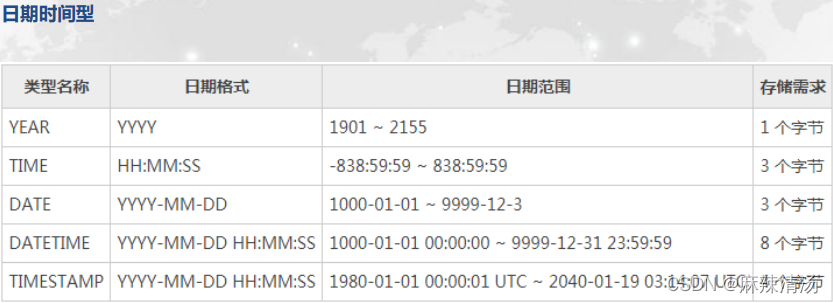
MySQL常用数据类型
• int:大整数型,有符号大小-2147483648~2147483647, 无符号大小0~4294967295,默认长度最多为11个数字,如int(11)
• float:单精度浮点型,默认float(10,2),表示最多10个数字,其中有2位小数
• decimal:十进制小数型,适合金额、价格等对精度要求较高的数据存储。默认decimal(10,0),表示最多10位数字,其中0位小数。
• char:固定长度字符串型,长度为1-255。如果长度小于指定长度,右边填充空格。如果不指定长度,默认为1。如char(10),‘abc ’
• varchar:可变长度字符串型,长度为1-255。必须指定长度,如varchar(10),‘abc’
• text:长文本字符串型,最大长度65535,不能指定长度
• date:日期型,‘yyyy-MM-dd’
• time:时间型,‘hh:mm:ss’
• datetime:日期时间型,‘yyyy-MM-dd hh:mm:ss’
• Timestamp:时间戳,在1970-01-01 00:00:00和2037-12-31 23:59:59之间,如1973-12-30 15:30,时间戳为:19731230153000
约束条件
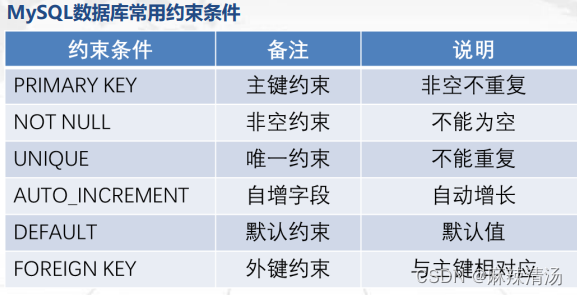
1.主键约束(primary key)
-
每个表中只能有一个主键
-
主键值须非空不重复
-
可设置单字段主键,也可设置多字段联合主键
(联合主键中多个字段的取值完全相同时,才违反主键约束) -
添加主键约束
列级添加主键约束
create table 表名(
字段名1 字段类型1 primary key,
...)
表级添加主键约束
create table 表名(
字段名1 字段类型1 ,
...,
primary key(字段名1[,字段名2]));
2.唯一约束(unique)
- 指定字段的取值不能重复,可以为空,但只能出现一个空值
3.自动增长列(auto_increment)
- 指定字段的取值自动生成,默认从1开始,每增加一条记录,该字段的取值会加1
- 只适用于整数型,配合主键一起使用
创建自动增长约束
create table 表名(
字段名1 字段类型1 primary key auto_increment,
...);
4.非空约束(not null)
- 字段的取值不能为空
5.默认约束(default)
- 如果新插入一条记录时没有为该字段赋值,系统就会自动为这个字段赋值为默认约束设定的值
6.外键约束(foreign key)
在一张表中执行插入、更新、删除等操作时,DBMS都会跟另一张表进行对照,避免不规范的操作,以确保数据存储的完整性
- 某一表中的某字段的值依赖于另一张表中某字段的值
- 主键所在的表为主表,外键所在的表为从表
- 每一个外键值必须与另一个表中的主键值相对应
创建外键约束
create table 表名(
字段名1 字段类型1,
...,
foreign key(字段名) references 主表名(主键字段));
修改数据表(alter)
修改数据库中已经存在的数据表的结构
- 修改表名(rename)
alter table 原表名
rename 新表名
- 修改字段名
alter table 表名
change 原字段名 新字段名 数据类型 [自增/非空/默认] [字段位置]
- 修改字段类型
alter table 表名
modify 字段名 新数据类型 [自增/非空/默认] [字段位置]
- 添加字段(add)
alter table 表名
add 字段名 字段类型
- 修改字段的排列位置
alter table 表名 modify 字段名 数据类型 first:
alter table 表名 modify 目标字段名 数据类型 after 参照字段
- 删除字段
alter table 表名 drop 字段名;
数据操作语言DML
插入数据
字段名与字段值的数据类型、个数、顺序必须一一对应
- 指定字段名插入;
insert into 表名(
字段名1[,字段值2,...] values(字段值1[字段值2,...]
...);
- 不指定字段名插入;
insert into 表名 values(字段值1[,字段值2,...]);
需要为表中的每一个字段指定值,且值的顺序须和数据表中的顺序相同
- • 批量导入数据:(路径中不能有中文,并且要将‘\’改为‘\’或‘/’)
load data infile ‘文件路径.csv’into table 表名[ fields terminated
by ‘,’ ignore 1 lines];
更新数据
update 表名
set 字段名1 =字段值1[,字段名2=字段值2[,...]]
[where 条件];
删除数据
1.delete
delete from 表名 where [删除条件]
2.truncate
truncate 和delete from 一样,都是删除表中全部数据,保留表结构。
truncate 表名
区别
- 语法上:delete可以添加where 条件删除
- 原理上:delete是一行一行检索删除,速度较慢;truncate是直接把表删除(drop table)然后再创建一个新表(create table),执行速度比delete快。
DQL
单表查询
全表查询:select * from 表名;
-
查询指定列:select 字段 1.2.3 from 表名
-
别名的设置
select 字段名 [as] 列别名
from 原表名 [as] 表别名;
- 查询不重复的记录(distinct +字段名)必须放在开头
条件查询
select 字段1.。。 from 表名
where 查询条件
空值查询
select 字段1.。。 from 表名
where 空值字段 is [not] null;
模糊查询(只能用于字符串类型)
- 百分号(%):匹配多个任意字符
- 下划线( _ ) : 匹配一个任意字符
select 字段1.。。 from 表名
where 字符串字段 [not] like 通配符;
排序字段(默认asc升序,desc降序)
- 多字段排序时,先按第一个字段排序,第一个字段内再按第二个字段排序。
select 字段1.。。
from 表名
order by 字段1 [排序方向,字段2 排序方向,...]
限制查询数量
- 偏移量:去除前面n个,从n+1个开始计数(默认是0)
- 可能会涉及到开窗函数(请看主页)
select 字段1.。。
from 表名
limit [偏移量],行数;
分组查询
- 将查询结果按照一个或多个字段进行分组,字段值相同的为一组
- 因为相当于去重操作,所以只产生一个字段,那个字段肯定是聚合字段
- 在进行分组之前也可以先进行筛选where
select 字段1.。。
from 表名
[where 查询条件]
group by 分组字段1[,分组字段2.。。] #多字段分组
having 筛选条件;
-
having 是根据筛选条件筛选出所需要的组
-
where 与having的区别
-where子句作用与表,having子句作用于组-where条件查询的作用域是针对数据表进行筛选,having对分组结果进行过滤
-where 在分组和聚合计算之前筛选出行,而having在分组和聚合之后筛选分组的行,因此where子句不能包含聚合函数
多表查询

- 一表作为主表可以保证维度的完整性
- 多表作为主表可以保证度量的准确性
- 在没有明确表示需要保证维度完整性时,优先保证度量值所在的表作为主表。
- 度量字段通常存在于多表中,因此通常情况下可以将多表作为主表进行外连接。
通过不同表中具有相同意义的关键字段,将多个表进行连接,查询不同表中的字段信息。
- 连接方式
- 内连接和外连接(左连接和右连接)
- 多表连接的结果通过三个属性决定
- 方向性
- 主副关系:主表有所有的数据范围,附表于主表无匹配时标记为null,内连接无主副之分。
- 对应关系:关键字段中有重复值的表为多表,反之一表
- 为什么拆分表:节省存储空间,避免数据冗余
- 内连接:按照连接条件合并两个表,放回满足条件的行。
-连接字段可用(表1.key=表2.key)或using(key)
select 字段。。。
from 表1 right/left join 表2
using(连接字段)
- 联合查询(纵向连接)
-把多条select 语句的查询结果合并为一个结果集。(被合并的结果集的列数、顺序和数据类型必须完全一致)(字段名可以不相同)
union 去重:
select 字段。。。 from 表名
union
select 字段。。。 from 表名
union 不去重
select 字段。。。 from 表名
union all
select 字段。。。 from 表名
- 自连接
-通过别名,将同一张表视为多表
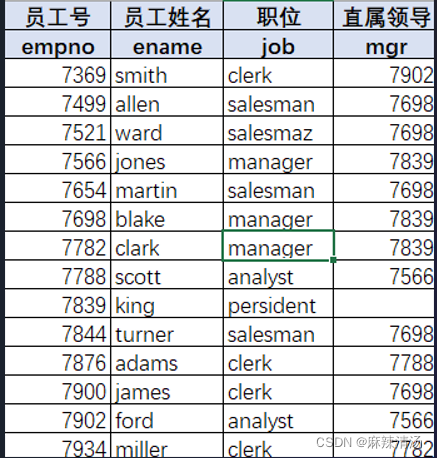
-- 查询所有员工姓名及其直属领导姓名
-- (要显示的两个字段均在一个字段里)
select t1.ename,t2.ename
from emp t1 left join emp t2
on t1.mgr=t2.emoid
#虽然执行顺序是 on->join 但是on中还是可以使用别名
- 连接查询中连接条件为区域(不等值连接)
-- 设有个数据表字段a代表等级a,b,c。另外两个字段losal最低工资和最高工资。
select ename ,grade
from emp left join salgrade
on sal between losal and hisal;
子查询
- 子查询
- 标量子查询:返回的结果是一个数据(单行单列)
- 行子查询:返回的结果是一行(单行多列)
- 列子查询:返回的结果是一列(多行单列)
- 表子查询:返回的结果是一张表(多行多列)(一定要设置表名)
出现在select子句中:将子查询返回的结果作为主查询(一个字段或计算值)
where/having子句中:作为主查询的条件
from子句中:作为主查询的一个表
资料
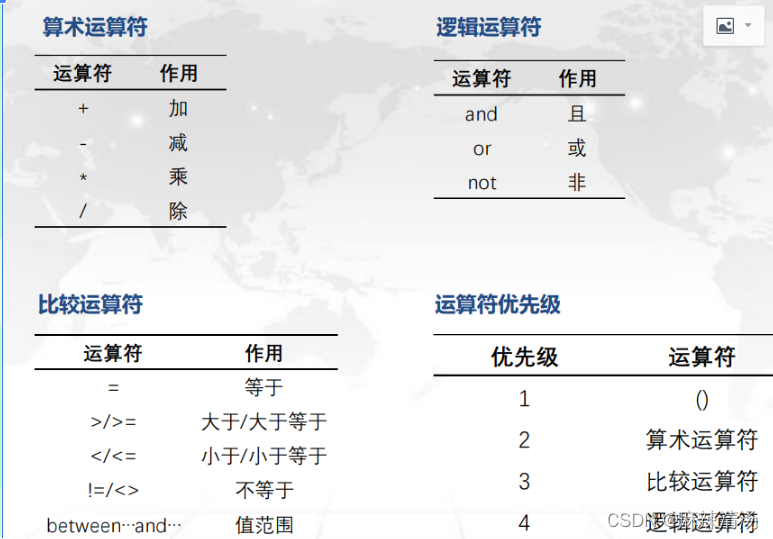
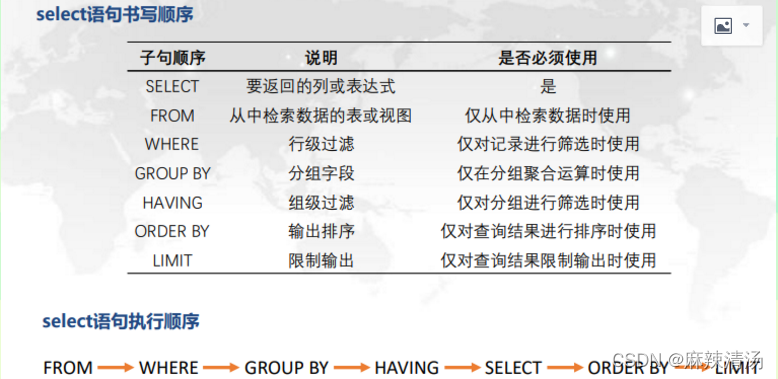
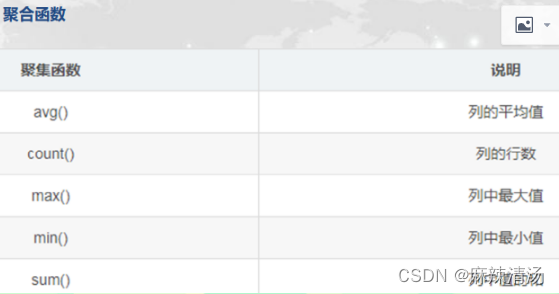
!!聚合函数会忽略空值null(特别是count())

!!!用not in时一定要排除该字段不为空值。因为会一直显示false,最后查询出空值。
大于任意的用:any;
大于所有的用:all

















 3762
3762

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









