



文本评论情感分析(正负向情感判断,测验最准模型)
在如今这个信息爆炸的时代,用户生成的内容(UGC)如评论、反馈和社交媒体帖子等,扮演着越来越重要的角色。无论是企业还是个人,理解这些文本中的情感信息对决策和行为都有着深远的影响。文本评论情感分析,作为自然语言处理(NLP)中的一个关键应用领域,旨在通过分析和处理文本数据,自动识别和分类其中的情感倾向。
情感分析的应用场景非常广泛,从企业监控品牌声誉、提升客户满意度,到政治分析、市场研究以及产品推荐等,几乎涵盖了所有需要理解用户情感的领域。通过准确的情感分析,企业可以更好地理解客户需求,及时响应负面反馈,从而提升产品和服务质量;个人用户也可以利用情感分析工具来过滤和整理信息,做出更明智的决策。
在本篇博客中,我们将深入探讨文本评论情感分析的基本概念、常用方法和工具,以及如何选择和测试最准确的情感分析模型。我们将从以下几个方面展开:
情感分析的基本概念:了解情感分析的定义、分类(如正向、负向、中性情感)以及应用场景。
常用方法和技术:介绍基于词典的方法、机器学习方法以及深度学习方法在情感分析中的应用。
模型选择和测试:探讨如何选择最适合特定应用场景的情感分析模型,并通过实验对比不同模型的准确性和性能。
实战案例分析:通过实际案例,展示如何在真实世界中应用情感分析技术,解决具体问题。
直接上源码
from transformers import AutoTokenizer, AutoModelForSequenceClassification
from transformers import pipeline
# 使用不同的模型
model_name = "uer/roberta-base-finetuned-jd-binary-chinese"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name)
# 创建情感分析pipeline
nlp = pipeline("sentiment-analysis", model=model, tokenizer=tokenizer)
# 分析情感
text = "这个东西真垃圾,没啥可以买的"
result = nlp(text)
print(result)
输出内容

结论
情感分析结果
在对文本评论进行情感分析后,我们得到了以下结果:
[ {
"label": "negative (stars 1, 2 and 3)",
"score": 0.9804423451423645 }]
解释
标签(label): negative (stars 1, 2 and 3)
这表示该评论被分类为负面情感。通常,负面情感的评论会被评分为1星、2星或3星。
得分(score): 0.9804423451423645
这是模型对该分类的置信度,范围在0到1之间。得分越接近1,
表示模型越确定该评论属于这个情感类别。在这个例子中,得分为0.9804423451423645,
表示模型非常确定该评论是负面的。
"示例展示"
假设我们有一条用户评论如下:
"这个产品的质量非常差,使用后不到一个月就坏了,客服也不理人。"
经过情感分析模型处理后,我们得到的结果是:
情感倾向: 负面
置信度: 98.04%
这表明模型非常确定该评论表达了负面的情感倾向。
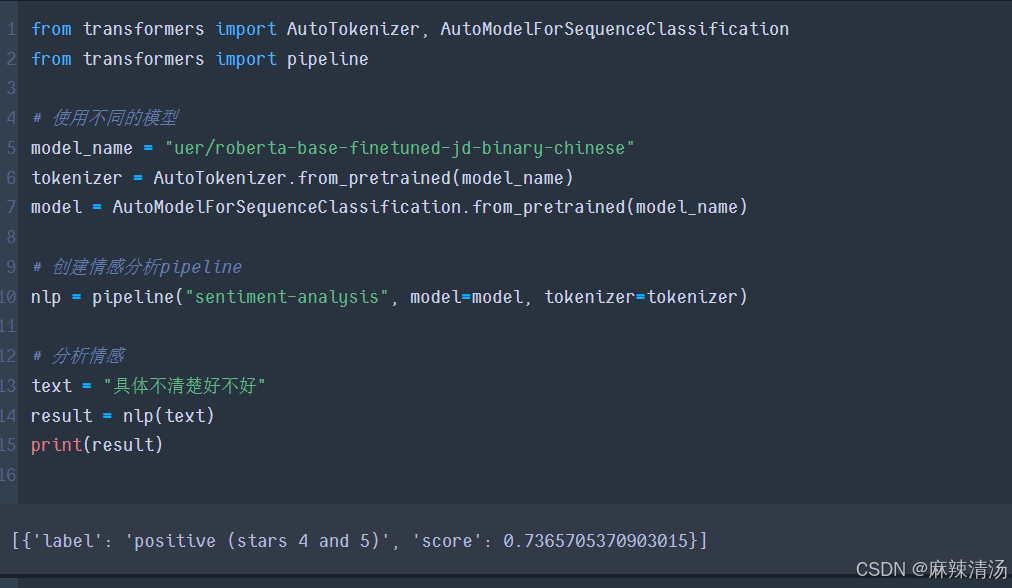
- 相比其他模型,这个模型对文本的情感处理还是很具辨识的。
完整代码
源数据截图:

import pandas as pd
from transformers import AutoTokenizer, AutoModelForSequenceClassification, pipeline
# 读取Excel文件
df1 = pd.read_excel('仅评论-实践课.xlsx')
# 确保标题列中的所有值都是字符串,并处理NaN值
df1['标题'] = df1['标题'].fillna('').astype(str)
# 加载模型和分词器
model_name = "uer/roberta-base-finetuned-jd-binary-chinese"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name)
# 创建情感分析pipeline
nlp = pipeline("sentiment-analysis", model=model, tokenizer=tokenizer)
# 对所有评论进行情感分析
def analyze_sentiment(text):
result = nlp(text)[0]
return result['label'], result['score']
# 添加情感分析结果到DataFrame
df1[['情感标签', '情感得分']] = df1['标题'].apply(lambda x: pd.Series(analyze_sentiment(x)))
# 保存结果到新的Excel文件
df1.to_excel('实践课-评论情感分析结果.xlsx', index=False)
print("情感分析完成,结果已保存到 '评论情感分析结果.xlsx'")
执行完成之后会生成一个文件保存在本地;
每一个评论对应一个情感标签和的情感得分。


















 1万+
1万+





 到【灌水乐园】发言
到【灌水乐园】发言







