







动手学深度学习
7.1 AlexNet
-
试着增加迭代轮数。对比LeNet的结果有什么不同?为什么?
增加迭代次数,LeNet的准确率比AlexNet低,因为复杂的网络有着更强的学习能力。
LeNet

AlexNet








-
AlexNet对Fashion-MNIST数据集来说可能太复杂了。
- 尝试简化模型以加快训练速度,同时确保准确性不会显著下降。
- 设计一个更好的模型,可以直接在图像上工作。
读取28*28图像的网络
net28 = nn.Sequential(
nn.Conv2d(1, 64, kernel_size=5, stride=2, padding=1), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=1),
# nn.Conv2d(64, 96, kernel_size=3, padding=2), nn.ReLU(),
# nn.MaxPool2d(kernel_size=2, stride=1),
nn.Conv2d(64, 128, kernel_size=3, padding=1), nn.ReLU(),
nn.Conv2d(128, 128, kernel_size=3, padding=1), nn.ReLU(),
nn.Conv2d(128, 96, kernel_size=3, padding=1), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Flatten(),
nn.Linear(96 * 5 * 5, 2048), nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(2048, 1024), nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(1024, 10)
)
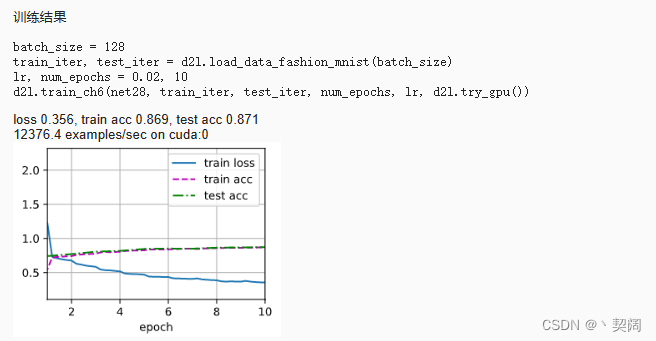
-
修改批量大小,并观察模型精度和GPU显存变化。
修改批大小可以发现,相同的训练次数,batchSize大的收敛速度更快,最终的准确率更高。直观地理解,小样本的数量越多,小样本集合的分布更接近于样本总体的分布,训练过程中的梯度的方向更接近整个训练集(做个假设,实际上几乎不可能一次性把所有训练集丢来训练)进行训练的方向。
-
分析了AlexNet的计算性能。

左边是LeNet,右边是AlexNet
-
在AlexNet中主要是哪部分占用显存?
训练时占用的显存包括参数、梯度以及隐变量的运算结果。
这题我的理解是AlexNet里面不同层需要的参数大小决定了占用显存的大小 第一层卷积层卷积核参数个数:11x11x3x96=34,848 第二层卷积层卷积核参数个数:5x5x96x256=614,400 第三层卷积层卷积核参数个数:3x3x256x384=884,736 第四层卷积层卷积核参数个数:3x3x384x384=1,327,104 第五层卷积层卷积核参数个数:3x3x384x256=884,736 第一层全连层参数(权重+偏移):6400x4096+4096=26,218,496 第二层全连层参数(权重+偏移):4096x4096+4096=16,781,312 第三层全连层参数(权重+偏移):4096x1000+1000=4,100,096 所以是第一层全连层占用了最多的显存 -
在AlexNet中主要是哪部分需要更多的计算?
把运算分为乘法运算、加法运算和特殊运算(ReLu、池化)
卷积层的计算次数:Ci x Co x Kw x Kh x Nw x Nh + Ci x Co x (Kw x Kh -1)x Nw x Nh + Co x (Ci-1) x Nw x Nh
池化层的计算次数:Nh x Nw x Ci
全连接层的计算次数:权重与变量相乘、结果相加、偏置项第一层卷积层计算次数:3x96x(2x11x11-1)x54x54+96x2x54x54=202,953,600 第一层卷积层的池化层计算次数:26x26x96=64896 第二层卷积层卷计算次数:96*256*(2*5*5-1)*26*26+256*95*26*26=830,495,744 第二层卷积层的池化层计算次数:12x12x256=36864 第三层卷积层计算次数:256*384*(2*3*3-1)*12*12+384*255*12*12=254748672 第四层卷积层计算次数:384*384*(2*3*3-1)*12*12+384*383*12*12=382150656 第五层卷积层计算次数:384*256*(2*3*3-1)*12*12+256*383*12*12=254767104 第五层卷积层池化层计算次数:5x5x256=6400 第一层全连层计算次数:6400*4096+4096*(6400-1)+4096=52,428,800 第二层全连层计算次数:4096*4096+4096*(4096-1)+4096=33,554,432 第三层全连层计算次数:1000*4096+1000*4095+1000=8,192,000第二层卷积层需要最多次数的计算,卷积层的运算次数与输入通道数、输出通道数、图片大小、卷积核大小都有关。
-
计算结果时显存带宽如何?不懂显存带宽的概念,懂的大神可以在评论区发表高见。
-
将dropout和ReLU应用于LeNet-5,效果有提升吗?再试试预处理会怎么样?
未改进:
改进后:

??这是什么情况?
上网查询资料后得出loss不变可能的几种情况:
-1 数据本身的问题 sigmoid能够成功说明数据本身没有问题,有问题可以进行批量规范化处理。
-2 初始化权重的问题 初始化权重使用了Xavier初始化方法,应该没有问题
-3 学习率过大的问题 推测可能是学习率过大导致loss在第一轮训练时就已经收敛到一个较小的值,由于学习率过大,后面的学习基本上是反复跳变不再收敛。
把学习率从0.9改为0.01后问题解决
把sigmoid函数改为ReLu函数

在全连接层加上nn.Dropout(p=0.2)

并没有什么用,因为LeNet很简单神经元也很少,没有过拟合现象发生。
至于使用预处理操作,可以去看7.5的批量规范化,其中有介绍。
7.2 VGGNet

-
打印层的尺寸时,我们只看到8个结果,而不是11个结果。剩余的3层信息去哪了?
VGG-11由五个卷积块(前两个各有一个卷积层,后三个各有两个卷积层)和三个全连接层构成。对于每个卷积块,我们只能看到一个结果。
-
与AlexNet相比,VGG的计算要慢得多,而且它还需要更多的显存。分析出现这种情况的原因。
从本章给出的模型来看,VGG有8个卷积层,AlexNet只有5个卷积层;VGG的卷积层最大输出通道数为512,AlexNet为384。更多的卷积层和更多的通道数是的运算量和中间变量的数目变多,需要更多的运算时间和显存。
-
尝试将Fashion-MNIST数据集图像的高度和宽度从224改为96。这对实验有什么影响?
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Y8Hh8Z7X-1673260076890)(assets/2023-01-08-11-12-52-image.png)]
使用colab训练,可以观察到训练速度有所加快。
-
请参考VGG论文 (Simonyan and Zisserman, 2014)中的表1构建其他常见模型,如VGG-16或VGG-19。

按此表构建不同数量和尺寸的卷积块即可
7.3 NiN

- 调整NiN的超参数,以提高分类准确性。

调整训练次数

2. 为什么NiN块中有两个卷积层?删除其中一个,然后观察和分析实验现象。
偷懒借鉴一下原文评论区的答案。

3. 计算NiN的资源使用情况。
-
参数的数量是多少?
一个NiN块的参数数量:3*96*11*11+96*96*1*1+96*96*1*1=53280 二个NiN块的参数数量:96*256*5*5+256*256*1*1+256*256*1*1=745472 三个NiN块的参数数量:3x3x256x384+1x1x384x384+1x1x384x384=1179648 四个NiN块的参数数量:3x3x384x10+1x1x10x10+1x1x10x10=34760 -
计算量是多少?
把卷积和求最大值视为一次操作则计算量
一个NiN块的计算量:54*54*96+54*54*96+54*54*96=839808 最大池化:26*26*96=64896 二个NiN块的计算量:26*26*256+26*26*256+26*26*256=519168 最大池化:12*12*256=36864 三个NiN块的计算量:12*12*384+12*12*384+12*12*384=165888 最大池化:5*5*384=9600 四个NiN块的计算量:5*5*10+5*5*10+5*5*10=9600 平均池化:10 -
训练期间需要多少显存?
-
预测期间需要多少显存?
训练所需的显存和参数的权重,参数的梯度,以及梯度反向传播过程中的中间值,最后还有数据(batch_size)都有关,不好直接计算,但是可以估测。
-
一次性直接将384x5x5的表示缩减为10x5x5的表示,会存在哪些问题?



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









