






 本文详细介绍了深度学习在医学图像分割领域的进展,特别关注了FCN和UNet网络结构。FCN作为语义分割的先驱,而UNet则通过其U型结构和数据增强策略提升了分割精度,尤其适用于医学图像。文章还探讨了医学图像分割的挑战,如数据稀缺、图像尺寸大、要求高和多模态数据。UNet通过引入跳跃连接和全卷积层,有效结合了低分辨率和高分辨率信息,成为医学图像分割的基准。此外,FusionNet通过加深网络和引入残差块进一步提高了分割性能。最后,文章详细阐述了训练策略,包括数据增强、损失函数优化和权重初始化方法。
本文详细介绍了深度学习在医学图像分割领域的进展,特别关注了FCN和UNet网络结构。FCN作为语义分割的先驱,而UNet则通过其U型结构和数据增强策略提升了分割精度,尤其适用于医学图像。文章还探讨了医学图像分割的挑战,如数据稀缺、图像尺寸大、要求高和多模态数据。UNet通过引入跳跃连接和全卷积层,有效结合了低分辨率和高分辨率信息,成为医学图像分割的基准。此外,FusionNet通过加深网络和引入残差块进一步提高了分割性能。最后,文章详细阐述了训练策略,包括数据增强、损失函数优化和权重初始化方法。
前置需求
- 语义分割综述
- FCN 论文阅读
- 推荐去看一下 FCN 论文笔记
论文导读
论文研究背景、成果及意义
医学图像分割
- 医学图像分割是医学图像处理与分析领域的复杂而关键的步骤,目的是将医学图像中某些特殊含义的部分分割出来,并提取相关特征
- 要求非常高,毕竟人命关天,比其他场景的分割都要精细
- 从手动分割、半自动分割到全自动分割,是医学图像分割的终极目标
难点
- 数据量少。一些挑战赛提供的数据甚至不足100例
- 图片尺寸大。单张图片尺寸大、分辨率高,对模型的处理速度有一定的要求
- 要求高。医学图像边界模糊、梯度复杂,对算法的分割准确度要求极高
- 多模态。以 ISLES 脑梗竞赛为例,其官方提供了 CBF、MTT、CBV、TMAX、CTP 等多种模态的数据
ISBI 挑战赛
即「IEEE International Symposium on Biomedical Imaging」IEEE 国际生物医学影像研讨会挑战赛
医学图像分割非常著名的挑战赛
连接组学
「连接组学绘制与研究神经连接组」:一种刻画有机体神经系统的连接方式(尤其是脑子和眼睛)的完整线路图。旨在全面的映射神经系统中发现的神经元网络的结构,以便更好地理解大脑如何工作
成像非常夸张,1mm^31mm3 的脑组织可以产生超过 1000TB1000TB 的数据。难点不是获取数据本身,而是对这个尺度的数据进行处理和信息提取
研究成果及意义
- 赢得了 ISBI cell tracking challenge 2015
- 速度快,对于一个 512 \times 512512×512 的图像,使用一块 GPU 只需要不到 1s 的时间
- 称为大多数做医疗影像语义分割任务的 Baseline ,也启发了大量研究者去思考 U 型语义分割网络
- UNet 结合了低分辨率信息(提供物体类别识别依据)以及高分辨率信息(提供精准分割定位依据),完美适用于医学图像分割
论文泛读
论文结构
- Abstract 摘要
- Introduction:相关背景概述
- Network Architecture:简述算法结构
- Training:训练细节、数据增强
- Experiments:实验结果分析
- Conclusion:实验结论
Abstract 摘要
UNet 摘要
- 主要贡献:本文提出了一个网络和训练策略,使用数据增强,以便更有效的使用可用的带标签的样本
- 网络结构:网络由两部分组成,定义一个收缩路径来获取全局信息,同时定义一个对称的扩张路径用来精确定位
- 网络效果:该网络可以用很少的图片进行端到端的训练,同时处理速度也比较快
- 实验结果:以很大的优势赢得了 2015 ISBI 细胞跟踪挑战赛
FusionNet 摘要
- 主要贡献:提出了一种熊德深度神经网络 FusionNet,用于自动分割连接组学数据中的神经元结构
- 主要方法:引入基于求和的跳跃连接,允许更深入的网路结构以实现更精确的分割
- 实验结果:通过与传统方法比较,FusionNet 展现出了更好的性能
Introduction 引言和相关工作
UNet
正文
- 前几句话:CNN 发展历程,略
-
CNN 发展的转折:ImageNet 超大型数据集的出现,自从 ALexNet 出现后,很多网络涌现出来
- The breakthrough by Krizhevsky et al. [7] was due to supervised training of a large network with 8 layers and millions of parameters on the ImageNet dataset with 1 million training images. Since then, even larger and deeper networks have been trained [12].
- CNN 的典型应用实际上是在分类算法上的。但是又因为有很多的可视化任务需要从端到端,像素到像素进行分类
- However, in many visual tasks, especially in biomedical image processing, the desired output should include localization, i.e., a class label is supposed to be assigned to each pixel.
- 根据大背景,介绍前人的办法,因为和深度学习关系不大所以不在此赘述。
-
从 FCN 入手,引出思想的来源:在本篇论文中,我们修改和扩展了传统的 FCN 网络架构,处理很少的图像就能取得比较准确的分割
- In this paper, we build upon a more elegant architecture, the so-called “fully convolutional network” [9]. We modify and extend this architecture such that it works with very few training images and yields more precise segmentations;
- 提出本文的算法架构:本文的架构有一个对于上采样部分的重要修改,使得网络能把全局信息带到更高分辨率的层上去
- One important modification in our architecture is that in the upsampling part we have also a large number of feature channels, which allow the network to propagate context information to higher resolution layers.
- 这样的结果扩增路径基本对称于收缩路径,所以呈现出了一个“U”形。
- As a consequence, the expansive path is more or less symmetric to the contracting path, and yields a u-shaped architecture.
- 整个网络中并没有使用任何的全连接层,而只是使用每一个卷积层的有效部分(Valid Part),也就是,在网络中的分割图层(Segmentation Map)包含对于每一个输入图像,全局信息(Full Context)都共享的信息
- 可能上面这句话比较难理解,但通俗点讲就是:可以做到更高的全局信息共享性,来达到更好的训练效果,这点在 FCN 是做不到的
- The network does not have any fully connected layers and only uses the valid part of each convolution, i.e., the segmentation map only contains the pixels, for which the full context is available in the input image.
- 为了预测图片的边界区域的边界像素(Border Region),解决上下文丢失(The Missing Context)问题,本文采用了图片镜像输入(Mirroring the Input Image)进行补全
- 镜像输入可能不是很好懂,请看 Fig.2 部分
- To predict the pixels in the border region of the image, the missing context is extrapolated by mirroring the input image.
- 数据增强的必要性:在网络处理的过程中,经过一些弹性变形(Elastic Deformations),把数据集中的数据拿到外面进行一些“骚操作”。比如下文提到的「Overlap-tile」就是其中的一种,来增加数据量
- 值得注意的是,UNet 恰好是比较适合这种变形的。因为在医学图像中,有些生物组织在真实世界中也会发生和弹性变形差不多的形变,这可能使得 UNet 所增强的数据更贴近真实情况
- As for our tasks there is very little training data available, we use excessive data augmentation by applying elastic deformations to the available training images. This allows the network to learn invariance to such deformations, without the need to see these transformations in the annotated image corpus. This is particularly important in biomedical segmentation, since deformation used to be the most common variation in tissue and realistic deformations can be simulated efficiently.
- 下一段提出了另外一种优化方式:因为在实际使用过程中,会出现「两种细胞紧紧贴合在一起」这种尴尬情况。如何长得很像且距离很近的东西也能得到精确的划分?这也是 UNet 切实解决了的一个问题。
在本文中提出了一种新的 Loss 计算方法:加权损失。连接了细胞的背景获得了比较大的权重,那么整个模型在训练的过程中就会把注意力更放在这些「两种细胞紧紧贴合在一起」的小细节的地方,集中火力干掉难点- 更多信息请看 Fig.3
- Another challenge in many cell segmentation tasks is the separation of touching objects of the same class; see Figure 3. To this end, we propose the use of a weighted loss, where the separating background labels between touching cells obtain a large weight in the loss function.
Figures
- Fig.2:下图所示,最中心白线所包含的正方形,就是原始图片,而白线周围的则是通过镜像翻转得到的图片信息,比较直观
- 图片:
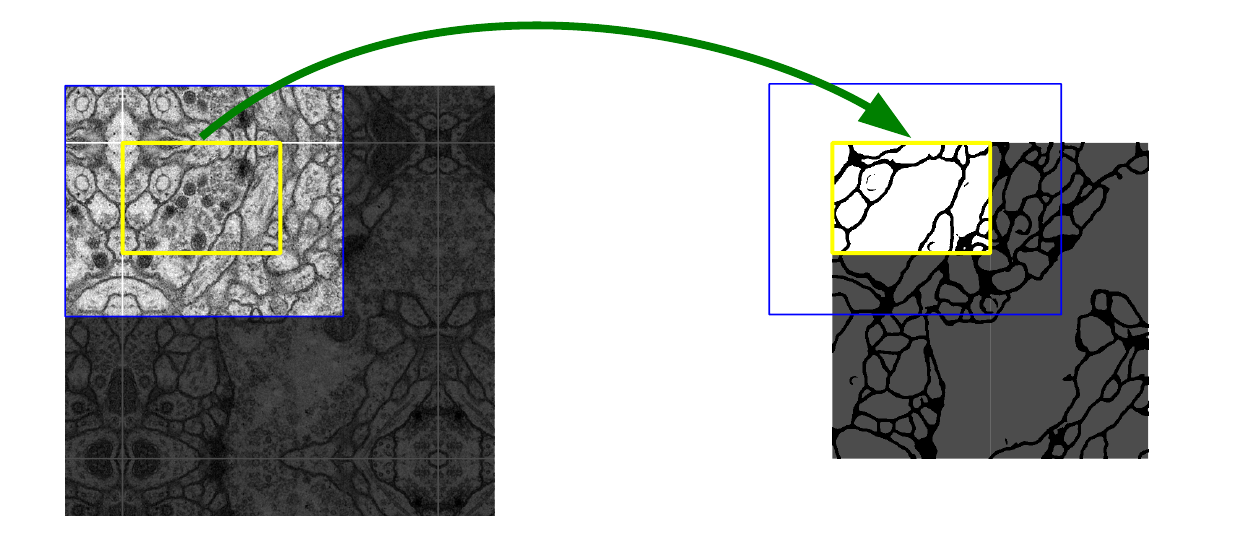
- 作者把这种做法称为「Overlap-tile」
- 图片:
FusionNet
正文
- 首先通过问题引出连接组学(Connectomics Research),介绍了一下连接组学
- “How does the brain work?” This question has baffled biologists for centuries. The brain is considered the most complex organ in the human body, which has limited our understanding of how relating its structure is related to its function even after decades of research [21]. Connectomics research seeks to disentangle the complicated neuronal circuits embedded within the brain.
- 上文提到了电子显微镜,可以取得更大更精细的组织图片。但是这些图片过于庞大,难以处理,成为了连接组学发展中的一大问题
- Therefore, handling and analyzing the resulting datasets is one of the most challenging problems in connectomics.
- 本文观察到目前最先进的端到端语义分割网路就是 UNet,但是也有不少缺点。虽然 UNet 比传统的 FCN 更好,但还是被传统的神经网络所限制:网络深度不够深。那么反映到分割结果上,就是分割的还不够细致。
为了解决这个问题,提出了扩展 UNet。使用了残差(ResNet)和跳跃连接(shortcut),来加深网络的深度
- We observed that the current state-of-the-art deep neural network for end-to-end segmentation (i.e., U-net) [25] shares a similar limitation with the conventional CNN in increasing network depth, as discussed in residual CNN [14]. To address this problem, we propose a novel extension of U-net by using residual layers in each level of the network and introducing summation-based skip connections to make the entire network much deeper than U-net.
因为提出的理念并没有太多创新,不再赘述细节
Network Architecture 模型详解
UNet
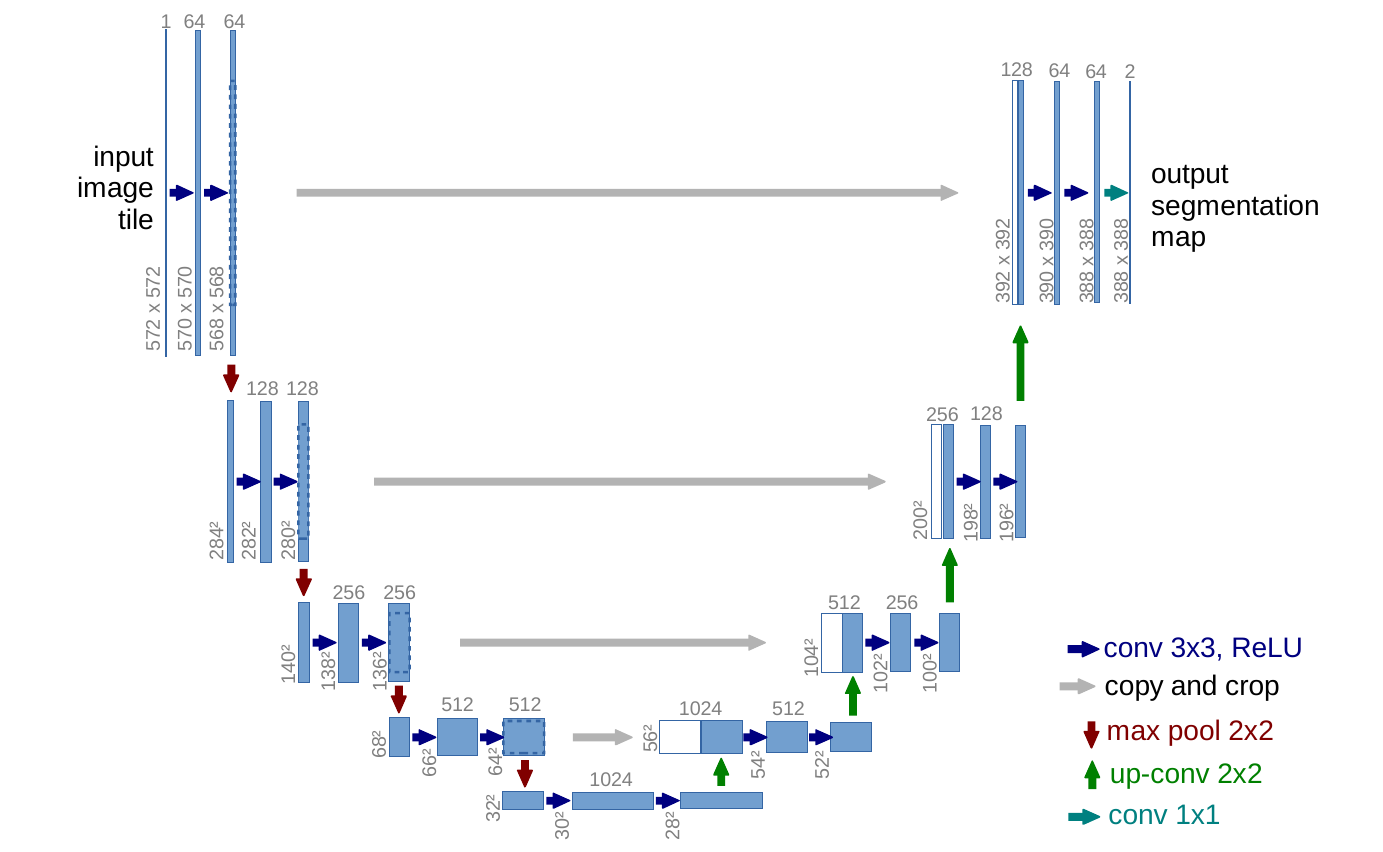
如图,是 UNet 的网络结构
有以下几点需要注意:
- 输入的通道数为 1 因为医学图像一般都是灰度图
- 输出的通道数为 2,因为一般医学图像分割就是分成两类
- 输入的图片为 572 x 572,输出的图片为 388 x 388,实际上输入的 572 是 388 的原始图片进行镜像翻转得到的
FusionNet
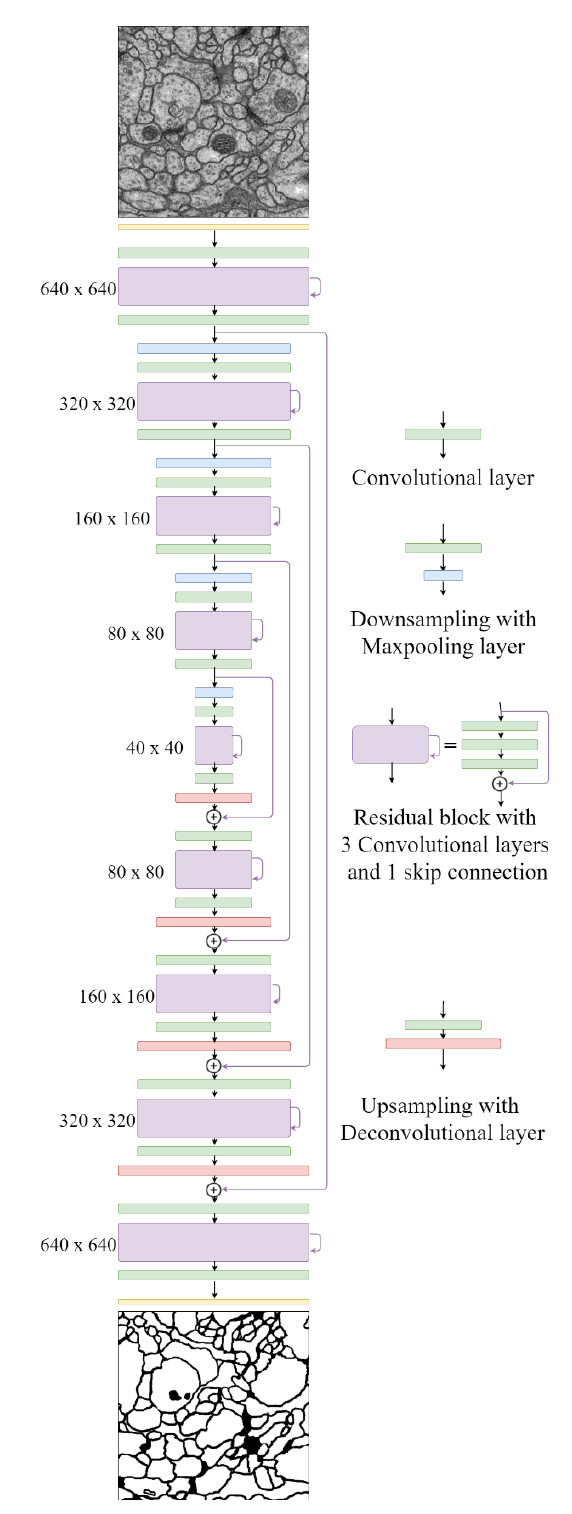
如图,是 FusionNet 的网络结构图
其内部大致和 UNet 相同,只不过把一些层替换为了“汉堡”形状的层,并且把 “U形” 结构伸直
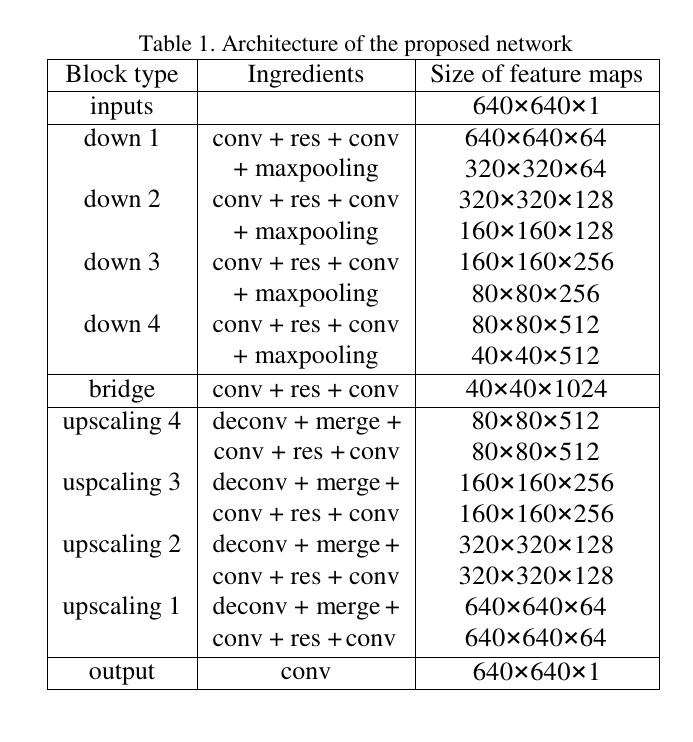
上图为网络图片大小的转换过程详解
Training 训练细节
UNet 输入和输出
医学图像一般都是相当大的,分割的时候几乎不可能直接把这么大的图片丢进去运行,所以必须切成一张一张的小 Patch ,然后把这些小 Patch 送进 UNet 进行分割。
因为 UNet 的镜像翻转,所以切成小 Patch 并不会造成分割情况变差。
UNet 具体操作
图片输入原则
上文提到,输入图片的时候使用小 Patch 分批送入一整张大型图片,但是会存在一些问题:是使用 “小 Patch 大 BatchSize” 还是 “大 Patch 小 BatchSize”?
答案是后者,本篇论文中作者更提倡 “大 Patch 小 BatchSize”,甚至 BatchSize = 1都是可以的。
- To minimize the overhead and make maximum use of the GPU memory, we favor large input tiles over a large batch size and hence reduce the batch to a single image.
动量设置
值得注意的是,本篇文章中使用的动量是比较大的,作者使用的动量为 0.990.99 ,来增加网络的性能,使得更多的先前得到的梯度信息决定本次迭代要更新的方向
- Accordingly we use a high momentum (0.99) such that a large number of the previously seen training samples determine the update in the current optimization step.
加权损失函数
此损失函数定义如下:
E=\sum_{\mathbf{x} \in \Omega} w(\mathbf{x}) \log \left(p_{\ell(\mathbf{x})}(\mathbf{x})\right)E=x∈Ω∑w(x)log(pℓ(x)(x))
根据我们之前的知识很容易知道,如果上面的公式去掉 \omega(x)ω(x) 这一部分,就是普通的交叉熵损失函数(Cross Entropy Loss)。
但这个 \omega(x)ω(x) 确实整个文章的比较重要的创新点。将其放入公式并直观理解一下的话,那么这个 \omega(x)ω(x) 代表的其实就是「对某一像素的重视程度」,其中 \omega(x)ω(x) 越大则说明越重视。
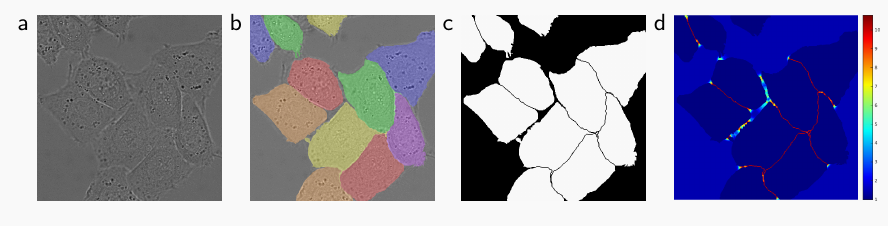
看上图可得,当像素之间区域越来越近,越来越难以分辨的时候, \omega(x)ω(x) 就会越大,也就是整个网络会格外注意这些区域,来使得分割结果更加准确
其中 \omega(x)ω(x) 的定义式为:
w(\mathbf{x})=w_{c}(\mathbf{x})+w_{0} \cdot \exp \left(-\frac{\left(d_{1}(\mathbf{x})+d_{2}(\mathbf{x})\right)^{2}}{2 \sigma^{2}}\right)w(x)=wc(x)+w0⋅exp(−2σ2(d1(x)+d2(x))2)
其中 d_1(x)d1(x) 表示的是某一像素 xx 到离它最近的细胞边界的距离, d_2(x)d2(x) 表示的是某一像素 xx 到离它第二近的细胞边界的距离。
那么通过计算二者的值越大,二者相加的平方越大,那么 \omega(x)ω(x) 就会越小,也就是「这个像素点并不在细胞间缝隙内」。
权重初始化
在实际使用中,我们有概率是随机到和真实我们需要的梯度信息背道而驰的初始值。所以为了减少这一情况的出现,本篇论文作者提出了另外一种权重初始化方法。
可以使用在 \sqrt{2 / N}2/N 为标准差的高斯分布进行初始化操作。其中 NN 表示的是「一个神经元传入的节点的数量」。如一个 3\times33×3 的卷积,以及含有 6464 个 Feature 的通道,那么 N = 3\times3\times 64 = 576N=3×3×64=576
Conclusion 讨论和总结
UNet 的关键点和创新点
- 设计了严格对称的U型结构
- 使用镜像折叠补充输入图像
- 使用了一种加权损失函数
FusionNet 的关键点和创新点
- 改编 UNet
- 加入残差块
- 短连接 + 长连接

















 3136
3136

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









