



 文章详细解读了Transformer算法的结构,从论文《AttentionIsAllYouNeed》出发,结合GitHub上的demo代码,解析了输入、输出以及模型中数据形状的变化。输入为长度15的整数列表,表示15个字符的句子,输出则略去了首字符。该示例程序旨在通过Transformer模型进行序列生成任务,即预测给定输入序列的后续部分。
文章详细解读了Transformer算法的结构,从论文《AttentionIsAllYouNeed》出发,结合GitHub上的demo代码,解析了输入、输出以及模型中数据形状的变化。输入为长度15的整数列表,表示15个字符的句子,输出则略去了首字符。该示例程序旨在通过Transformer模型进行序列生成任务,即预测给定输入序列的后续部分。
论文来源:Attention Is All You Need
程序源码来源:github中的demo
算法结构
根据论文的给出的图片,我们不难模仿着画出算法的简要结构。
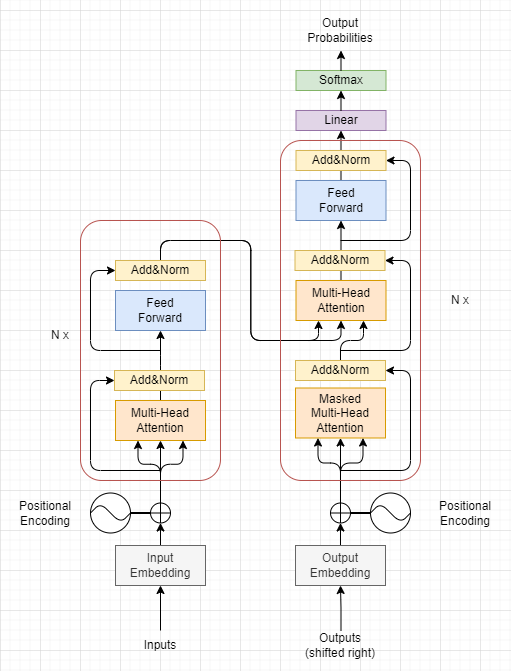
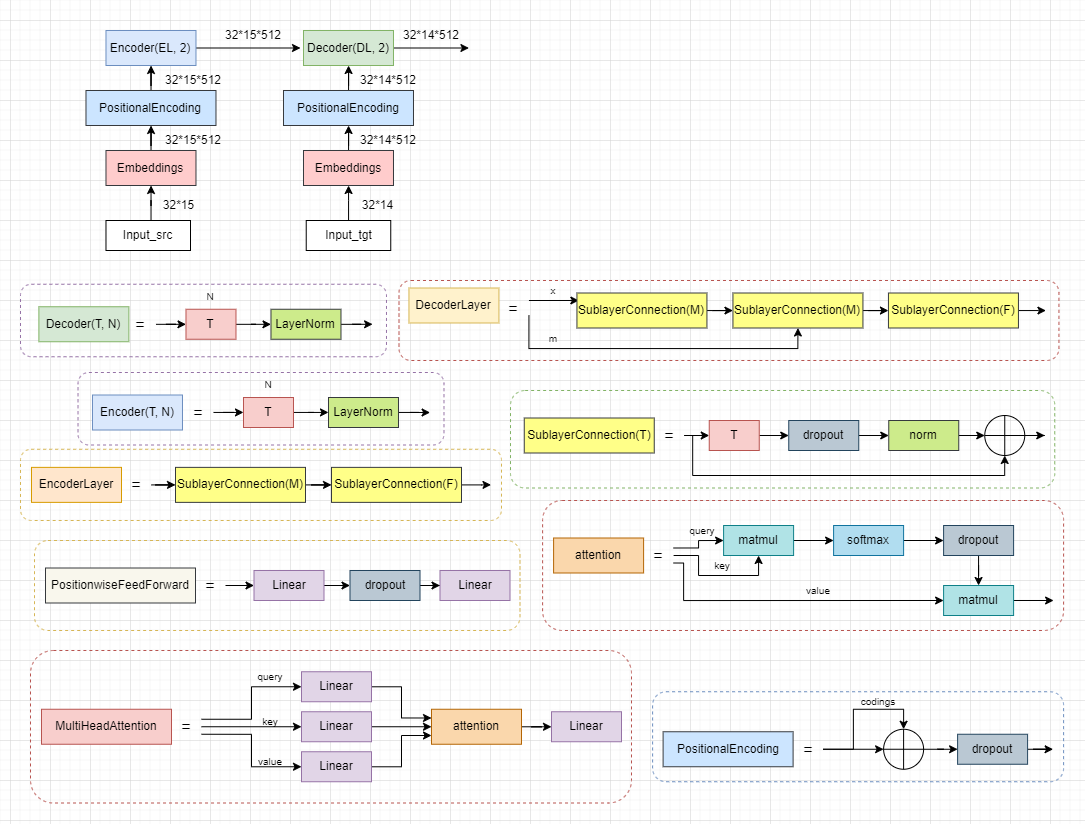
代码解读
拿到这个demo后,首先确定一下这个程序的输入是什么,输出是什么,要解决的是什么问题。
通过一步步的debug代码调试,不难发现,输入是[2, 3, 4, 5, 2, 4, 9, 7, 6, 10, 5]这样的整数列表。而且这里的列表长度默认是15(训练数据encoder输入是15,decoder输入是14),列表中的值位于[2, 11)之间。这里的范围与长度都是有一定的意义的,我们把每一个列表看成一个句子,每个整数值当作一个字,则这里15表示一个句子的长度为15,而11的限制暗示这些句子中会有11种不同的字。
这个demo程序的任务就是要通过[2, 3, 4, 5, 2, 4, 9, 7, 6, 10, 5]这样的输入,推出[ 3, 4, 5, 2, 4, 9, 7, 6, 10, 5]这样的输出,更直观的来说就是略去最开头的字符。输入数据shape(15),而输出数据shape(14)。
参考博客与网络资源:
[1]: Transformer代码完全解读(附有可实验的完整训练推理程序)
[2]: Transformer算法完全解读
[3]: NLP基础知识点:BLEU(及Python代码实现)
[4]: 十分钟读懂Beam Search 1:基础

















 1450
1450




 到【灌水乐园】发言
到【灌水乐园】发言







