






背景
Transformer模型最初是使用在NLP中,但近几年Transformer模型在图像上的使用越来越频繁,最新的模型也出现了很多基于Transfomer的,而其中经典的是Vision Transformer(ViT),它是用于图像分类的,这里就以ViT-B/16这个模型来学习Transformer模型是如何在图像领域使用的。
整体框架
ViT的网络结构如图所示,可以将ViT分为三个部分:
- Embedding层:对原始的图像数据进行处理,转换为embedding(向量)序列,使其符合Transformer Encoder的输入要求
- Transformer Encoders层:包含多个Encoder Block,对输入的token进行处理
- MLP Head层:用于分类的层结构

各个部分的详解
Embedding层
对于标准的Transformer模块,要输入的是embedding(向量)序列,也就是二维矩阵[embedding_token,embedding_dim(向量的长度)],以ViT-B/16为例,embedding的长度为768。
而对于图像数据而言,其格式为[H,W,C],显然不是Transformer模块需要的,因此需要通过一个Embedding层来对数据格式进行转换。
操作过程如下图所示,以ViT-B/16为例,首先将输入图像(224x224)切分为196个16x16的Patch,这些Patch的格式为[16,16,3]。接下来将这些Patch进行线性映射,映射到潜在空间,也就是转换为一维的向量:[16,16,3]-->[768]。不同ViT中patch映射的向量长度不同

在代码实现中,直接使用一个卷积层来实现,卷积核大小为patch大小,卷积核个数为embed_dim的维度数,不同种类的ViT的值不同。若输入数据为[B,C,H,W],经过卷积并展平后,数据尺寸变为[B,embed_dim,num_patches],而为了符合输入要求,需要将第2与3维进行转置,变为[B,num_patches,embed_dim]
以ViT-B/16为例,使用一个卷积核为16x16,步距为16,卷积核个数为768的卷积层来实现。通过卷积层会得到[224,224,3]-->[14,14,768],然后在通过Flatten操作将[H,W]展平即可[14, 14, 768] -> [196, 768],此时正好为二维矩阵,符合Transformer模块的需要。

在输入到Transformer模块前,需要加上[class]token(token所属的类别)与位置编码Position Embedding。
- [class]token:在刚刚得到的一堆tokens中插入一个专门用于分类的[class]token,这个[class]token是一个可训练的参数,数据格式和其他token一样都是一个向量,以ViT-B/16为例,就是一个长度为768的向量,与之前从图片中生成的tokens拼接在一起
Cat([1, 768], [196, 768]) -> [197, 768],增加了一个向量。 - Position Embedding:就是之前Transformer中讲到的Positional Encoding,这里的Position Embedding采用的是一个可训练的参数,这里是直接叠加(add)到token上。以ViT-B/16为例,刚刚拼接[class]token后shape是
[197, 768],那么这里的Position Embedding的shape也是[197, 768]。

Embedding 层的整体结构如图所示

Transformer Encoder层
Transformer Encoder其实就是重复堆叠Encoder Block L次,Encoder Block由以下部分构成:
- Layer Norm:对每个token进行标准化处理
- Multi-Head Attention:链接
- Dropout/DropPath:防止过拟合,在原论文的代码中是直接使用的Dropout层,但也有人使用DropPath
- MLP Block:如图右侧所示,由全连接层(Liner)+GELU激活函数+DropOut层构成,需要注意的是第一个全连接层会将节点个数翻4倍
[197,768]-->[197,3072],而第二个全连接层会将节点个数恢复原样[197,3072]-->[197,768],这样经过MPL Block不会修改数据的结构。
通过Transformer Encoder后输出的shape和输入的shape是保持不变的,以ViT-B/16为例,输入的是[197, 768]输出的还是[197, 768]

而在代码实现中,会在Transformer模块前面加一个Dropout层,后面加一个Layer Norm层。

MLP Head
由于只需要分类的信息,因此只需要将[class]token生成的对应结果提取出来即可,即[197, 768]中抽取出[class]token对应的[1, 768],最后在使用MLP Head得到最终的分类结果。
在论文中,训练ImageNet21K(大型数据集)时,MLP Head是由Linear+tanh激活函数+Linear组成。但是迁移到ImageNet1K上或者你自己的数据上时,只用一个Linear即可。
以ViT-B/16为例

不同种类的ViT
论文中提供了三种ViT模型的参数
- Layers:Transformer模块中Encoder模块的个数
- Hidden Size:经过Embedding层后每个token的长度
- MLP Size:MLP Block中第一个全连接层的输出节点个数,是Hidden Size的四倍。
- Heads:Multi-Head Attention的heads数。

代码实现
Embedding层

在代码实现时,要注意输入数据的格式,一般的格式为(B,C,H,W),但后面需要的数据格式为(B,HW,C),即二三维需要调换,因此需要进行转置操作。
class Patch_Embedding(nn.Module):
def __init__(self, image_size=224, in_channel=3, embed_dim=768, patch_size=16, dropout=0.1):
"""
嵌入层
@param image_size: 图像大小
@param in_channel: 输入通道数
@param embed_dim: 输出向量的维度
@param patch_size: patch的大小
@param dropout: dropout操作
"""
super(self,Patch_Embedding).__init__()
self.patcher = nn.Sequential(
nn.Conv2d(
in_channels=in_channel,
out_channels=embed_dim,
kernel_size=patch_size,
stride=patch_size
), # 通过卷积操作,提取出各个patch,并转为向量,(B,C,H,W)-->(B,embed_dim,num_patch/2,num_patch/2)
nn.Flatten(2) # 将patch的维度展平,-->(B,embed_dim,num_patch)
)
self.class_token = nn.Parameter(torch.randn(size=(1, 1, embed_dim))) # 随机初始化class_token
self.num_patch = (image_size // patch_size) * (image_size // patch_size) # patch的个数
self.position_embedding = nn.Parameter(torch.randn(size=(1,self.num_patch+1,embed_dim))) # 随机初始化位置编码
self.dropout = nn.Dropout(p=dropout)
def forward(self,x):
B,C,H,W = x.shape
x = self.patcher(x) # 通过卷积得到各个patch,并展平
x = x.permute(0,2,1) # 交换 (B,embed_dim,num_patch)-->(B,num_patch,embed_dim)
x = torch.cat((x,self.class_token),dim=1) # 与class_token拼接
x = x + self.position_embedding # 与位置编码相加
return x
Transformer Encoder层


有两种实现方法:1.使用pytorch中的API;2.手动搭建
① 使用pytorch中的API:
在pytorch中,有两个API:nn.TransformerEncoderLayer与nn.TransformerEnoder
其中TransformerEncoderLayer相当于图中的Encoder Block,而TransformerEncoder则包含所有Encoder Block。
因此使用时需要先构造出TransformerLayer对象,设置好参数,再使用TransformerLayer对象出构造TransformerEncoder。

参数:
d-model(int):输入数据的特征维度,在vit中也就是第三维的数据个数nhead(int):多头自注意力机制中,head的个数dim_feedforward(int):前馈网络中隐藏层的维度,默认为2048dropout(float):dropout的比例,默认为0.1activation(str):使用的激活函数,如‘“relu”与“gelu”,默认为“relu”layer_norm_eps (float):在layer normalization中使用的,默认为1e-5batch_first (bool):若为True,则在输入与输出的数据中,batch在第一个维度,反之在第二个维度。默认为Flasenorm_first (bool):是否在执行起始的layer normalization。若为True则执行,默认为Falsebias (bool):Liner与layer normalization是否使用bias。若为True则使用,默认为Flase。

参数:
encoder_layer (TransformerEncoderLayer):传入TransformerEncoderLayer对象num_layers(int):包含多少个Encoder Blocknorm (Optional[Module]): layer normalization使用的模块,默认为None
self.TransformerEnoderLayer = nn.TransformerEncoderLayer( # Encoder Block
d_model=embed_dim,
nhead=num_head,
dropout=dropout,
activation=activation,
batch_first = True,
norm_first = True,
)
self.TransformerEncoder = nn.TransformerEncoder(self.TransformerEnoderLayer,num_layers) # Encoder
② 自己实现:
首先要实现Attention与MLP block,并构成Transformer Encoder Block。
Multi Attention
首先要初始化要使用的各种参数与层,其中使用一个全连接层来获得QKV,其输出维度为输入的3倍。
def __init__(self,
dim, # 输入token的维度数,也就是自注意力中输入a的维度
num_heads=8, # 注意力头个数
qkv_bias=False, # 是否使用偏置
qk_scale=None,
attn_drop_ratio=0.,
proj_drop_ratio=0.):
super(Attention, self).__init__()
self.num_heads = num_heads
head_dim = dim // num_heads # 每个head分到的维度数,一般是均分
self.scale = qk_scale or head_dim ** -0.5 # 一般是根号(head_dim),对应注意力的公式
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias) # 通过一个全连接层生成QKV,将维度数*3
self.attn_drop = nn.Dropout(attn_drop_ratio)
self.proj = nn.Linear(dim, dim) # 作为Wo,在融合结果时使用
self.proj_drop = nn.Dropout(proj_drop_ratio)
(1)获得QKV:
在实现过程中,首先要获得QKV,这里使用了一个全连接层得到QKV。全连接层的输出:[B,num_patch+1,3*embed_dim]
然后需要从中提取出各个head的QKV,要经过一下步骤:
- reshape:
[B,num_patch+1,3*embed_dim]->[B, num_patch + 1, 3, num_head, embed_dim_per_head]
也就是将3*embed_dim拆分成各个head的数据。 - permute:
[B, num_patch + 1, 3, num_head, embed_dim_per_head]->[3, B, num_head, num_patch + 1, embed_dim_per_head]
调整顺序,将3放到前面,方便对QKV进行处理与提取;将num_heads与N调换,让N与数据放在一起,这样方便使用每个head的数据 q, k, v = qkv[0], qkv[1], qkv[2]:提取各个head的QKV,每个的结构为[B, num_head, num_patch + 1, embed_dim_per_head]
def forward(self, x):
# [batch_size, num_patches + 1, total_embed_dim]
# num_patches:划分出的patch个数,加1是加上class_token
# embed_dim:经过embedding层后得到
B, N, C = x.shape
'''
1.得到QKV
先将输入数据复制三份,然后按照QKV中的每个head进行均分
'''
# qkv(): -> [batch_size, num_patches + 1, 3 * total_embed_dim] 维度数*3
# reshape: -> [batch_size, num_patches + 1, 3, num_heads, embed_dim_per_head]
# 将最后一维的数据进行拆分,拆分为QKV:
# 3对应着QKV,num_heads对应着每个head,embed_dim_per_head对应着每个head中qkv的dim
# permute: -> [3, batch_size, num_heads, num_patches + 1, embed_dim_per_head]
# 调整数据中的顺序,将3放到前面,方便对QKV进行处理与提取;
# 将num_heads与N调换,让N与数据放在一起,这样方便使用每个head的数据
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
# [batch_size, num_heads, num_patches + 1, embed_dim_per_head]
# 提取出QKV
q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
提取出QKV后,要根据公式进行计算
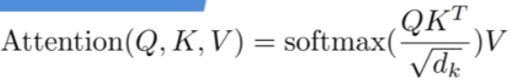
(2)计算QK相乘:
Q与K后两维的数据进行相乘,得到[B, num_heads, num_patches + 1, num_patches + 1]。然后再继续softmax操作与下采样操作。
'''
2.计算Q*K的转置,计算attention
'''
# transpose: -> [batch_size, num_heads, embed_dim_per_head, num_patches + 1] 对K进行转置,转置最后两维
# @: multiply -> [batch_size, num_heads, num_patches + 1, num_patches + 1]
attn = (q @ k.transpose(-2, -1)) * self.scale # QK矩阵相乘,并进行scale操作。各个head中的qk相乘
# 对QK的结果运行softmax操作,也就是对结果的每一行进行softmax:dim=-1代表对每一行的数据进行?
attn = attn.softmax(dim=-1)
# 最后进行一个下采样,得到V的权重
attn = self.attn_drop(attn)
(3)计算与V相乘:
得到[B, num_heads, num_patches + 1, embed_dim_per_head]。
然后通过transpose与reshape要将尺寸恢复为原样,也就是[B, num_heads, num_patches + 1, embed_dim_per_head]->[B, num_patches + 1, total_embed_dim]
最后再将数据输入到全连接层进行融合
'''
3.与V相乘
'''
# @: multiply -> [batch_size, num_heads, num_patches + 1, embed_dim_per_head]
x = (attn @ v) # 与V相乘
# 将数据格式恢复为原样,注意力不会改变数据的尺寸
# transpose: -> [batch_size, num_patches + 1, num_heads, embed_dim_per_head]
# 将数据转变为对于每个patch中,各个head得到的结果
# reshape: -> [batch_size, num_patches + 1, total_embed_dim]
# 对最后两维的数据进行拼接,也就是对每个head的结果进行concat拼接
x = x.transpose(1, 2).reshape(B, N, C)
# 将拼接后的结果进行融合,也就是*Wo,最终得到每个patch的结果
x = self.proj(x)
x = self.proj_drop(x)
return x
完整代码
class Attention(nn.Module):
def __init__(self,
dim, # 输入token的维度数,也就是自注意力中输入a的维度
num_heads=8, # 注意力头个数
qkv_bias=False, # 是否使用偏置
qk_scale=None,
attn_drop_ratio=0.,
proj_drop_ratio=0.):
super(Attention, self).__init__()
self.num_heads = num_heads
head_dim = dim // num_heads # 每个head分到的维度数,一般是均分
self.scale = qk_scale or head_dim ** -0.5 # 一般是根号(head_dim),对应注意力的公式
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias) # 通过一个全连接层生成QKV,将维度数*3
self.attn_drop = nn.Dropout(attn_drop_ratio)
self.proj = nn.Linear(dim, dim) # 作为Wo,在融合结果时使用
self.proj_drop = nn.Dropout(proj_drop_ratio)
def forward(self, x):
# [batch_size, num_patches + 1, total_embed_dim]
# num_patches:划分出的patch个数,加1是加上class_token
# embed_dim:经过embedding层后得到
B, N, C = x.shape
'''
1.得到QKV
先将输入数据复制三份,然后按照QKV中的每个head进行均分
'''
# qkv(): -> [batch_size, num_patches + 1, 3 * total_embed_dim] 维度数*3
# reshape: -> [batch_size, num_patches + 1, 3, num_heads, embed_dim_per_head]
# 将最后一维的数据进行拆分,拆分为QKV,3对应着QKV,num_heads对应着每个head,embed_dim_per_head对应着每个head中qkv的dim
# permute: -> [3, batch_size, num_heads, num_patches + 1, embed_dim_per_head]
# 调整数据中的顺序,将3放到前面,方便对QKV进行处理与提取;将num_heads与N调换,让N与数据放在一起,这样方便使用每个head的数据
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
# [batch_size, num_heads, num_patches + 1, embed_dim_per_head]
# 提取出QKV
q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
'''
2.计算Q*K的转置,计算attention
'''
# transpose: -> [batch_size, num_heads, embed_dim_per_head, num_patches + 1] 对K进行转置,转置最后两维
# @: multiply -> [batch_size, num_heads, num_patches + 1, num_patches + 1]
attn = (q @ k.transpose(-2, -1)) * self.scale # QK矩阵 相乘,并进行scale操作。各个head中的qk相乘
attn = attn.softmax(dim=-1) # 对QK的结果运行softmax操作,也就是对结果的每一行进行softmax:dim=-1代表对每一行的数据进行?
attn = self.attn_drop(attn) # 最后进行一个下采样,得到V的权重
'''
3.与V相乘
'''
# @: multiply -> [batch_size, num_heads, num_patches + 1, embed_dim_per_head]
x = (attn @ v) # 与V相乘
# 将数据格式恢复为原样,注意力不会改变数据的尺寸
# transpose: -> [batch_size, num_patches + 1, num_heads, embed_dim_per_head]
# 将数据转变为对于每个patch中,各个head得到的结果
# reshape: -> [batch_size, num_patches + 1, total_embed_dim]
# 对最后两维的数据进行拼接,也就是对每个head的结果进行concat拼接
x = x.transpose(1, 2).reshape(B, N, C)
# 将拼接后的结果进行融合,也就是*Wo,最终得到每个patch的结果
x = self.proj(x)
x = self.proj_drop(x)
return x
MLP Block
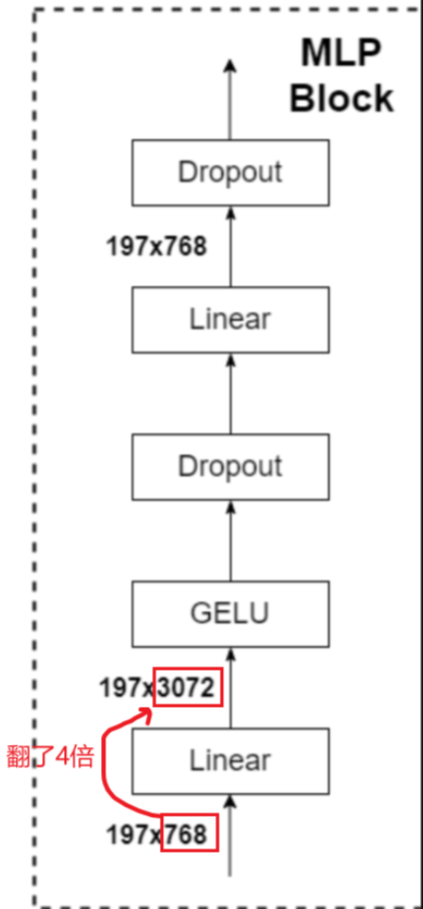
class Mlp(nn.Module):
"""
MLP as used in Vision Transformer, MLP-Mixer and related networks
"""
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features # 一般为in_features
hidden_features = hidden_features or in_features # 一般是in_features*4
self.fc1 = nn.Linear(in_features, hidden_features) # 第一个全连接层
self.act = act_layer() # 激活函数
self.fc2 = nn.Linear(hidden_features, out_features) # 第二个全连接层
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
Encoder Block
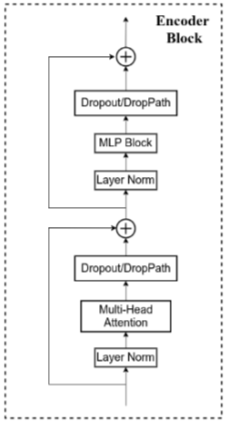
class Block(nn.Module):
def __init__(self,
dim,
num_heads, # head个数
mlp_ratio=4., # MLP中hidden_dim与in_dim的倍数关系
qkv_bias=False,
qk_scale=None,
drop_ratio=0., # 作用于Attention与MLP
attn_drop_ratio=0., # attention得到softmax(QK)后的dropout层
drop_path_ratio=0., # Encoder Block中使用的两个droppath层
act_layer=nn.GELU,
norm_layer=nn.LayerNorm):
super(Block, self).__init__()
self.norm1 = norm_layer(dim) # 第一个norm层
self.attn = Attention(dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale,
attn_drop_ratio=attn_drop_ratio, proj_drop_ratio=drop_ratio)
# NOTE: drop path for stochastic depth, we shall see if this is better than dropout here
self.drop_path = DropPath(drop_path_ratio) if drop_path_ratio > 0. else nn.Identity()
self.norm2 = norm_layer(dim) # 第二个norm层
mlp_hidden_dim = int(dim * mlp_ratio) # MLP中通道数翻倍的数量
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop_ratio)
def forward(self, x):
x = x + self.drop_path(self.attn(self.norm1(x))) # 第一个部分
x = x + self.drop_path(self.mlp(self.norm2(x))) # 第二个部分
return x
Transformer Encoder
self.blocks = nn.Sequential(*[
# 使用循环,加入各个Encoder Block,构造Transformer Encoder
Block(dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias,
qk_scale=qk_scale,drop_ratio=drop_ratio, attn_drop_ratio=attn_drop_ratio,
drop_path_ratio=dpr[i],norm_layer=norm_layer, act_layer=act_layer)
for i in range(depth) # 包含depth个Encoder Block
])
Classifier

'''
MLP Head
'''
x = self.norm(x) # [B,197,768]
if self.dist_token is None:
# 提取class_token x[:,0]=[B,embed_dim],在第二维度中提取
return self.pre_logits(x[:, 0]) # [B,768]
else: # 兼容 DeiT
return x[:, 0], x[:, 1]
'''
MLP Head
'''
if self.head_dist is not None: # 用于兼容DeiT模型
x, x_dist = self.head(x[0]), self.head_dist(x[1])
if self.training and not torch.jit.is_scripting():
# during inference, return the average of both classifier predictions
return x, x_dist
else:
return (x + x_dist) / 2
else:
x = self.head(x) # 输入到分类头,得到分类结果 [B,768]->[B,num_classes]
return x
CNN与Transformer的混合网络:Hybrid
Hybrid将传统CNN的特征提取和Transformer进行结合。
下图是以ResNet50作为特征提取器的Hybrid的网络结构,与ViT区别在于开始阶段会使用ResNet50网络进行特征提取。但这里的ResNet50与普通的ResNet50不同。
首先这里的R50的卷积层采用的StdConv2d不是传统的Conv2d,然后将所有的BatchNorm层替换成GroupNorm层。
而且在原Resnet50网络中,stage1重复堆叠3次,stage2重复堆叠4次,stage3重复堆叠6次,stage4重复堆叠3次。但是在这里的R50中,stage4的3次被集成到stage3中,因此stage3堆叠了9次。
通过R50 Backbone进行特征提取后,得到的特征矩阵为[14,14,1024],然后输入到Embedding层,要注意的是这个Embedding层中的卷积变为卷积核为1x1,步长为1,只是调整了channel为768。
后面的处理与ViT一样。

模型训练时一些注意事项
ViT在训练过程中,一般会进行预训练或加载已经训练好的权重,来减少训练的要求,接着针对任务进行模型的微调。
而在微调过程中,部分层是不需要训练的。越靠前的Transformer层越倾向于提取特征,而越靠后的则倾向于完成分类任务。
提取特征是一个客观的需求,无论任务如何,提取特征大差不差,因此在微调过程中,前面的层是可以冻结的。而后面的层是针对于当前任务的,因此需要进行微调。

















 5239
5239

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









