







文章目录
TensorBoard进阶
本教程使用TensorBoard可视化模型、数据和训练过程。展示了如何加载数据,通过定义为nn.Module子类的模型将其输入,在训练数据上训练该模型,并在测试数据上测试它。为了了解发生了什么,我们在模型训练时打印出一些统计数据,以了解训练是否正在进行。然而,我们可以做得更好:PyTorch与TensorBoard集成,TensorBoard是一种旨在可视化神经网络训练运行结果的工具,并且可以在训练时进行实时的观测。本教程使用Fashion-MNIST数据集说明了它的一些功能,该数据集可以使用torchvision.datasets读入PyTorch。
引导代码:直接运行,知道每个功能模块是干什么的就可以了。
# imports
import matplotlib.pyplot as plt
import numpy as np
import torch
import torchvision
import torchvision.transforms as transforms
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
# transforms
# 给下面的datasets做准备,就是对图像进行处理的,将图像数据转换为张量。
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))])
# datasets
# 创建并加载FashionMNIST训练集与测试集,并对图像数据进行了预处理。
trainset = torchvision.datasets.FashionMNIST('./data',
download=True,
train=True,
transform=transform)
testset = torchvision.datasets.FashionMNIST('./data',
download=True,
train=False,
transform=transform)
# dataloaders
# 定义了train dataloader与test dataloader,用于加载数据的。
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4,
shuffle=True, num_workers=2)
testloader = torch.utils.data.DataLoader(testset, batch_size=4,
shuffle=False, num_workers=2)
# constant for classes
# 类别标签
classes = ('T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle Boot')
# helper function to show an image
# (used in the `plot_classes_preds` function below)
# 显示图像的函数
def matplotlib_imshow(img, one_channel=False):
if one_channel:
img = img.mean(dim=0)
img = img / 2 + 0.5 # unnormalize
npimg = img.numpy()
if one_channel:
plt.imshow(npimg, cmap="Greys")
else:
plt.imshow(np.transpose(npimg, (1, 2, 0)))
# 定义了一个Net模型
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 6, 5) # 二维卷积
self.pool = nn.MaxPool2d(2, 2) # 最大池化
self.conv2 = nn.Conv2d(6, 16, 5) # 二维卷积
self.fc1 = nn.Linear(16 * 4 * 4, 120) # 全连接
self.fc2 = nn.Linear(120, 84) # 全连接
self.fc3 = nn.Linear(84, 10) # 全连接
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 4 * 4)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net()
criterion = nn.CrossEntropyLoss() # 交叉熵损失
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9) # SGD优化器
1.设置TensorBoard(重点✅)
SummaryWriter类是记录数据以供TensorBoard使用和可视化的主要入口。通过SummaryWriter(log_dir=None, comment='', purge_step=None, max_queue=10, flush_secs=120, filename_suffix='')创建一个SummaryWriter实例。关键参数解释:
- log_dir(str):
event文件的保存目录位置。默认值为runs/CURRENT_DATETIME_HOSTNAME,每次运行后都会更改。建议使用分层文件夹结构来比较运行。例如,传入“runs/exp1”、“runs/exp2”等。对于每个新实验进行比较。 - comment(str):comment后缀附加到默认log_dir后面。如果分配了log_dir,则此参数无效。
- filename_suffix(str) :filename_suffix后缀添加到log_dir目录中的所有事件文件名。
# create a summary writer with automatically generated folder name.
writer = SummaryWriter()
# folder location: runs/May04_22-14-54_s-MacBook-Pro.local/
# create a summary writer using the specified folder name.
writer = SummaryWriter("my_experiment")
# folder location: my_experiment
# create a summary writer with comment appended.
writer = SummaryWriter(comment="LR_0.1_BATCH_16")
# folder location: runs/May04_22-14-54_s-MacBook-Pro.localLR_0.1_BATCH_16/
Examples:
"""
coding:utf-8
* @Author:FHTT-Tian
* @name:temporary.py
* @Time:2024/7/15 星期一 16:09
* @Description: 模型在每个种子下都要执行训练,每个种子都有各自的train与vaild的loss,每个种子下执行SummaryWriter都会生成一个新的event文件,TensorBoard可视化的时候需要针对每个不同的event进行加载,所以使用filename_suffix给event文件添加后缀。以下是伪代码:
"""
from torch.utils.tensorboard import SummaryWriter
for s in seed:
set_random_seed(s)
model_train() # 模型训练
model_test() # 模型测试
writer = SummaryWriter('runs/',filename_suffix='.seed'+str(s)) # 实例化SummaryWriter对象
2.图像数据在TensorBoard中可视化
利用add_image(tag, img_tensor, global_step=None, walltime=None, dataformats='CHW')函数将图像数据添加到Writer中。
writer.add_image('tag', image_tensor)
Examples:
# get some random training images
dataiter = iter(trainloader)
images, labels = next(dataiter)
# create grid of images
img_grid = torchvision.utils.make_grid(images)
# show images
matplotlib_imshow(img_grid, one_channel=True)
# write to tensorboard
# 一个标签只对应一组图片,尽管这段运行多次,代码中呈现的是不同的图片组,但是写入tensorboard中的图片组仅是第一次运行所保存的图片组。
writer.add_image('four_fashion_mnist_images', img_grid)
注意:pillow版本应该低于10.0.0,否则会报错module 'pil.image' has no attribute 'antialias'。
接下来使用tensorboard --logdir runs命令启动TensorBoard,需注意,logdir对应的路径可以是绝对路径也可以是相对路径,但是绝对路径在Windows下需要用引号包括,Linux下不用。
tensorboard --logdir "D:\Jupyter\Introduction to Pytorch\runs"

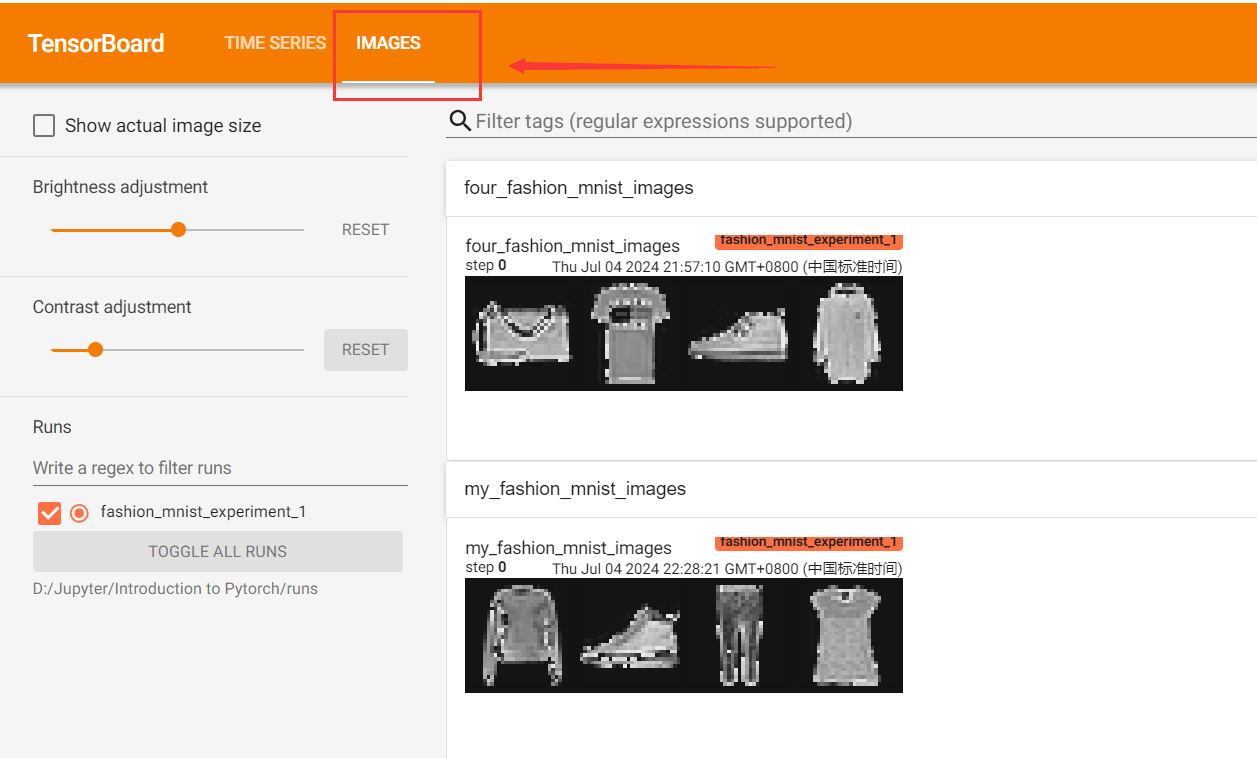
3.模型结构在TensorBoard中可视化(重点✅)
利用add_graph(model, input_to_model=None, verbose=False, use_strict_trace=True)函数将模型结构添加到Writer中。
writer.add_graph(model, input_to_model = torch.rand(1, 3, 224, 224))
Examples:
writer.add_graph(net, images)
writer.close()
刷新TensorBoard UI界面,会在“Graphs”选项卡看到模型结构。模型结构里面还有维度的变化,很方便我们去观察特征的维度变化。👍

4.高维数据在TensorBoard中低维可视化
writer.add_embedding(features,
metadata=class_labels,
label_img=images.unsqueeze(1))
Examples:
# helper function
def select_n_random(data, labels, n=100):
'''
Selects n random datapoints and their corresponding labels from a dataset
'''
assert len(data) == len(labels)
perm = torch.randperm(len(data))
return data[perm][:n], labels[perm][:n]
# select random images and their target indices
images, labels = select_n_random(trainset.data, trainset.targets)
# get the class labels for each image
class_labels = [classes[lab] for lab in labels]
# log embeddings
features = images.view(-1, 28 * 28)
writer.add_embedding(features,
metadata=class_labels,
label_img=images.unsqueeze(1))
writer.close()
在TensorBoard UI中找到Project选项卡,然后就会看到被投影到三维空间的图像数据。
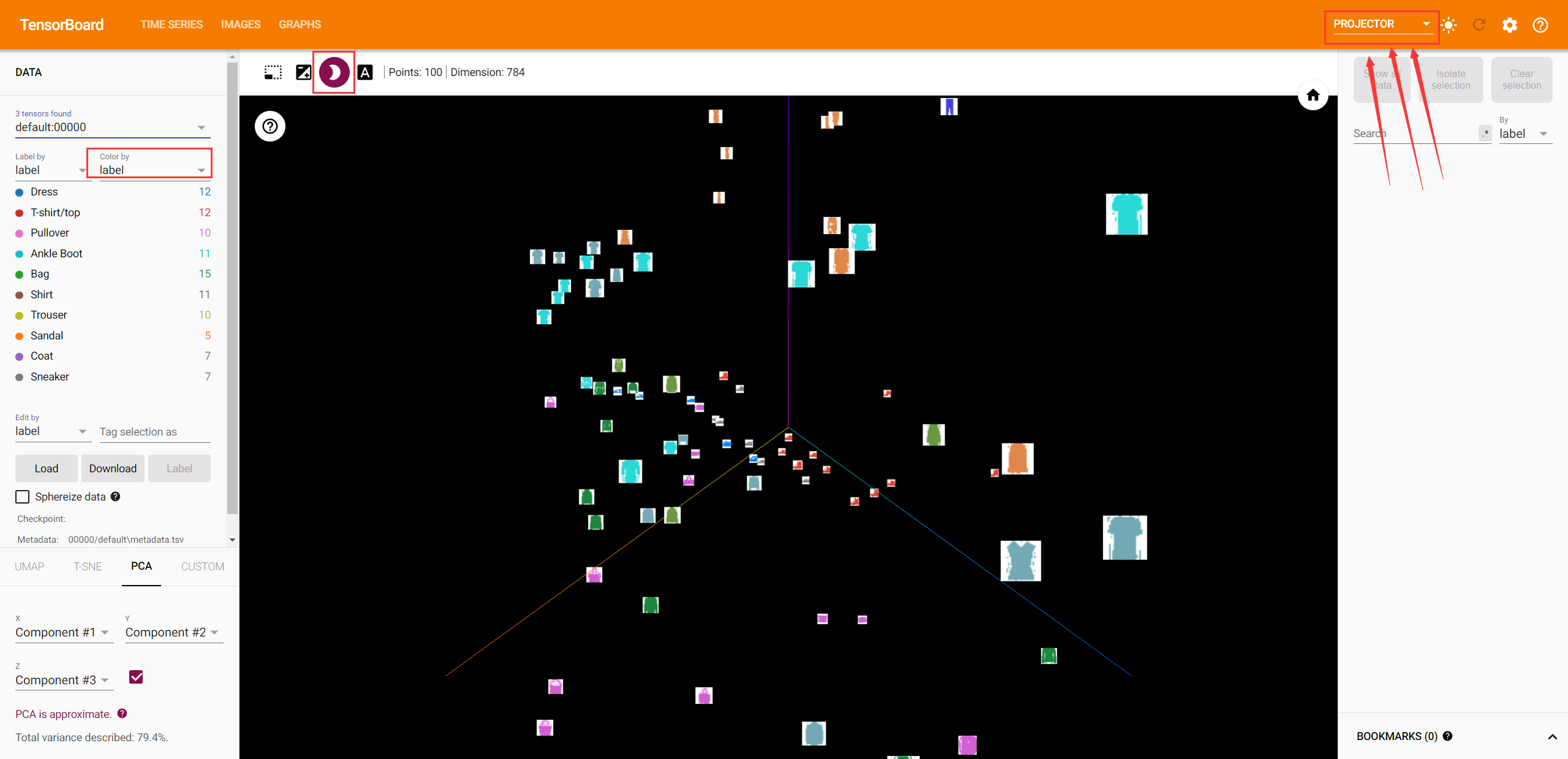
5.利用TensorBoard跟踪模型的训练过程(重点✅)
利用add_scalar(tag, scalar_value, global_step=None, walltime=None, new_style=False, double_precision=False)函数记录要跟踪的指标来观察模型的训练过程。
writer.add_scalar('loss', loss, epoch)
writer.add_scalar('accuracy', accuracy, epoch)
Examples:
# helper functions
def images_to_probs(net, images):
'''
Generates predictions and corresponding probabilities from a trained
network and a list of images
'''
output = net(images)
# convert output probabilities to predicted class
_, preds_tensor = torch.max(output, 1)
preds = np.squeeze(preds_tensor.numpy())
return preds, [F.softmax(el, dim=0)[i].item() for i, el in zip(preds, output)]
def plot_classes_preds(net, images, labels):
'''
Generates matplotlib Figure using a trained network, along with images
and labels from a batch, that shows the network's top prediction along
with its probability, alongside the actual label, coloring this
information based on whether the prediction was correct or not.
Uses the "images_to_probs" function.
'''
preds, probs = images_to_probs(net, images)
# plot the images in the batch, along with predicted and true labels
fig = plt.figure(figsize=(12, 48))
for idx in np.arange(4):
ax = fig.add_subplot(1, 4, idx+1, xticks=[], yticks=[])
matplotlib_imshow(images[idx], one_channel=True)
ax.set_title("{0}, {1:.1f}%\n(label: {2})".format(
classes[preds[idx]],
probs[idx] * 100.0,
classes[labels[idx]]),
color=("green" if preds[idx]==labels[idx].item() else "red"))
return fig
running_loss = 0.0
for epoch in range(1): # loop over the dataset multiple times
for i, data in enumerate(trainloader, 0):
# get the inputs; data is a list of [inputs, labels]
inputs, labels = data
# zero the parameter gradients
optimizer.zero_grad()
# forward + backward + optimize
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if i % 1000 == 999: # every 1000 mini-batches...
# ...log the running loss
# 记录的是每1000个mini-batch所对应的损失变化
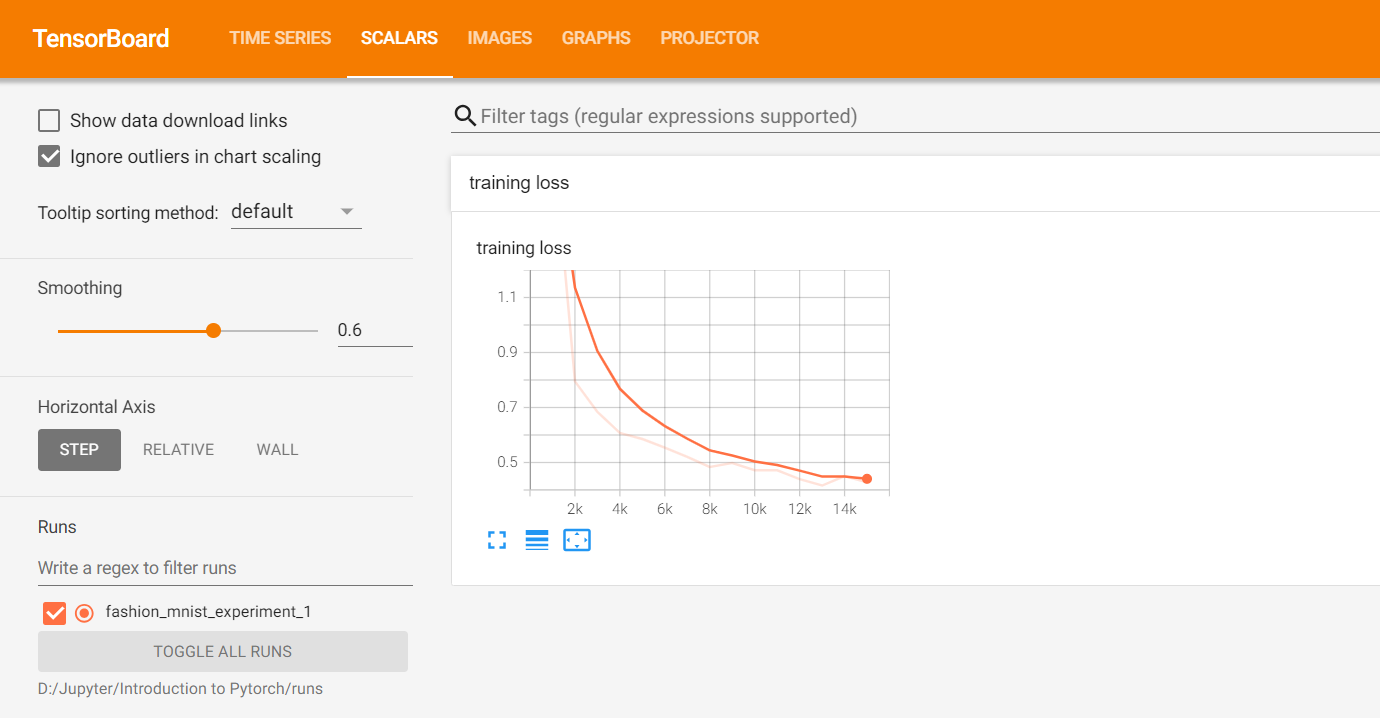
writer.add_scalar('training loss',
running_loss / 1000,
epoch * len(trainloader) + i)
# ...log a Matplotlib Figure showing the model's predictions on a random mini-batch
writer.add_figure('predictions vs. actuals',
plot_classes_preds(net, inputs, labels),
global_step=epoch * len(trainloader) + i)
running_loss = 0.0
print('Finished Training')
在TensorBoard UI中的Scalars选项卡查看loss的变化。
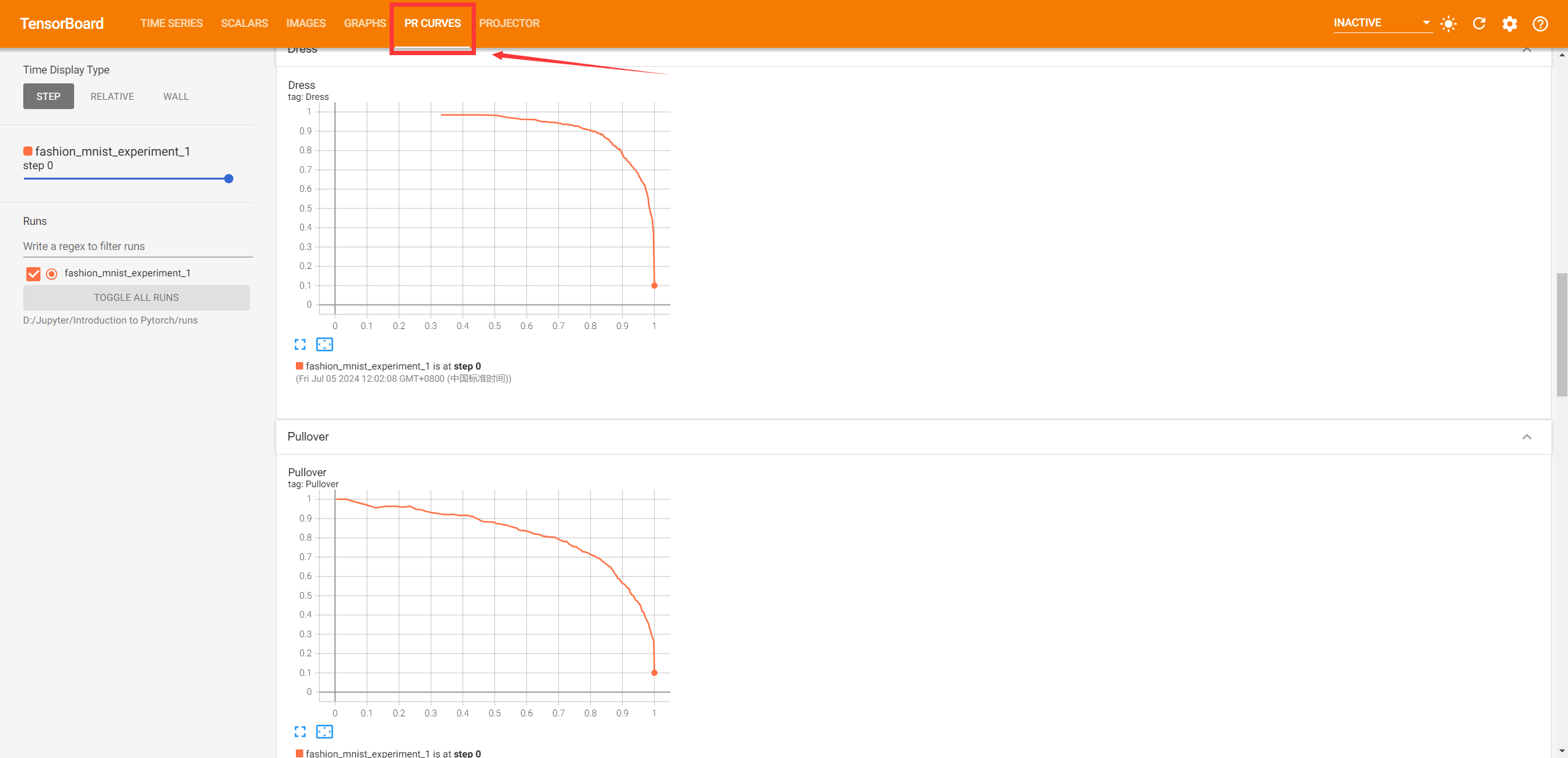
6.利用TensorBoard给每个类绘制PR曲线
writer.add_pr_curve(classes[class_index],
tensorboard_truth,
tensorboard_probs)
Examples:
# 1. gets the probability predictions in a test_size x num_classes Tensor
# 2. gets the preds in a test_size Tensor
# takes ~10 seconds to run
class_probs = []
class_label = []
with torch.no_grad():
for data in testloader:
images, labels = data
output = net(images)
class_probs_batch = [F.softmax(el, dim=0) for el in output]
class_probs.append(class_probs_batch)
class_label.append(labels)
test_probs = torch.cat([torch.stack(batch) for batch in class_probs])
test_label = torch.cat(class_label)
# helper function
def add_pr_curve_tensorboard(class_index, test_probs, test_label, global_step=0):
'''
Takes in a "class_index" from 0 to 9 and plots the corresponding
precision-recall curve
'''
tensorboard_truth = test_label == class_index
tensorboard_probs = test_probs[:, class_index]
writer.add_pr_curve(classes[class_index],
tensorboard_truth,
tensorboard_probs,
global_step=global_step)
writer.close()
# plot all the pr curves
for i in range(len(classes)):
add_pr_curve_tensorboard(i, test_probs, test_label)
在TensorBoard UI中的PR Curves选项卡查看每个类的精度-召回曲线(Precision-Recall Curve,简称 PR 曲线)。(PR 曲线功能:可以用于比较不同分类器或不同模型的性能。通过比较不同模型的 PR 曲线下的面积(Area Under the Curve, AUC),可以直观地评估哪种模型在特定类别上表现更优;对于多分类问题,每个类别都有对应的 PR 曲线,通过分析每个类别的 PR 曲线,可以发现模型在哪些类别上表现较好,在哪些类别上存在不足,从而针对性地进行改进。)
7.在TensorBoard中绘制训练与验证损失对比曲线(重点✅)
利用add_scalars(main_tag, tag_scalar_dict, global_step=None, walltime=None)函数跟踪多个标量数据(add_scalars是将多个标量数据的变化反映在同一图像中,add_scalar是将单个标量数据的变化反映在对应图像中)。利用add_scalars()函数,在TensorBoard中绘制训练与验证loss的对比曲线图。
writer.add_scalars('train-valid loss',
{'train-loss': train_loss, 'valid-loss': valid_loss},
epoch)
Examples:
# 将三个值sinx、cosx及tanx添加到带有标记的同一个标量图中。
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter()
r = 5
for i in range(100):
writer.add_scalars('run_14h', {'xsinx':i*np.sin(i/r),
'xcosx':i*np.cos(i/r),
'tanx': np.tan(i/r)}, i)
writer.close()

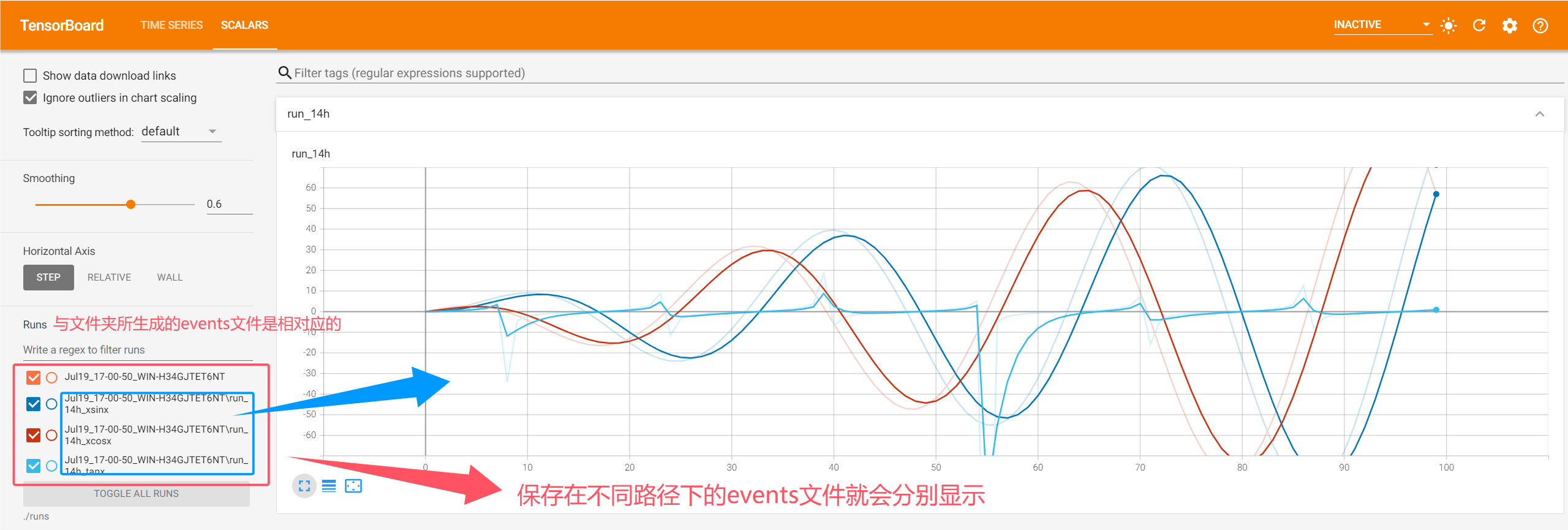
8.TensorBoard的跟踪参数曲线图线条紊乱的解决办法(重点✅)
原因:同时加载了同一路径下的多个events文件。

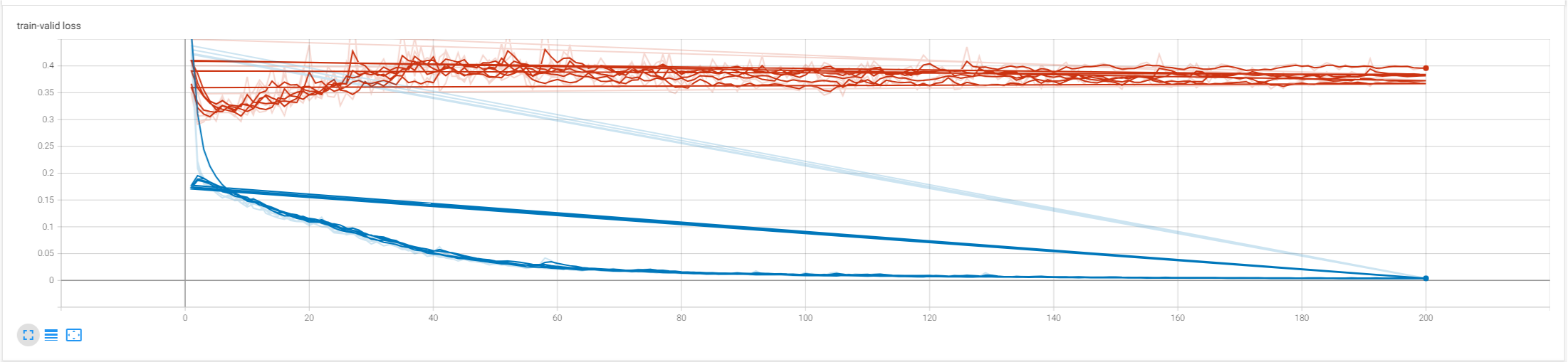
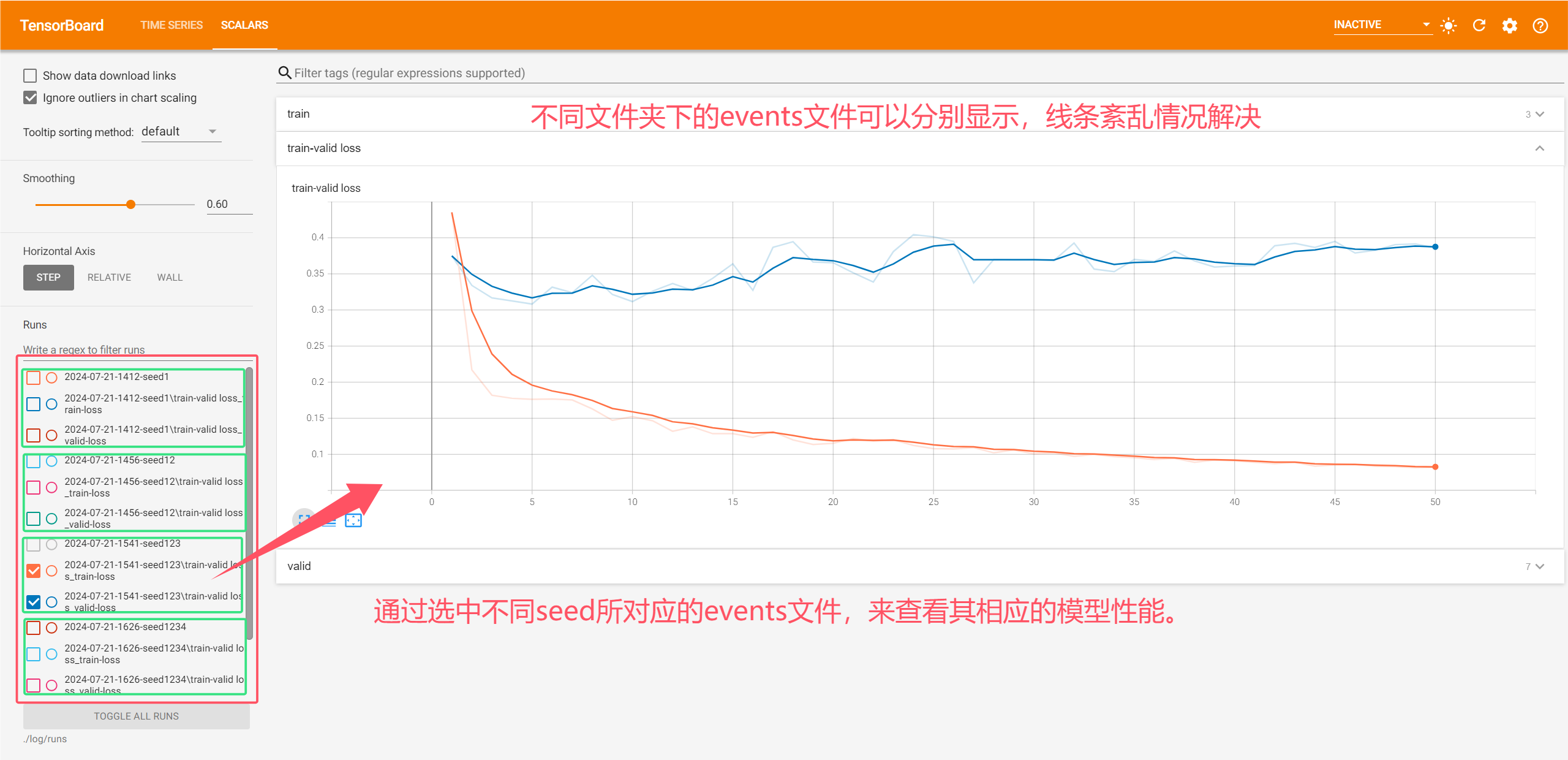
解决办法:将每次生成的events文件保存在不同的路径下(因为保存在不同路径下的events文件就会分别显示),所以使用时间戳作为路径名来解决线条紊乱的问题。
"""
coding:utf-8
* @Author:FHTT-Tian
* @name:temporary.py
* @Time:2024/7/15 星期一 16:09
* @Description: 使用时间戳+seed值作为路径名来解决线条紊乱的伪代码
"""
import datetime
from torch.utils.tensorboard import SummaryWriter
TIMESTAMP = datetime.datetime.now().strftime('%Y-%m-%d-%H%M')
for s in seed:
set_random_seed(s)
model_train() # 模型训练
model_test() # 模型测试
writer = SummaryWriter('runs/'+TIMESTAMP+'-seed'+str(s),
filename_suffix='.seed'+str(s))
writer.add_scalars('train-valid loss', {'train-loss': avg_loss, 'valid-loss': result_loss}, epoch) # add train-valid loss curve

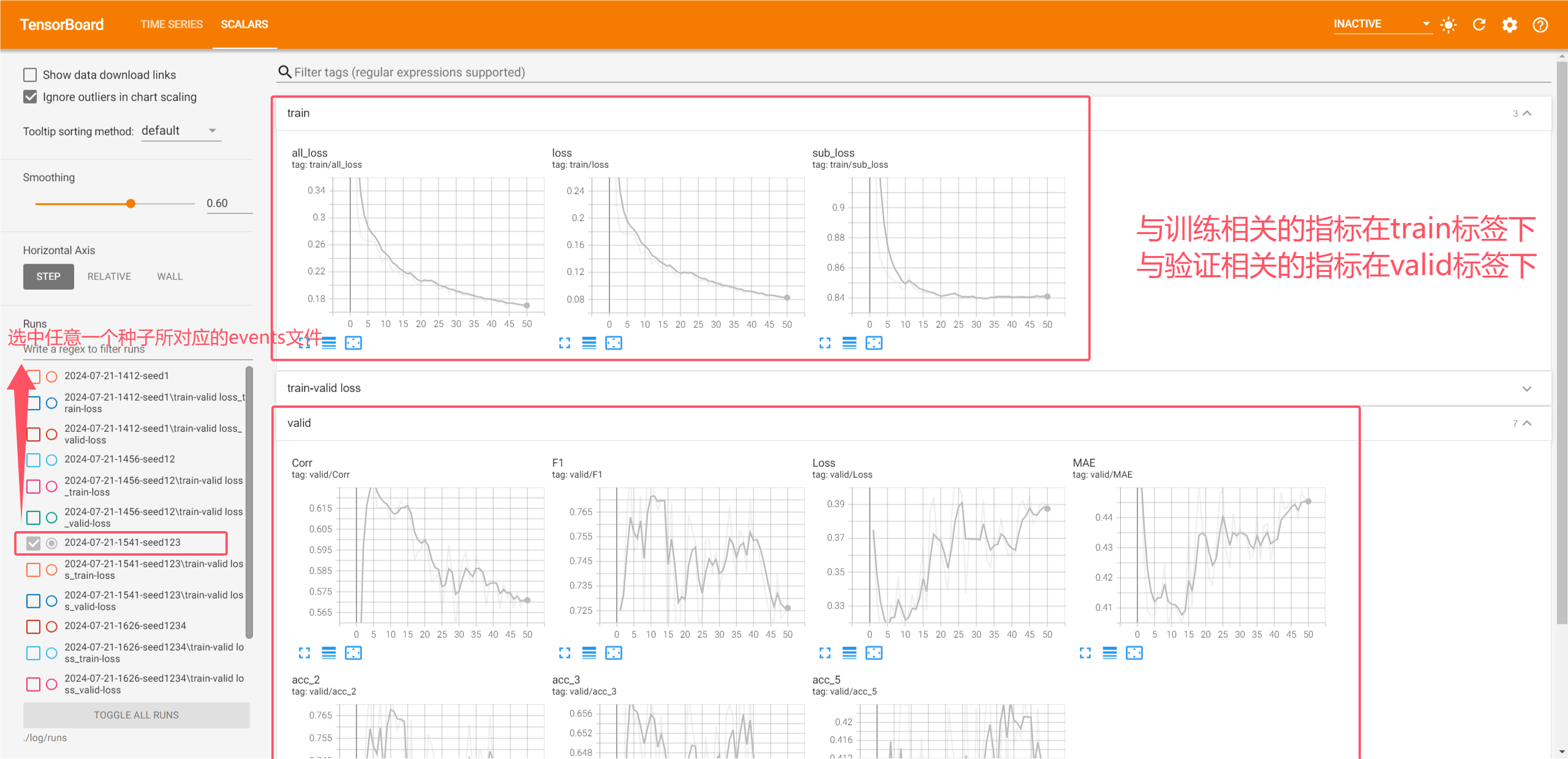
9.TensorBoard中通过分层命名图避免UI混乱
一个实验可以记录大量信息。为了避免UI混乱并获得更好的结果聚类,可以通过分层命名图来对它们进行分组。例如,训练的相关指标放到一起train/指标,验证的相关指标放到一起valid/指标。
writer.add_scalar('train/all_loss', avg_all_loss, epoch)
writer.add_scalar('train/loss', avg_loss, epoch)
writer.add_scalar('train/sub_loss', avg_sub_loss, epoch)
writer.add_scalar('valid/acc_2', result['Mult_acc_2'], epoch)
writer.add_scalar('valid/acc_3', result['Mult_acc_3'], epoch)
writer.add_scalar('valid/F1', result['F1_score'], epoch)
writer.add_scalar('valid/acc_5', result['Mult_acc_5'], epoch)
writer.add_scalar('valid/MAE', result['MAE'], epoch)
writer.add_scalar('valid/Corr', result['Corr'], epoch)
writer.add_scalar('valid/Loss', result_loss, epoch)
参考
- Visualizing Models, Data, and Training with TensorBoard
- 准确率、精确率、召回率、P-R曲线
- torch.utils.tensorboard
- 模型可视化工具 torchsummary (torchsummary 是一个模型可视化的工具,使用简单,可以可视化出模型每一层的输出shape,个人感觉比TensorBoard的模型可视化好用一点,用法很简单,参考github的README就可以)
😃😃😃


















 1634
1634

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









