







文章目录
UMDF:用于具有不确定缺失模态的多模态情感分析的统一自馏框架
总结:提出的UMDF框架解决了MSA任务中的缺失模态问题。UMDF通过蒸馏式分布监督和基于注意力的多粒度交互,产生了鲁棒的联合多模态表征。
文章信息
作者:Mingcheng Li,Dingkang Yang,Lihua Zhang
单位:复旦大学工程技术研究院、认知与智能技术实验室(CIT 实验室)
会议/期刊:The Thirty-Eighth AAAI Conference on Artificial Intelligence (AAAI 2024)
年份:2024
代码:暂未公开(2024.5.14)
数据集:MOSI、MOSEI、IEMOCAP
算力需求:NVIDIA Tesla V100
研究目的
大多数 MSA 研究都基于模态完整性假设。然而,现实世界中许多不可避免的因素会导致不确定的模态缺失,从而使固定的多模态融合方法失效。为此,作者提出了统一多模态缺失模态自蒸馏框架(UMDF)来处理 MSA 中的不确定模态缺失问题。–> 致力于解决由于遮挡、环境噪声等原因造成的不确定模态缺失和识别精度低下的问题。
研究内容
- 设计了一种统一的自蒸馏机制,通过单个网络内的双向知识转移,从多模态数据表征的一致分布中自动学习鲁棒的内在表征。双向知识转移途径可以监督模型在异构模态缺失案例之间保持相似的特征分布和对数分布。这种有效的途径抑制了对所学特征的单向依赖,并在两个方面带来益处:从更多模态到更少模态的知识转移有利于恢复丢失的模态信息,同时在相反的方向上增强了特定模态的特征。(知识蒸馏,教师网络与学生网络)
- 提出了一个多粒度跨模态交互模块,该模块对缺失模态逐步执行粗粒度和细粒度跨模态自适应,分层捕捉模态间的交互(跨模态元素相关性)和模态内的动态(长程的时序依赖关系),以渐进式地捕获互补的有价值语义。
- 引入了一个动态特征整合模块,并通过帧级别的自增强和选择性过滤策略过滤冗余特征,以生成精炼的多模态表征(获得更精细的表征)。
研究方法
1.模态缺失模拟

给定一个包含三种模态的多模态视频片段为 S = [ X L , X A , X V ] \boldsymbol{S}=[\boldsymbol{X}_{L},\boldsymbol{X}_{A},\boldsymbol{X}_{V}] S=[XL,XA,XV],其中 X L , X A , X V X_L,X_A,X_V XL,XA,XV 分别表示语言、音频和视觉模态。作者定义了两种模态缺失情况(两个异构模态缺失版本),来模拟真实世界场景中的整体挑战:1) 模态内缺失,表示模态序列中的某些帧级别的特征缺失;2) 模态间缺失,表示某些模态完全缺失。
目标是利用模态缺失的多模态数据来识别语篇级情感。
2.整体框架
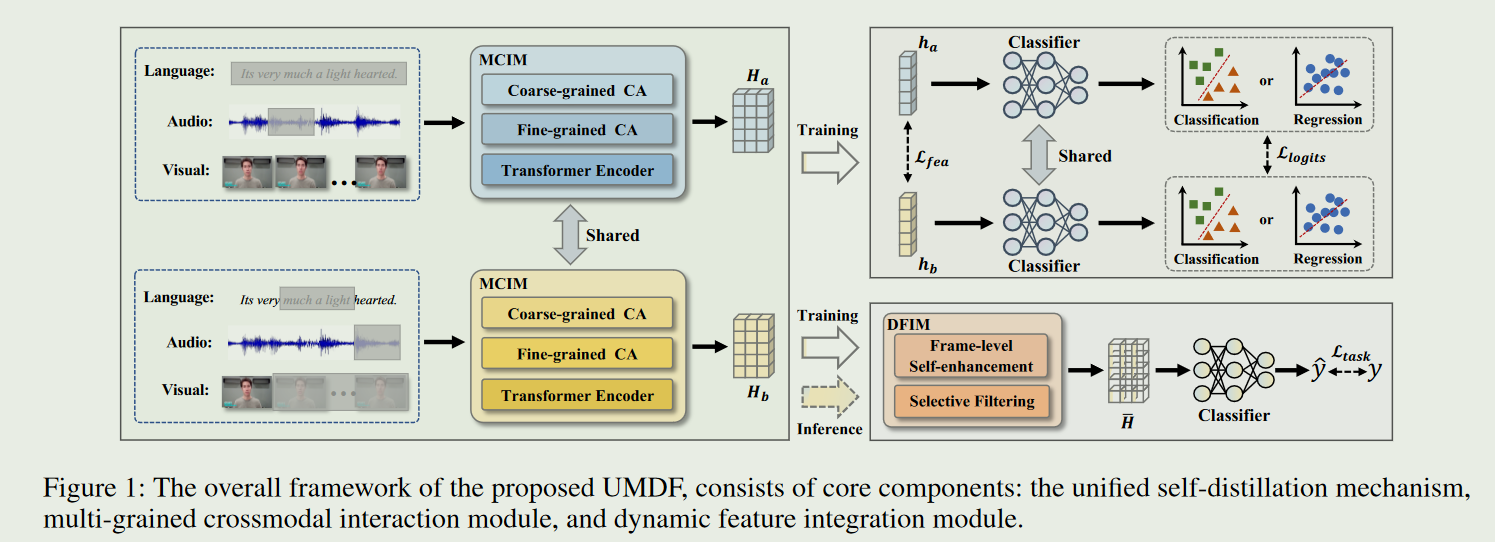
给定视频片段样本 S = [ X L , X A , X V ] \boldsymbol{S}=[\boldsymbol{X}_{L},\boldsymbol{X}_{A},\boldsymbol{X}_{V}] S=[XL,XA,XV],首先生成两个异构模态缺失版本 S a S_a Sa 和 S b S_b Sb。 S a S_a Sa 和 S b S_b Sb 被送入多粒度跨模态交互模块(MCIM),以获得联合多模态表征 H a H_a Ha 和 H b H_b Hb。然后,这两个多模态表征会经过两个分支:1) 通过自蒸馏机制实现特征级和对数级的一致监督,以充分学习模态间鲁棒的内在表征;2) 使用动态特征整合模块对特征进行增强和过滤,以获得精炼表征 H ‾ \overline{H} H。最后,该精炼表征 H ‾ \overline{H} H 被送入特定任务的全连接层,实现情感预测。
注:在推理阶段,会克隆测试样本的副本,并将它们一起作为多模态情感分析模型的双流输入。
3.Unified Self-distillation Mechanism
自蒸馏是一种完全监督模式,它仅从标注数据中挖掘单个网络的潜在能力,无需辅助模型。所提出的统一自蒸馏机制通过软标签,在单一网络内的异构模态缺失样本之间双向传输知识。与地面实况标签相比,软标签包含更完整的结构化信息。知识的相互传递会引导模型增强可用语义,恢复缺失语义,从而产生更有价值的内在表征。在实践中,对于每个mini-batch,会根据其中的每个样本随机生成两个异构模态缺失版本(包括模态完整的情况),并鼓励它们通过共享网络获得一致的语义特征(即特征分布一致性和对数分布一致性)。
3.1Feature Distillation
采用最大均值差异(MMD)作为非参数度量方法来测量两个特征分布(即 H a H_a Ha 和 H b H_b Hb)之间的差异。MMD 已被广泛应用于领域适应,以估计两个领域之间的差异,它在计算和优化方面具有良好的鲁棒性和效率。MMD 是一种内核双样本检验,根据观察样本,接受或拒绝零假设 p = q p = q p=q。
从形式上看,MMD 定义了以下差异度量:
D
H
(
p
,
q
)
≜
∥
E
p
[
ϕ
(
S
a
)
]
−
E
q
[
ϕ
(
S
b
)
]
∥
H
2
\mathcal{D}_{\mathcal{H}}(p,q)\triangleq\left\|\mathbf{E}_p\left[\phi\left(S_a\right)\right]-\mathbf{E}_q\left[\phi\left(S_b\right)\right]\right\|_{\mathcal{H}}^2
DH(p,q)≜∥Ep[ϕ(Sa)]−Eq[ϕ(Sb)]∥H2
k ( S a , S b ) = ⟨ ϕ ( S a ) , ϕ ( S b ) ⟩ k(S_a,S_b)=\langle\phi(S_a),\phi(S_b)\rangle k(Sa,Sb)=⟨ϕ(Sa),ϕ(Sb)⟩
MMD 的核心理论是,当且仅当
D
H
(
p
,
q
)
=
0
\mathcal{D}_{\mathcal{H}}(p,q)=0
DH(p,q)=0 时,假设
p
=
q
p = q
p=q 成立。在实践中,MMD 的无偏估计值可按以下方式计算:
D
^
H
(
p
,
q
)
=
∥
1
n
∑
i
=
1
n
ϕ
(
S
a
)
−
1
n
∑
i
=
1
n
ϕ
(
S
b
)
∥
H
2
\hat{\mathcal{D}}_\mathcal{H}(\boldsymbol{p},\boldsymbol{q})=\left\|\frac1n\sum_{i=1}^n\phi\left(\boldsymbol{S}_a\right)-\frac1n\sum_{i=1}^n\phi\left(\boldsymbol{S}_b\right)\right\|_\mathcal{H}^2
D^H(p,q)=
n1i=1∑nϕ(Sa)−n1i=1∑nϕ(Sb)
H2
特征蒸馏损失:->降低损失使得特征分布一致
L
f
e
a
=
1
n
∑
i
=
1
n
D
^
H
(
h
a
,
h
b
)
\mathcal{L}_{fea}=\frac1n\sum_{i=1}^n\hat{\mathcal{D}}_\mathcal{H}(\boldsymbol{h}_a,\boldsymbol{h}_b)
Lfea=n1i=1∑nD^H(ha,hb)
| 符号 | 含义 |
|---|---|
| H \mathcal{H} H | 特征内核 k 的再生核希尔伯特空间(RKHS) |
| k ( S a , S b ) k(S_a,S_b) k(Sa,Sb) | 内核 k |
| ϕ ( ⋅ ) \phi(\cdot) ϕ(⋅) | 表示将原始样本映射到 RKHS 的某种特征映射 |
| n n n | mini-batch 中的样本数 |
| h a h_a ha 与 h b h_b hb | 表示联合多模态表征 H a H_a Ha 与 H b H_b Hb 的最后元素 |
3.2Logits Distillation
为了最小化两个对数之间的分布差异,作者构建了软标签来监督学习。值得注意的是,提出的统一自蒸馏机制可同时应用于回归和分类任务,并具有很高的可扩展性。
在分类任务中,使用 Jensen-Shanno (JS) 发散作为差异度量,它解决了 Kullback-Leible (KL) 发散不对称的问题,可以更好地度量分布之间的差异。
K
L
KL
KL 发散表示为
D
K
L
(
p
b
∥
p
a
)
=
−
1
n
∑
i
=
1
n
p
(
x
b
)
log
p
(
x
a
)
p
(
x
b
)
\mathcal{D}_{KL}\left(\boldsymbol{p}_b\|\boldsymbol{p}_a\right)=-\frac1n\sum_{i=1}^n\boldsymbol{p}\left(\boldsymbol{x}_b\right)\log\frac{\boldsymbol{p}\left(\boldsymbol{x}_a\right)}{\boldsymbol{p}\left(\boldsymbol{x}_b\right)}
DKL(pb∥pa)=−n1i=1∑np(xb)logp(xb)p(xa)
对数蒸馏损失:
L
l
o
g
i
t
s
=
D
J
S
(
f
y
(
h
a
)
∣
∣
f
y
(
h
b
)
)
,
=
1
2
(
D
K
L
(
f
y
(
h
a
)
∣
∣
M
)
)
+
D
K
L
(
f
y
(
h
b
)
∣
∣
M
)
)
,
\begin{aligned} \mathcal{L}_{logits}& =\mathcal{D}_{JS}(f_y(\boldsymbol{h}_a)||f_y(\boldsymbol{h}_b)), \\ &=\frac12(\mathcal{D}_{KL}(f_y(\boldsymbol{h}_a)||M))+\mathcal{D}_{KL}(f_y(\boldsymbol{h}_b)||M)), \end{aligned}
Llogits=DJS(fy(ha)∣∣fy(hb)),=21(DKL(fy(ha)∣∣M))+DKL(fy(hb)∣∣M)),
在回归任务中,使用平均平方误差(MSE)估算两个对数之间的差异,这有利于网络收敛,可以对较大的预测误差进行惩罚。对数蒸馏损失表示为:->降低损失使得对数分布一致
L
l
o
g
i
t
s
=
D
M
S
E
=
1
n
∑
i
=
1
n
(
f
y
(
h
a
)
−
f
y
(
h
b
)
)
2
.
\mathcal{L}_{logits}=\mathcal{D}_{MSE}=\frac1n\sum_{i=1}^n\left(f_y(\boldsymbol{h}_a)-f_y(\boldsymbol{h}_b)\right)^2.
Llogits=DMSE=n1i=1∑n(fy(ha)−fy(hb))2.
| 符号 | 含义 |
|---|---|
| p b p_b pb | p b p_b pb 是作为软标签的目标概率,用于监督预测概率 p a p_a pa 的学习。 |
| f y f_y fy | f y f_y fy 是一个计算对数的全连接层 |
| M M M | M M M 是 f y ( h a ) f_y(\boldsymbol{h}_a) fy(ha) 和 f y ( h b ) f_y(\boldsymbol{h}_b) fy(hb) 的平均分布 |
4.Multi-grained Crossmodal Interaction Module
模态异质性通常会导致多模态融合中的分布差距和信息冗余,从而产生与任务无关的语义和模糊的多模态联合表征。此外,虽然之前的研究在缺失模态的 MSA 方面取得了一些进展,但这些研究只考虑了独立模态之间成对的方向性交互,从而导致了非稳健的联合表征和无效的元素相关性。为解决这一问题,作者提出了多粒度跨模态交互模块(MCIM),通过同时建模模态间交互和模态内动态,彻底探索缺失模态元素间的自然相关性。具体来说,MCIM 依次执行粗粒度和细粒度的跨模态交互。这种分层互动范式激发了不完整模态逐步重建缺失语义的潜力。
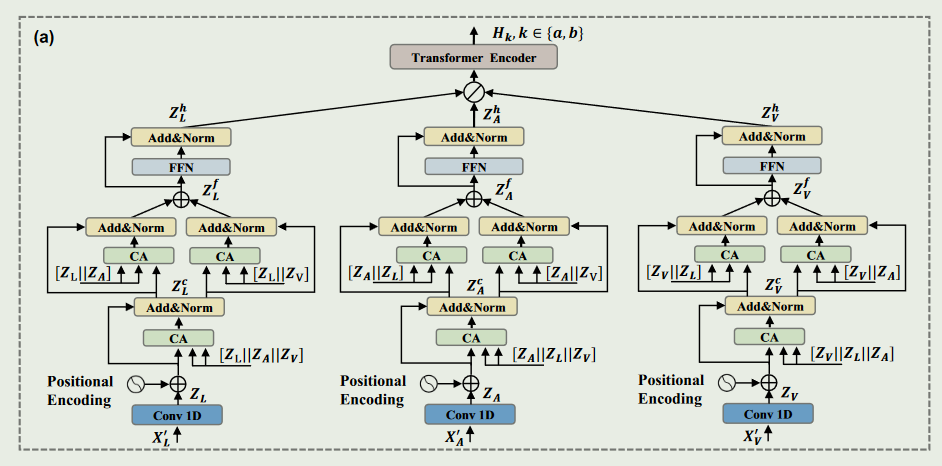
多粒度跨模态交互模块(MCIM)由多个多头Crossmodal Attention、LayerNorm 和 FFN 组成。以语言模态作为目标模态为例介绍 MCIM,首先将不完整模态 X m ′ X_{m}^{\prime} Xm′输入到 kernel 大小为 3x3 的一维时空卷积层中,得到具有相同维度的模态表征 X m ′ \boldsymbol{X}_m^{\prime} Xm′。然后,将位置嵌入扩展到 X m ′ \boldsymbol{X}_m^{\prime} Xm′ 得到低级表征 Z m Z_m Zm。之后,将三种模态的低级表征连接起来获得粗粒度表征 Z L A V Z_{LAV} ZLAV 与两个细粒度表征 Z L A Z_{LA} ZLA和 Z L V Z_{LV} ZLV。利用得到的粗粒度表征与细粒度表征,使其相互作用,得到交互后的表征 Z L f Z_L^f ZLf 。最后,将 Z L f Z_L^f ZLf 送入 FFN,并使用 LayerNorm 与残差连接得到语言模态的高级表征 Z L h Z_L^h ZLh 。其余两种模态也是同样的操作,这样就得到了对应模态的高级表征 Z L h , Z A h , Z V h Z_L^h,Z_A^h,Z_V^h ZLh,ZAh,ZVh。
注意:通过将 MCIM 堆叠了 D 层,来逐步补充和丰富模态表征的情感语义。
X s → t = C A ( X s , X t ) = s o f t m a x ( X t W Q t W K s ⊤ X s ⊤ d k ) X s W V s , X t = L N ( X t + X s → t ) . X ^ m ′ = W 3 × 3 ( X m ′ ) Z L A V = [ Z L , Z A , Z V ] Z L A = [ Z L , Z A ] Z L V = [ Z L , Z V ] Z L c = L N ( C A ( Z L A V , Z L ) + Z L ) Z L f = L N ( C A ( Z L A , Z L c ) + Z L c ) + L N ( C A ( Z L V , Z L c ) + Z L c ) . Z L h = L N ( F θ ( Z L f ) + Z L f . \boldsymbol{X}_{s\to t}=\mathrm{CA}(\boldsymbol{X}_s,\boldsymbol{X}_t)=\mathrm{softmax}(\frac{\boldsymbol{X}_tW_{\boldsymbol{Q}_t}W_{\boldsymbol{K}_s}^\top\boldsymbol{X}_s^\top}{\sqrt{d_k}})\boldsymbol{X}_s\boldsymbol{W}_{\boldsymbol{V}_s},\\ \boldsymbol{X}_t=\mathrm{LN}(\boldsymbol{X}_t+\boldsymbol{X}_{s\to t}).\\ \hat{\boldsymbol{X}}_m^{\prime}=\boldsymbol{W}_{3\times3}(\boldsymbol{X}_m^{\prime})\\ Z_{LAV}=[Z_L,Z_A,Z_V] \\ Z_{LA}=[Z_L,Z_A] \\ Z_{LV}=[Z_L,Z_V] \\ Z_L^c=\mathrm{LN}(\mathrm{CA}(Z_{LAV},Z_L)+Z_L) \\ Z_L^f=\mathrm{LN}(\mathrm{CA}(Z_{LA},Z_L^c)+Z_L^c)+\mathrm{LN}(\mathrm{CA}(Z_{LV},Z_L^c)+Z_L^c).\\ Z_L^h=\mathrm{LN}(\mathcal{F}_\theta(\boldsymbol{Z}_L^f)+\boldsymbol{Z}_L^f. Xs→t=CA(Xs,Xt)=softmax(dkXtWQtWKs⊤Xs⊤)XsWVs,Xt=LN(Xt+Xs→t).X^m′=W3×3(Xm′)ZLAV=[ZL,ZA,ZV]ZLA=[ZL,ZA]ZLV=[ZL,ZV]ZLc=LN(CA(ZLAV,ZL)+ZL)ZLf=LN(CA(ZLA,ZLc)+ZLc)+LN(CA(ZLV,ZLc)+ZLc).ZLh=LN(Fθ(ZLf)+ZLf.
最终,将 Z L h , Z A h , Z V h Z_L^h,Z_A^h,Z_V^h ZLh,ZAh,ZVh 拼接起来,并送入一个transformer encoder中实现进一步的交互,得到 H k ∈ R T m × 3 d with k ∈ { a , b } \boldsymbol{H}_k\in\mathbb{R}^{T_m\times3d}\text{ with }k\in\{a,b\} Hk∈RTm×3d with k∈{a,b} 。
| 符号 | 含义 |
|---|---|
| X s X_s Xs | 源模态, s ∈ { L , A , V } s\in\{L,A,V\} s∈{L,A,V} |
| X t X_t Xt | 目标模态, t ∈ { L , A , V } t\in\{L,A,V\} t∈{L,A,V} |
| F θ ( ⋅ ) \mathcal{F}_\theta(\cdot) Fθ(⋅) | 全连接层FFN |
5.Dynamic Feature Integration Module
模态缺失会模糊样本中有价值的情感语义,导致冗余的联合多模态表征。为此,作者提出了一种动态特征整合模块(DFIM),以实现对两种异构缺失模态表征的自适应信息整合。其核心理念是保留和增强不完整模态中的有益语义,并过滤冗余信息。

DFIM 接收由异构模态缺失版本样本生成的联合多模态表征
H
k
H_k
Hk 作为输入。首先,利用帧级的自我增强策略来增强联合多模态表征。(先通过全连接层对
H
k
H_k
Hk 进行维度的调整。然后将Softmax函数应用于
H
^
k
\hat{\boldsymbol{H}}_k
H^k,得到得分矩阵
M
k
M_k
Mk(
M
k
M_k
Mk中的第
i
i
i个条目代表
H
^
k
\hat{\boldsymbol{H}}_k
H^k中的第
i
i
i个帧的重要性)。最后,将联合多模态表征
H
k
H_k
Hk与得分矩阵
M
k
M_k
Mk相乘,得到自增强表征
H
~
k
\tilde{H}_k
H~k)
H
^
k
=
F
k
(
H
k
;
W
θ
)
∈
R
T
m
×
1
M
k
=
s
o
f
t
m
a
x
(
H
^
k
)
H
~
k
=
M
k
⊙
H
k
\hat{\boldsymbol{H}}_k=\mathcal{F}_k(\boldsymbol{H}_k;\boldsymbol{W}_\theta)\in\mathbb{R}^{T_m\times1} \\ M_k=softmax(\hat{\boldsymbol{H}}_k) \\ \tilde{H}_k=M_k \odot H_k
H^k=Fk(Hk;Wθ)∈RTm×1Mk=softmax(H^k)H~k=Mk⊙Hk
然后,利用一种选择性过滤机制,过滤联合多模态表征中的冗余信息,同时保留情感语义。(将上一步的自增强表征
H
~
k
\tilde{H}_k
H~k,首先进行拼接,然后通过一个 3x3 的卷积以及 sigmoid 激活函数得到
u
u
u值,利用该
u
u
u值对自增强表征
H
~
k
\tilde{H}_k
H~k进行过滤,获得更精细的多模态表征
H
e
H_e
He ,最后将该表征
H
e
H_e
He送入到一个transformer encoder中实现进一步的整合,产生
H
‾
\overline{H}
H。
H
‾
\overline{H}
H的最后一个元素用于进行预测,通过全连接层获得预测值
y
^
\hat{y}
y^ )
μ
=
σ
(
W
3
×
3
(
[
H
~
a
;
H
~
b
]
)
)
,
H
e
=
μ
⊙
H
~
a
+
(
1
−
μ
)
⊙
H
~
b
,
H
‾
=
T
r
a
n
s
f
o
r
m
e
r
E
n
c
o
n
d
e
r
(
H
e
)
\mu=\sigma\left(\boldsymbol{W}_{3\times3}([\tilde{\boldsymbol{H}}_{a};\tilde{\boldsymbol{H}}_{b}])\right),\\H_{e}=\mu\odot\tilde{H}_{a}+(1-\mu)\odot\tilde{\boldsymbol{H}}_{b},\\ \overline{H} = TransformerEnconder(H_e)
μ=σ(W3×3([H~a;H~b])),He=μ⊙H~a+(1−μ)⊙H~b,H=TransformerEnconder(He)
| 符号 | 含义 |
|---|---|
| σ \sigma σ | sigmoid激活函数 |
| ⊙ \odot ⊙ | 矩阵相乘,Hadamard product |
| ⊘ \oslash ⊘ | 连接操作 |
6.Loss Fuction
L t o t a l = L t a s k + λ 1 L f e a + λ 2 L l o g i t s \mathcal{L}_{total}=\mathcal{L}_{task}+\lambda_{1}\mathcal{L}_{fea}+\lambda_{2}\mathcal{L}_{logits} Ltotal=Ltask+λ1Lfea+λ2Llogits
对于分类和回归任务,分别使用 cross-entropy 损失和 MSE 损失作为任务损失 L t a s k \mathcal{L}_{task} Ltask。
实验分析
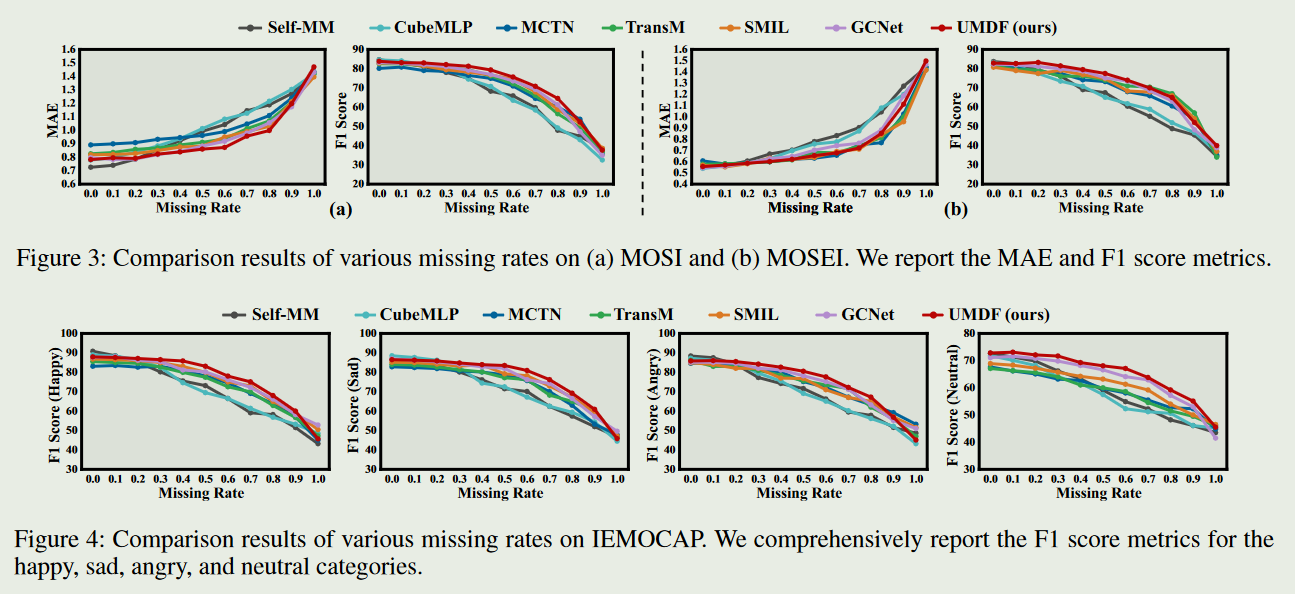
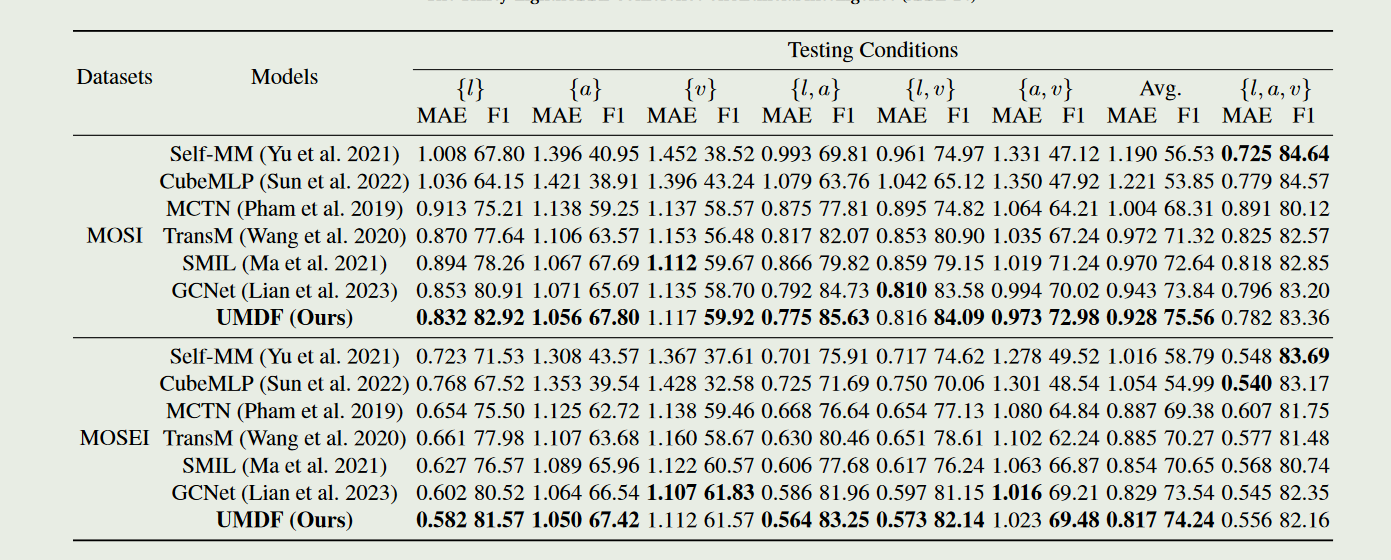
- 作者比较了UMDF与六种代表性的最先进方法在单模态和多模态缺失情况下的鲁棒性和有效性。在单模态缺失情况下,UMDF表现最优,其自我蒸馏机制实现了最强的鲁棒性。所有模型的性能都随着缺失率的增加而下降,表明缺失会导致情感语义的丢失。在完整模态测试条件下,UMDF优于以前的缺失模态方法,并与完整模态方法竞争。(在单模态缺失情况下,缺失模态方法优于完整模态方法,因为它们的训练范式专注于从不完整数据中捕获有价值的语义并补充多模态表征)
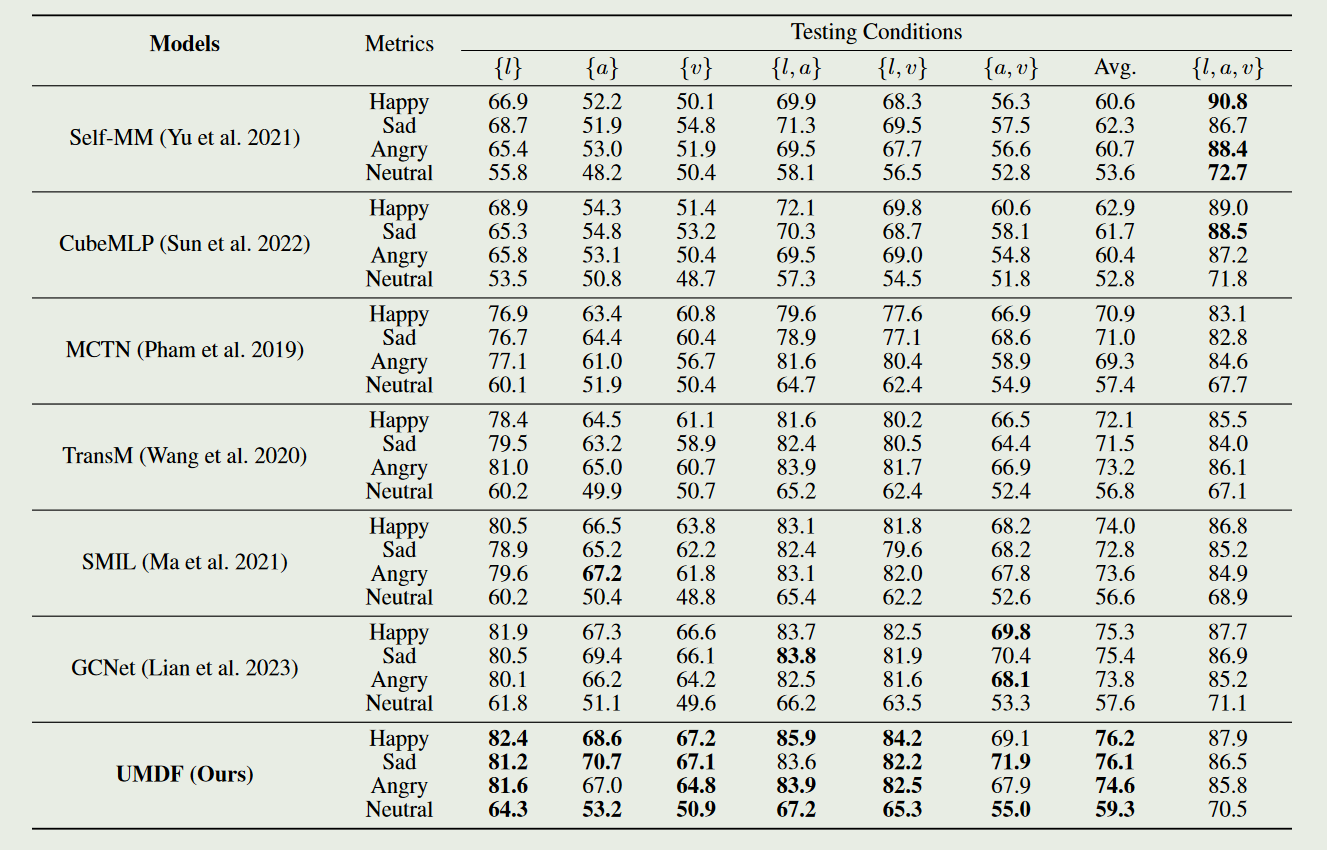
- 作者在MOSI数据集上进行了全面的消融研究,验证了不同组件的必要性。结果表明,双向知识转移对于恢复缺失元素的语义至关重要;分层建模跨模态交互对于逐步重现缺失语义至关重要;自适应增强和过滤不同模态的语义有助于提高模型性能。

- 为了直观地显示 UMDF 对模态缺失的鲁棒性,作者将 UMDF 和其他方法在 MOSI 数据集上的联合表征分布可视化。测试条件设定为只有语言模态可用,模态内缺失率p = 0.5。相比之下,UMDF的判别能力最强,可以有效地将不同的情感表征分离开。

😃😃😃


















 1023
1023

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









