







HSCL:多模态情感分析的分层监督对比学习
总结:采用了层次化对比学习结构,以有效对齐和融合各种模态。此外,通过监督对比回归,旨在定义一个嵌入根据标签接近性对齐的子空间。这一策略在多个层次上丰富了表征。
文章信息
作者:Kezhou Chen,Shuo Wang
单位:中国科学技术大学-教育部脑启发智能感知与认知重点实验室
会议/期刊:MultiMedia Modeling(CCF C)
题目:Hierarchical Supervised Contrastive Learning for Multimodal Sentiment Analysis
发布日期:2024 年 1 月 28 日
代码:https://github.com/Turdidae810/HSCL
数据集:CMU-MOSI、CMU-MOSEI
算力要求:Nvidia RTX 3090 GPU(24G)
研究目的
弥补各种模态之间存在的语义差异,解决模态异构性的问题。
研究内容
将监督对比学习(SCL)引入 MSA 任务,提出了一种层次化监督对比学习方法(HSCL),以对齐来自不同模态的内容,包括单模态表征和双模态融合特征。同时,使用标签来约束对齐的表征,以保留丰富的情感语义。
- 引入了有监督的对比学习,并提出了一种分层训练策略,即从低层和高层特征表征中捕捉情感。
- 设计了self-attention和cross-attention模块,以融合来自不同模态数据的表征,从而提供更有效的情感内容。
- 结果表明,HSCL 在两个公开的多模态情感分析数据集上取得了最先进的性能。
研究方法
1.总体结构
对于三种不同类型的数据,采用不同的特征提取器将这些数据转换成具有代表性的特征。随后,采用有监督的对比回归来调整这些单模态表征。同时,设计了两种跨模态注意力结构来融合不同的表征,并使用高级监督对比学习来衡量模态间的关系。最后,这一过程会产生任务对齐的多模态表征,可以有效预测给定视频中的情感。

2.单模态表征提取
首先,使用BERT提取文本模态特征,使用COVAREP以及Facet结合Transformer提取音频模态和视觉模态特征。
E
t
=
B
E
R
T
(
X
t
;
θ
t
B
E
R
T
)
,
E
m
=
Transformer
(
X
m
;
θ
m
T
r
a
n
s
f
o
r
m
e
r
)
,
m
∈
{
a
,
v
}
,
\begin{aligned}&\mathbf{E}_t=\mathrm{BERT}(\mathbf{X}_t;\theta_t^\mathrm{BERT}),\\&\mathbf{E}_m=\text{Transformer}(\mathbf{X}_m;\theta_m^\mathrm{Transformer}),m\in\{a,v\},\end{aligned}
Et=BERT(Xt;θtBERT),Em=Transformer(Xm;θmTransformer),m∈{a,v},
然后,利用对比学习对齐不同模态。为了将每个单模态表征投射到同一维度上,将其通过一个全连接层。(
R
m
R_m
Rm代表每个序列开始的 [cls] token)
R
^
m
=
F
C
m
(
R
m
;
θ
m
F
C
)
,
m
∈
{
a
,
v
,
m
}
,
\hat{R}_m=\mathrm{FC}_m(R_m;\theta_m^{\mathrm{FC}}),m\in\{a,v,m\},
R^m=FCm(Rm;θmFC),m∈{a,v,m},
接着在文本-语音模态、文本-视觉模态之间采用监督对比回归方法,来构造一个多模态嵌入空间。样本对构建如下图所示:
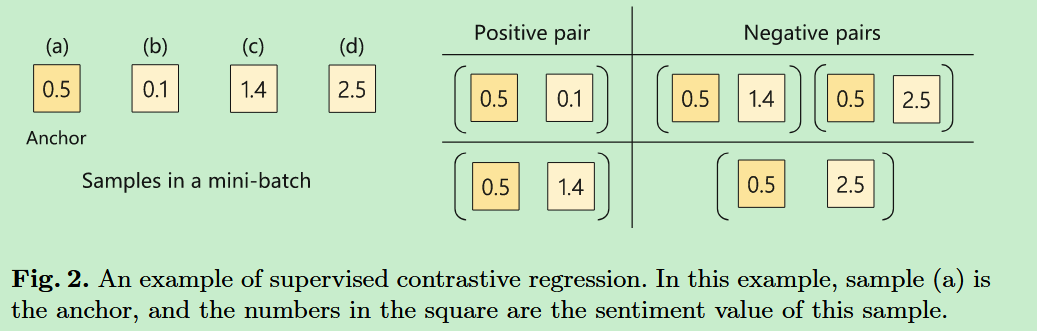
锚点-负样本之间的距离大于锚点-正样本之间的距离:
A
(
k
)
=
{
k
≠
i
,
∣
y
i
−
y
k
∣
≥
∣
y
i
−
y
j
∣
;
k
∈
{
1
,
2
,
…
,
2
N
}
}
\mathbb{A}(k)=\{k\neq i,|\boldsymbol{y}_i-\boldsymbol{y}_k|\geq|\boldsymbol{y}_i-\boldsymbol{y}_j|;k\in\{1,2,\ldots,2N\}\}
A(k)={k=i,∣yi−yk∣≥∣yi−yj∣;k∈{1,2,…,2N}}
基于有监督的对比回归分析,单模态表征
R
^
t
\hat{R}_{t}
R^t 和
R
^
a
\hat{R}_{a}
R^a 之间的对比学习操作可计算为:
L
t
a
S
u
p
C
R
=
−
1
2
N
∑
i
=
1
2
N
1
2
N
−
1
∑
j
=
1
,
j
≠
i
2
N
exp
(
R
^
m
,
i
⋅
R
^
m
,
j
/
τ
)
∑
k
∈
A
(
k
)
exp
(
R
^
m
,
i
⋅
R
^
m
,
k
/
τ
)
,
\mathcal{L}_{ta}^{SupCR}=-\frac1{2N}\sum_{i=1}^{2N}\frac1{2N-1}\sum_{j=1,j\neq i}^{2N}\frac{\exp\left(\hat{R}_{m,i}\cdot\hat{R}_{m,j}/\tau\right)}{\sum_{k\in\mathbb{A}(k)}\exp\left(\hat{R}_{m,i}\cdot\hat{R}_{m,k}/\tau\right)},
LtaSupCR=−2N1i=1∑2N2N−11j=1,j=i∑2N∑k∈A(k)exp(R^m,i⋅R^m,k/τ)exp(R^m,i⋅R^m,j/τ),
由于不同模态数据存在异质性,对比损失可能无法工作,因此需要为不同模态建立一个共同的子空间。通过构造一个相似性损失函数来实现:
L
t
a
s
i
m
=
∥
R
^
t
−
R
^
a
∥
2
2
.
\mathcal{L}_{ta}^{sim}=\left\|\hat{R}_t-\hat{R}_a\right\|_2^2.
Ltasim=
R^t−R^a
22.
最后,将相似性损失和对比损失结合起来实现双模态的对齐。
L
t
a
=
L
t
a
S
u
p
C
R
+
α
L
t
a
s
i
m
.
\mathcal{L}_{ta}=\mathcal{L}_{ta}^{SupCR}+\alpha\mathcal{L}_{ta}^{sim}.
Lta=LtaSupCR+αLtasim.
| 符号 | 含义 |
|---|---|
| m m m | 文本模态和音频模态 |
| N N N | batch size |
| i , j , k i,j,k i,j,k | 锚点、正样本和负样本 |
| A ( k ) \mathbb{A}(k) A(k) | 负样本指数集 |
| ∣ ⋅ ∣ 2 2 |\cdot|_2^2 ∣⋅∣22 | L2 正则化 |
3.双模态表征融合
双模态融合过程由三个子层组成:自注意力(Self-Attention)、交叉注意力(CrossAttention)和前馈网络(Feed-Forward)。(每个子层都包含一个残差连接,每层都进行正则化)
首先,将编码文本通过自注意力层:
H
t
=
Add
&
Norm
(
Self-Attention
(
E
t
)
)
=
Add
&
Norm
(
softmax
(
E
t
W
Q
W
K
⊤
E
t
⊤
d
t
)
E
t
W
V
)
)
\begin{aligned} \mathbf{H}_t& =\operatorname{Add}\&\operatorname{Norm}\left(\operatorname{Self-Attention}(\mathbf{E}_t)\right) \\ &=\operatorname{Add}\&\operatorname{Norm}\left(\operatorname{softmax}\left(\frac{\operatorname{E}_t\mathbf{W}_Q\mathbf{W}_K^\top\mathbf{E}_t^\top}{\sqrt{d_t}}\right)\mathbf{E}_t\mathbf{W}_V)\right) \end{aligned}
Ht=Add&Norm(Self-Attention(Et))=Add&Norm(softmax(dtEtWQWK⊤Et⊤)EtWV))
其次,采用交叉注意力将文本与其他模态进行融合:
F
m
t
=
Add
&
Norm
(
Cross-Attention
m
→
t
(
H
t
,
E
m
)
)
,
=
A
d
d
&
N
o
r
m
(
s
o
f
t
m
a
x
(
H
t
W
Q
t
W
K
m
⊤
E
m
⊤
d
t
)
E
m
W
V
m
)
,
\begin{aligned} \mathbf{F}_{mt}& =\text{Add}\&\text{Norm}\left(\text{ Cross-Attention}_{m\to t}(\mathbf{H}_t,\mathbf{E}_m)\right), \\ &=\mathrm{Add}\And\mathrm{Norm}\left(\mathrm{~softmax}\left(\frac{\mathrm{H}_t\mathrm{W}_{Q_t}\mathrm{W}_{K_m}^\top\mathrm{E}_m^\top}{\sqrt{d_t}}\right)\mathrm{E}_m\mathrm{W}_{V_m}\right), \end{aligned}
Fmt=Add&Norm( Cross-Attentionm→t(Ht,Em)),=Add&Norm( softmax(dtHtWQtWKm⊤Em⊤)EmWVm),
然后,通过一个前馈网络层:
Y
m
t
=
Add
&
Norm
(
ReLU
(
F
m
t
W
1
+
b
1
)
W
2
+
b
2
)
,
\mathbf{Y}_{mt}=\operatorname{Add}\&\operatorname{Norm}\left(\operatorname{ReLU}(\mathbf{F}_{mt}\mathbf{W}_1+b_1)\mathbf{W}_2+b_2\right),
Ymt=Add&Norm(ReLU(FmtW1+b1)W2+b2),
获得融合特征
Y
m
t
Y_{mt}
Ymt后,同样将 [cls] 令牌作为双模态表征
R
m
t
R_{mt}
Rmt,然后将它们传递到一个全连接层:
R
^
m
t
=
F
C
(
R
m
t
;
θ
m
t
F
C
)
\hat{R}_{\boldsymbol{mt}}=\mathrm{FC}(R_{\boldsymbol{mt}};\theta_{\boldsymbol{mt}}^{FC})
R^mt=FC(Rmt;θmtFC)
最后,同样应用监督对比损失:
L
f
u
s
i
o
n
=
−
1
2
N
∑
i
=
1
2
N
1
2
N
−
1
∑
j
=
1
,
j
≠
i
2
N
exp
(
R
^
m
t
,
i
⋅
R
^
m
t
,
j
/
τ
)
∑
k
∈
A
(
k
)
exp
(
R
^
m
t
,
i
⋅
R
^
m
t
,
k
/
τ
)
\mathcal{L}_{fusion}=-\frac1{2N}\sum_{i=1}^{2N}\frac1{2N-1}\sum_{j=1,j\neq i}^{2N}\frac{\exp\left(\hat{R}_{mt,i}\cdot\hat{R}_{mt,j}/\tau\right)}{\sum_{k\in\mathbb{A}(k)}\exp\left(\hat{R}_{mt,i}\cdot\hat{R}_{mt,k}/\tau\right)}
Lfusion=−2N1i=1∑2N2N−11j=1,j=i∑2N∑k∈A(k)exp(R^mt,i⋅R^mt,k/τ)exp(R^mt,i⋅R^mt,j/τ)
4.情感预测
最后通过一个MLP进行情感分析:
y
^
=
M
L
P
(
1
2
(
R
a
t
⊕
R
v
t
)
;
θ
M
L
P
)
,
\boldsymbol{\hat{y}}=\mathrm{MLP}\left(\frac12(R_{at}\oplus R_{vt});\theta^{MLP}\right),
y^=MLP(21(Rat⊕Rvt);θMLP),
预测损失:
L
task
=
1
N
∑
i
=
1
N
∣
y
i
−
y
^
i
∣
,
\mathcal{L}_\text{task }=\frac1N\sum_{i=1}^N\lvert y_i-\hat{y}_i\rvert,
Ltask =N1i=1∑N∣yi−y^i∣,
总损失:
L
=
L
t
a
s
k
+
ω
1
(
L
t
a
+
L
t
v
)
+
ω
2
L
f
u
s
i
o
n
,
\mathcal{L}=\mathcal{L}_{task}+\omega_1(\mathcal{L}_{ta}+\mathcal{L}_{tv})+\omega_2\mathcal{L}_{fusion},
L=Ltask+ω1(Lta+Ltv)+ω2Lfusion,
实验分析
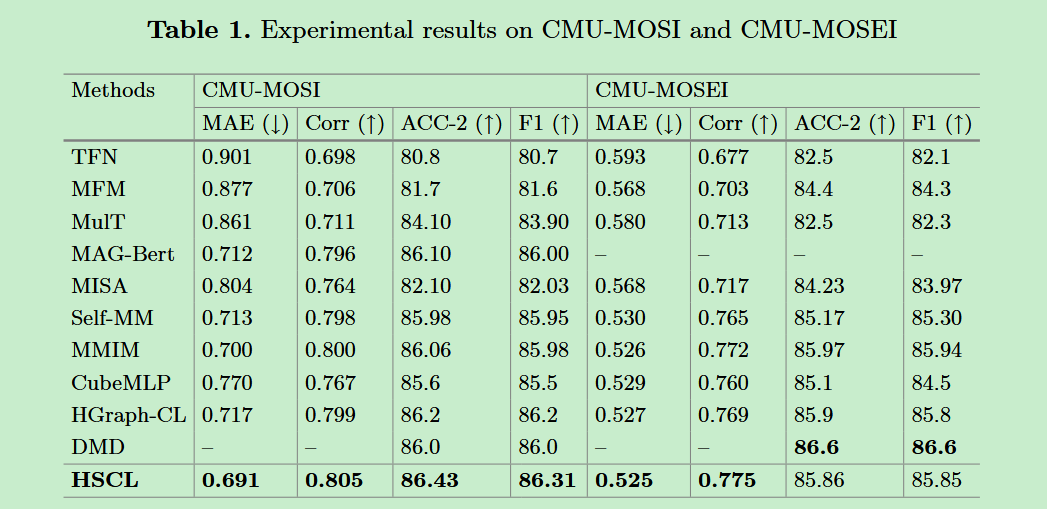
- 对比实验。HSCL 在 CMU-MOSI 与 CMU-MOSEI 数据集上进行了实验,结果表明 HSCL 在多数指标上优于基线模型。
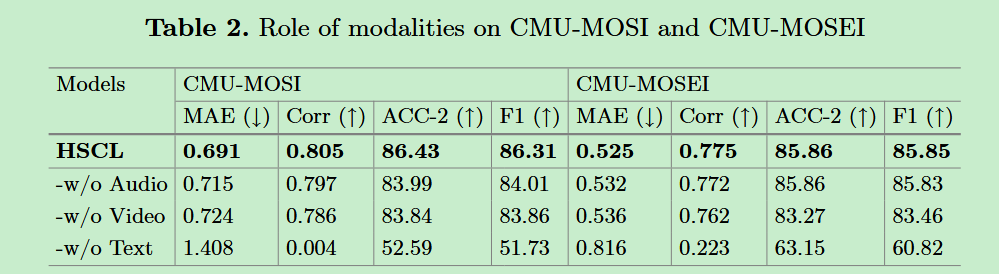
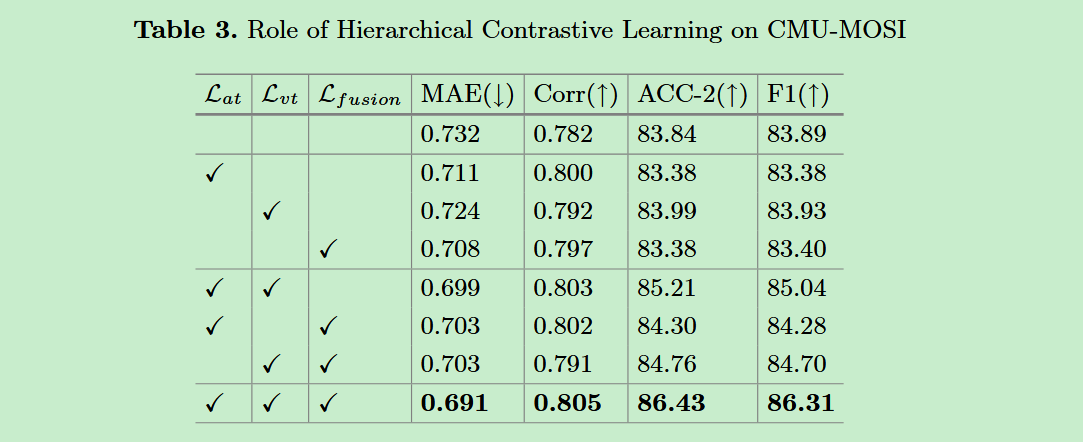
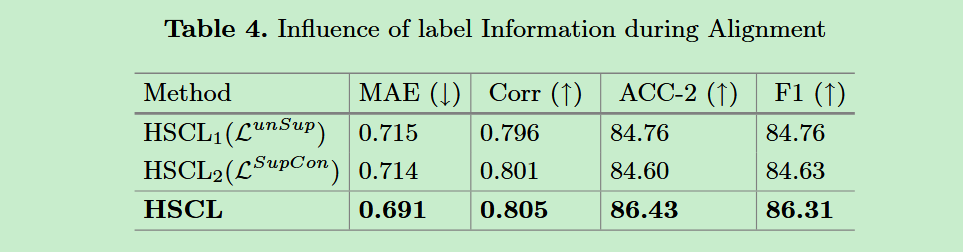
- 消融实验。进行了一系列的消融实验,探究不同模态的影响、层次对比学习的影响、标签信息在对齐过程中的影响。
😃😃😃


















 2082
2082

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









