




一、引入
希尔排序是一种分组插入排序的算法。
二、排序思路
- 首先取一个整数d1 = n/2,将元素分为d1个组,每组相邻量取元素距离为d1,在各组内直接进行插入排序;
- 取第二个整数d2 = d1/2, 重复上述分组排序过程,直到d1 = 1,即所有元素在同意最内进行直接插入排序。
- 希尔排序每趟并不使某些元素有序,而是使整体数据越来越接近有序;最后一趟排序使得所有数据有序。
如下图所示:n = 9 ; d1 = n // 2 = 4 ; 第一次将其分为四组;每组进行一次插入排序,排序完成后返回。
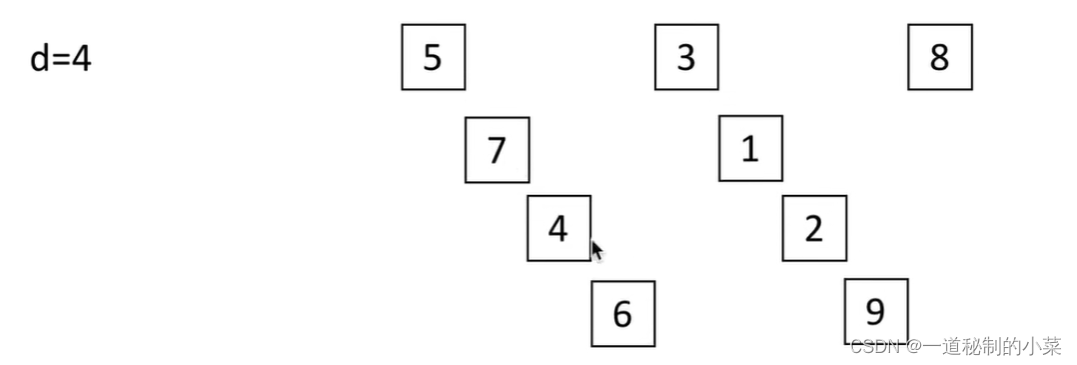
第二次将其分为 d1 = d // 2 = 2组后再重新进行插入排序:
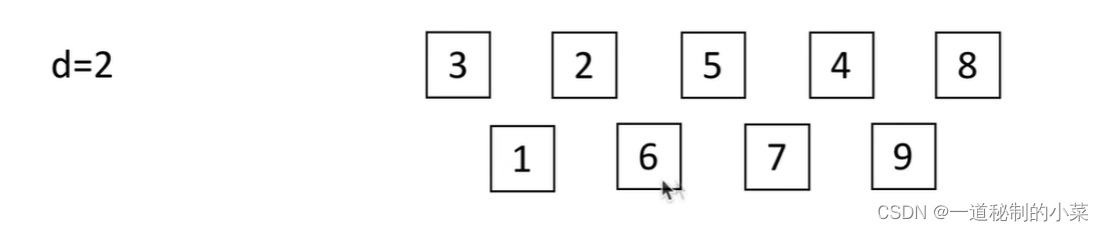
直到最后d = 1时,再对整体进行一次插入排序

三、代码思路
1. 按照间隔为gap的插入
相当于每次间隔gap进行一次插入排序,对比之前写的插入排序,相当于将其中的1变为gap。
示例代码:
def insert_sort_gap(li, gap):
for i in range(gap, len(li)): # i 表示摸到牌的下表; 总共n张牌,起始手里有一张牌
tmp = li[i] # 将摸到的牌存起来
j = i - gap # j指的是手里牌的下标,初始手里有一张牌
while j >= 0 and li[j] > tmp: # 将手里的牌和摸到的牌作比较;摸到的牌小于手里的牌and
li[j + gap] = li[j] # 往右挪位置
j -= gap # 缩小j后继续比较
li[j + gap] = tmp # j往前移后继续比较;如果此时摸到的牌大于li[j],则将摸到的牌放到j+1的位置
print(li)
接下来我们再写希尔排序的代码:
def shell_sort(li):
d = len(li) // 2
while d >= 1 :
insert_sort_gap(li, d)
d //= 2
因此总的演示代码如下所示:
def insert_sort_gap(li, gap):
for i in range(gap, len(li)): # i 表示摸到牌的下表; 总共n张牌,起始手里有一张牌
tmp = li[i] # 将摸到的牌存起来
j = i - gap # j指的是手里牌的下标,初始手里有一张牌
while j >= 0 and li[j] > tmp: # 将手里的牌和摸到的牌作比较;摸到的牌小于手里的牌and
li[j + gap] = li[j] # 往右挪位置
j -= gap # 缩小j后继续比较
li[j + gap] = tmp # j往前移后继续比较;如果此时摸到的牌大于li[j],则将摸到的牌放到j+1的位置
def shell_sort(li):
d = len(li) // 2
while d >= 1 :
insert_sort_gap(li, d)
d //= 2
li = [1,4,7,2,5,8,3,6,9]
print(li)
shell_sort(li)
print(li)
输出结果如下:
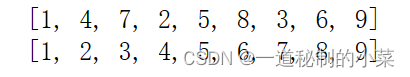
四、时间复杂度
希尔排序的时间复杂度比较复杂,并且和选取的gap序列有关。


如上图所示,选取不同的gap序列时希尔排序具有不同的时间复杂度,且存在一些复杂的gap序列使得无法计算其复杂度,但总的来说,希尔排序的时间复杂度比基础排序快,比进阶排序慢。


















 2989
2989

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











