







 本文介绍了Adaboost算法的基本原理,它与GBDT的关系,以及与Bagging的区别。通过实例展示了Adaboost在决策树上的应用,并对比了XGBoost在 iris 数据集上的分类效果。此外,还演示了如何使用XGBoost进行参数调优,以优化模型性能。
本文介绍了Adaboost算法的基本原理,它与GBDT的关系,以及与Bagging的区别。通过实例展示了Adaboost在决策树上的应用,并对比了XGBoost在 iris 数据集上的分类效果。此外,还演示了如何使用XGBoost进行参数调优,以优化模型性能。
Boosting
1、Adaboost的基本思路
Adaboost是一种迭代算法,其核心思想是针对同一个训练集训练不同的分类器(弱分类器),然后把这些弱分类器集合起来,构成一个更强的最终分类器(强分类器)
2、Adaboost与GBDT的联系与区别
相同点都对Boosting原始求解困难的加法模型改为分步优化
AdaBoost:调整错分的分类器权重进行学习,形成“基分类器”加性模型
GradientBoost:函数估计,得到最小化损失函数。
3、Boosting与Bagging的区别,以及如何提升模型的精度
boosting是降低偏差
通过提高那些在前一轮被弱分类器分错样例的权值,减小前一轮分对样例的权值,来使得分类器对误分的数据有较好的效果。
通过加法模型将弱分类器进行线性组合,比如AdaBoost通过加权多数表决的方式,即增大错误率小的分类器的权值,同时减小错误率较大的分类器的权值。
而提升树通过拟合残差的方式逐步减小残差,将每一步生成的模型叠加得到最终模型。
bagging是降低方差
从原始样本集中抽取训练集。每轮从原始样本集中使用Bootstraping的方法抽取n个训练样本(在训练集中,有些样本可能被多次抽取到,而有些样本可能一次都没有被抽中)。共进行k轮抽取,得到k个训练集。(k个训练集之间是相互独立的)
每次使用一个训练集得到一个模型,k个训练集共得到k个模型。
这里并没有具体的分类算法或回归方法,我们可以根据具体问题采用不同的分类或回归方法,如决策树、感知器等)
对分类问题:将上步得到的k个模型采用投票的方式得到分类结果
对回归问题,计算上述模型的均值作为最后的结果。(所有模型的重要性相同)
4、使用基本分类模型和Boosting提升的模型,并画出他们的决策边界
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.style.use("ggplot")
import seaborn as sns
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
#pandas设置最大显示行和列
pd.set_option('display.max_columns',50)
pd.set_option('display.max_rows',300)
#调整显示宽度,以便整行显示
pd.set_option('display.width',1000)
if __name__ == '__main__':
# 加载训练数据:
wine = pd.read_csv("https://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data",header=None)
wine.columns = ['Class label', 'Alcohol', 'Malic acid', 'Ash', 'Alcalinity of ash', 'Magnesium', 'Total phenols', 'Flavanoids', 'Nonflavanoid phenols','Proanthocyanins', 'Color intensity', 'Hue', 'OD280/OD315 of diluted wines', 'Proline']
#查看红酒类别
print("Class labels", np.unique(wine["Class label"]))
# 查看前五行数据
print(wine.head())
# 仅仅考虑2,3类葡萄酒,去除1类
wine = wine[wine['Class label'] != 1]
y = wine['Class label'].values
X = wine[['Alcohol', 'OD280/OD315 of diluted wines']].values #选取两列数据作为X
# 将分类标签变成二进制编码
le = LabelEncoder()
y = le.fit_transform(y)
# 按8:2分割训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1,stratify=y)
# stratify参数代表了按照y的类别等比例抽样
# 使用单一决策树建模
from sklearn.tree import DecisionTreeClassifier
tree = DecisionTreeClassifier(criterion='entropy',random_state=1,max_depth=1)
from sklearn.metrics import accuracy_score
tree = tree.fit(X_train,y_train)
y_train_pred = tree.predict(X_train)
y_test_pred = tree.predict(X_test)
tree_train = accuracy_score(y_train,y_train_pred)
tree_test = accuracy_score(y_test,y_test_pred)
print('Decision tree train/test accuracies %.3f/%.3f' % (tree_train,tree_test))
# Decision tree train/test accuracies 0.916/0.875
'''
AdaBoostClassifier相关参数:
base_estimator:基本分类器,默认为DecisionTreeClassifier(max_depth=1)
n_estimators:终止迭代的次数
learning_rate:学习率
algorithm:训练的相关算法,{'SAMME','SAMME.R'},默认='SAMME.R'
random_state:随机种子
'''
from sklearn.ensemble import AdaBoostClassifier
ada = AdaBoostClassifier(base_estimator=tree,n_estimators=500,learning_rate=0.1,random_state=1)
ada = ada.fit(X_train,y_train)
y_train_pred = ada.predict(X_train)
y_test_pred = ada.predict(X_test)
ada_train = accuracy_score(y_train,y_train_pred)
ada_test = accuracy_score(y_test,y_test_pred)
print('Adaboost train/test accuracies %.3f/%.3f' % (ada_train,ada_test))
# Adaboost train/test accuracies 1.000/0.917
# 画出单层决策树与Adaboost的决策边界:
x_min = X_train[:, 0].min() - 1
x_max = X_train[:, 0].max() + 1
y_min = X_train[:, 1].min() - 1
y_max = X_train[:, 1].max() + 1
#生成矩阵坐标,从坐标向量中返回坐标矩阵
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.1),np.arange(y_min, y_max, 0.1))
f, axarr = plt.subplots(nrows=1, ncols=2,sharex='col',sharey='row',figsize=(12, 6))
# nrows,ncols:
for idx, clf, tt in zip([0, 1],[tree, ada],['Decision tree', 'Adaboost']):
# zip :将对象中对应的元素打包成一个个元组
clf.fit(X_train, y_train)
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
axarr[idx].contourf(xx, yy, Z, alpha=0.3)
axarr[idx].scatter(X_train[y_train==0, 0],X_train[y_train==0, 1],c='blue', marker='^')
axarr[idx].scatter(X_train[y_train==1, 0],X_train[y_train==1, 1],c='red', marker='o')
axarr[idx].set_title(tt)
axarr[0].set_ylabel('Alcohol', fontsize=12)
plt.tight_layout()
plt.text(0, -0.2,s='OD280/OD315 of diluted wines',ha='center',va='center',fontsize=12,transform=axarr[1].transAxes)
plt.show()
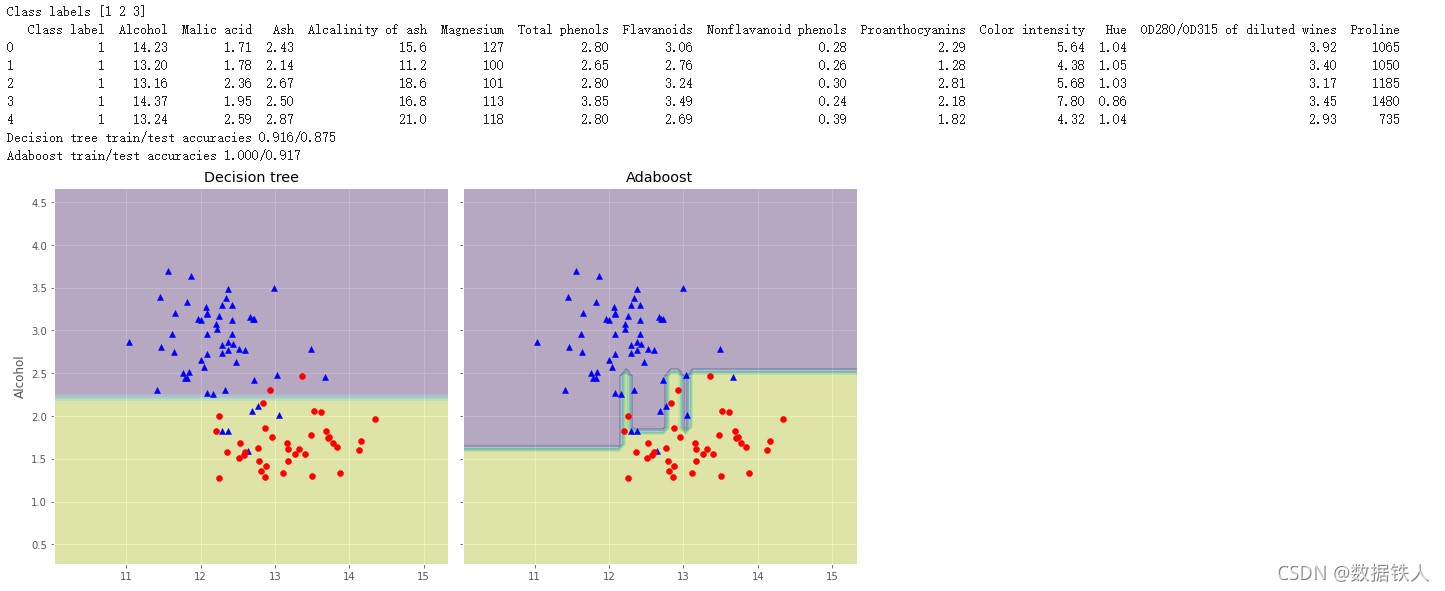
5、尝试使用XGboost模型完成一个具体的分类任务,并进行调参
XGboost模型分类
from sklearn.datasets import load_iris
import xgboost as xgb
from xgboost import plot_importance
from matplotlib import pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score # 准确率
# 加载样本数据集
iris = load_iris()
X, y = iris.data, iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1234565) # 数据集分割
# 算法参数
params = {
'booster': 'gbtree',
'objective': 'multi:softmax', # 回归任务设置为:'objective': 'reg:gamma',
'num_class': 3, # 回归任务没有这个参数
'gamma': 0.1,
'max_depth': 6,
'lambda': 2,
'subsample': 0.7,
'colsample_bytree': 0.7,
'min_child_weight': 3,
'silent': 1,
'eta': 0.1,
'seed': 2021,
'nthread': 4,
}
dtrain = xgb.DMatrix(X_train, y_train) # 生成数据集格式
num_rounds = 500
model = xgb.train(params, dtrain, num_rounds) # xgboost模型训练
# 对测试集进行预测
dtest = xgb.DMatrix(X_test)
y_pred = model.predict(dtest)
# 计算准确率
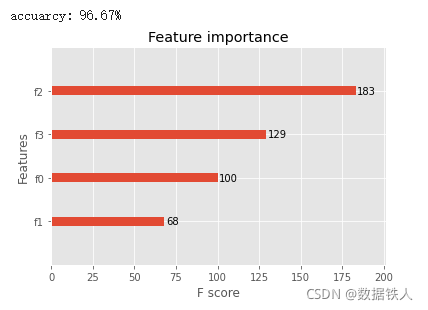
accuracy = accuracy_score(y_test, y_pred)
print("accuarcy: %.2f%%" % (accuracy * 100.0))
# 显示重要特征
plot_importance(model)
plt.show()
XGBoost调参(结合sklearn网格搜索)
import xgboost as xgb
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import roc_auc_score
iris = load_iris()
X,y = iris.data,iris.target
col = iris.target_names
train_x, valid_x, train_y, valid_y = train_test_split(X, y, test_size=0.3, random_state=1) # 分训练集和验证集
parameters = {
'max_depth': [5, 10, 15, 20, 25],
'learning_rate': [0.01, 0.02, 0.05, 0.1, 0.15],
'n_estimators': [500, 1000, 2000, 3000, 5000],
'min_child_weight': [0, 2, 5, 10, 20],
'max_delta_step': [0, 0.2, 0.6, 1, 2],
'subsample': [0.6, 0.7, 0.8, 0.85, 0.95],
'colsample_bytree': [0.5, 0.6, 0.7, 0.8, 0.9],
'reg_alpha': [0, 0.25, 0.5, 0.75, 1],
'reg_lambda': [0.2, 0.4, 0.6, 0.8, 1],
'scale_pos_weight': [0.2, 0.4, 0.6, 0.8, 1]
}
xlf = xgb.XGBClassifier(max_depth=10,
learning_rate=0.01,
n_estimators=2000,
silent=True,
objective='multi:softmax',
num_class=3 ,
nthread=-1,
gamma=0,
min_child_weight=1,
max_delta_step=0,
subsample=0.85,
colsample_bytree=0.7,
colsample_bylevel=1,
reg_alpha=0,
reg_lambda=1,
scale_pos_weight=1,
seed=0,
missing=None)
gs = GridSearchCV(xlf, param_grid=parameters, scoring='accuracy', cv=3)
gs.fit(train_x, train_y)
print("Best score: %0.3f" % gs.best_score_)
print("Best parameters set: %s" % gs.best_params_ )
https://github.com/datawhalechina/ensemble-learning
http://blog.17baishi.com/7228/
http://www.qishunwang.net/news_show_280248.aspx

















 520
520

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









