



 本文介绍了手写数字识别的研究背景及重要性,对比了几种传统机器学习算法在手写数字识别任务上的表现,并探讨了全连接神经网络和卷积神经网络的应用。
本文介绍了手写数字识别的研究背景及重要性,对比了几种传统机器学习算法在手写数字识别任务上的表现,并探讨了全连接神经网络和卷积神经网络的应用。
1.引言
手写数字是人手书写的各种字符中最简单常见的一种。在过去的30多年间,对手写数字识别的研究一直都是模式识别领域的研究热点。数字是世界各国通用的符号,类别也较少,有助于做深入分析及验证一些新的理论,因此它也是各种识别算法优劣的重要检测手段。手写数字识别的基本过程,一般可分为手写数字样本的收集、输入和预处理、特征提取、分类和识别等几个步骤。多年来,为了提高识别率和运行速度、降低误识率,众多的学者就纷纷识别的步骤提出各种新技术和新想法。大家讨论的焦点主要集中在特征提取、分类以及识别等方面。
手写数字识别(Handwritten Numeral Recognition)是光学字符识别技术(Optical Character Recogmition,简称OCR)的一个分支,它研究的对象是:如何利用电子计算机自动辨认人手写在纸张上的阿拉伯数字。随着社会信息化的发展,手写数字的识别研究有着重大的实用价值,如在邮政编码、税务报表、统计报表、财务报表、银行票据、海关、人口普查等需要处理大量字符信息录入的场合。
手写体数字识别方法大体可分为两类:基于统计的识别方法和基于结构的识别方法。第一类方法包括模板匹配法、矩法、笔道的点密度测试、字符轨迹法及数字变换法等。第二类则是尽量抽取数字的骨架或轮廓特征,如环路、端点、交叉点、弧状线、环及凹凸性等,两类方法具有一定的互补性。手写数字识别是当前图像处理和模式识别领域的一个重要研究分支,由于手写数字的随意性大,其识别准确率易受字体大小、笔画粗细和倾斜角度等因素的影响,因此进行手写数字识别方法和系统的设计具有重要的理论价值和实际意义。
手写体数字用多层BP网络来识别可以采用两种输入网络的形式:一种是点阵(0,1点阵)直接输入网络,利用网络来抽取特征并进行分类,这也叫点阵输入网络;另一种是通过一些算法,抽取字符特征,然后将一组特征值输入网络,利用神经网络对特征分类,达到识别字符的目的,这也叫作特征输入网络,它仅起分类作用。对于识别手写体数字,特征输入网络要比点阵输入网络效果好。
特征输入网络多数是直接输入提取的所有字符特征,一般来说,特征输入的越多识别才能越准确。但是太多的输入会使网络变的很大,难于收敛或者收敛到局部极小点。可以先对待识别数字进行粗特征分类,其作用是根据一些简单的特征对数字分类,选择具有这些简单特征的数字准备进行进一步识别;然后再提取其他特征,输入粗分类中选中的数字判别网络进行判别。
常用的特征提取方法,有逐像素特征提取法、骨架特征提取法和垂直方向数据统计特征提取法L6j等。逐像素特征提取法n3是一种最简单的特征提取方法,它是对图像进行逐行逐列地扫描,其特点是算法简单,运算速度快,可以使网络很快地收敛,训练效果好,但适应性不强;骨架特征提取法是一种利用细化的方法来提取骨架的方法。该方法对于线条粗细不同的数字有一定的适应性,但是图像一旦出现偏移就难以识别;垂直方向数据统计特征提取法就是自左向右对图像进行逐列地扫描,统计每列黑像素的个数,然后自上而下逐行扫描,统计每行的黑像素的个数,将统计结果作为字符的特征向量。这种方法的效果不是很理想,适应性不强。分类与识别的方式主要有贝叶斯分类器嘲、人工神经网络、多分类器组合或多级分类器、基于图论原理的分类、支持向量机等。由于人工神经网络具有自学习、容错性、分类能力强和并行处理等特点,因此它也是最常用的分类识别方式。在训练神经网络时最常用的是BP算法。由于手写体存在本身的不规则性及不同人书写风格的差异,手写数字的特征向量常出现交叉和混淆。可是BP网络采用剧变的判别边界来分割特征空间,对于样本特征空间存在交叉的情况,它将无法正确的估计出处于特征空间交叉处样本的隶属度值。不过,由于量子神经网络,具有超高速、超并行、指数容量级的特点,对具有不确定性、两类模式之间存在交叉数据的模式识别问题有极好的分类效果,因此,量子神经网络就可很好的克服常规BP神经网络的局限性。本文针对上述特征提取方法和BP神经网路的缺陷,提出了一种将新型特征提取方法(13维特征提取法)与量子神经网络相结合的手写数字识别方法。实验结果表明,与其他方法相比,该方法的识别正确率有了明显的提高。
2.传统机器学习
机器学习可以分为传统机器学习和深度学习。我先从传统机器学习的几个比较经典的方法出发,研究手写数据集的准确率。
2.1 K-近邻算法(KNN)介绍
K-近邻算法是一种惰性学习模型(lazy learning),也称为基于实例学习模型,这与**勤奋学习模型(eager learning)**不一样。例如线性回归模型就是属于勤奋学习模型。
勤奋学习模型在训练模型的时候会很耗资源,它会根据训练数据生成一个模型,在预测阶段直接带入数据就可以生成预测的数据,所以在预测阶段几乎不消耗资源
惰性学习模型在训练模型的时候不会估计由模型生成的参数,他可以即刻预测,但是会消耗较多资源,例如KNN模型,要预测一个实例,需要求出与所有实例之间的距离。
K-近邻算法是一种非参数模型,参数模型使用固定的数量的参数或者系数去定义模型,非参数模型并不意味着不需要参数,而是参数的数量不确定,它可能会随着训练实例数量的增加而增加,当数据量大的时候,看不出解释变量和响应变量之间的关系的时候,使用非参数模型就会有很大的优势,而如果数据量少,可以观察到两者之间的关系的,使用相应的模型就会有很大的优势。
原理:存在一个样本集,也就是训练集,每一个数据都有标签,也就是我们知道样本中每个数据与所属分类的关系,输入没有标签的新数据后,新数据的每个特征会和样本集中的所有数据对应的特征进行比较,算出新数据与样本集其他数据的欧几里得距离,这里需要给出K值,这里会选择与新数据距离最近的K个数据,其中出现次数最多的分类就是新数据的分类,一般k不会大于20。
K近邻算法(knn)实现步骤:
- 计算当前点与已知类别数据集中的点的距离
- 距离递增排序,选出距离最小的k个点
- 确定前k个点类别出现的频率
- 将频率最高的类别作为当前点的预测分类
2.2 支持向量机(SVM)介绍
支持向量机(Support Vector Machine, SVM)是一类按监督学习(supervised learning)方式对数据进行二元分类(binary classification)的广义线性分类器(generalized linear classifier),其决策边界是对学习样本求解的最大边距超平面(maximum-margin hyperplane)。
SVM使用铰链损失函数(hinge loss)计算经验风险(empirical risk)并在求解系统中加入了正则化项以优化结构风险(structural risk),是一个具有稀疏性和稳健性的分类器。SVM可以通过核方法(kernel method)进行非线性分类,是常见的核学习(kernel learning)方法之一。
SVM在解决小样本、非线性及高维模式识别中表现出许多特有的优势,是迄今为止具有最小化分类错误率和最大化泛化能力的一种强有力的分类工具,已经在模式识别、回归分析等机器学习领域得到广泛应用,成为机器学习领域研究的热点。
SVM是一种最小化结构风险的机器学习算法,克服了经验风险最小化机器学习算法所带来的分类函数推广能力差,即分类器泛化能力差的缺憾。SVM 建立在统计学习理论的VC维和结构风险最小化原理基础上,能根据有限的样本信息在模型的复杂性(即对特定训练样本的学习精度)和学习能力(即无错误地识别任意样本的能力)之间寻求最佳折衷,获得最好的推广能力也即泛化能力。
对于线性可分的两类样本,SVM算法可以学习得到一个将这两类样本分开的最优分类超平面f(x)=<w·x>+b=0。该最优分类超平面只需要少数几个样本就可以确定,这几个样本构成支持向量。该最优分类超平面是具有最大几何间隔的超平面,即样本集到该最优分类超平面的欧氏距离最大,就是样本集中距离超平面最近的样本到超平面的欧氏距离达到最大,因此这个最优分类超平面一定在两类中间,使得两类样本集到超平面的距离相等。此时,样本被误分的次数≤(2R/γ)2,γ是几何间隔,R是样本的最长向量长度值,R代表了样本的分布广度。因此,最大化几何间隔作为SVM 学习的目标,就是最小化样本错分率。
对于线性不可分的两类样本,SVM通过核函数将低维输入空间线性不可分的样本映射到高维特征空间成为线性可分的样本,在高维特征空间求解线性可分的两类样本的最优分类超平面。
常用的核函数有:线性核函数K(x,x)=x·x,多项式核函数函数K(x,x)=(x·x+1)d,径向基核函数,S型核函数等。其中径向基核函数几乎可以解决所有的分类问题。但是在具有高维特征的问题中,比如基因选择、文本分类等,线性核函数经常被使用。
对于带有噪音的近似可分两类样本,SVM通过引入松弛变量得到一阶或二阶的软间隔分类器,并通过惩罚因子调控噪音点对最优分类超平面的影响,惩罚因子越大噪音点的影响越强。
2.3 朴素贝叶斯法介绍
朴素贝叶斯法是基于贝叶斯定理与特征条件独立假设的分类方法。简单来说,朴素贝叶斯分类器假设样本每个特征与其他特征都不相关。举个例子,如果一种水果具有红,圆,直径大概4英寸等特征,该水果可以被判定为是苹果。尽管这些特征相互依赖或者有些特征由其他特征决定,然而朴素贝叶斯分类器认为这些属性在判定该水果是否为苹果的概率分布上独立的。尽管是带着这些朴素思想和过于简单化的假设,但朴素贝叶斯分类器在很多复杂的现实情形中仍能够取得相当好的效果。朴素贝叶斯分类器的一个优势在于只需要根据少量的训练数据估计出必要的参数(离散型变量是先验概率和类条件概率,连续型变量是变量的均值和方差)。
2.3.1 贝叶斯分类模型
P
(
Y
∣
X
)
=
P
(
Y
)
P
(
X
∣
Y
)
P
(
X
)
P(Y|X)=\frac {P(Y)P(X|Y)}{P(X)}
P(Y∣X)=P(X)P(Y)P(X∣Y)
其中,X表示属性集,Y表示类变量,P(Y)为先验概率,P(X|Y)为类条件概率,P(X)为证据,P(Y|X)为后验概率。贝叶斯分类模型就是用先验概率P(Y)、类条件概率P(X|Y)和证据P(X)来表示后验概率。在比较Y的后验概率时,分母中的证据P(X)总是常数,因此可以忽略不计。先验概率P(Y)可以通过计算训练集中属于每个类的训练记录所占的比例很容易估计。对类条件概率P(X|Y)的估计,不同的实现决定不同的贝叶斯分类方法,常见的有朴素贝叶斯分类法和贝叶斯信念网络。
2.3.2 朴素贝叶斯分类模型
朴素贝叶斯分类法在估计类条件概率P(X|Y)时假设属性之间条件独立,条件独立假设可以表示如下:
P
(
X
∣
Y
=
y
)
=
∏
i
=
1
d
P
(
X
i
∣
Y
=
y
)
P(X|Y = y) = \prod_{i=1}^d P(X_i|Y = y)
P(X∣Y=y)=i=1∏dP(Xi∣Y=y)
其中,d为每条记录的属性个数
朴素贝叶斯分类法模型如下:
P
(
Y
=
y
j
∣
X
)
=
P
(
Y
=
y
j
)
∏
i
=
1
d
P
(
X
i
∣
Y
=
y
j
)
P
(
X
)
P(Y = y_j|X) = \frac{P(Y = y_j)\prod_{i=1}^d P(X_i|Y = y_j)}{P(X)}
P(Y=yj∣X)=P(X)P(Y=yj)∏i=1dP(Xi∣Y=yj)
模型中,对于所有的Y,P(X)是固定的,所以上述模型等价于:
P
(
Y
=
y
j
∣
X
)
=
a
r
g
m
a
x
y
j
P
(
Y
=
y
j
)
∏
i
=
1
d
P
(
X
i
∣
Y
=
y
j
)
P(Y = y_j|X) = arg max_{y_j}P(Y = y_j)\prod_{i=1}^d P(X_i|Y = y_j)
P(Y=yj∣X)=argmaxyjP(Y=yj)i=1∏dP(Xi∣Y=yj)
当属性是离散型时,类的先验概率可以通过训练集的各类样本出现的次数来估计,例如:A类先验概率=A类样本的数量/样本总数。类条件概率$ P(X_i = x_i|Y_j = y_j)
可
以
根
据
类
可以根据类
可以根据类y_j
中
属
性
值
等
于
中属性值等于
中属性值等于x_i
的
训
练
实
例
的
比
例
来
估
计
。
∗
∗
当
属
性
是
连
续
型
时
∗
∗
,
有
两
种
方
法
来
估
计
属
性
的
类
条
件
概
率
。
第
一
种
方
法
是
把
每
一
个
连
续
的
属
性
离
散
化
,
然
后
用
相
应
的
离
散
区
间
替
换
连
续
属
性
值
,
但
这
种
方
法
不
好
控
制
离
散
区
间
划
分
的
粒
度
。
如
果
粒
度
太
细
,
就
会
因
为
每
一
个
区
间
中
训
练
记
录
太
少
而
不
能
对
的训练实例的比例来估计。 **当属性是连续型时**,有两种方法来估计属性的类条件概率。第一种方法是把每一个连续的属性离散化,然后用相应的离散区间替换连续属性值,但这种方法不好控制离散区间划分的粒度。如果粒度太细,就会因为每一个区间中训练记录太少而不能对
的训练实例的比例来估计。∗∗当属性是连续型时∗∗,有两种方法来估计属性的类条件概率。第一种方法是把每一个连续的属性离散化,然后用相应的离散区间替换连续属性值,但这种方法不好控制离散区间划分的粒度。如果粒度太细,就会因为每一个区间中训练记录太少而不能对P(X|Y)$做出可靠的估计,如果粒度太粗,那么有些区间就会含有来自不同类的记录,因此失去了正确的决策边界。第二种方法是,可以假设连续变量服从某种概率分布,然后使用训练数据估计分布的参数,高斯分布通常被用来表示连续属性的类条件概率分布。
高斯分布有两个参数,均值
u
u
u和方差
σ
2
{\sigma}^2
σ2,对于每个类
y
i
y_i
yi,属性
X
i
X_i
Xi的类条件概率等于:
P
(
X
i
=
x
i
∣
Y
=
y
j
)
=
1
2
π
σ
i
j
2
e
−
(
x
i
−
u
i
j
)
2
2
σ
i
j
2
P(X_i = x_i|Y = y_j)= \frac{1}{\sqrt{2\pi}{{\sigma}_{ij}}^2}e^{-\frac{{(x_i-{u}_{ij})}^2}{2{\sigma}_{ij}^2}}
P(Xi=xi∣Y=yj)=2πσij21e−2σij2(xi−uij)2
参数
u
i
j
{u}_{ij}
uij可以用类
y
j
y_j
yj的所有训练记录关于
X
i
X_i
Xi的样本值来估计,同理,
σ
i
j
2
{\sigma}_{ij}^2
σij2可以用这些训练记录的样本方差来估计
2.4 决策树介绍
决策树(Decision Tree)是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,评价项目风险,判断其可行性的决策分析方法,是直观运用概率分析的一种图解法。由于这种决策分支画成图形很像一棵树的枝干,故称决策树。
决策树是一种树形结构,其中每个内部节点表示一个属性上的测试,每个分支代表一个测试输出,每个叶节点代表一种类别。
机器学习中,决策树是一个预测模型;他代表的是对象属性与对象值之间的一种映射关系。树中每个节点表示某个对象,而每个分叉路径则代表的某个可能的属性值,而每个叶结点则对应从根节点到该叶节点所经历的路径所表示的对象的值。决策树仅有单一输出,若欲有复数输出,可以建立独立的决策树以处理不同输出。数据挖掘中决策树是一种经常要用到的技术,可以用于分析数据,同样也可以用来作预测。
决策树实际上是一个if-then规则的集合。例如,现在要做一个决策:周末是否要打球,我们可能要考虑下面几个因素。第一,天气因素,如果是晴天,我们就打球,如果是雨天我们就不打球。第二,球场是否满员,如果满员,我们就不打球,如果不满员我们就打球。第三,是否需要加班,如果加班则不打球,如果不需要加班则打球。这样我们就形成了一个决策树,如图 1 所示。
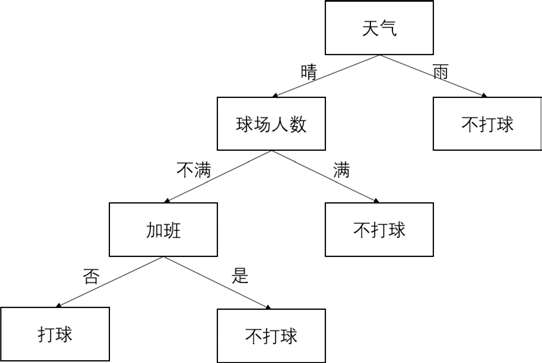
可以将这个决策过程抽象一下,每个决策点称为分支节点,如图 2 所示。
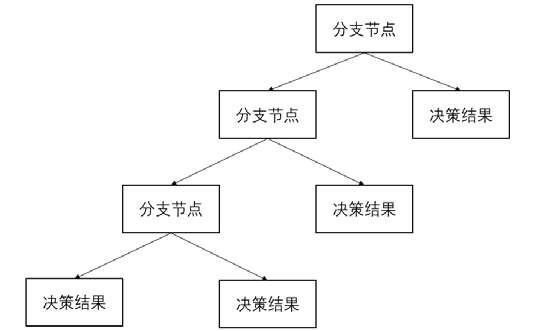
2.5 AdaBoost介绍
AdaBoost,是英文"Adaptive Boosting"(自适应增强)的缩写,是一种机器学习方法,由Yoav Freund和Robert Schapire提出。AdaBoost方法的自适应在于:前一个分类器分错的样本会被用来训练下一个分类器。AdaBoost方法对于噪声数据和异常数据很敏感。但在一些问题中,AdaBoost方法相对于大多数其它学习算法而言,不会很容易出现过拟合现象。AdaBoost方法中使用的分类器可能很弱(比如出现很大错误率),但只要它的分类效果比随机好一点(比如两类问题分类错误率略小于0.5),就能够改善最终得到的模型。而错误率高于随机分类器的弱分类器也是有用的,因为在最终得到的多个分类器的线性组合中,可以给它们赋予负系数,同样也能提升分类效果。
AdaBoost方法是一种迭代算法,在每一轮中加入一个新的弱分类器,直到达到某个预定的足够小的错误率。每一个训练样本都被赋予一个权重,表明它被某个分类器选入训练集的概率。如果某个样本点已经被准确地分类,那么在构造下一个训练集中,它被选中的概率就被降低;相反,如果某个样本点没有被准确地分类,那么它的权重就得到提高。通过这样的方式,AdaBoost方法能“聚焦于”那些较难分(更富信息)的样本上。在具体实现上,最初令每个样本的权重都相等,对于第k次迭代操作,我们就根据这些权重来选取样本点,进而训练分类器Ck。然后就根据这个分类器,来提高被它分错的的样本的权重,并降低被正确分类的样本权重。然后,权重更新过的样本集被用于训练下一个分类器Ck。整个训练过程如此迭代地进行下去。

-
预设条件
假设我们的训练集样本是: X = ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x m , y m ) X = {(x_1,y_1),(x_2,y_2),...,(x_m,y_m)} X=(x1,y1),(x2,y2),...,(xm,ym)
训练集的在第k个弱学习器的样本权重系数为: D ( k ) = ( w k 1 , w k 2 , . . . , w k m ) ; ∑ i = 1 m w k i = 1 ; w 1 i = 1 m ; i = 1 , 2 , . . , m D(k) = (w_{k1},w_{k2},...,w_{km});\sum_{i = 1}^{m}w_{ki} = 1;w_{1i} = \frac{1}{m};i = 1,2,..,m D(k)=(wk1,wk2,...,wkm);i=1∑mwki=1;w1i=m1;i=1,2,..,m -
分类误差率
分类问题的误差率很好理解和计算。由于多元分类是二元分类的推广,这里假设我们是二元分类问题,输出为{-1,1},则第k个弱分类器 G k ( x ) G_k(x) Gk(x)在训练集上的分类误差率为:
e k = P ( G k ( x i ) ≠ y i ) = ∑ i = 1 m w k i I ( G k ( x i ) ≠ y i ) e_k = P(G_k(x_i)\neq y_i) = \sum_{i = 1}^{m}w_{ki}I(G_k(x_i)\neq y_i) ek=P(Gk(xi)=yi)=i=1∑mwkiI(Gk(xi)=yi) -
样本权重
如何更新样本权重D。假设第k个弱分类器的样本集权重系数为 D ( k ) = ( w k 1 , w k 2 , . . . , w k m ) D(k) = (w_{k1},w_{k2},...,w_{km}) D(k)=(wk1,wk2,...,wkm) ,则对应的第k+1个弱分类器的样本权重系数为:
w k + 1 , i = w k i Z K e x p ( − α k y i G k ( x i ) ) w_{k+1,i} = \frac{w_{ki}}{Z_{K}}exp(-{\alpha}_ky_iG_k(x_i)) wk+1,i=ZKwkiexp(−αkyiGk(xi))
这里 Z k Z_k Zk是规范化因子:
Z k = ∑ i = 1 m w k i e x p ( − α k y i G k ( x i ) ) Z_k = \sum_{i = 1}^{m}w_{ki}exp(-{\alpha}_ky_iG_k(x_i)) Zk=i=1∑mwkiexp(−αkyiGk(xi))
从 w k + 1 , i w_{k+1,i} wk+1,i计算公式可以看出,如果第i个样本分类错误,则 y i G k ( x i ) < 0 y_iG_k(x_i) < 0 yiGk(xi)<0 ,导致样本的权重在第k+1个弱分类器中增大,如果分类正确,则权重在第k+1个弱分类器中减少.不改变所给的训练集数据,通过不断的改变训练样本的权重,使得训练集数据在弱分类器的学习中起不同的作用。 -
弱学习器的权重系数
接着我们看弱学习器权重系数,对于二元分类问题,第k个弱分类器 G k ( x ) G_k(x) Gk(x)的权重系数为:
α k = 1 2 l o g 1 − e k e k {\alpha}_k = \frac{1}{2}log{\frac{1-e_k}{e_k}} αk=21logek1−ek
(注意这个权重系数的定义,指数损失的由来)
为什么这样计算弱学习器权重系数?从上式可以看出,如果分类误差率 e k e_k ek越大,则对应的弱分类器权重系数 α k {\alpha}_k αk越小。也就是说,误差率小的弱分类器权重系数越大。
- 结合策略
Adaboost分类采用的是加权平均法,最终的强分类器为:
f ( x ) = s i g n ( ∑ k = 1 K α k G k ( x ) ) f(x) = sign(\sum_{k=1}^{K}{\alpha}_kG_k(x)) f(x)=sign(k=1∑KαkGk(x))
系数 α k {\alpha}_k αk表示了弱分类器 G k ( x ) G_k(x) Gk(x)的重要性,这里所有 α {\alpha} α之和并不为1, f ( x ) f(x) f(x)的符号决定实例 x x x的类, f ( x ) f(x) f(x)的绝对值表示分类的置信度。
2.6 python实现
# 1.导包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_digits
from sklearn.preprocessing import MinMaxScaler, StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.svm import SVC
from sklearn.naive_bayes import MultinomialNB
from sklearn.ensemble import AdaBoostClassifier
from sklearn.metrics import accuracy_score
# 2.加载数据并探索
# 加载数据
digits = load_digits()
data = digits.data
# 数据探索
print(data.shape)
# 查看第一幅图像
print(digits.images[0])
# 第一幅图像代表的数字含义
print(digits.target[0])
# 将第一幅图像显示出来
plt.imshow(digits.images[0])
plt.show()
(1797, 64)
[[ 0. 0. 5. 13. 9. 1. 0. 0.]
[ 0. 0. 13. 15. 10. 15. 5. 0.]
[ 0. 3. 15. 2. 0. 11. 8. 0.]
[ 0. 4. 12. 0. 0. 8. 8. 0.]
[ 0. 5. 8. 0. 0. 9. 8. 0.]
[ 0. 4. 11. 0. 1. 12. 7. 0.]
[ 0. 2. 14. 5. 10. 12. 0. 0.]
[ 0. 0. 6. 13. 10. 0. 0. 0.]]
0

# 3.分割数据集并规范化
# 数据及目标
data1 = digits.data
target1 = digits.target
# # 数据增广
# data2 = np.vstack((data1, data1))
# target2 = np.hstack((target1, target1))
data2 = np.vstack((data1, data1, data1))
target2 = np.hstack((target1, target1, target1))
# 分割数据,将25%的数据作为测试集,其余作为训练集(你也可以指定其他比例的数据作为训练集)
# train_x, test_x, train_y, test_y = train_test_split(data1, target1, test_size=0.25)
train_x, test_x, train_y, test_y = train_test_split(data2, target2, test_size=0.25)
# 采用z-score规范化
ss = StandardScaler()
train_ss_scaled = ss.fit_transform(train_x)
test_ss_scaled = ss.transform(test_x)
# 采用0-1归一化,有分类器不能为负数,如多项式朴素贝叶斯分类
mm = MinMaxScaler()
train_mm_scaled = mm.fit_transform(train_x)
test_mm_scaled = mm.transform(test_x)
# 4.建立模型,并进行比较
models = {}
models['knn'] = KNeighborsClassifier()
models['svm'] = SVC()
models['bayes'] = MultinomialNB()
models['tree'] = DecisionTreeClassifier()
models['ada'] = AdaBoostClassifier(base_estimator=models['tree'], learning_rate=0.1)
for model_key in models.keys():
if model_key == 'knn' or model_key == 'svm' or model_key == 'ada':
model = models[model_key]
model.fit(train_ss_scaled, train_y)
predict = model.predict(test_ss_scaled)
print(model_key, "准确率:", accuracy_score(test_y, predict))
else:
model = models[model_key]
model.fit(train_mm_scaled, train_y)
predict = model.predict(test_mm_scaled)
print(model_key, "准确率: ", accuracy_score(test_y, predict))
knn 准确率: 0.976261127596
svm 准确率: 0.994807121662
bayes 准确率: 0.904302670623
tree 准确率: 0.993323442136
ada 准确率: 0.993323442136
分析以上结果,可以看到,除朴素贝叶斯模型的准确率只有0.90,KNN的准确率只有0.97,预测效果不是特别好以外,其他模型的准确率都已经高达0.993以上了
3 全连接神经网络(DNN)
3.1全连接神经网络原理
全连接神经网络(DNN)是最朴素的神经网络,它的网络参数最多,计算量最大。
全连接神经网络规则如下:
-
神经元按照层来布局。最左边的层叫做输入层,负责接收输入数据;最右边的层叫输出层,我们可以从这层获取神经网络输出数据。输入层和输出层之间的层叫做隐藏层,因为它们对于外部来说是不可见的。
-
同一层的神经元之间没有连接。
-
第N层的每个神经元和第N-1层的所有神经元相连(这就是full connected的含义),第N-1层神经元的输出就是第N层神经元的输入。
-
每个连接都有一个权值。
DNN的结构不固定,一般神经网络包括输入层、隐藏层和输出层,一个DNN结构只有一个输入层,一个输出层,输入层和输出层之间的都是隐藏层。每一层神经网络有若干神经元,层与层之间神经元相互连接,层内神经元互不连接,而且下一层神经元连接上一层所有的神经元。
隐藏层比较多(>2)的神经网络叫做深度神经网络(DNN的网络层数不包括输入层),深度神经网络的表达力比浅层网络更强,一个仅有一个隐含层的神经网络就能拟合任何一个函数,但是它需要很多很多的神经元。
优点:由于DNN几乎可以拟合任何函数,所以DNN的非线性拟合能力非常强。往往深而窄的网络要更节约资源。
缺点:DNN不太容易训练,需要大量的数据,很多技巧才能训练好一个深层网络。
感知器
DNN也可以叫做多层感知器(MLP),DNN的网络结构太复杂,神经元数量太多,为了方便讲解我们设计一个最简单的DNN网络结构--感知机
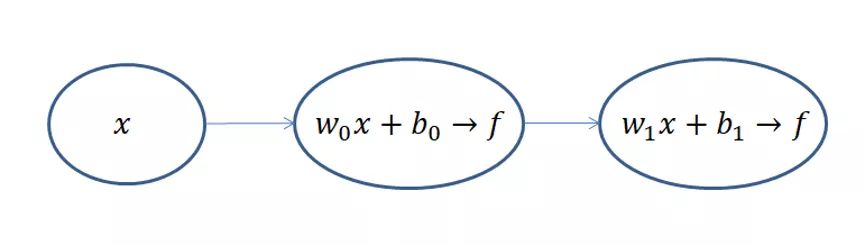
这是一个只有两层的神经网络,假定输入
x
x
x,我们规定隐层h和输出层o这两层都是
z
=
w
x
+
b
z=wx+b
z=wx+b和
f
(
z
)
=
1
1
+
e
−
z
f(z)=\frac{1}{1+e^{-z}}
f(z)=1+e−z1的组合,一旦输入样本x和标签y之后,模型就开始训练了。那么我们的问题就变成了求隐藏层的
w
0
、
b
0
w_0、b_0
w0、b0和输出层的
w
1
、
b
1
w_1、b_1
w1、b1四个参数的过程。
训练的目的是神经网络的输出和真实数据的输出"一样",但是在"一样"之前,模型输出和真实数据都是存在一定的差异,我们把这个"差异"作这样的一个参数 e e e代表误差的意思,那么模型输出加上误差之后就等于真实标签了,作: y = w x + b + e y=wx+b+e y=wx+b+e
当我们有n对 x x x和 y y y那么就有n个误差 e e e,我们试着把n个误差 e e e都加起来表示一个误差总量,为了不让残差正负抵消我们取平方或者取绝对值,本文取平方。这种误差我们称为“残差”,也就是模型的输出的结果和真实结果之间的差值。损失函数Loss还有一种称呼叫做“代价函数Cost”,残差表达式如下:
L o s s = ∑ i = 1 n e i 2 = ∑ i = 1 n ( y i − ( w x i + b ) ) 2 Loss=\sum_{i=1}^{n}e_i^2=\sum_{i=1}^{n}(y_i-(wx_i+b))^2 Loss=i=1∑nei2=i=1∑n(yi−(wxi+b))2
现在我们要做的就是找到一个比较好的w和b,使得整个Loss尽可能的小,越小说明我们训练出来的模型越好。
反向传播算法(BP)
BP算法主要有以下三个步骤 :
- 前向计算每个神经元的输出值;
- 反向计算每个神经元的误差项 e e e值;
- 最后用随机梯度下降算法迭代更新权重w和b。
我们把损失函数展开如下图所示,他的图形到底长什么样子呢?到底该怎么求他的最小值呢?
L o s s = ∑ i = 1 n ( x i 2 w 2 + b 2 + 2 x i w b − 2 y i b − 2 x i y i w + y i 2 ) = A w 2 + B b 2 + C w b + D b + D w + E b + F Loss=\sum_{i=1}^{n}(x_i^2w^2+b^2+2x_iwb-2y_ib-2x_iy_iw+y_i^2)\\ =Aw^2+Bb^2+Cwb+Db+Dw+Eb+F Loss=i=1∑n(xi2w2+b2+2xiwb−2yib−2xiyiw+yi2)=Aw2+Bb2+Cwb+Db+Dw+Eb+F
我们初始化一个 w 0 w_0 w0和 b 0 b_0 b0,带到Loss函数里面去,这个点( w o , b o , L o s s o w_o,b_o,Loss_o wo,bo,Losso)会出现在碗壁的某个位置,而我们的目标位置是碗底,那就慢慢的一点一点的往底部挪吧。
x n + 1 = x n − η d f ( x ) d x x_{n+1}=x_n-\eta \frac{df(x)}{dx} xn+1=xn−ηdxdf(x)
上式为梯度下降算法的公式,其中 d f ( x ) d x \frac{df(x)}{dx} dxdf(x)为梯度, η \eta η是学习率,也就是每次挪动的步长, η \eta η大每次迭代的脚步就大, η \eta η小每次迭代的脚步就小,我们只有取到合适的 η \eta η才能尽可能的接近最小值而不会因为步子太大越过了最小值。
当 x n = 3 x_n=3 xn=3时, − η d f ( x ) d x -\eta\frac{df(x)}{dx} −ηdxdf(x)为负数,更新后 x n + 1 x_{n+1} xn+1会减小;当 x n = − 3 x_n=-3 xn=−3时, − η d f ( x ) d x -\eta\frac{df(x)}{dx} −ηdxdf(x)为正数,更新后 x n + 1 x_{n+1} xn+1还是会减小。这总函数其实就是凸函数。满足 f ( x i + x 2 2 ) = f ( x i ) + f ( x 2 ) 2 f(\frac{x_i+x_2}{2})=\frac{f(x_i)+f(x_2)}{2} f(2xi+x2)=2f(xi)+f(x2)都是凸函数。沿着梯度的方向是下降最快的。
我们初始化 ( w 0 , b 0 , L o s s o ) (w_0,b_0,Loss_o) (w0,b0,Losso)后下一步就水到渠成了,
w 1 = w o − η ∂ L o s s ∂ w , b 1 = b o − η ∂ L o s s ∂ b w_1=w_o-\eta \frac{\partial Loss}{\partial w},b_1=b_o-\eta \frac{\partial Loss}{\partial b} w1=wo−η∂w∂Loss,b1=bo−η∂b∂Loss
有了梯度和学习率 η \eta η乘积之后,当这个点逐渐接近“碗底”的时候,偏导也随之下降,移动步伐也会慢慢变小,收敛会更为平缓,不会轻易出现“步子太大”而越过最低的情况。一轮一轮迭代,但损失值的变化趋于平稳时,模型的差不多就训练完成了。
梯度下降算法
我们用 w n e w = w o l d − η ∂ L o s s ∂ w w_{new}=w_{old}-\eta\frac{\partial Loss}{\partial w} wnew=wold−η∂w∂Loss讲以下梯度下降算法,零基础的读者可以仔细观看,有基础的请忽视梯度下降算法,我们定义y为真实值, y ^ \hat{y} y^为预测值
∂ L o s s ∂ w = ∂ ∂ w 1 2 ∑ i = 1 n ( y − y ^ ) 2 = 1 2 ∑ i = 1 n ∂ ∂ w ( y − y ^ ) 2 \frac{\partial Loss}{\partial w}=\frac{\partial}{\partial\mathrm{w}}\frac{1}{2}\sum_{i=1}^{n}(y-\hat{y})^2=\frac{1}{2}\sum_{i=1}^{n}\frac{\partial}{\partial\mathrm{w}}(y-\hat{y})^2 ∂w∂Loss=∂w∂21i=1∑n(y−y^)2=21i=1∑n∂w∂(y−y^)2
y是与 w w w无关的参数,而 y ^ = w x + b \hat{y}=wx+b y^=wx+b,下面我们用复合函数求导法
∂ L o s s ∂ w = ∂ L o s s ∂ y ^ ∂ y ^ ∂ w \frac{\partial Loss}{\partial\mathrm{w}}=\frac{\partial Loss}{\partial \hat{y}} \frac{\partial \hat{y}}{\partial w} ∂w∂Loss=∂y^∂Loss∂w∂y^
分别计算上式等号右边的两个偏导数
∂ L o s s ∂ y ^ = ∂ ∂ y ^ ( y 2 − 2 y y ^ + y ^ 2 ) = − 2 y + 2 y ^ \frac{\partial Loss}{\partial\hat{y}}=\frac{\partial}{\partial \hat{y}}(y^2-2y\hat{y}+\hat{y}^2)=-2y+2\hat{y} ∂y^∂Loss=∂y^∂(y2−2yy^+y^2)=−2y+2y^
∂ y ^ ∂ w = ∂ ∂ w ( w x + b ) = x \frac{\partial \hat{y}}{\partial\mathrm{w}}=\frac{\partial}{\partial\mathrm{w}}(wx+b)=x ∂w∂y^=∂w∂(wx+b)=x
代入 ∂ L o s s ∂ w \frac{\partial Loss}{\partial w} ∂w∂Loss,求得
∂ L o s s ∂ w = 1 2 ∑ i = 1 n ∂ ∂ w ( y − y ^ ) 2 = 1 2 ∑ i = 1 n 2 ( − y + y ^ ) x = − ∑ i = 1 n ( y − y ^ ) x \frac{\partial Loss}{\partial\mathrm{w}}=\frac{1}{2}\sum_{i=1}^{n}\frac{\partial}{\partial\mathrm{w}}(y-\hat{y})^2=\frac{1}{2}\sum_{i=1}^{n}2(-y+\hat{y})\mathrm{x}=-\sum_{i=1}^{n}(y-\hat{y})\mathrm{x} ∂w∂Loss=21i=1∑n∂w∂(y−y^)2=21i=1∑n2(−y+y^)x=−i=1∑n(y−y^)x
有了上面的式字,我们就能写出训练线性单元的代码
[ w 0 w 1 w 2 … w m ] n e w = [ w 0 w 1 w 2 … w m ] o l d + η ∑ i = 1 n ( y − y ^ ) [ x 0 x 1 x 2 … x m ] \begin{bmatrix} w_0 \\ w_1 \\ w_2 \\ … \\ w_m \\ \end{bmatrix}_{new}= \begin{bmatrix} w_0 \\ w_1 \\ w_2 \\ … \\ w_m \\ \end{bmatrix}_{old}+\eta\sum_{i=1}^{n}(y-\hat{y}) \begin{bmatrix} x_0 \\ x_1\\ x_2\\ … \\ x_m\\ \end{bmatrix} ⎣⎢⎢⎢⎢⎡w0w1w2…wm⎦⎥⎥⎥⎥⎤new=⎣⎢⎢⎢⎢⎡w0w1w2…wm⎦⎥⎥⎥⎥⎤old+ηi=1∑n(y−y^)⎣⎢⎢⎢⎢⎡x0x1x2…xm⎦⎥⎥⎥⎥⎤
这个网络用函数表达式写的话如下所示:
第一层(隐藏层) z h = w n x + b n , y h = 1 1 + e − z h \begin{matrix}z_h=w_nx+b_n,&y_h=\frac{1}{1+e^{-z_h}}\end{matrix} zh=wnx+bn,yh=1+e−zh1
第二层(输出层) z o = w o y h + b o , y o = 1 1 + e − z o \begin{matrix}z_o=w_oy_h+b_o,&y_o=\frac{1}{1+e^{-z_o}}\end{matrix} zo=woyh+bo,yo=1+e−zo1
接下来的工作就是把 w h 、 b h 、 w o 、 b o w_h、b_h、w_o、b_o wh、bh、wo、bo参数利用梯度下降算法求出来,把损失函数降低到最小,那么我们的模型就训练出来呢。
第一步:准备样本,每一个样本 x i x_i xi对应标签 y i y_i yi。
第二步:清洗数据,清洗数据的目的是为了帮助网络更高效、更准确地做好分类。
第三步:开始训练,
L o s s = ∑ i = 1 n ( y o i − y i ) 2 Loss=\sum_{i=1}^{n}(y_{oi}-y_i)^2 Loss=i=1∑n(yoi−yi)2
我们用这四个表达式,来更新参数。
( w h ) n = ( w h ) n − 1 − η ∂ L o s s ∂ w h (w_h)^n=(w_h)^{n-1}-\eta \frac{\partial Loss}{\partial w_h} (wh)n=(wh)n−1−η∂wh∂Loss
( b h ) n = ( b h ) n − 1 − η ∂ L o s s ∂ b h (b_h)^n=(b_h)^{n-1}-\eta \frac{\partial Loss}{\partial b_h} (bh)n=(bh)n−1−η∂bh∂Loss
( w o ) n = ( w o ) n − 1 − η ∂ L o s s ∂ w o (w_o)^n=(w_o)^{n-1}-\eta \frac{\partial Loss}{\partial w_o} (wo)n=(wo)n−1−η∂wo∂Loss
( b o ) n = ( b o ) n − 1 − η ∂ L o s s ∂ b o (b_o)^n=(b_o)^{n-1}-\eta \frac{\partial Loss}{\partial b_o} (bo)n=(bo)n−1−η∂bo∂Loss
问题来了, ∂ L o s s ∂ w h \frac{\partial Loss}{\partial w_h} ∂wh∂Loss、 ∂ L o s s ∂ b h \frac{\partial Loss}{\partial b_h} ∂bh∂Loss、 ∂ L o s s ∂ w o \frac{\partial Loss}{\partial w_o} ∂wo∂Loss、 ∂ L o s s ∂ b o \frac{\partial Loss}{\partial b_o} ∂bo∂Loss这4个值怎么求呢?
L o s s = ∑ i = 1 n ( y o i − y i ) 2 ⇒ L o s s = 1 2 ∑ i = 1 n ( y o i − y i ) 2 Loss=\sum_{i=1}^{n}(y_{oi}-y_i)^2\Rightarrow Loss=\frac{1}{2}\sum_{i=1}^{n}(y_{oi}-y_i)^2 Loss=i=1∑n(yoi−yi)2⇒Loss=21i=1∑n(yoi−yi)2
配一个 1 2 \frac{1}{2} 21出来,为了后面方便化简。
∂ L o s s ∂ w h = ∂ ∑ i = 1 n 1 2 ( y o i − y i ) 2 ∂ w o = ∂ ∑ i = 1 n y o i w o = ∑ i = 1 n ∂ y o i ∂ z o ⋅ z o w o = ∑ i = 1 n ∂ y o i ∂ z o ⋅ z o y h ⋅ ∂ y h ∂ z h ⋅ ∂ z h ∂ w h \frac{\partial Loss}{\partial w_h}=\frac{\partial \sum_{i=1}^{n}\frac{1}{2}(y_{oi}-y_i)^2}{\partial w_o}=\frac{\partial \sum_{i=1}^{n}y_{oi}}{w_o}=\sum_{i=1}^{n}\frac{\partial y_{oi}}{\partial z_o}·\frac{z_o}{w_o}=\sum_{i=1}^{n}\frac{\partial y_{oi}}{\partial z_o}·\frac{z_o}{y_h}·\frac{\partial y_h}{\partial z_h}·\frac{\partial z_h}{\partial w_h} ∂wh∂Loss=∂wo∂∑i=1n21(yoi−yi)2=wo∂∑i=1nyoi=i=1∑n∂zo∂yoi⋅wozo=i=1∑n∂zo∂yoi⋅yhzo⋅∂zh∂yh⋅∂wh∂zh
其他三个参数,和上面类似,这是一种“链乘型”求导方式。我们的网络两层就4个连乘,如果是10层,那么就是20个连乘。但一层网络的其中一个节点连接着下一层的其他节点时,那么这个节点上的系数的偏导就会通过多个路径传播过去,从而形成“嵌套型关系”。
DropOut
DropOut是深度学习中常用的方法,主要是为了克服过拟合的现象。全连接网络极高的VC维,使得它的记忆能力非常强,甚至把一下无关紧要的细枝末节都记住,一来使得网络的参数过多过大,二来这样训练出来的模型容易过拟合。
DropOut:是指在在一轮训练阶段临时关闭一部分网络节点。让这些关闭的节点相当去去掉。如下图所示去掉虚线圆和虚线,原则上是去掉的神经元是随机的。

python代码实现
** 手写数字是通过矩阵录入电脑的,我们先来研究一下怎么将数字图片变为矩阵**
from PIL import Image
im = Image.open('D:\\Download\\5.png') # 图像路径
width = im.size[0]
height = im.size[1]
fh = open('1.txt','w') # 转换成的txt文件
for i in range(height):
for j in range(width):
# 获取像素点颜色
color = im.getpixel((j,i))
# 如果color=0则说明是黑色,写成1;如果color=1则说明是白色,写成0
if(color == 0):
fh.write('1')
else:
fh.write('0')
fh.write('\n')
fh.close()
** 我们来查看第一个测试数据的输入**
import tensorflow as tf # 深度学习库,Tensor 就是多维数组
mnist = tf.contrib.keras.datasets.mnist # mnist 是 28x28 的手写数字图片和对应标签的数据集
(x_train, y_train),(x_test, y_test) = mnist.load_data() # 分割数据集
print(x_train[0]) # 查看第一个测试数据的输入
[[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 3 18 18 18 126 136
175 26 166 255 247 127 0 0 0 0]
[ 0 0 0 0 0 0 0 0 30 36 94 154 170 253 253 253 253 253
225 172 253 242 195 64 0 0 0 0]
[ 0 0 0 0 0 0 0 49 238 253 253 253 253 253 253 253 253 251
93 82 82 56 39 0 0 0 0 0]
[ 0 0 0 0 0 0 0 18 219 253 253 253 253 253 198 182 247 241
0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 80 156 107 253 253 205 11 0 43 154
0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 14 1 154 253 90 0 0 0 0
0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 139 253 190 2 0 0 0
0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 11 190 253 70 0 0 0
0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 35 241 225 160 108 1
0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 81 240 253 253 119
25 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 45 186 253 253
150 27 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 16 93 252
253 187 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 249
253 249 64 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 46 130 183 253
253 207 2 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 39 148 229 253 253 253
250 182 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 24 114 221 253 253 253 253 201
78 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 23 66 213 253 253 253 253 198 81 2
0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 18 171 219 253 253 253 253 195 80 9 0 0
0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 55 172 226 253 253 253 253 244 133 11 0 0 0 0
0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 136 253 253 253 212 135 132 16 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0]]
让我们把这个矩阵用图像表示出来
import matplotlib.pyplot as plt
%matplotlib inline
plt.imshow(x_train[0],cmap=plt.cm.binary) # 显示黑白图像
plt.show()

单层线性神经网络
现在我们知道了怎么进行手写数字和矩阵的转换
让我们先研究一个最简单的线性神经网络
所用到的手写数据集是已经录入处理好的数据集MNIST

- 训练迭代次数
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import numpy as np
import matplotlib.pyplot as plt
# Import data
#下载和读取MNIST的训练集、测试集和验证集
#将数据读到内存后,我们就可以直接通过mnist.test.images和mnist.test.labels来获得测试集的图片和对应的标签了。TensorFlow提供的方法从训练集里取了5000个样本作为验证集,所以训练集、测试集、验证集的大小分别为:55000、10000、5000。
#'input_data/'是你存放下载的数据集的文件夹名。
mnist = input_data.read_data_sets('input_data/', one_hot=True)
# Create the model
x = tf.placeholder(tf.float32, [None, 784])
#这里简单的将参数都初始化为0。在复杂的模型中,初始化参数有很多的技巧。
W = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([10]))
#一个简单的线性模型,tf.matmul表示矩阵相乘。
y = tf.matmul(x, W) + b
y_ = tf.placeholder(tf.float32, [None, 10])
keep_prob = tf.placeholder("float")
#计算每个样本的cross-entropy
# loss function & optimization algorithm
cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=y))
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
sess = tf.InteractiveSession()
tf.global_variables_initializer().run()
losss = []
accurs = []
steps = []
correct_predict = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_predict, tf.float32))
for i in range(20000):
batch = mnist.train.next_batch(50)
sess.run(train_step, feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.5})
if i % 100 == 0:
loss = sess.run(cross_entropy, {x: batch[0], y_: batch[1], keep_prob: 1.0})
accur = sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels, keep_prob: 1.0})
steps.append(i)
losss.append(loss)
accurs.append(accur)
# plot loss
plt.figure()
plt.plot(steps, losss)
plt.xlabel('Number of steps')
plt.ylabel('Loss')
plt.figure()
plt.plot(steps, accurs)
plt.hlines(0.92, 0, max(steps), colors='r', linestyles='dashed')
plt.xlabel('Number of steps')
plt.ylabel('Accuracy')
plt.show()
print('Steps: {} loss: {}'.format(20000, loss))
print('Steps: {} accuracy: {}'.format(20000, accur))
Extracting input_data/train-images-idx3-ubyte.gz
Extracting input_data/train-labels-idx1-ubyte.gz
Extracting input_data/t10k-images-idx3-ubyte.gz
Extracting input_data/t10k-labels-idx1-ubyte.gz


Steps: 20000 loss: 0.16216324269771576
Steps: 20000 accuracy: 0.9208999872207642
可以看到,我们最终的准确率大约在0.92左右,在上面模型中优化器使用Adam,学习率设为1e-4。我们可以考虑换一个优化器(梯度下降法)来求损失函数。
- 不同的优化器
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import numpy as np
import matplotlib.pyplot as plt
# Import data
#下载和读取MNIST的训练集、测试集和验证集
#将数据读到内存后,我们就可以直接通过mnist.test.images和mnist.test.labels来获得测试集的图片和对应的标签了。TensorFlow提供的方法从训练集里取了5000个样本作为验证集,所以训练集、测试集、验证集的大小分别为:55000、10000、5000。
#'input_data/'是你存放下载的数据集的文件夹名。
mnist = input_data.read_data_sets('input_data/', one_hot=True)
# Create the model
x = tf.placeholder(tf.float32, [None, 784])
#这里简单的将参数都初始化为0。在复杂的模型中,初始化参数有很多的技巧。
W = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([10]))
#一个简单的线性模型,tf.matmul表示矩阵相乘。
y = tf.matmul(x, W) + b
y_ = tf.placeholder(tf.float32, [None, 10])
keep_prob = tf.placeholder("float")
#计算每个样本的cross-entropy
# loss function & optimization algorithm
cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=y))
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy)
sess = tf.InteractiveSession()
tf.global_variables_initializer().run()
losss = []
accurs = []
steps = []
correct_predict = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_predict, tf.float32))
for i in range(20000):
batch = mnist.train.next_batch(50)
sess.run(train_step, feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.5})
if i % 100 == 0:
loss = sess.run(cross_entropy, {x: batch[0], y_: batch[1], keep_prob: 1.0})
accur = sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels, keep_prob: 1.0})
steps.append(i)
losss.append(loss)
accurs.append(accur)
# plot loss
plt.figure()
plt.plot(steps, losss)
plt.xlabel('Number of steps')
plt.ylabel('Loss')
plt.figure()
plt.plot(steps, accurs)
plt.hlines(0.92, 0, max(steps), colors='r', linestyles='dashed')
plt.xlabel('Number of steps')
plt.ylabel('Accuracy')
plt.show()
print('Steps: {} loss: {}'.format(20000, loss))
print('Steps: {} accuracy: {}'.format(20000, accur))
Extracting input_data/train-images-idx3-ubyte.gz
Extracting input_data/train-labels-idx1-ubyte.gz
Extracting input_data/t10k-images-idx3-ubyte.gz
Extracting input_data/t10k-labels-idx1-ubyte.gz


Steps: 20000 loss: 0.09164124727249146
Steps: 20000 accuracy: 0.9239000082015991
结论:单层的Softmax Regression进行手写数字识别的准确率约为92%,比传统机器学习的预测效果还是差很多的,不过这只是最简单的线性神经网络,所以我们可以继续继续探究
二层神经网络
神经网络设计
将28×28的图片转换成向量,长度为784,因此神经网络的输入层有784个神经元;输出层显然需要10个神经元,因为输出的是0~9这10个数字;隐含层采用15个神经元。网络结构如下:

- 隐层的激活函数采用 sigmoid 函数,输出层的激活函数采用 softmax 函数。
- 损失函数为实际的label与概率归一化预测输出的交叉熵,具体采用 “tf.nn.softmax_cross_entropy_with_logits” 进行计算
- 优化算法采用Adam算法,即tensorflow中的“tf.train.AdamOptimizer”。(因为之前的研究中发现不同优化器得出的准确度差不多,故此处不再另外画tf.train.GradientDescentOptimizer(梯度下降法)的结果图)
python代码
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
old_v = tf.logging.get_verbosity()
tf.logging.set_verbosity(tf.logging.ERROR)
# create model
# input layer
x = tf.placeholder(tf.float32, [None, 784]) # input images
y_ = tf.placeholder(tf.float32, [None, 10]) # input labels
# hidden layer
hidden_layer_count = 15
w1 = tf.Variable(tf.zeros([784, hidden_layer_count]))
b1 = tf.Variable(tf.zeros([hidden_layer_count]))
y1 = tf.sigmoid(tf.matmul(x, w1) + b1)
# output layer
output_layer_count = 10
w2 = tf.Variable(tf.zeros([hidden_layer_count, output_layer_count]))
b2 = tf.Variable(tf.zeros(output_layer_count))
y2 = tf.nn.softmax(tf.matmul(y1, w2) + b2)
# loss function & optimization algorithm
cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=y2))
train_step = tf.train.AdamOptimizer(learning_rate=0.01).minimize(cross_entropy)
# new session
sess = tf.Session()
sess.run(tf.global_variables_initializer())
# train
for i in range(10000):
batch_xs, batch_ys = mnist.train.next_batch(50)
sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})
if i % 1000 == 0:
loss = sess.run(cross_entropy, {x: batch_xs, y_: batch_ys})
print("Iter: %s loss: %s" % (i, loss))
# test
correct_prediction = tf.equal(tf.argmax(y_, 1), tf.argmax(y2, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
print('Accuracy: ', sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels}))
tf.logging.set_verbosity(old_v)
Extracting MNIST_data/train-images-idx3-ubyte.gz
Extracting MNIST_data/train-labels-idx1-ubyte.gz
Extracting MNIST_data/t10k-images-idx3-ubyte.gz
Extracting MNIST_data/t10k-labels-idx1-ubyte.gz
Extracting MNIST_data/train-images-idx3-ubyte.gz
Extracting MNIST_data/train-labels-idx1-ubyte.gz
Extracting MNIST_data/t10k-images-idx3-ubyte.gz
Extracting MNIST_data/t10k-labels-idx1-ubyte.gz
Iter: 0 loss: 2.29982
Iter: 1000 loss: 1.75346
Iter: 2000 loss: 1.84664
Iter: 3000 loss: 1.82348
Iter: 4000 loss: 1.78865
Iter: 5000 loss: 1.80391
Iter: 6000 loss: 1.68537
Iter: 7000 loss: 1.73748
Iter: 8000 loss: 1.7446
Iter: 9000 loss: 1.6616
Accuracy: 0.7207
该方法最终的准确率约为72.07%。使用单层的Softmax Regression进行手写数字识别的准确率约为92%,而加了一层隐层之后,准确率只有70%左右,令人感到意外,因为一般网络越深,分类效果应该越好才对。不过简单分析一下,原因可能就是加了一层隐层之后参数数量变大,容易产生过拟合等。单层的Softmax Regression网络其参数个数为78410+10=7850,而增加一层15个神经元的隐层之后,参数个数变为(78415+15)+(15*10+10)=11935。因此我们可以通过调整隐层神经元的个数、w和b的初始值、激活函数、学习率、每批训练样本的个数、训练的迭代次数等尝试提高准确率。
优化策略
一、指数衰减学习率
学习率是指每次参数更新的幅度,如下。

学习率设置的过小则参数更新太慢,学习效率低;学习率设置的太大,则后期容易产生振荡,难以收敛。但在参数更新前期,参数距离最优参数较远,希望学习率设置的大些;而在参数更新后期,参数距离最优参数较近,为了避免产生振荡,希望参数设置的小些。由此可见,学习率设置成固定值并不是最好的。
指数衰减学习率是根据运行的轮数动态调整学习率的一种方法,在TensorFlow中表示如下:
tf.train.exponential_decay(
learning_rate, # 学习率初始值
global_step, # 当前训练总轮数(不能为负)
decay_steps, # 衰减步长(必须为正),即多少轮更新一次学习率
decay_rate, # 衰减率,一般取值范围为(0,1)
staircase=False, # True:阶梯型衰减, False:平滑衰减
name=None # 操作的可选名称,默认为'ExponentialDecay'
)
学习率的计算公式为:
decayed_learning_rate = learning_rate *
decay_rate ^ (global_step / decay_steps)
注意当staircase为Ture时,global_step / decay_steps是一个整数,衰减率为阶梯函数 ,如下。
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
learning_rate = 0.5
decay_rate = 0.9
global_steps = 1000
decay_steps = 100
global_step = tf.Variable(0)
lr1 = tf.train.exponential_decay(
learning_rate = learning_rate,
global_step = global_step,
decay_steps = decay_steps,
decay_rate = decay_rate,
staircase = True
)
lr2 = tf.train.exponential_decay(
learning_rate = learning_rate,
global_step = global_step,
decay_steps = decay_steps,
decay_rate = decay_rate,
staircase = False
)
LR1 = []
LR2 = []
with tf.Session() as sess:
for i in range(global_steps):
LR1.append(sess.run(lr1, feed_dict = {global_step: i}))
LR2.append(sess.run(lr2, feed_dict = {global_step: i}))
plt.figure(1)
plt.plot(range(global_steps), LR1, 'r-')
plt.plot(range(global_steps), LR2, 'b-')
plt.show()

其中lr1的staircase =True, 而 lr2的staircase =False,衰减如下所示,lr1是红色曲线,lr2是蓝色曲线,可以看到lr1中每经过decay_steps = 100步之后进行计算,而lr2在每个step都进行计算。
二、正则化
当模型比较复杂时,它会去拟合数据中的噪声而损失了一定的通用性,即产生了过拟合。为了避免过拟合问题,常用的方法是加入正则化项,即在损失函数中加入刻画模型复杂程度的指标,将优化目标定义为 J ( θ ) + λ R ( w ) J(\theta)+λR(w) J(θ)+λR(w),其中R(w)刻画的是模型的复杂程度,包括了权重项w不包括偏置项b,λ表示模型复杂损失在总损失中的比例。
常用的正则化有L1正则化和L2正则化,
R
(
w
)
=
∣
∣
ω
∣
∣
1
=
∑
i
∣
∣
ω
∣
i
∣
R(w) = {||\omega||}_1 = \sum_{i}|{|\omega|}_i|
R(w)=∣∣ω∣∣1=i∑∣∣ω∣i∣
R
(
w
)
=
∣
∣
ω
∣
∣
2
2
=
∑
i
∣
∣
ω
∣
i
2
∣
R(w) = {||\omega||}_2^2 = \sum_{i}|{|\omega|}_i^2|
R(w)=∣∣ω∣∣22=i∑∣∣ω∣i2∣
其中,L1正则化会让参数变得更稀疏,L2则不会。一个含有L2正则化的损失函数的例子:
loss = tf.reduce_mean(tf.square(y_ - y)) + tf.contrib.layers.l2_regularizer(lambda)(w)
其中损失函数的第一项一般为预测输出和真实label之间的均方误差或交叉熵,第二项即为L2正则化项,lambda表示正则化项的权重,也就是J(θ)+λR(w)中的λ,w为需要计算正则化损失的参数。
TensorFlow中tf.contrib.layers.l2_regularizer函数的定义:
tf.contrib.layers.l2_regularizer(
scale, # 正则项的系数
scope=None # 可选的scope name
)
在简单的神经网络中,加入正则化来计算损失函数还是比较容易的。当神经网络变得非常复杂(层数很多)的时候,那么在损失函数中加入正则化的就会变得非常的复杂,使得损失函数的定义变得很长,从而还会导致程序的可读性变差,如这个例子。而且还有可能,当神经网络变得复杂的时候,定义网络结构的部分和计算损失函数的部分不在同一个函数中,这样就会使得计算损失函数不方便。TensorFlow提供了集合的方式,通过在计算图中保存一组实体,来解决这一类问题。
优化后
隐层神经元个数仍设为15个,隐层激活函数改为Relu函数。weight初始化为服从正态分布的随机数,bias初始化为常数0.1。
使用指数衰减学习率,学习率初始值设为0.01,衰减步长设为训练集的batch个数,衰减率设为0.99,优化算法采用Adam。
加入了正则化,正则项的系数设为0.0001。batch的大小为100,训练次数为20000,程序如下。
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import matplotlib.pyplot as plt
# move warning
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
old_v = tf.logging.get_verbosity()
tf.logging.set_verbosity(tf.logging.ERROR)
# neural network parameters
INPUT_NODE = 784
LAYER1_NODE = 15
OUTPUT_NODE = 10
# exponential attenuation learning rate
LEARNING_RATE_BASE = 0.01
LEARNING_RATE_DECAY = 0.99
# regularization coefficient
LAMDA = 0.0001
# training parameters
BATCH_SIZE = 100
TRAINING_STEPS = 100000
# initialize weights and add regularization
def get_weight(shape, lamda):
weights = tf.Variable(tf.random_normal(shape=shape), dtype=tf.float32)
tf.add_to_collection("losses", tf.contrib.layers.l2_regularizer(lamda)(weights))
return weights
# read data
mnist = input_data.read_data_sets('input_data/', one_hot=True)
# create model
# input layer
x = tf.placeholder(tf.float32, [None, INPUT_NODE]) # input images
y_ = tf.placeholder(tf.float32, [None, OUTPUT_NODE]) # input labels
# hidden layer
w1 = get_weight([INPUT_NODE, LAYER1_NODE], LAMDA)
b1 = tf.Variable(tf.constant(0.1, shape=[LAYER1_NODE]))
y1 = tf.nn.relu(tf.matmul(x, w1) + b1)
# output layer
w2 = get_weight([LAYER1_NODE, OUTPUT_NODE], LAMDA)
b2 = tf.Variable(tf.constant(0.1, shape=[OUTPUT_NODE]))
y2 = tf.nn.softmax(tf.matmul(y1, w2) + b2)
# loss function
cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=y2))
tf.add_to_collection('losses', cross_entropy)
loss = tf.add_n(tf.get_collection('losses'))
# optimization algorithm
global_step = tf.Variable(0, trainable=False)
learning_rate = tf.train.exponential_decay(LEARNING_RATE_BASE, global_step,
mnist.train.num_examples / BATCH_SIZE, LEARNING_RATE_DECAY)
train_step = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(loss, global_step=global_step)
# new session
sess = tf.Session()
sess.run(tf.global_variables_initializer())
# train
losss = []
accurs = []
steps = []
rates = []
correct_prediction = tf.equal(tf.argmax(y_, 1), tf.argmax(y2, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
for i in range(TRAINING_STEPS):
batch_xs, batch_ys = mnist.train.next_batch(BATCH_SIZE)
_, now_loss, step, now_learn_rate = sess.run([train_step, loss, global_step, learning_rate],
feed_dict={x: batch_xs, y_: batch_ys})
if i % 1000 == 0:
accur = sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels})
accurs.append(accur)
losss.append(now_loss)
steps.append(step)
rates.append(now_learn_rate)
# learning rate
plt.figure()
plt.plot(steps, rates)
plt.xlabel('Number of steps')
plt.ylabel('Learning rate')
# loss
plt.figure()
plt.plot(steps, losss)
plt.xlabel('Number of steps')
plt.ylabel('Loss')
# accuracy
plt.figure()
plt.plot(steps, accurs)
plt.hlines(1, 0, max(steps), colors='r', linestyles='dashed')
plt.xlabel('Number of steps')
plt.ylabel('Accuracy')
plt.show()
print('Steps: {} accuracy: {}'.format(100000, accur))
tf.logging.set_verbosity(old_v)
Extracting input_data/train-images-idx3-ubyte.gz
Extracting input_data/train-labels-idx1-ubyte.gz
Extracting input_data/t10k-images-idx3-ubyte.gz
Extracting input_data/t10k-labels-idx1-ubyte.gz
<matplotlib.figure.Figure at 0x247461c97f0>
<matplotlib.figure.Figure at 0x24746302630>
<matplotlib.figure.Figure at 0x24746b68e48>
Steps: 100000 accuracy: 0.9592000246047974


由图可知,学习率指数地下降,Loss下降地很快,测试集准确度也很快稳定下来,最终准确度约为95%,相比于之前的72%有了很大的提升。
我们还可以探究每一层网络的weight、bias与迭代次数的关系
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import matplotlib.pyplot as plt
# move warning
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
old_v = tf.logging.get_verbosity()
tf.logging.set_verbosity(tf.logging.ERROR)
# neural network parameters
INPUT_NODE = 784
LAYER1_NODE = 15
OUTPUT_NODE = 10
# exponential attenuation learning rate
LEARNING_RATE_BASE = 0.01
LEARNING_RATE_DECAY = 0.99
# regularization coefficient
LAMDA = 0.0001
# training parameters
BATCH_SIZE = 100
TRAINING_STEPS = 20000
# initialize weights and add regularization
def get_weight(weight_name, shape, lamda):
weights = tf.Variable(tf.random_normal(shape=shape), dtype=tf.float32)
tf.summary.histogram(weight_name, weights)
tf.add_to_collection("losses", tf.contrib.layers.l2_regularizer(lamda)(weights))
return weights
# read data
mnist = input_data.read_data_sets('MNIST_data/', one_hot=True)
# create model
# input layer
x = tf.placeholder(tf.float32, [None, INPUT_NODE]) # input images
y_ = tf.placeholder(tf.float32, [None, OUTPUT_NODE]) # input labels
# hidden layer
with tf.name_scope('hidden'):
w1 = get_weight('w1', [INPUT_NODE, LAYER1_NODE], LAMDA)
b1 = tf.Variable(tf.constant(0.1, shape=[LAYER1_NODE],name='b1'))
tf.summary.histogram('/b1', b1)
y1 = tf.nn.relu(tf.matmul(x, w1) + b1)
# output layer
with tf.name_scope('output'):
w2 = get_weight('w2', [LAYER1_NODE, OUTPUT_NODE], LAMDA)
b2 = tf.Variable(tf.constant(0.1, shape=[OUTPUT_NODE],name='b2'))
tf.summary.histogram('/b2', b2)
y2 = tf.nn.softmax(tf.matmul(y1, w2) + b2)
# loss function
cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=y2))
tf.add_to_collection('losses', cross_entropy)
loss = tf.add_n(tf.get_collection('losses'))
# optimization algorithm
global_step = tf.Variable(0, trainable=False)
learning_rate = tf.train.exponential_decay(LEARNING_RATE_BASE, global_step, mnist.train.num_examples / BATCH_SIZE, LEARNING_RATE_DECAY,staircase=True)
train_step = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(loss, global_step=global_step)
# new session
sess = tf.Session()
merged = tf.summary.merge_all()
# save the logs
writer = tf.summary.FileWriter("logs/", sess.graph)
sess.run(tf.global_variables_initializer())
# train
losss_train = []
losss_test = []
accurs_train = []
accurs_test = []
steps = []
rates = []
correct_prediction = tf.equal(tf.argmax(y_, 1), tf.argmax(y2, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
for i in range(TRAINING_STEPS):
batch_xs, batch_ys = mnist.train.next_batch(BATCH_SIZE)
accuracy_train, _, now_loss, step, now_learn_rate,merge= sess.run([accuracy, train_step, loss, global_step, learning_rate,merged],
feed_dict={x: batch_xs, y_: batch_ys})
writer.add_summary(merge, i)
if i % 1000 == 0:
accur_test,loss_test = sess.run([accuracy,loss], feed_dict={x: mnist.test.images, y_: mnist.test.labels})
accurs_test.append(accur_test)
losss_test.append(loss_test)
accurs_train.append(accuracy_train)
losss_train.append(now_loss)
steps.append(step)
rates.append(now_learn_rate)
# learning rate
plt.figure()
plt.plot(steps, rates)
plt.xlabel('Number of steps')
plt.ylabel('Learning rate')
# loss
plt.figure()
plt.plot(steps, losss_train, label='losss_train')
plt.plot(steps, losss_test, label='losss_test')
plt.xlabel('Number of steps')
plt.ylabel('Loss')
plt.legend(loc='lower right')
# accuracy
plt.figure()
plt.plot(steps, accurs_train,label='accurs_train')
plt.plot(steps, accurs_test,label='accurs_test')
plt.hlines(1, 0, max(steps), colors='r', linestyles='dashed')
plt.xlabel('Number of steps')
plt.ylabel('Accuracy')
plt.legend(loc='lower right')
plt.show()
print('Accuracy: ', sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels}))
tf.logging.set_verbosity(old_v)
但是可能是由于环境变量的问题,代码没有在jupyter notebook中运行成功,但是可以在pycharm中运行,此处仅给出运行结果。



增加隐层神经元的个数
此外,通过增加隐层神经元的个数可以进一步提高神经网络的性能。例如,我们将隐层神经元由15个提高到100个,学习率初始值设为0.005,则最终准确度为98%左右,如下图所示。
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import matplotlib.pyplot as plt
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
old_v = tf.logging.get_verbosity()
tf.logging.set_verbosity(tf.logging.ERROR)
mnist = input_data.read_data_sets('input_data/', one_hot=True)
# neural network parameters
INPUT_NODE = 784
LAYER1_NODE = 100
OUTPUT_NODE = 10
# exponential attenuation learning rate
LEARNING_RATE_BASE = 0.005
LEARNING_RATE_DECAY = 0.99
# regularization coefficient
LAMDA = 0.0001
# training parameters
BATCH_SIZE = 100
TRAINING_STEPS = 100000
# initialize weights and add regularization
def get_weight(shape, lamda):
weights = tf.Variable(tf.random_normal(shape=shape), dtype=tf.float32)
tf.add_to_collection("losses", tf.contrib.layers.l2_regularizer(lamda)(weights))
return weights
# create model
# input layer
x = tf.placeholder(tf.float32, [None, INPUT_NODE]) # input images
y_ = tf.placeholder(tf.float32, [None, OUTPUT_NODE]) # input labels
# hidden layer
w1 = get_weight([INPUT_NODE, LAYER1_NODE], LAMDA)
b1 = tf.Variable(tf.constant(0.1, shape=[LAYER1_NODE]))
y1 = tf.nn.relu(tf.matmul(x, w1) + b1)
# output layer
w2 = get_weight([LAYER1_NODE, OUTPUT_NODE], LAMDA)
b2 = tf.Variable(tf.constant(0.1, shape=[OUTPUT_NODE]))
y2 = tf.nn.softmax(tf.matmul(y1, w2) + b2)
# loss function
cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=y2))
tf.add_to_collection('losses', cross_entropy)
loss = tf.add_n(tf.get_collection('losses'))
# optimization algorithm
global_step = tf.Variable(0, trainable=False)
learning_rate = tf.train.exponential_decay(LEARNING_RATE_BASE, global_step,
mnist.train.num_examples / BATCH_SIZE, LEARNING_RATE_DECAY)
train_step = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(loss, global_step=global_step)
# new session
sess = tf.Session()
sess.run(tf.global_variables_initializer())
# train
losss = []
accurs = []
steps = []
rates = []
correct_prediction = tf.equal(tf.argmax(y_, 1), tf.argmax(y2, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
for i in range(TRAINING_STEPS):
batch_xs, batch_ys = mnist.train.next_batch(BATCH_SIZE)
_, now_loss, step, now_learn_rate = sess.run([train_step, loss, global_step, learning_rate],
feed_dict={x: batch_xs, y_: batch_ys})
if i % 1000 == 0:
accur = sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels})
accurs.append(accur)
losss.append(now_loss)
steps.append(step)
rates.append(now_learn_rate)
# learning rate
plt.figure()
plt.plot(steps, rates)
plt.xlabel('Number of steps')
plt.ylabel('Learning rate')
# loss
plt.figure()
plt.plot(steps, losss)
plt.xlabel('Number of steps')
plt.ylabel('Loss')
# accuracy
plt.figure()
plt.plot(steps, accurs)
plt.hlines(1, 0, max(steps), colors='r', linestyles='dashed')
plt.xlabel('Number of steps')
plt.ylabel('Accuracy')
plt.show()
tf.logging.set_verbosity(old_v)

4 卷积神经网络(CNN)
4.1 卷积操作
图像中的每一个像素点和周围的像素点是紧密联系的,但和太远的像素点就不一定有什么关联了,这就是人的视觉感受野的概念,每一个感受野只接受一小块区域的信号。这一小块区域的像素是互相关联的,每一个神经元不需要接收全部的像素点的信息,只需要接收局部的像素点作为输入,而后将这些神经元收到的局部信息综合起来就可以得到全局的信息。
图像的卷积操作就是指从图像的左上角开始,利用一个卷积模板在图像上滑动,在每一个位置将图像像素点上的像素灰度值与对应的卷积核上的数值相乘,并将所有相乘后的结果求和作为卷积核中心像素对应的卷积结果值,按照此步骤在图像的所有位置完成滑动得到卷积结果的过程。这个卷积模板在卷积神经网络中通常叫做卷积核,或滤波器,下图所示为一个图像卷积操作部分过程的示意图,图中采用33的卷积核对55大小的图片进行卷积操作。
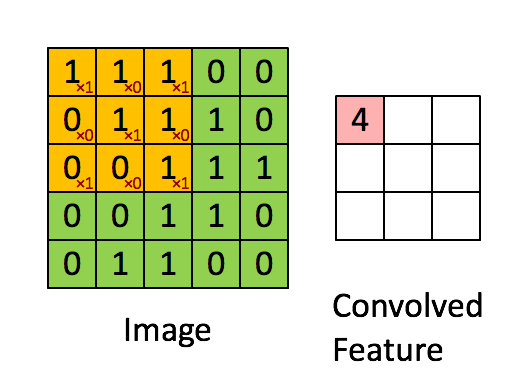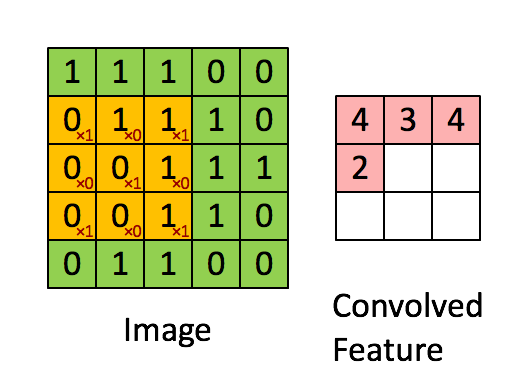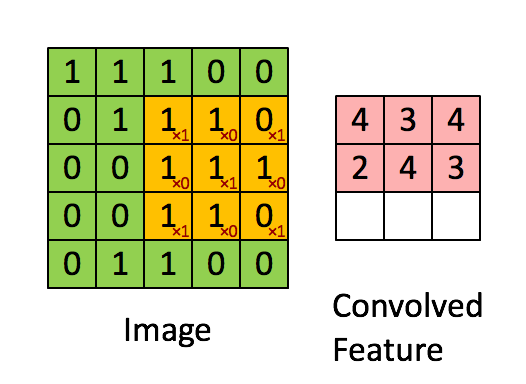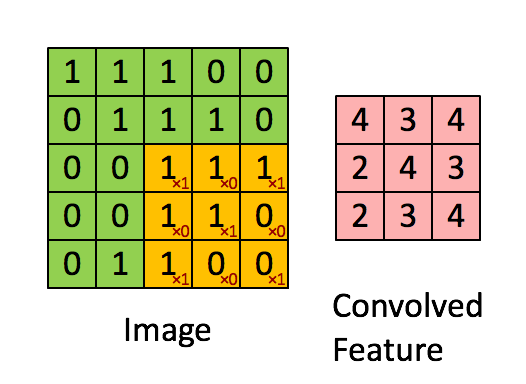
图像卷积操作可以表示为
g
=
f
⊗
h
g = f \otimes h
g=f⊗h,其中:
g
(
i
,
j
)
=
∑
k
,
l
f
(
i
+
k
,
j
+
l
)
h
(
k
,
l
)
g(i,j) = \sum_{k,l}f(i+k,j+l)h(k,l)
g(i,j)=k,l∑f(i+k,j+l)h(k,l)
其中,f为待卷积图像的矩阵,h为卷积核函数,g为图像卷积操作的输出图像。在深度学习中,输入的图像矩阵和输出的结果矩阵都称作特征图。
4.2 池化操作
在通过卷积层获得了二维特征图之后,通常情况下特征图的尺寸仍然很大,如果直接用这些特征送给分类器进行分类,那么在计算量上将会面临很大的考验,另外也有可能出现过拟合问题,因此不方便直接用这些特征图做分类。池化操作就是为了解决这样的问题而设计的技术,它在特征图矩阵上对不同位置的特征进行聚合统计,浓缩特征。
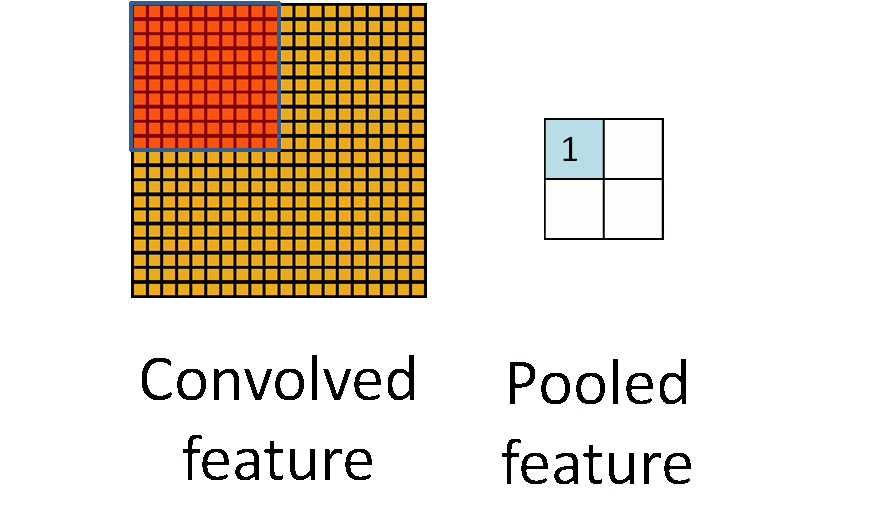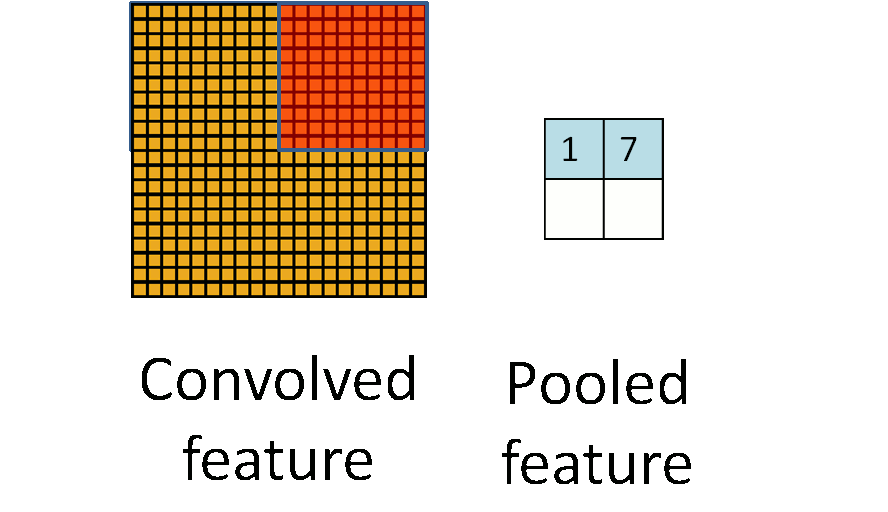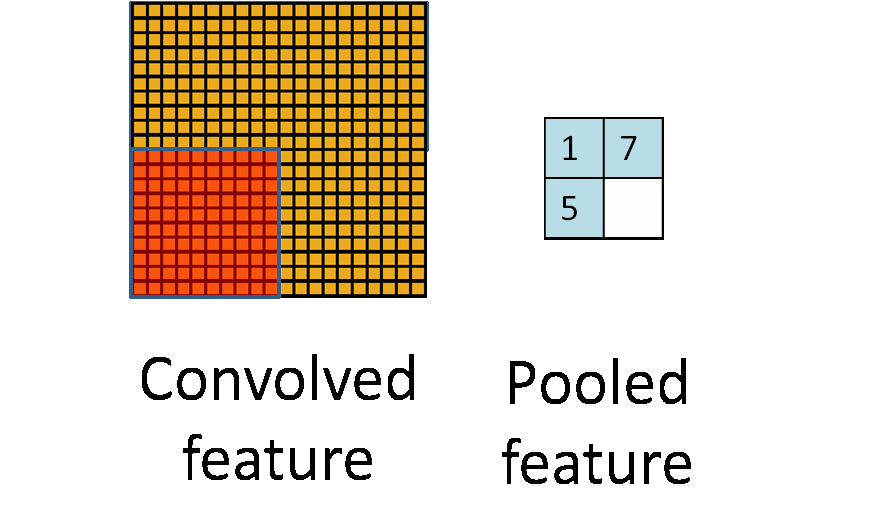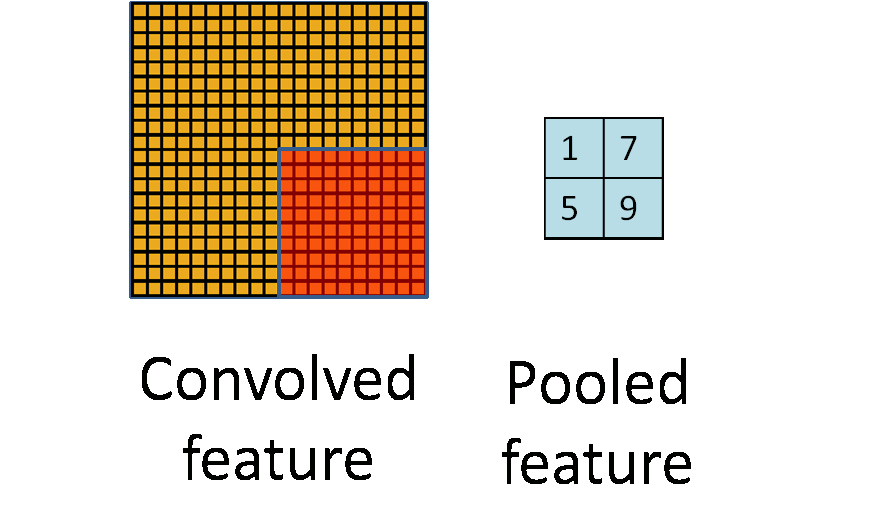
池化操作的示意图如上图所示。常用的池化操作有两种,一种是平均池化,平均池化操作的输出是池化核对应范围内输入特征图中特征的均值;另一种是最大池化,最大池化操作的输出是池化核对应范围内输入特征图中特征的最大值。可以看出池化操作是一种特殊的图像卷积操作。
进行池化操作能显著改善卷积神经网络的效果,这主要是由于特征浓缩,特征图维度降低,卷积神经网络经常出现的过拟合现象也会相应减轻的缘故。此于,由于浓缩了一定范围内特征信息,池化操作还有增强卷积神经网络中小范围内平移不变性的作用。
4.3 卷积层
一般的卷积神经网络由多个卷积层构成,每个卷积层中通常会进行如下几个操作.
- 图像通过多个不同的卷积核的滤波,并加偏置(bias),提取出局部特征,每一个卷积核会映射出一个新的2D图像。
- 将前面的卷积核的滤波输出结果进行非线性的激活函数的处理,目前一般用ReLU函数。
- 对激活函数的结果再进行池化操作(即降采样,比如22的图片降为11的图片),目前一般是使用最大池化,保留最显著的特征,并提升模型的畸变容忍能力。
注意,一个卷积层中一般有多个不同的卷积核,因为每个卷积核只能提取一种图片特征,可以增加卷积核的数量多提取一些特征。每一个卷积核对应一个滤波后映射出的新图像,同一个新图像中的每一个像素都来自完全相同的卷积核,这就是卷积核的权值共享。共享卷积核的权值参数的目的很简单,降低模型复杂度,减轻过拟合并降低计算量。
卷积层需要训练的权值数量只和卷积核的大小以及卷积核的数量有关,我们可以使用非常少的参数处理任意大小的图片。每一个卷积层提取的特征,在后面的层中都会抽象组合成更高阶的特征。
4.4 卷积神经网络
卷积神经网络和多层感知器网络的不同之处在于,卷积神经网络包含了若干个卷积层和池化层构成的特征抽取器,可以有效地减少参数数量,大大简化模型的复杂度,从而减少过拟合的风险。同时赋予了卷积神经网络对平移和轻度变形的容忍性,提高了模型的泛化能力。
著名的LeNet5的结构如下图所示,包含了三个卷积层,一个全连接层和一个高斯连接层。一般来说,针对不同数据集、不同大小的输入图片可以根据需要合理地设计不同的卷积神经网络,来应对不同的实际问题。
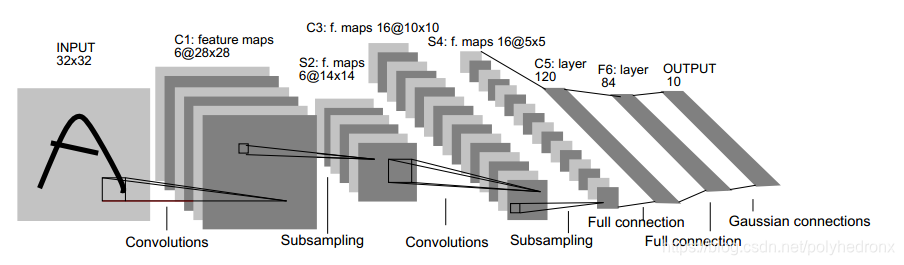
用于手写数字识别问题的卷积神经网络的设计
采用两个卷积层和一个全连接层构建一个简单的卷积神经网络。
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import matplotlib.pyplot as plt
# move warning
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
old_v = tf.logging.get_verbosity()
tf.logging.set_verbosity(tf.logging.ERROR)
mnist = input_data.read_data_sets('input_data/', one_hot=True)
# weight initialization
def weight_variable(shape):
return tf.Variable(tf.truncated_normal(shape, stddev=0.1))
# bias initialization
def bias_variable(shape):
return tf.Variable(tf.constant(0.1, shape=shape))
# convolution operation
def conv2d(x, W):
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding="SAME")
# pooling operation
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding="SAME")
# Convolutional Neural Network
def cnn2(x):
x_image = tf.reshape(x, [-1, 28, 28, 1])
# Layer 1: convolutional layer
W_conv1 = weight_variable([5, 5, 1, 32])
b_conv1 = bias_variable([32])
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)
h_pool1 = max_pool_2x2(h_conv1)
# Layer 2: convolutional layer
W_conv2 = weight_variable([5, 5, 32, 64])
b_conv2 = weight_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)
h_pool2 = max_pool_2x2(h_conv2)
# Layer 3: full connection layer
W_fc1 = weight_variable([7 * 7 * 64, 1024])
b_fc1 = bias_variable([1024])
h_pool2_flat = tf.reshape(h_pool2, [-1, 7 * 7 * 64])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
# dropout layer
keep_prob = tf.placeholder("float")
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
# output layer
W_fc2 = weight_variable([1024, 10])
b_fc2 = bias_variable([10])
y_conv = tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2)
return y_conv, keep_prob
# input layer
x = tf.placeholder("float", shape=[None, 784])
y_ = tf.placeholder("float", shape=[None, 10])
# cnn
y_conv, keep_prob = cnn2(x)
# loss function & optimization algorithm
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_*tf.log(y_conv), reduction_indices=[1]))
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
# new session
sess = tf.Session()
sess.run(tf.global_variables_initializer())
# train
losss = []
accurs = []
steps = []
correct_predict = tf.equal(tf.argmax(y_conv, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_predict, "float"))
for i in range(20000):
batch = mnist.train.next_batch(50)
sess.run(train_step, feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.5})
if i % 100 == 0:
loss = sess.run(cross_entropy, {x: batch[0], y_: batch[1], keep_prob: 1.0})
accur = sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels, keep_prob: 1.0})
steps.append(i)
losss.append(loss)
accurs.append(accur)
# plot loss
plt.figure()
plt.plot(steps, losss)
plt.xlabel('Number of steps')
plt.ylabel('Loss')
plt.figure()
plt.plot(steps, accurs)
plt.hlines(1, 0, max(steps), colors='r', linestyles='dashed')
plt.xlabel('Number of steps')
plt.ylabel('Accuracy')
plt.show()
print('Accuracy: ', sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels}))
tf.logging.set_verbosity(old_v)

我们可以通过添加归一化层优化我们的模型
Batch Normalization(批量归一化)实现了在神经网络层的中间进行预处理的操作,即在上一层的输入归一化处理后再进入网络的下一层,这样可有效地防止“梯度弥散”,加速网络训练。
Batch Normalization具体的算法如下图所示:

每次训练时,取 batch_size 大小的样本进行训练,在BN层中,将一个神经元看作一个特征,batch_size 个样本在某个特征维度会有 batch_size 个值,然后在每个神经元
x
i
x_i
xi 维度上的进行这些样本的均值和方差,通过公式得到
x
i
^
\hat{x_i}
xi^,再通过参数
γ
\gamma
γ和
β
\beta
β进行线性映射得到每个神经元对应的输出
y
i
y_i
yi 。在BN层中,可以看出每一个神经元维度上,都会有一个参数
γ
\gamma
γ和
β
\beta
β,它们同权重
ω
\omega
ω一样可以通过训练进行优化。
在卷积神经网络中进行批量归一化时,一般对 未进行ReLu激活的 feature map进行批量归一化,输出后再作为激励层的输入,可达到调整激励函数偏导的作用。
一种做法是将 feature map 中的神经元作为特征维度,参数 γ \gamma γ和 β \beta β的数量和则等于 2 × f m a p w i d t h × f m a p l e n g t h × f m a p n u m 2×fmap_{width}×fmap_{length}×fmap_{num} 2×fmapwidth×fmaplength×fmapnum,这样做的话参数的数量会变得很多;
另一种做法是把 一个 feature map 看做一个特征维度,一个 feature map 上的神经元共享这个 feature map的 参数 γ \gamma γ和 β \beta β,参数 γ \gamma γ和 β \beta β的数量和则等于 2 × f m a p n u m 2×fmap_{num} 2×fmapnum,计算均值和方差则在batch_size个训练样本在每一个feature map维度上的均值和方差。
注: f m a p n u m fmap_{num} fmapnum指的是一个样本的feature map数量,feature map 跟神经元一样也有一定的排列顺序。
Batch Normalization 算法的训练过程和测试过程的区别:
在训练过程中,我们每次都会将 batch_size 数目大小的训练样本 放入到CNN网络中进行训练,在BN层中自然可以得到计算输出所需要的均值和方差;
而在测试过程中,我们往往只会向CNN网络中输入一个测试样本,这是在BN层计算的均值和方差会均为 0,因为只有一个样本输入,因此BN层的输入也会出现很大的问题,从而导致CNN网络输出的错误。所以在测试过程中,我们需要借助训练集中所有样本在BN层归一化时每个维度上的均值和方差,当然为了计算方便,我们可以在 batch_num 次训练过程中,将每一次在BN层归一化时每个维度上的均值和方差进行相加,最后再进行求一次均值即可。
import tensorflow as tf
from sklearn.datasets import load_digits
import numpy as np
from sklearn.preprocessing import MinMaxScaler
from sklearn.preprocessing import OneHotEncoder
from sklearn.metrics import accuracy_score
digits = load_digits()
X_data = digits.data.astype(np.float32)
Y_data = digits.target.astype(np.float32).reshape(-1,1)
print (X_data.shape)
print (Y_data.shape)
scaler = MinMaxScaler()
X_data = scaler.fit_transform(X_data)
Y = OneHotEncoder().fit_transform(Y_data).todense() #one-hot编码
# 转换为图片的格式 (batch,height,width,channels)
X = X_data.reshape(-1,8,8,1)
batch_size = 8 # 使用MBGD算法,设定batch_size为8
def generatebatch(X,Y,n_examples, batch_size):
for batch_i in range(n_examples // batch_size):
start = batch_i*batch_size
end = start + batch_size
batch_xs = X[start:end]
batch_ys = Y[start:end]
yield batch_xs, batch_ys # 生成每一个batch
tf.reset_default_graph()
# 输入层
tf_X = tf.placeholder(tf.float32,[None,8,8,1])
tf_Y = tf.placeholder(tf.float32,[None,10])
# 卷积层+激活层
conv_filter_w1 = tf.Variable(tf.random_normal([3, 3, 1, 10]))
conv_filter_b1 = tf.Variable(tf.random_normal([10]))
relu_feature_maps1 = tf.nn.relu(\
tf.nn.conv2d(tf_X, conv_filter_w1,strides=[1, 1, 1, 1], padding='SAME') + conv_filter_b1)
# 池化层
max_pool1 = tf.nn.max_pool(relu_feature_maps1,ksize=[1,3,3,1],strides=[1,2,2,1],padding='SAME')
print (max_pool1)
# 卷积层
conv_filter_w2 = tf.Variable(tf.random_normal([3, 3, 10, 5]))
conv_filter_b2 = tf.Variable(tf.random_normal([5]))
conv_out2 = tf.nn.conv2d(relu_feature_maps1, conv_filter_w2,strides=[1, 2, 2, 1], padding='SAME') + conv_filter_b2
print(conv_out2)
# BN归一化层+激活层
batch_mean, batch_var = tf.nn.moments(conv_out2, [0, 1, 2], keep_dims=True)
shift = tf.Variable(tf.zeros([5]))
scale = tf.Variable(tf.ones([5]))
epsilon = 1e-3
BN_out = tf.nn.batch_normalization(conv_out2, batch_mean, batch_var, shift, scale, epsilon)
print(BN_out)
relu_BN_maps2 = tf.nn.relu(BN_out)
# 池化层
max_pool2 = tf.nn.max_pool(relu_BN_maps2,ksize=[1,3,3,1],strides=[1,2,2,1],padding='SAME')
print(max_pool2)
# 将特征图进行展开
max_pool2_flat = tf.reshape(max_pool2, [-1, 2*2*5])
# 全连接层
fc_w1 = tf.Variable(tf.random_normal([2*2*5,50]))
fc_b1 = tf.Variable(tf.random_normal([50]))
fc_out1 = tf.nn.relu(tf.matmul(max_pool2_flat, fc_w1) + fc_b1)
# 输出层
out_w1 = tf.Variable(tf.random_normal([50,10]))
out_b1 = tf.Variable(tf.random_normal([10]))
pred = tf.nn.softmax(tf.matmul(fc_out1,out_w1)+out_b1)
loss = -tf.reduce_mean(tf_Y*tf.log(tf.clip_by_value(pred,1e-11,1.0)))
train_step = tf.train.AdamOptimizer(1e-3).minimize(loss)
y_pred = tf.arg_max(pred,1)
bool_pred = tf.equal(tf.arg_max(tf_Y,1),y_pred)
accuracy = tf.reduce_mean(tf.cast(bool_pred,tf.float32)) # 准确率
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for epoch in range(1000): # 迭代1000个周期
for batch_xs,batch_ys in generatebatch(X,Y,Y.shape[0],batch_size): # 每个周期进行MBGD算法
sess.run(train_step,feed_dict={tf_X:batch_xs,tf_Y:batch_ys})
if(epoch%100==0):
res = sess.run(accuracy,feed_dict={tf_X:X,tf_Y:Y})
print (epoch,res)
res_ypred = y_pred.eval(feed_dict={tf_X:X,tf_Y:Y}).flatten() # 只能预测一批样本,不能预测一个样本
print (res_ypred)
print(accuracy_score(Y_data,res_ypred.reshape(-1,1)))
(1797, 64)
(1797, 1)
Tensor("MaxPool:0", shape=(?, 4, 4, 10), dtype=float32)
Tensor("add_1:0", shape=(?, 4, 4, 5), dtype=float32)
Tensor("batchnorm/add_1:0", shape=(?, 4, 4, 5), dtype=float32)
Tensor("MaxPool_1:0", shape=(?, 2, 2, 5), dtype=float32)
0 0.183083
100 0.979967
200 0.997774
300 0.997218
400 0.998331
500 0.998887
600 0.996105
700 0.997774
800 0.998331
900 0.996661
[0 1 2 ..., 8 9 8]
0.997217584864

















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









