






 遮罩纹理在商业游戏中用于精细控制模型表面的光照效果,如控制高光反射的强度和分布。通过采样遮罩纹理,可以决定哪些区域受特定光照属性影响,常用于混合不同材质纹理。示例Shader代码展示了如何在Unity中应用遮罩纹理来调整模型的镜面高光和粗糙度。
遮罩纹理在商业游戏中用于精细控制模型表面的光照效果,如控制高光反射的强度和分布。通过采样遮罩纹理,可以决定哪些区域受特定光照属性影响,常用于混合不同材质纹理。示例Shader代码展示了如何在Unity中应用遮罩纹理来调整模型的镜面高光和粗糙度。
1 遮罩纹理介绍
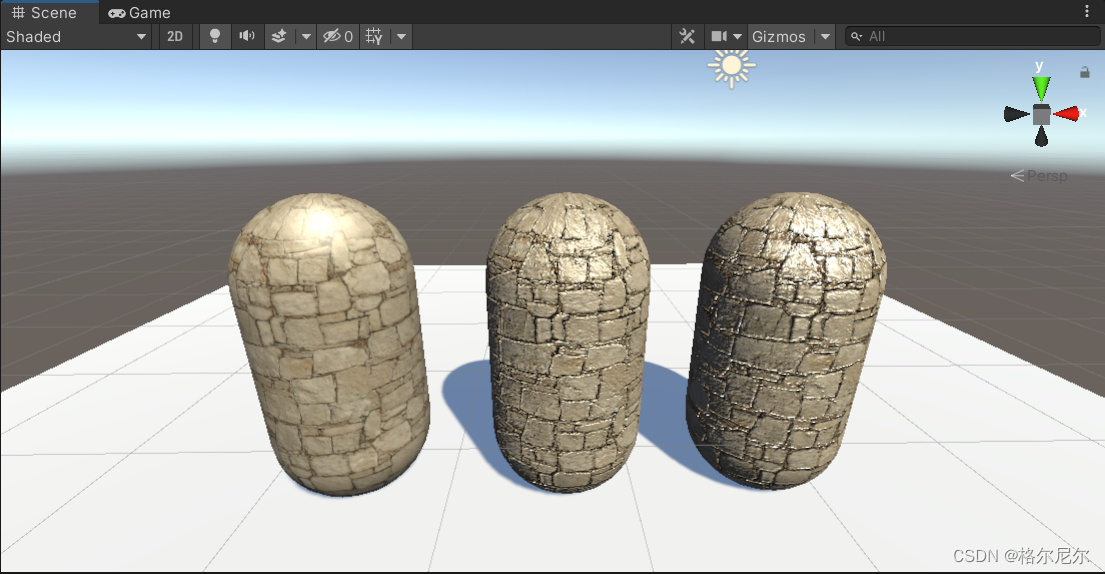
遮罩纹理(mask texture)在很多商业游戏中都可以见到它的身影。遮罩允许我们可以保护某些区域,使它们免于某些修改。例如,在之前的实现中,我们都是把高光反射应用到模型表面的所有地方,即所有的像素都使用同样大小的高光强度和高光指数。但有时,我们希望模型表面某些区域的反光强烈一些,而某些区域弱一些。为了得到更加细腻的效果,我们就可以使用一张遮罩纹理来控制光照。另一种常见的应用是在制作地形材质时需要混合多张图片,例如表现草地的纹理、表现石子的纹理、表现裸露土地的纹理等,使用遮置纹理可以控制如何混合这些纹理。
使用遮罩纹理的流程一般是:通过采样得到遮罩纹理的纹素值,然后使用其中某个(或某几个)通道的值(例如 texel)来与某种表面属性进行相乘,这样,当该通道的值为0时,可以保护表面不受该属性的影响。总而言之,使用遮罩纹理可以让美术人员更加精准(像素级别)地控制模型表面的各种性质。
2遮罩纹理介绍
Shader "MyShader/7-Mask Texture" {
Properties {
_Color ("Color Tint", Color) = (1, 1, 1, 1)
_MainTex ("Main Tex", 2D) = "white" {}
_BumpMap ("Normal Map", 2D) = "bump" {}
_BumpScale("Bump Scale", Float) = 1.0
_SpecularMask ("Specular Mask", 2D) = "white" {}
_SpecularScale ("Specular Scale", Float) = 1.0
_Specular ("Specular", Color) = (1, 1, 1, 1)
_Gloss ("Gloss", Range(8.0, 256)) = 20
}
SubShader {
Pass {
Tags { "LightMode"="ForwardBase" }
CGPROGRAM
#pragma vertex vert
#pragma fragment frag
#include "Lighting.cginc"
fixed4 _Color;
sampler2D _MainTex;
float4 _MainTex_ST;
sampler2D _BumpMap;
float _BumpScale;
sampler2D _SpecularMask;
float _SpecularScale;
fixed4 _Specular;
float _Gloss;
struct a2v {
float4 vertex : POSITION;
float3 normal : NORMAL;
float4 tangent : TANGENT;
float4 texcoord : TEXCOORD0;
};
struct v2f {
float4 pos : SV_POSITION;
float2 uv : TEXCOORD0;
float3 lightDir: TEXCOORD1;
float3 viewDir : TEXCOORD2;
};
v2f vert(a2v v) {
v2f o;
o.pos = UnityObjectToClipPos(v.vertex);
o.uv.xy = v.texcoord.xy * _MainTex_ST.xy + _MainTex_ST.zw;
//调用这个宏会得到一个矩阵rotation,该矩阵用来把模型空间下的方向转换为切线空间下rotation
TANGENT_SPACE_ROTATION;
o.lightDir = mul(rotation, ObjSpaceLightDir(v.vertex)).xyz;
o.viewDir = mul(rotation, ObjSpaceViewDir(v.vertex)).xyz;
return o;
}
//要把所有跟法线方向有关的运算,都放到切线空间下。因为从法线贴图中取得的法线方向是在切线空间下的。
fixed4 frag(v2f i) : SV_Target {
//切线空间下的光照方向归一化
fixed3 tangentLightDir = normalize(i.lightDir);
fixed3 tangentViewDir = normalize(i.viewDir);
//使用Unity内置的方法,从颜色值得到法线在切线空间的方向
fixed3 tangentNormal = UnpackNormal(tex2D(_BumpMap, i.uv));
tangentNormal.xy *= _BumpScale;
tangentNormal.z = sqrt(1.0 - saturate(dot(tangentNormal.xy, tangentNormal.xy)));
//纹理采样
fixed3 albedo = tex2D(_MainTex, i.uv).rgb * _Color.rgb;
//获取环境色
fixed3 ambient = UNITY_LIGHTMODEL_AMBIENT.xyz * albedo;
//计算漫反射色
fixed3 diffuse = _LightColor0.rgb * albedo * max(0, dot(tangentNormal, tangentLightDir));
fixed3 halfDir = normalize(tangentLightDir + tangentViewDir);
// 获取遮罩纹理采样
fixed specularMask = tex2D(_SpecularMask, i.uv).r * _SpecularScale;
// 计算有遮罩情况下的高光反射
fixed3 specular = _LightColor0.rgb * _Specular.rgb * pow(max(0, dot(tangentNormal, halfDir)), _Gloss) * specularMask;
return fixed4(ambient + diffuse + specular, 1.0);
}
ENDCG
}
}
FallBack "Specular"
}

















 742
742

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









