







SplatAD: Real-Time Lidar and Camera Rendering with 3D Gaussian Splatting for Autonomous Driving
原文链接:https://arxiv.org/pdf/2411.16816
简介:自动驾驶需要大量的测试,其中仿真是关键的部分。神经渲染方法可以数据驱动的形式建立仿真环境,但NeRF渲染速度太慢,而3D高斯溅射(3DGS)则只能渲染图像数据。本文提出SplatAD,第一个基于3DGS的动态场景渲染方法,可实时渲染真实的图像和激光雷达数据。SplatAD建模了卷帘快门效应、激光雷达的强度和射线丢弃。
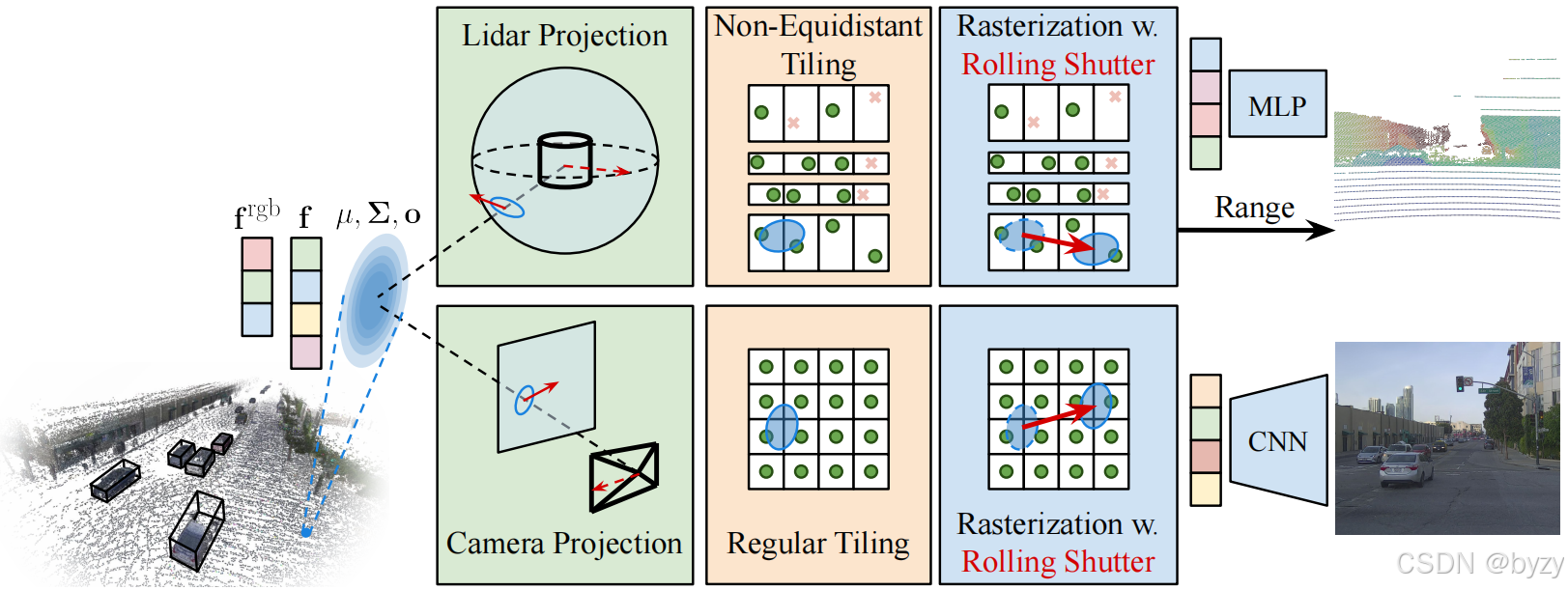
1. 场景表达
本文方法的场景由半透明3D高斯表达,每个高斯包含可学习的占用 o ∈ ( 0 , 1 ) o\in(0,1) o∈(0,1),均值 μ ∈ R 3 \mu\in\mathbb R^3 μ∈R3和协方差矩阵 Σ ∈ R 3 × 3 \Sigma\in\mathbb R^{3\times3} Σ∈R3×3(由尺度 S ∈ R 3 S\in\mathbb R^3 S∈R3和四元数 q ∈ R 4 q\in\mathbb R^4 q∈R4表示)参数。使用可学习的基础颜色 f r g b ∈ R 3 f^{rgb}\in\mathbb R^3 frgb∈R3和特征向量 f ∈ R D f f\in\mathbb R^{D_f} f∈RDf替代原本的球面谐波,其中 f f f编码了视图相关的效应和激光雷达属性。此外,还包含了各传感器可学习的嵌入,以建模特定的外观特征。
为处理动态,使用场景图分解,将场景分为静态背景和动态参与者集合。每个动态参与者由3D边界框和SE(3)姿态序列描述(可由现成的目标检测器和跟踪器,或是标注得到)。每个高斯有不可学习的ID,指示其属于静态或某个动态参与者。对属于动态参与者的高斯,其均值和协方差是在其局部坐标系(即与边界框对齐的坐标系)下定义的。对特定时刻 t t t下的场景,先将边界框高斯基于参与者的姿态,变换到世界坐标系下,并使用可学习的偏移量调整以减小姿态不准确带来的影响。每个参与者还有从姿态差异初始化的速度和可学习的速度偏移量。
2. 相机渲染
给定已知姿态的相机,使用3DGS的基于区块(tile)的渲染方法渲染 t t t时刻的图像 I I I,但作出了一些调整以适应本文方法。
投影,划分和排序。给定世界坐标系下的均值 μ C \mu^C μC和协方差 Σ C \Sigma^C ΣC,首先将均值透视投影到图像上得到 μ I ∈ R 2 \mu^I\in\mathbb R^2 μI∈R2,然后使用投影矩阵的雅可比矩阵前两行得到变换后的协方差 Σ I = J I Σ C ( J I ) T ∈ R 2 × 2 \Sigma^I=J^I\Sigma^C(J^I)^T\in\mathbb R^{2\times2} ΣI=JIΣC(JI)T∈R2×2。剔除位于视锥外的高斯后,将图像划分为 16 × 16 16\times16 16×16的区块,并将高斯分配给所有相交的区块。这样,在栅格化时,每个像素仅需处理一部分高斯。最后,基于均值 μ C \mu^C μC的 z z z深度排序高斯。
卷帘快门。许多相机使用卷帘快门,即逐行捕捉图像,使得曝光过程中可能存在相机运动。本文将高斯相对相机的速度投影到图像空间,根据像素的捕捉时间调整均值
μ
I
\mu^I
μI。

对每个高斯,其像素速度近似如下:
v
I
=
J
I
(
−
ω
C
×
μ
C
−
v
C
+
v
d
y
n
)
∈
R
2
v^I=J^I(-\omega_C\times\mu^C-v_C+v_{dyn})\in\mathbb R^2
vI=JI(−ωC×μC−vC+vdyn)∈R2
其中
ω
C
\omega_C
ωC和
v
C
v_C
vC为相机坐标系下相机的角速度和线速度(负号表示高斯相对相机的运动),且
v
d
y
n
=
T
a
c
t
→
C
(
ω
a
c
t
×
μ
a
c
t
+
v
a
c
t
)
∈
R
3
v_{dyn}=T^{act\rightarrow C}(\omega_{act}\times\mu^{act}+v_{act})\in\mathbb R^3
vdyn=Tact→C(ωact×μact+vact)∈R3
为动态物体高斯的速度, ω a c t \omega_{act} ωact和 v a c t v_{act} vact在参与者坐标系下表达, μ a c t \mu^{act} μact为参与者坐标系下的高斯均值。 T a c t → C T^{act\rightarrow C} Tact→C为参与者坐标系到相机坐标系的变换。对于静态高斯, v d y n = 0 v_{dyn}=0 vdyn=0。
删除高斯时,也考虑了卷帘快门,并在考虑高斯和图像区块相交时增加高斯的近似范围。3DGS使用包含99%置信度的、正方形的、轴对齐的边界框(AABB) 近似高斯;本文使用长方形的AABB,包含 Σ I \Sigma^I ΣI的三个标准差并添加 ∣ v I ∣ ⋅ t r s / 2 |v_I|\cdot t_{rs}/2 ∣vI∣⋅trs/2。 t r s t_{rs} trs表示卷帘快门时间,即最后一行与第一行像素的捕捉时间之差。该式假设传感器时间戳为曝光的中间时刻,故本文还引入时间偏移量指示可能存在的时间偏差。使用长方形AABB减少了不必要的相交,如窄高斯和速度与轴对齐的高斯。
栅格化。3DGS通过为每个区块加载一个线程块、为每个像素分配一个线程来实现并行栅格化。对每个像素,其坐标
p
=
[
p
u
,
p
v
]
T
p=[p_u,p_v]^T
p=[pu,pv]T通过块和线程索引得到。像素与图像中间行的捕捉时间差为
t
p
i
x
=
(
p
v
/
H
−
0.5
)
⋅
t
r
s
t_{pix}=(p_v/H-0.5)\cdot t_{rs}
tpix=(pv/H−0.5)⋅trs
对按深度排序的、与本区块相交的高斯,取其RGB值
f
i
r
g
b
f_i^{rgb}
firgb和特征
f
i
f_i
fi进行
α
\alpha
α混合:
[
F
p
r
g
b
,
F
p
]
=
∑
i
[
f
i
r
g
b
,
f
i
]
α
i
∏
j
=
1
i
−
1
(
1
−
α
j
)
[F_p^{rgb},F_p]=\sum_i[f_i^{rgb},f_i]\alpha_i\prod_{j=1}^{i-1}(1-\alpha_j)
[Fprgb,Fp]=i∑[firgb,fi]αij=1∏i−1(1−αj)
其中
α
i
=
∣
Σ
i
I
∣
∣
Σ
i
I
+
s
I
∣
o
i
exp
(
−
1
2
Δ
i
T
(
Σ
i
I
+
s
I
)
−
1
Δ
i
)
Δ
i
=
p
−
(
μ
i
I
+
v
i
I
t
p
i
x
)
\alpha_i=\sqrt{\frac{|\Sigma_i^I|}{|\Sigma_i^I+sI|}}o_i\exp(-\frac12\Delta_i^T(\Sigma_i^I+sI)^{-1}\Delta_i)\\ \Delta_i=p-(\mu_i^I+v_i^It_{pix})
αi=∣ΣiI+sI∣∣ΣiI∣oiexp(−21ΔiT(ΣiI+sI)−1Δi)Δi=p−(μiI+viItpix)
使用卷帘快门补偿的均值,计算像素和高斯的距离 Δ i \Delta_i Δi。注意此处为3DGS+EWA的渲染,其中 s = 0.3 s=0.3 s=0.3。
视图相关的效应被小型CNN建模。给定特征图
F
∈
R
H
×
W
×
D
f
F\in\mathbb R^{H\times W\times D_f}
F∈RH×W×Df、相应的射线方向
d
∈
R
H
×
W
×
3
d\in\mathbb R^{H\times W\times 3}
d∈RH×W×3和相机的可学习嵌入
e
e
e,预测逐像素的仿射映射
M
∈
R
H
×
W
×
3
M\in\mathbb R^{H\times W\times 3}
M∈RH×W×3和
b
∈
R
H
×
W
×
3
b\in\mathbb R^{H\times W\times 3}
b∈RH×W×3,并应用于
F
r
g
b
F^{rgb}
Frgb:
M
,
b
=
C
N
N
(
F
,
d
,
e
)
I
=
M
⊙
F
r
g
b
+
b
M,b=CNN(F,d,e)\\ I=M\odot F^{rgb}+b
M,b=CNN(F,d,e)I=M⊙Frgb+b
使用CNN比MLP更利于进行纹理建模,相机嵌入可建模曝光差异。
3. 激光雷达渲染
投影。给定已知姿态的激光雷达和
t
t
t时刻的高斯,首先将高斯转换到激光雷达坐标系下,得到
μ
L
=
[
x
,
y
,
z
]
T
\mu^L=[x,y,z]^T
μL=[x,y,z]T和
Σ
L
\Sigma^L
ΣL。原始激光雷达数据通常表达在球坐标下,包含水平角
ϕ
\phi
ϕ,俯仰角
ω
\omega
ω和距离
r
r
r。因此,将高斯均值转换到球坐标系下:
μ
S
=
[
ϕ
ω
r
]
=
[
arctan
2
(
y
,
x
)
arcsin
(
z
/
r
)
x
2
+
y
2
+
z
2
]
\mu^S=\begin{bmatrix}\phi\\\omega\\r\end{bmatrix}=\begin{bmatrix}\arctan2(y,x)\\\arcsin(z/r)\\\sqrt{x^2+y^2+z^2}\end{bmatrix}
μS=
ϕωr
=
arctan2(y,x)arcsin(z/r)x2+y2+z2
并将协方差根据上式的雅可比矩阵转化到球坐标系下:
Σ
S
=
J
S
Σ
L
(
J
S
)
T
\Sigma^S=J^S\Sigma^L(J^S)^T
ΣS=JSΣL(JS)T。其中
J
S
=
[
−
y
x
2
+
y
2
x
x
2
+
y
2
0
−
x
z
r
2
x
2
+
y
2
−
y
z
r
2
x
2
+
y
2
x
2
+
y
2
r
2
x
r
y
r
z
r
]
J^S=\begin{bmatrix}-\frac y{x^2+y^2}&\frac x{x^2+y^2}&0\\ -\frac{xz}{r^2\sqrt{x^2+y^2}}&-\frac{yz}{r^2\sqrt{x^2+y^2}}&\frac{\sqrt{x^2+y^2}}{r^2}\\ \frac xr&\frac yr&\frac zr\end{bmatrix}
JS=
−x2+y2y−r2x2+y2xzrxx2+y2x−r2x2+y2yzry0r2x2+y2rz
和相机一样,考虑卷帘快门效应:
v
S
=
J
S
(
−
ω
L
×
μ
L
−
v
L
+
v
d
y
n
)
∈
R
3
v^S=J^S(-\omega_L\times\mu^L-v_L+v_{dyn})\in\mathbb R^3
vS=JS(−ωL×μL−vL+vdyn)∈R3
注意与图像的 v I v^I vI不同, v S v^S vS为三维的,因为需要精确的距离栅格化。使用 v S t r s / 2 v^St_{rs}/2 vStrs/2的前两维来扩展高斯的长方形AABB,并删除激光雷达视野外的高斯。
划分和渲染。通常激光雷达有固定的水平角分辨率,但二极管之间的非等距分布使得在感兴趣区的俯仰角分辨率更高。本文在水平方向上使用固定的角度分辨率,而在垂直方向上按照固定的二极管数量划分(保证每个区块包含相同的激光雷达点数)。分配高斯后,基于均值 μ S \mu^S μS的距离排序。
栅格化。每个区块加载一个线程块,每个线程负责栅格化得到一个激光雷达点。每个线程有水平角、俯仰角、以及捕获时间的信息,这是由于点不可能完美地沿扫描线分布(不能通过块和线程的索引来确定坐标,只能使用激光雷达参数或根据已有的点云计算得到),且水平角和俯仰角不能决定相对激光雷达扫描中心的时间偏移量。
对每个激光雷达点,对高斯的特征 f i f_i fi进行 α \alpha α混合(公式类似图像的渲染)。渲染的特征会和射线方向拼接,并通过小型MLP解码得到强度和射线丢弃概率。
为得到期望的距离,对卷帘快门修正的高斯距离
r
i
,
r
s
r_{i,rs}
ri,rs进行
α
\alpha
α混合,其中
r
i
,
r
s
=
r
i
+
v
r
S
t
l
r_{i,rs}=r_i+v_r^St_l
ri,rs=ri+vrStl
其中 v r S v_r^S vrS为相对激光雷达速度的距离分量, t l t_l tl为当前捕捉时刻和激光雷达扫描的中间时刻之差。渲染的距离为第一个满足 ∏ j = 1 i − 1 ( 1 − α j ) < 0.5 \prod_{j=1}^{i-1}(1-\alpha_j)<0.5 ∏j=1i−1(1−αj)<0.5的高斯(卷帘快门修正后的)中值距离。注意在训练时使用期望距离,而推断时使用中值距离。
4. 优化和实施
总损失如下:
L
=
λ
r
L
1
+
(
1
−
λ
r
)
L
S
S
I
M
+
λ
d
e
p
t
h
L
d
e
p
t
h
+
λ
l
o
s
L
l
o
s
+
λ
i
n
t
e
n
s
L
i
n
t
e
n
+
λ
r
a
y
d
r
o
p
L
B
C
E
+
λ
M
C
M
C
L
M
C
M
C
L=\lambda_rL_1+(1-\lambda_r)L_{SSIM}+\lambda_{depth}L_{depth}+\lambda_{los}L_{los}+\lambda_{intens}L_{inten}+\lambda_{raydrop}L_{BCE}+\lambda_{MCMC}L_{MCMC}
L=λrL1+(1−λr)LSSIM+λdepthLdepth+λlosLlos+λintensLinten+λraydropLBCE+λMCMCLMCMC
其中L1和SSIM损失为图像的渲染损失, L d e p t h L_{depth} Ldepth和 L i n t e n L_{inten} Linten为激光雷达距离和强度的L2损失。 L l o s L_{los} Llos为视线损失,惩罚激光雷达距离内的不透明度。BCE损失为激光雷达射线丢弃概率的二元交叉熵, L M C M C L_{MCMC} LMCMC为不透明度和尺度正则化损失。
(1)与激光雷达点 p p p相交的高斯的视线损失为: L l o s , p = ∑ r i < r p − ϵ α i L_{los,p}=\sum_{r_i<r_p-\epsilon}\alpha_i Llos,p=ri<rp−ϵ∑αi
其中 r i r_i ri为高斯的距离, r p r_p rp为点的距离, ϵ = 0.8 \epsilon=0.8 ϵ=0.8。
(2)MCMC损失为
λ M C M C L M C M C = λ o ∑ i ∣ o i ∣ + λ Σ ∑ i , j ∣ e i g j ( Σ i ) ∣ \lambda_{MCMC}L_{MCMC}=\lambda_o\sum_i|o_i|+\lambda_\Sigma\sum_{i,j}|\sqrt{eig_j(\Sigma_i)}| λMCMCLMCMC=λoi∑∣oi∣+λΣi,j∑∣eigj(Σi)∣
使用激光雷达点和随机点共同初始化高斯。边界框内的激光雷达点被分配到相应的参与者。所有激光雷达点被投影到最近的图像上设置初始颜色。随机点被包括激光雷达距离内的均匀采样点和激光雷达距离外的线性采样点(颜色均随机初始化)。使用MCMC策略而非3DGS的分裂和密集化策略,因其有更好的远场渲染质量和可预测的计算需求。


















 1856
1856

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











