






 本文详细介绍了机器学习中数据集的划分方法,包括留出法、交叉验证法、自助法和窗口划分法,以及它们各自适用的情况和优缺点。强调了训练集、验证集和测试集在模型调参和评估中的角色,指出在模型选择和参数调整过程中,正确使用这些方法能有效提升模型的泛化能力。
本文详细介绍了机器学习中数据集的划分方法,包括留出法、交叉验证法、自助法和窗口划分法,以及它们各自适用的情况和优缺点。强调了训练集、验证集和测试集在模型调参和评估中的角色,指出在模型选择和参数调整过程中,正确使用这些方法能有效提升模型的泛化能力。
机器学习的目的是得到一个具有预测能力的模型,预测能力来源于数据,直观上理解有了数据就可以进行训练了,然而实际上并非如此。我们要做的事情并不只有训练而已。
1.需要足够的数据进行训练
2.能够用用数据测试的方法评估模型的泛化能力(预测能力)
3.能够通过对比的方法调整模型的超参数(需要人为指定,训练过程中不改变的参数)
实际的机器学习会有几个客观限制:
1.数据有限:虽然对于一个问题,样本空间很大,然而客观上能够获得的数据就只有样本空间中的一部分,在实际的训练过程中,我们只能按照数据集的特点一定程度上认为数据集能够代表样本空间。
2.互斥原则:用于测试的数据尽量不出现在训练数据集中。用于训练的数据集无法反映模型的泛化能力,理解起来也很容易,模型来自于训练数据集,用自己来评判自己,当然就失去了对泛化能力的评估作用。
一、留出法hold-out(划分数据集与训练集)
1.定义:
有了互斥原则,很容易想到留出法,即:直接将数据集划分成两个互斥的集合,其中一个集合作为训练集,另一个作为数据集。常见做法是训练集占60%-80%
2.抽样方法:
其中,训练和测试集划分要尽可能保持数据集分布的一致性,避免因数据集划分过程引入额外偏差。常用方法为分层抽样,也可采用其他抽样方法,作用是让训练集和测试集的划分后分布接近数据集。
3.使用:
在实际使用的时候,有时候即便是使用分层抽样等方法,留一法单次使用的估计结果往往不够可靠,一般要采用若干次随机划分、重复进行试验评估后取平均值作为留出法的评估结果。在数据量比较大,样本分布比较均匀的情况下效果较好。
二、交叉验证法cross-validation(最为常用)
1.定义:
将原始数据集通过分层抽样划分为k个大小一致的互斥子集。然后,每次利用k-1各子集合的并集作为训练集,剩下的那个做测试集。这样就可以得到k个训练集/测试集的组合,从而可以进行k次训练和测试,最终返回的结果为k次测试结果的均值。

2.具体步骤:
1. 随机将训练数据等分成k份,S1, S2, …, Sk。
2. 对于每一个模型Mi,算法执行k次,每次选择一个Sj作为验证集,而其它作为训练集来训练模型Mi,把训练得到的模型在Sj上进行测试,这样一来,每次都会得到一个误差E,最后对k次得到的误差求平均,就可以得到模型Mi的泛化误差。
3. 算法选择具有最小泛化误差的模型作为最终模型,并且在整个训练集上再次训练该模型,从而得到最终的模型。
3.K值:
为了减小因样本划分不同而引入的差别,k折交叉验证通常要随机使用不同的划分重复p次,最终结果返回p次随机划分数据集k折交叉验证结果的均值。例如常见的有10次10折交叉验证。但无论如何随机地划分都会产生一定程度的由于数据划分产生的偏差。
通常建议K=10.,也可以 ![]() 且保证
且保证 ![]()
4.留一法:
对于交叉验证,存在一种方法叫留一法,也就是K=N,也就不需要多次随机划分,可以完全消除划分产生的偏差。但缺点在于模型训练困难。
三、自助法
留出法和交叉验证法由于划分出一部分未参与训练,会由于样本规模的缩小产生估计误差。(留一法可以同时解决样本划分和样本规模产生的误差,但计算复杂度过高)。在样本规模很小的情况下,样本规模误差较大的时候,适合用自助法
1.定义:
原始数据集包含m个样本,则有放回的抽样m次,组成一个包含m个样本的训练集D`,一个样本经过m次抽样任然没有被抽取到的概率为(1-1/m)**m=0.368,我们将D`作为训练集D-D`作为测试集,这样我们训练集和原始数据集一样有m个样本,同时测试集约有1/3的样本是训练集中没有出现过的。
2.作用:
自助法在数据集较小、难以有效划分训练集/测试集时很有效;自助法能产生多个不同的训练集这对集成学习算法很有帮助;自助法改变了原始数据集的分布,因此在数据量足够的情况下,我们一般采用留出法和交叉验证法。
四、窗口划分法
在实际问题中,我们的做法一般是用一部分数据取预测另一部分数据,在两部分数据有着特定的逻辑关系的时候,窗口划分法就很有用。比如根据历史数据去预测未来某段时间发生的事情;将用户的历史数据按照时间窗口划分,例如选取4月到5月的数据为训练集,5月到6月的数据为测试集。
或者用一组原始数据做数据集。用另一组独立数据做训练集
五、调参与最终模型
1.调参与模型评估
参数调整与模型评估本身是相互独立的关系,调参是找到存在超参数模型的最优参数,模型评估是评价模型的训练结果的方法。之所以两者容易弄混,是因为实际操作的过程中,会经历多次调参和模型评估,这个过程和模型评估方法会有些相似,所以有时会把整个训练过程混淆为模型评估方法。
2.训练集、测试集和验证集
训练集(train set):用于模型拟合的数据样本。
验证集(development set):是模型训练过程中单独留出的样本集,它可以用于调整模型的超参数和用于对模型的能力进行初步评估。 通常用来在模型迭代训练时,用以验证当前模型泛化能力(准确率,召回率等),以决定是否停止继续训练。
在神经网络中, 我们用验证数据集去寻找最优的网络深度(number of hidden layers),或者决定反向传播算法的停止点或者在神经网络中选择隐藏层神经元的数量;
在普通的机器学习中常用的交叉验证(Cross Validation) 就是把训练数据集本身再细分成不同的验证数据集去训练模型。
测试集:用来评估模最终模型的泛化能力。但不能作为调参、选择特征等算法相关的选择的依据。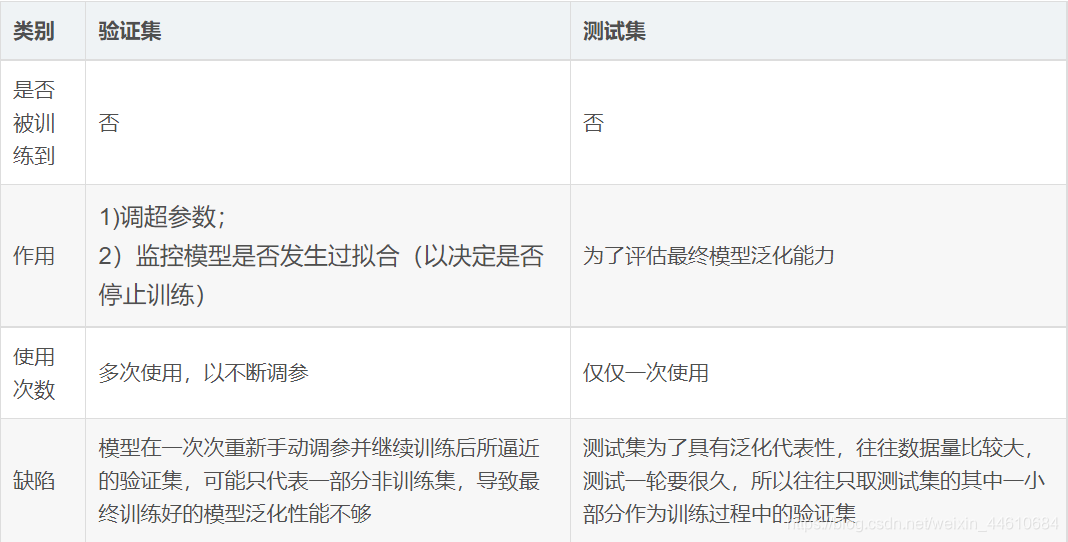
大致的关系如下图:
 3.调参步骤
3.调参步骤
首先划划分原始训练集和测试集,原始训练集用于调参和训练最终模型,测试集仅用于最终评估
第二步划分原始训练集为训练集和验证集,在这个过程中往往会用某种模型评估方法划分并按照一定步长遍历评估每个参数,选择最优的参数。如果步长过大,则可以进一步缩小范围和步长进一步选择参数
第三步即为训练最终模型,重新用原始训练集训练模型,并用测试集测试最终模型的训练结果。

















 5565
5565

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









