







 本文介绍了线性判别分析(LDA)和主成分分析(PCA)的区别与应用场景。LDA是一种有监督的降维方法,用于分类任务,通过最大化类间距离和最小化类内距离来寻找最佳投影。PCA则是无监督降维,通过最大化样本方差来提取主要成分。在Python中,可以使用sklearn库实现LDA和PCA,代码示例展示了如何对Iris数据集和数字数据进行降维和可视化。
本文介绍了线性判别分析(LDA)和主成分分析(PCA)的区别与应用场景。LDA是一种有监督的降维方法,用于分类任务,通过最大化类间距离和最小化类内距离来寻找最佳投影。PCA则是无监督降维,通过最大化样本方差来提取主要成分。在Python中,可以使用sklearn库实现LDA和PCA,代码示例展示了如何对Iris数据集和数字数据进行降维和可视化。
机器学习—线性判别分析和主成分分析
1.通俗解释:
线性判别分析(Linear Discriminant Analysisi,LDA)与主成分分析(Principle Component Analysis,PCA)都是线性降维(Dimension Reduction)的算法,区别在于LDA是有监督的降维,而PCA是无监督的降维。LDA旨在寻找一个有标签的训练数据集上的最佳投影,是这个投影中同类的数据点较为集中,而不同类的数据点之间尽量分散,从而实现对新样本的判别。
PCA则是对于一个无标签的高维的训练样本集,找到若干最具有代表性的分量,选择的原则上是在该分量上样本集的方差最大,从而可以用这些低维分量来代表训练数据集中的样本数据。进行后续的分类等操作。
2.任务类型:
由上面的解释可知,LDA只能用于有监督任务,因为LDA的过程需要用类别标注作为指导,其目的在于降低数据维度,找到更能反映类别特异性的低维向量代替原始数据,从而避免由于维数灾难导致的过拟合,以及降低计算量。LDA可以直接给出低维空间的判别函数。对于新样本可以直接进行类别的判断。
PCA的应用场景较广,因为其不需要预先的标签,所以一般被作为一种数据预处理的手段来使用,经过PCA 后的数据只保留了重要的成分,从而使模型可以在训练的过程中更好的利用主要特征提高算法的鲁棒性。
3.代码实现
LDA:根据带有类别标注的训练数据将原始高维数据根据类内距离,类间距离的原则投影到一维,并进行判别的算法
PCA:是利用矩阵的特征分解,实现主成分的确定与选择,从而实现无监督的降维操作。
PCA:
***LDA ***
from sklearn.datasets import load_iris
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
import matplotlib.pyplot as plt
import numpy as np
#加载数据集,并挑选两类用于实验(一共三类)
iris=load_iris()
#得到数据与类别标签
iris_data=iris.data
iris_target=iris.target
select_ids=np.where(iris_target>0)[0]
X=iris_data[select_ids,:]
y=iris_target[select_ids]
#建立LDA 模型,参数n_components表示投影后的维度,和类别数有关
lda=LinearDiscriminantAnalysis(n_components=1)
lda.fit(X,y)
print(lda)
low_dim_data=lda.transform(X)
plt.scatter(low_dim_data,y)
plt.show()
PCA
from sklearn.datasets import load_digits
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
import numpy as np
#加载数据集,并取出数字3,4,8的样本
digits_dataset=load_digits()
digits=digits_dataset.data
labels=digits_dataset.target
digit_3=digits[labels==3]
digit_4=digits[labels==4]
digit_8=digits[labels==8]
#拼接成数据
X=np.concatenate((digit_3,digit_4,digit_8),axis=0)
#建立PCA模型,参数n_components为最大主成分的个数,取值为1到原始维度-1
model=PCA(n_components=2)
#模型训练,注意:PCA不需要训练标签
model.fit(X)
print(model)
pca_3=model.transform(digit_3)
pca_4=model.transform(digit_4)
pca_8=model.transform(digit_8)
plt.plot(pca_3[:,0],pca_3[:,1],'b.')
plt.plot(pca_4[:,0],pca_4[:,1],'ro')
plt.plot(pca_8[:,0],pca_8[:,1],'k*')
plt.legend(["3","4","8"])
plt.show()
4.实验结果
LDA实验结果
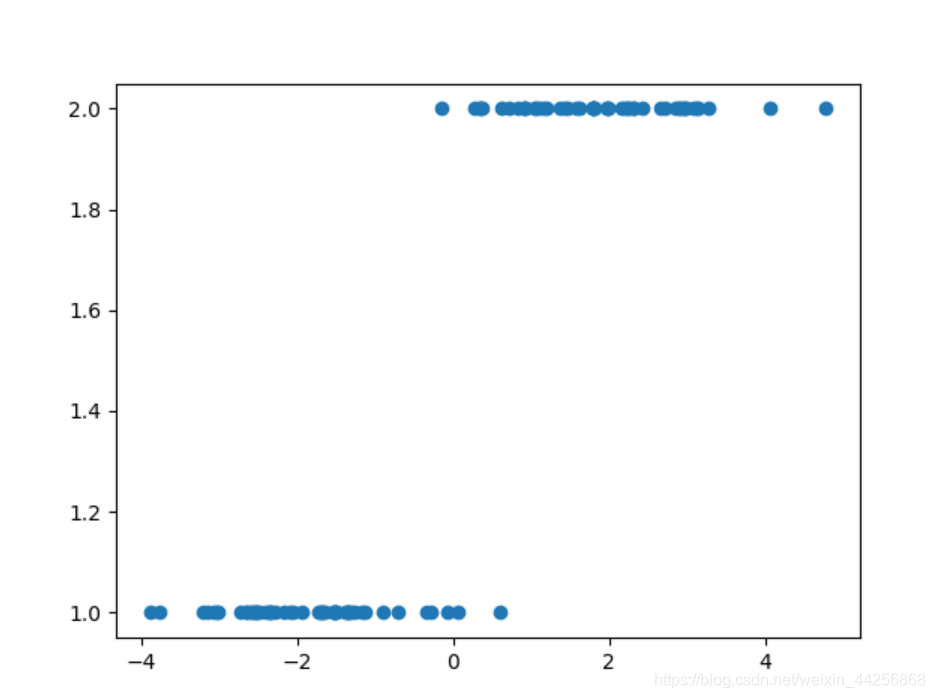
PCA 实验结果
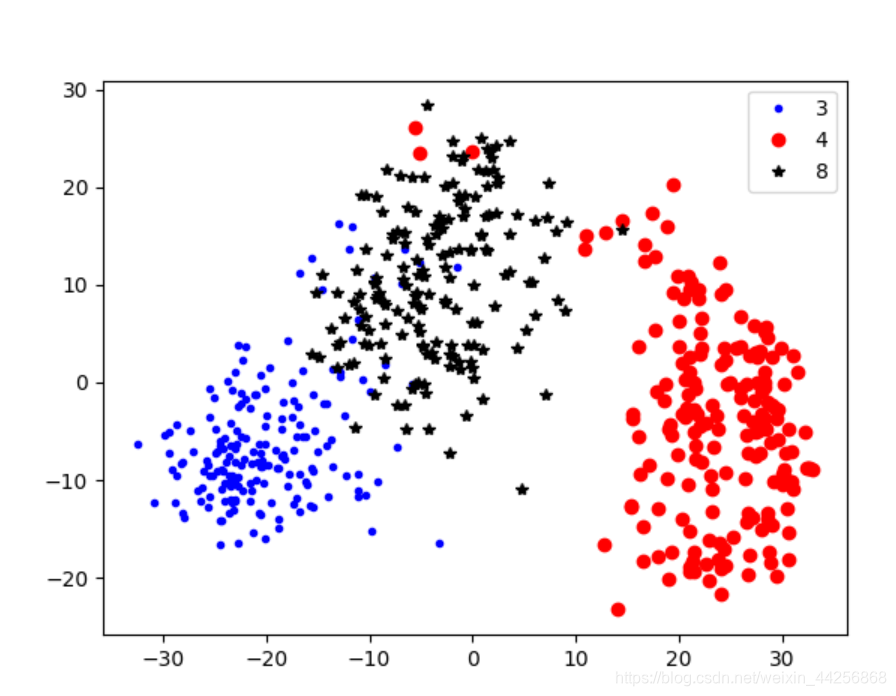


















 19
19

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









