







机器学习-----物理类聚 聚类算法
1.通俗解释:
聚类算法是一种经典的无监督学习算法,用来将无标记样本聚集成不同的集合(这样的集合一般称为簇),使同一个簇内的样本尽量相似。聚类算法通过不断的迭代计算当前划分下得到的各簇内的相似性,并以此对每个样本点的归属进行更新,最终得到一个稳定的结果。要注意的是聚类是一类算法的总称。本次主要介绍经典的K-means聚类和层次聚类(Hierarchical Clustering)
2.任务类型:
由于是无监督学习方法,因此聚类可以被应用于本身无标记数据,但是需要对其进行某种归类的任务。例如,在新闻文本的推送过程中,我们希望尽量将相似内容的文本放在一起,那么就可以应用聚类的方法对所有数据进行聚类,同一簇的文本都具有相似的特征,可以看作同一类。在例如应用经典的MNIST数据集来做聚类,这些样本会分成10个簇,没一簇内的样本表示同样的数字。可以看出,在这种问题中,我们不需要知道具体某一类别究竟是什么(是娱乐新闻还是体育新闻?是数字0,还是数字8? )而只是将同一类别聚集起来即可。
3.代码实现
#导入用到的python模块
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans,DBSCAN
import matplotlib.pyplot as plt
import numpy as np
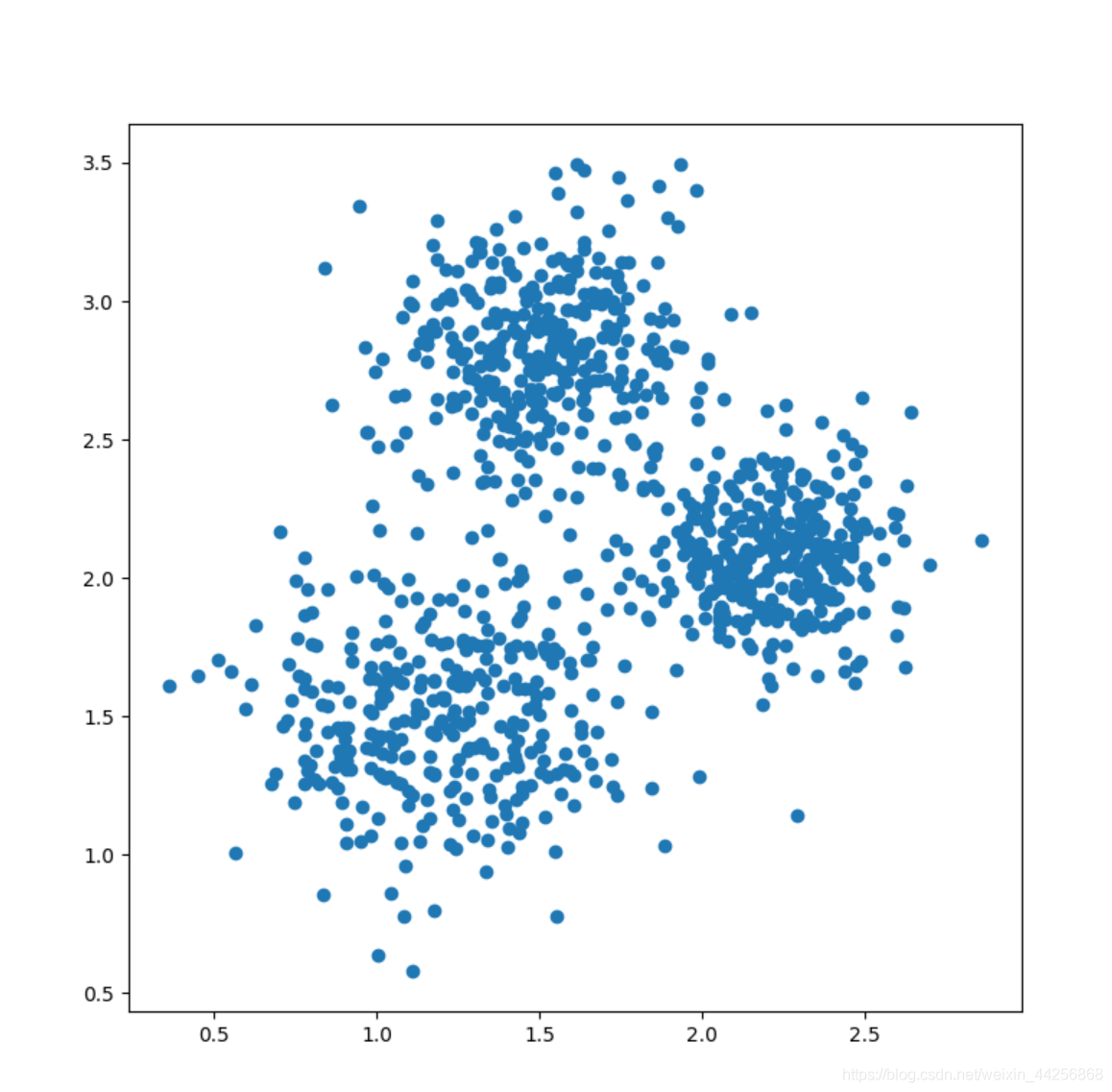
#利用生成器生成具有三个簇的合成数据集,共1000个样本点
#簇中心和标准如下所示,为方便作图,特征维度选择二维,返回值X为数据,t为各样本点所属的真实簇编号形成的向量
X,t=make_blobs(n_samples=1000,n_features=2,centers=[[1.2,1.5],[2.2,2.1],[1.5,2.8]],
cluster_std=[[0.3],[0.2],[0.25]],random_state=2021)
print(X)
#作图显示生成的样本点的分布
fig=plt.figure(figsize=(8,8))
ax=fig.add_subplot(111)
ax.scatter(X[:,0],X[:,1])
fig.show()
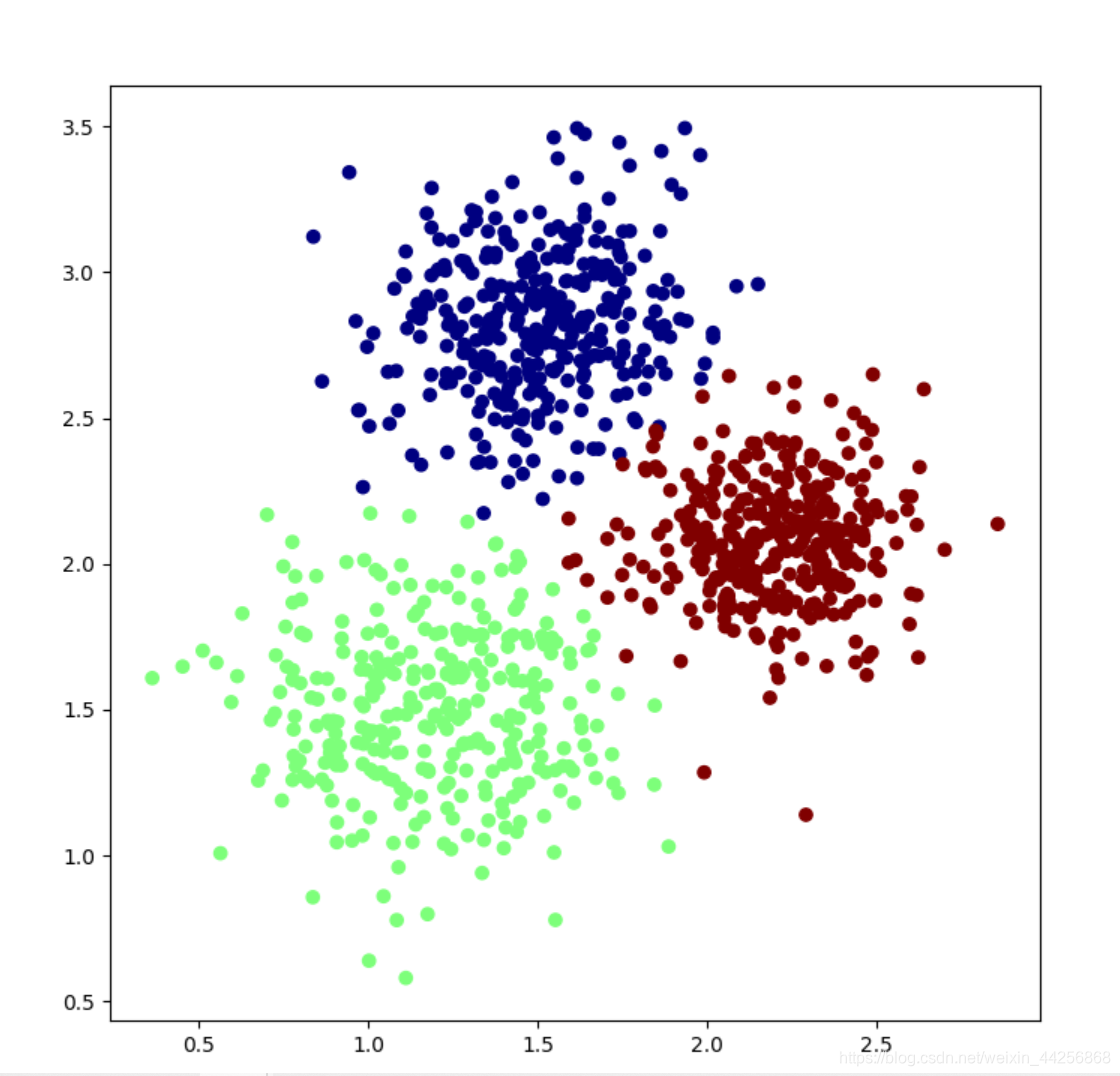
#选择k为3的K-means聚类,并绘制最终聚类结果
kmeans_model=KMeans(n_clusters=3,random_state=2021)
kmeans_model.fit(X)
y_kmeans=kmeans_model.predict(X)
p=plt.figure(figsize=(8,8))
ax=p.add_subplot(111)
ax.scatter(X[:,0],X[:,1],c=y_kmeans,cmap=plt.cm.jet)
p.show()
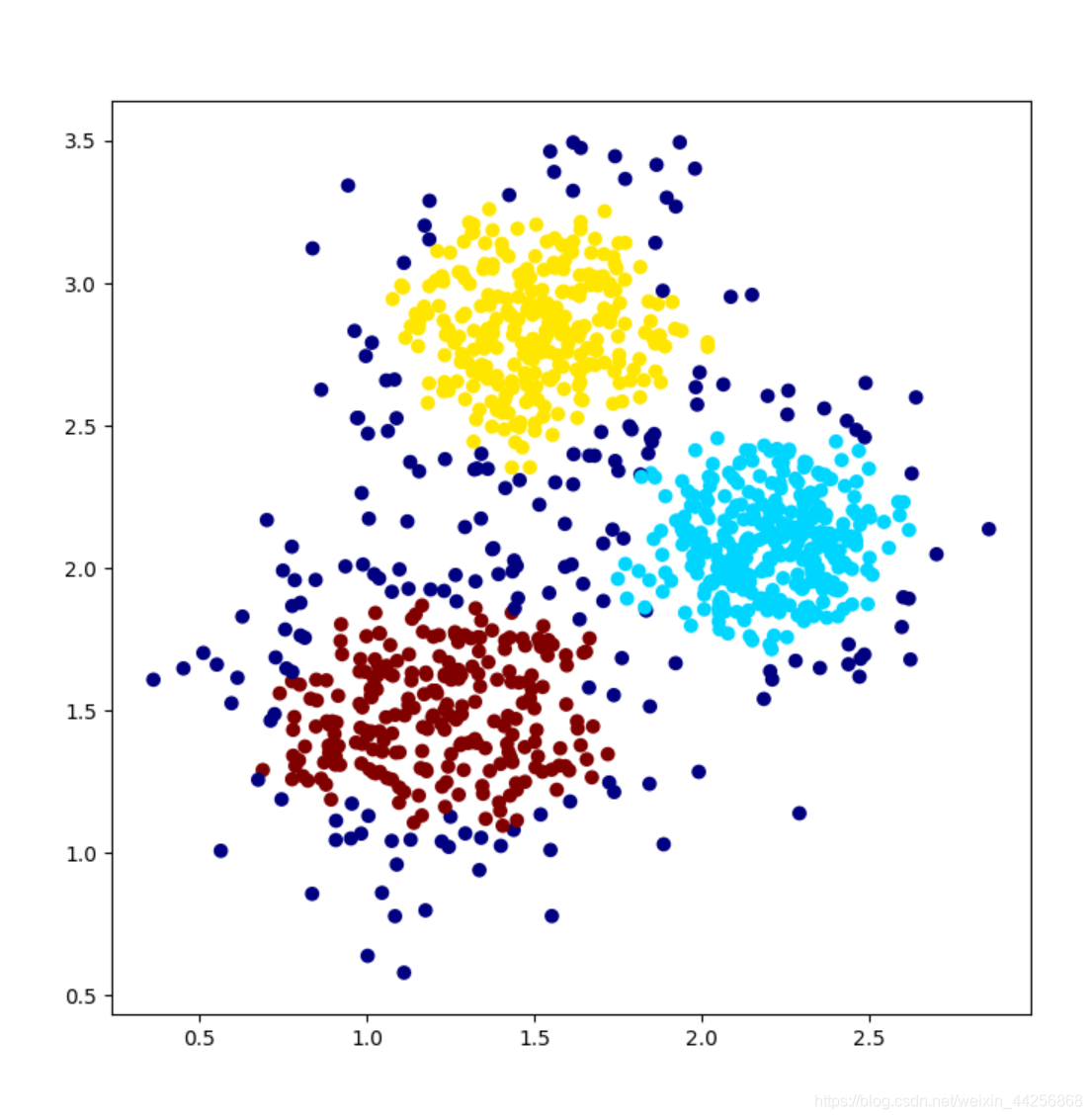
#下面使用DBSCAN算法对相同的数据进行聚类。
#选择邻居半径epsilon为1 距离度量为欧氏距离 核心点所需要的最小邻域样本数为10 个样本点
#邻域半径越小,一般得到的簇越多,邻域半径越大,越容易将更多样本聚集到一个簇中
#最小样本数越大,本当作噪声不进行分配的样本点就越多,反之则越少
dbscan_model=DBSCAN(eps=0.1,metric='euclidean',min_samples=10)
y_dbscan=dbscan_model.fit_predict(X)
p1=plt.figure(figsize=(8,8))
ax=p1.add_subplot(111)
ax.scatter(X[:,0],X[:,1],c=y_dbscan,cmap=plt.cm.jet)
p1.show()
4.实验结果
***1.原始数据分布***
2.K-means聚类后
3.DBSCAN聚类结果



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









