







处理缺失模态的模态不变多模态学习:一种单分支方法
arxiv 2024
论文链接

0.论文摘要和信息
摘要
摘要——多模态网络比单模态网络表现出显著的性能改进。现有的多模态网络是以多分支方式设计的,由于对融合策略的依赖,如果缺少一个或多个模态,则表现出恶化的性能。在这项工作中,我们提出了一种模态不变的多模态学习方法,它不太容易受到缺失模态的影响。它由跨多个模态共享权重的单分支网络组成,以学习模态间表示,从而最大化性能以及对缺失模态的鲁棒性。在四个具有挑战性的数据集上进行了广泛的实验,包括文本视觉(UPMC Food-101, Hateful Memes, Ferramenta)和视听模态(VoxCeleb1)。与现有的最先进的方法相比,我们提出的方法在所有模态都存在时以及在训练或测试期间缺少模态的情况下实现了优异的性能。
1.引言
包括文本、图像、视频和音频的多种模态通常包含关于共同主题的补充信息[4]、[5]、[6]。这些模态的不同组合已经被广泛研究,以解决各种任务,如多模态分类[7]、跨模态检索[8]、[9]、跨模态验证[10]、多模态命名实体识别[11]、视觉问答[12]、图像字幕[13]、多模态情感分析[14]和多模态机器翻译[15]。由于各种模态的结构和表示的差异,多模态建模具有挑战性[4]。现有的多模态方法通常使用基于神经网络的映射来学习多模态的联合表示。例如,利用单独的独立网络来提取每个模态的嵌入,以学习多分支网络[16]、[8]、[17]、[10]、[18]、[19]、[20]中的联合表示。类似地,一些最近的多模态方法利用Transformers来学习使用多分支的联合表示网络[21],[22]。在这些方法中,多分支网络的模块化性质是开发各种多模态应用的关键,并且已经证明了优于单模态方法的显著性能。然而,这些方法的局限性在于它们需要训练数据中的完整模态来展示良好的测试性能。
由于缺少模态,从现实世界收集的多模态数据通常是不完美的,导致现有模型的性能显著恶化[23]、[24]、[25]、[26]、[27]、[28]、[29]。例如,如表I所示,基于多模态Transformer model的模型ViLT[2]显示,当在测试时缺少70%的文本模态时,性能下降了28.3%。这种恶化的性能使得多模态学习对于可能遇到缺失模态的真实世界场景无效。性能的下降可能归因于实现用于模态交互的融合层的常用多分支设计(图1(a)-(c))。这种设计可以以性能高度依赖于输入模态的正确组合的方式学习权重[21],[2]。

表I:在不同训练和测试设置下,SRMM与ViLT[2]在UPMC Food-101[3]数据集上的比较。 ∆ ↓ ∆ ↓ ∆↓表示由于测试时缺少模态而导致的性能恶化。 ∆ ↓ = ( P c o m p l e t e − P m i s s i n g ) / P c o m p l e t e ∆ ↓ = (P_{complete} − P_{missing})/P_{complete} ∆↓=(Pcomplete−Pmissing)/Pcomplete,其中 P c o m p l e t e P_{complete} Pcomplete和 P m i s s i n g P_{missing} Pmissing是对完整和缺失模态的性能。每个设置中的最佳结果以粗体显示。
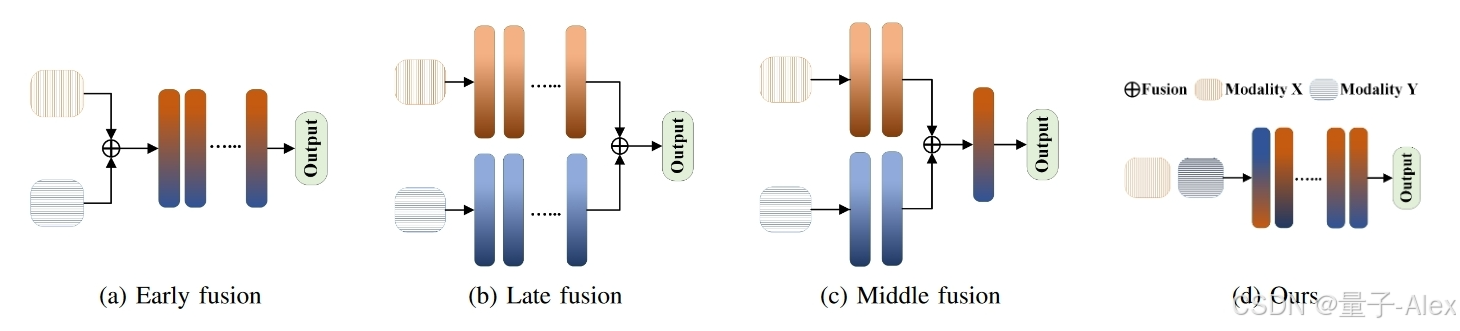
图1:常用的多分支网络的图示。这些方法从模态X和Y的嵌入中学习具有融合机制(早期、晚期或中期)的联合表示[1]。相比之下,我们提出的模态不变量方法仅利用一个分支来学习相似的表示。
在这项工作中,我们通过假设学习不同模态的共享表示能够实现公共连续表示空间[30]、[31]、[32]、[33]来解决对缺失模态的鲁棒性问题。在缺少模态的情况下,这种模态间表示可能是有益的。受此启发,我们提出了对缺失模态鲁棒的单分支方法(SRMM),该方法利用单分支网络中多个模态之间的权重共享来实现模态间表示的学习(图1d)。SRMM利用每个模态的预训练嵌入,并使用模态切换机制学习联合表示来执行训练。它在几个多模态数据集上优于最先进的(SOTA)方法,并在训练和测试期间表现出对缺失模态的卓越鲁棒性。例如,如表I所示,与现有的多模态SOTA方法ViLT[2]相比,当图像和文本模态在UPMC Food-101[3]上完全可用时,SRMM的分类准确率为91.9%。在相同的设置下,我们的方法优于ViLT,实现了94.6%的准确率.在严重缺失模态的情况下(即,在测试期间只有30%的文本模态可用),ViLT证明了65.9%的准确性。相比之下,SRMM通过在只有30%的文本模态可用时实现84.9%的准确率来证明对缺失模态的实质性鲁棒性,这优于单模态性能。在用于评估我们的方法的其他多模态分类数据集中也观察到了类似的趋势(第IV-D节)。我们工作的主要贡献如下:
1)SRMM:一种多模态学习方法,在训练和测试过程中对缺失模态具有鲁棒性。
2)模态不变机制,能够在单分支网络中跨多个模态进行权重共享。
3)在具有挑战性的数据集上进行了广泛的实验,包括文本-视觉(UPMC Food-101[3]、Hateful Memes[34]和Ferramenta[35])和视听(Voxceleb1[36])模态。当存在完整的模态时,SRMM表现出SOTA性能。类似地,在缺少模态的情况下,与现有的SOTA方法相比,我们的方法表现出更好的鲁棒性。
与会议版本的区别:我们的单分支训练的初步版本发表在2023年声学、语音和信号处理国际会议上[37]。在初步版本中,我们提出了一个单分支网络,并使用跨模态验证和匹配将其与现有多分支网络在基准多模态学习任务上的性能进行了比较。目前的工作是会议论文的实质性扩展,特别侧重于证明单分支网络对缺失模态场景是稳健的。首先,我们通过利用四个具有挑战性的多模态数据集来探索单分支网络在多模态分类新任务上的鲁棒性。其次,我们将研究扩展到另一种模态对(文本-视觉),以研究单分支训练的一般适用性。第三,我们广泛地展示了单分支训练对缺失模态具有显著的鲁棒性。
2.相关工作
多模态学习的目标是利用跨多个模态的互补信息来提高各种机器学习任务(如分类、检索或验证)的性能。每个多模态任务都不同,而基本目标保持不变:学习跨多模态的联合表征[4]、[5]、[38]。现有的多模态方法采用多分支网络通过最小化不同模态之间的距离来学习联合表示[8]、[18]、[19]、[20]、[39]、[40]、[41]。这种使用多分支网络的方法已经取得了显著的性能[42]、[3]、[43]、[39]、[35]、[44]。然而,如果一些模态在测试时缺失,大多数多模态方法会遭受性能恶化,这个问题通常被称为缺失模态问题[45]、[46]、[47]、[48]。
考虑到多模态方法的重要性,近年来人们对处理缺失模态问题越来越感兴趣[24]、[25]、[27]、[28]、[48]、[49]、[50]、[51]。通常,解决该问题的现有多模态方法可以分为三类。第一类是输入屏蔽方法,其在训练时随机移除输入以模拟缺失的模态信息。比如Parthasarathy等人[52]引入了一种在训练期间随机移除视觉输入的策略,以模拟多模态情感的缺失模态场景识别任务。第二类利用可用的模态来生成缺失的模态[27],[53]。比如张等人[47]以可用的视觉模态为条件生成缺失的文本模态。第三类学习具有来自多个模态的相关信息的联合表示[54]。比如韩等人[55]学习了视听联合表征来提高单模态情感识别任务的性能,然而,它不能在测试时利用完整的模态信息。
与先前的方法相反,我们建议使用跨多个模态的权重共享的单分支网络来学习模态不变表示。与现有的SOTA方法相比,SRMM不仅表现出优异的多模态性能,而且表现出对缺失模态的显著鲁棒性。
3.方法
在本节中,我们将描述SRMM,这是一种对缺失模态具有鲁棒性的多模态学习方法。SRMM建立在直觉上,即使用模态特定网络提取的多个嵌入表示相似的概念,但在不同的表示空间中。使用单分支网络的权重共享使得能够学习这些概念的模态间表示。然后,当在推理时缺少模态时,模型从表示中受益。图2展示了我们的方法。在下一节中,我们将解释模态嵌入提取、单分支网络和用于训练网络的损失公式。
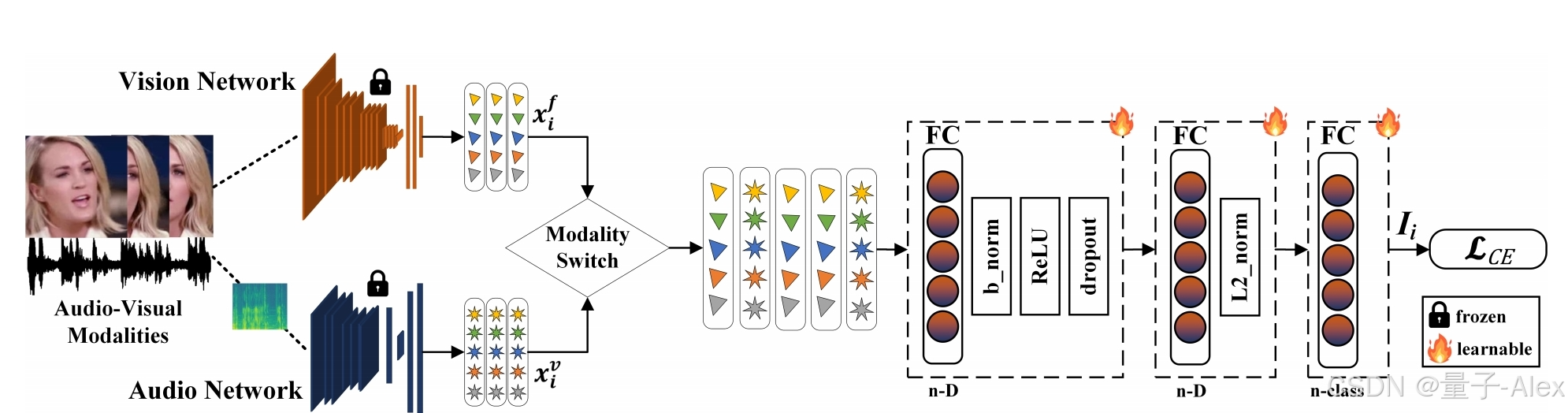
图2:SRMM的总体架构。特定于模态的预训练网络(给定示例中的视觉和音频网络)用于提取嵌入,所述嵌入通过模态切换机制并输入到我们的单分支网络,所述单分支网络学习模态独立表示,以编码跨多个模态的权重共享的模态间表示。
A.预备工作
给定 D = { ( M i 1 , M i 2 ) } i = 1 N \mathcal{D} = \{(M^1_i ,M^2_i )\}^N_{i=1} D={(Mi1,M
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 487
487

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











