






摘要:多模态模型的开发显著推动了多模态情感分析和情绪识别的进展。然而,在实际应用中,缺失模态的情况经常发生,导致模型性能下降。为了解决这个问题,本文提出了一种新型的多模态Transformer框架,利用提示学习来处理缺失模态。我们的模型引入了三种类型的提示:生成提示、缺失信号提示和缺失类型提示。这些提示能够生成缺失的模态特征,并促进模态间和模态内信息的学习。
1 引言
人类在感知世界时,是通过多模态的方式进行的。例如,我们通过视觉、听觉、触觉和语言等不同的感官来理解周围的环境。这些多模态的感知方式能够提供更加全面的信息,帮助我们更好地理解和探索世界。在情感分析和情绪识别任务中,使用多模态信息(如文本、语音、视频等)能够提供更丰富的情感线索,从而提升分析和识别的准确性。
然而,在现实世界中的应用中,多模态模型常常面临一个重要挑战:缺失模态的问题。多模态数据来自不同的源,可能由于设备故障、数据丢失、隐私问题或数据采集过程中的其他问题,导致某些模态信息的缺失。例如,在情绪识别任务中,某些音频信号可能由于录音质量差或网络传输问题而丢失,或者视频数据可能由于隐私保护原因无法获取。这些缺失的模态会导致现有的多模态模型性能严重下降,尤其是当模型在训练时使用的是完整数据集,但在测试时面临缺失模态的情况。
现有的大多数多模态情感分析和情绪识别方法假设数据是完整的,并且训练过程中各个模态的信息都是齐全的。这种假设在现实中往往不成立,因此,当模型遇到缺失模态时,通常会面临性能下降的问题。为了应对这个问题,研究人员提出了多种方法来处理缺失模态的情况。例如,一些方法直接生成缺失模态的信息,或者通过联合学习来预测缺失模态的表示。然而,这些方法往往依赖于复杂的架构,计算开销较大,且很难在实际应用中高效运行。
本文的贡献
为了有效解决缺失模态的问题,本文提出了一种新型的多模态Transformer框架,利用提示学习(Prompt Learning)来处理缺失模态。在我们的方法中,提示作为一种信息增强机制,通过不同类型的提示来弥补缺失的模态信息。我们提出了三种类型的提示:
- 生成提示(Generative Prompts):用于生成缺失的模态信息。
- 缺失信号提示(Missing-Signal Prompts):这种提示是模态特定的,用于捕捉单一模态的信息。
- 缺失类型提示(Missing-Type Prompts):这种提示是模态共享的,用于捕捉模态间的相互关系。
通过这些提示,我们能够有效地生成缺失的信息,并学习模态内和模态间的关系。此外,我们的框架大幅度减少了可训练参数数量,提高了计算效率。这使得我们的模型不仅在缺失模态情况下表现出色,还能够在资源受限的环境中运行。
2 关键
1 多模态情感分析与情绪识别的定义与挑战
MSA(多模态情感分析)和MER(情绪识别)都旨在通过分析多种模态的数据来理解和预测情感或情绪。例如,情感分析可以基于文本、语音和视频等多种信号来推断某人是表达积极还是消极的情感;而情绪识别则更关注不同情绪(如快乐、愤怒、悲伤等)的准确分类。
这些任务的主要挑战在于如何处理和融合来自不同模态的互补信息,因为不同的模态包含的情感信息可能不同且存在信息不一致或缺失的情况。
2 多模态信息融合策略
在多模态情感分析和情绪识别中,信息融合是一个关键步骤。目前,存在两种主要的融合策略:
特征级融合(Feature-Level Fusion):这种方法将来自不同模态的特征进行组合,生成统一的特征表示。特征级融合方法通常通过拼接、加权或其他数学方式来结合不同模态的特征。
决策级融合(Decision-Level Fusion):这种方法独立处理不同模态的数据,并在每个模态上做出预测后,将这些决策融合到最终的输出。
3 现有方法的挑战
缺失模态问题:多模态情感分析和情绪识别面临的一个主要挑战是缺失模态的问题。在现实应用中,可能由于设备故障、数据损坏或隐私问题导致某些模态缺失。然而,现有的多模态模型通常假设所有模态在训练和测试时都是完备的,因此,它们往往在面对缺失模态时表现不佳。
大规模模型的微调困难:随着大规模预训练多模态模型(如 CLIP 和 Flamingo)的成功,许多研究者尝试通过微调这些模型来适应下游任务。然而,大规模模型的微调通常需要巨大的计算资源,而在小数据集上微调可能导致模型的不稳定性(Mosbach et al., 2021)。因此,如何有效利用这些大型预训练模型,尤其是在有限计算资源下,是一个重要问题。
4 缺失模态现有解决方法
1 生成缺失模态
一些方法试图通过可用的模态信息来生成缺失的模态,从而弥补数据的缺失。例如
Cai et al. (2018) 提出了通过深度生成对抗网络(GANs)生成缺失模态的策略。该方法基于现有模态数据生成缺失的模态,从而避免了由于缺失模态导致的性能下降。
Du et al. (2018) 提出了基于半监督学习的生成模型,通过生成缺失模态来补全信息,使得模型可以在多模态数据不完整的情况下进行有效学习。
2 学习鲁棒的联合表示
另一种方法是通过学习鲁棒的联合模态表示,使得即使在某些模态缺失的情况下,模型依然能够从其他模态中获得足够的信息。
Zhao et al. (2021) 提出了一个方法来学习联合多模态表示,并在缺失模态的情况下,通过可用模态推断缺失模态的表示。这种方法利用可用模态的信息来预测缺失模态,从而降低缺失模态对模型性能的影响。
Ma et al. (2021) 提出的 SMIL (Severely Missing Modality) 模型也基于贝叶斯元学习(Bayesian Meta-Learning),旨在通过优化学习策略应对严重缺失模态的情境。
3 提示学习(Prompt Learning)方法
提示学习在处理缺失模态问题中获得了广泛关注,尤其是在大语言模型(如 GPT)和跨模态模型中。提示可以作为补充信息来指导模型处理缺失模态,从而有效减轻缺失模态对性能的负面影响。
Lee et al. (2023) 提出了使用缺失模态提示(Missing Modality Prompts)的方法来处理缺失模态问题。通过引入三种类型的提示(生成提示、缺失信号提示和缺失类型提示),模型能够有效生成缺失模态的信息,并在多个模态之间建立联系,从而提高多模态情感分析和情绪识别的准确性。
通过这种方法,模型可以在没有所有模态的情况下通过提示补充信息,进而减少由于模态缺失导致的性能损失。
4 多模态注意力机制
一些方法通过引入注意力机制来处理缺失模态,注意力机制能够帮助模型在不同模态之间进行有效的信息传递。
Liu et al. (2020) 提出了基于注意力机制的多模态融合方法,利用不同模态之间的相互关系来增强模型对缺失模态的鲁棒性。通过关注更重要的模态,模型能够在其他模态缺失时依然获得较好的表现。
5 现有方法的局限性与挑战
计算开销大:许多现有方法(如基于生成模型的补全方法)通常需要复杂的架构和大量的计算资源。例如,生成缺失模态的模型往往涉及多个网络组件的训练,导致计算成本较高。
缺失模态预测的不确定性:即使使用生成模型和鲁棒表示学习方法,预测缺失模态时仍存在一定的不确定性,生成的模态可能无法完美反映真实数据的分布,进而影响最终的预测性能。
高效性问题:虽然一些方法(如提示学习)通过减少可训练的参数来提升计算效率,但在复杂的多模态数据场景中,如何保持模型的有效性和效率之间的平衡仍是一个挑战。
5 提出的解决方案与贡献
本文提出了一种新的基于提示学习的方法来应对缺失模态问题。通过引入三种类型的提示(生成提示、缺失信号提示和缺失类型提示),该方法能够有效地处理缺失模态问题,同时显著减少计算开销和模型训练的复杂度。
这种方法不仅减少了对复杂架构的依赖,还能在多模态情感分析和情绪识别任务中,针对不同模态缺失的情境保持较高的性能。
1 生成提示(Generative Prompts)
定义:生成提示是用来指导模型在某些模态缺失时,如何通过已有模态信息生成缺失的模态数据。
作用:当某些模态(如视觉或音频数据)缺失时,生成提示通过学习已有模态(如文本或其他可用模态)的潜在表示来补充缺失的模态信息。模型通过生成提示来恢复和补充丢失的模态信息,帮助模型更好地理解和处理缺失模态的情况。
实现方式:生成提示可以被视为一个补充信号,它告知模型在某些模态缺失时,如何从可用的模态中推测出缺失模态的特征。通过这种方式,生成提示能够帮助模型通过已有模态生成缺失的模态数据。
2 缺失信号提示(Missing-Signal Prompts)
定义:缺失信号提示是模态特定的提示,用于指示哪些模态在当前输入中缺失。它告诉模型哪些模态的数据是丢失的,帮助模型在推理时能够更好地处理缺失模态。
作用:与生成提示不同,缺失信号提示并不试图恢复缺失模态,而是提供模态缺失的显式信号,使得模型在推理时能够识别并调整其处理策略。例如,如果视频模态缺失,模型能够知道缺少的是视频模态,从而对音频和文本模态的关系进行更有效的建模。
实现方式:缺失信号提示通常与每个模态相关联,并且为每个模态提供一个指示符或标志,表明该模态是否缺失。这可以是一个标量值或者一个向量,模型根据这些提示信号来调整其推理方式。
3 缺失类型提示(Missing-Type Prompts)
定义:缺失类型提示是跨模态的提示,用于指示某些模态的缺失类型,通常涵盖多个模态的缺失情景。它不仅告诉模型某个特定模态缺失,还告知模型多个模态缺失的组合模式。
作用:与缺失信号提示(通常只关注单一模态的缺失)不同,缺失类型提示关注的是缺失模式,即哪些模态同时缺失。通过这种方式,模型可以学习如何在多个模态同时缺失的情况下依然保持良好的性能。缺失类型提示帮助模型处理不同的缺失组合,例如视频和音频同时缺失,或者只有文本缺失等。
实现方式:缺失类型提示通常通过一个投影矩阵来构建,该矩阵结合了每个模态的缺失信号,并生成跨模态的信息。这样,模型不仅知道某个模态是否缺失,还能够知道哪些模态缺失,且如何根据不同的缺失模式调整推理策略。
3 方法
1 总体模型
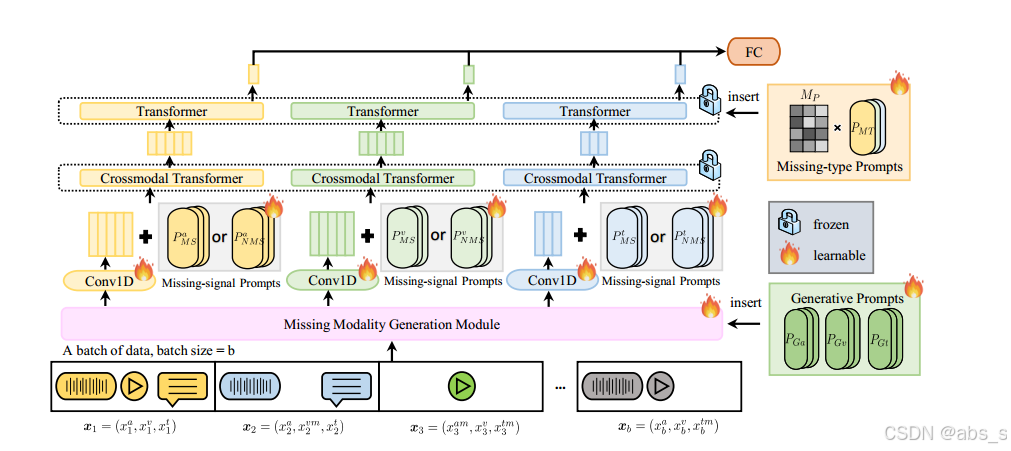
输入数据
输入数据包含多模态信息,例如文本、音频和视频。这些模态可能存在缺失,意味着某些模态(如文本或音频)在某些数据样本中不可用。为了处理这些缺失的模态,本文的方法设计了一个特殊的机制,确保模型可以在缺失某些模态时依然能够有效地进行推理。
缺失模态生成模块 (Missing Modality Generation Module)
该模块是整个架构中的关键部分,它的主要任务是生成缺失模态的特征表示。输入数据被送入此模块后,模型基于可用的模态(例如,文本或音频)推断出缺失模态的特征。例如,如果视频模态缺失,模型可以根据音频和文本信息生成缺失的视觉特征。通过这种生成机制,模型能够“补全”缺失的模态,从而获得更完整的模态信息。
预训练骨干网络 (Pre-trained Backbone)
一旦缺失模态的特征生成后,这些特征被输入到一个 预训练骨干网络 中。该骨干网络通常是一个多模态神经网络(例如,Transformer架构),它已经在大规模数据集上进行过预训练,具备了处理多模态信息的能力。在处理特征时,骨干网络结合了来自不同模态的输入(包括生成的模态和可用模态)。
缺失信号提示与缺失类型提示
为了帮助骨干网络更好地理解输入中哪些模态是缺失的,模型使用了两种类型的提示:
缺失信号提示(Missing-Signal Prompts):这种提示告知模型哪些模态数据缺失,帮助模型在处理时识别哪些信息是“不完整”的。
缺失类型提示(Missing-Type Prompts):这种提示进一步提供关于缺失模态的类型信息。例如,如果文本缺失,模型会知道缺失的是“文本”模态,而不是“音频”或“视频”。
这些提示信息有助于骨干网络在训练过程中更加关注如何处理缺失的模态,并能有效地将这些提示信息融入到模型的推理过程中。
输出和决策层
经过上述处理后,模型会生成一个联合特征表示,这些表示可以用来进行下游任务(如情感分析或情绪识别)。
2 缺失模态生成模块(MMGM)
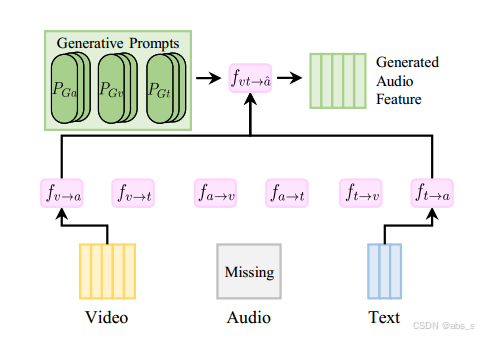
缺失模态生成模块(Missing Modality Generation Module,简称 MMGM)是本文提出方法中的关键组件,旨在解决多模态学习中的缺失模态问题。该模块通过利用已存在的模态(例如文本和视频)来推断和生成缺失的模态信息(例如音频或视频),从而提高模型对缺失模态的处理能力。
生成缺失模态特征
在多模态任务中,往往会遇到某些模态缺失的情况(例如,音频缺失或视频缺失)。MMGM的目的是根据已有模态的特征生成缺失模态的表示。例如,如果输入数据缺失音频模态(x_am),那么MMGM将根据视频模态(x_v)和文本模态(x_t)生成音频模态的特征(ˆx_a)。
生成提示
MMGM使用生成提示(Generative Prompts)来帮助生成缺失模态的特征。具体来说,生成提示包括:
P_Ga:音频的生成提示
P_Gv:视频的生成提示
P_Gt:文本的生成提示
这些生成提示作为输入与现有模态的特征结合,通过模型生成缺失模态的特征表示。
生成过程
MMGM通过结合生成提示和可用模态的特征,生成缺失模态的表示。假设音频模态缺失,MMGM将基于文本和视频信息生成音频特征。具体过程可以通过以下方程表示:
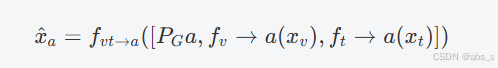
fv→a(xv) 表示从视频模态生成音频模态特征的过程。
ft→a(xt)ft→a(xt) 表示从文本模态生成音频模态特征的过程。
fvt→afvt→a 是一个函数,结合了视频和文本特征以及生成提示,生成音频模态的特征。
MMGM采用相对简单的结构,通过两个卷积块(Conv1D)和生成提示来生成缺失模态特征。与传统方法相比,这种方法避免了复杂的架构,降低了计算复杂度,使得该方法更高效。
3 缺失信号和缺失类型提示
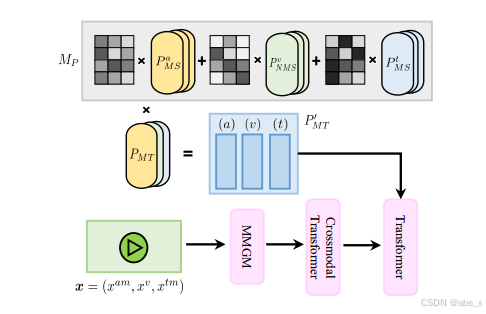
在多模态学习中,缺失模态问题是一个常见且挑战性较大的问题。为了解决这一问题,本文提出了两种不同类型的提示机制:缺失信号提示(Missing-Signal Prompts, P_MS)和缺失类型提示(Missing-Type Prompts, P_MT)。这两种提示机制可以帮助模型更好地处理缺失模态,提高多模态任务中的表现。
1 缺失信号提示 (Missing-Signal Prompts, P_MS)
缺失信号提示是专门为每种模态设计的,它的主要作用是告知模型某个特定模态是否缺失。它通过为每个模态生成一个信号,明确哪些模态是缺失的,从而让模型更好地理解输入数据的缺失情况。假设一个多模态任务涉及音频(A)、视频(V)和文本(T)三种模态。缺失信号提示为每个模态分配一个特定的信号,告诉模型该模态是否缺失。例如:
P_A_MS:表示音频模态是否缺失。
P_V_MS:表示视频模态是否缺失。
P_T_MS:表示文本模态是否缺失。
当模型接收到输入数据时,缺失信号提示会与实际输入(即可用模态)一起传递给模型。例如,如果视频模态缺失,P_V_MS 会给模型一个明确的信号,帮助模型理解视频模态不存在,从而调整模型的处理策略。
2 缺失类型提示 (Missing-Type Prompts, P_MT)
缺失类型提示用于告知模型哪些模态的组合缺失,而不仅仅是单个模态的缺失。
它帮助模型理解在多模态输入中,哪些模态组合是缺失的,从而支持更细粒度的信息推理和跨模态学习。假设存在多个模态(音频、视频、文本),并且可能存在不同的模态组合缺失。缺失类型提示为每种可能的缺失模态组合提供相应的信息。例如,若存在三种模态(音频、视频和文本),可以有以下几种缺失类型:
音频和视频缺失(x_am 和 x_vm)
音频和文本缺失(x_am 和 x_tm)
视频和文本缺失(x_vm 和 x_tm)
所有模态缺失(x_am, x_vm, x_tm)
缺失类型提示通常是一个共享的表示,可以对多个模态的缺失情况进行编码。当某些模态缺失时,缺失类型提示将提供一种复合的信号,帮助模型更好地学习跨模态的关系。例如,模型可能会知道在某些情况下音频和文本模态缺失,而视频仍然可用。在这种情况下,模型就可以通过缺失类型提示来补充推理过程。
4 实验
详情数据请参考文章
1 数据集与评估指标
数据集: 本文选用了多个数据集来评估提出的方法,包括高资源数据集 CMU-MOSEI 和低资源数据集 CMU-MOSI、IEMOCAP 和 CH-SIMS。这些数据集涵盖了情感分析和情绪识别任务中的多模态数据(如文本、音频和视频)。
CMU-MOSI 和 CMU-MOSEI 用于情感分析(包含视频、音频和文本模态)。
IEMOCAP 用于情绪识别,包含4种情绪(快乐、愤怒、悲伤、冷静)。
CH-SIMS 是中文情感分析数据集,包含视频片段和情感标签。
评估指标: 为了全面评估模型性能,本文使用了多种指标:
对于 CMU-MOSI 和 CMU-MOSEI 数据集:7类准确率(ACC-7)、二分类准确率(ACC)、F1值、均方误差(MAE)和皮尔逊相关系数(Corr)。
对于 IEMOCAP 数据集:平均准确率(ACC)和加权F1值(F1)。
对于 CH-SIMS 数据集:二分类准确率(ACC)、F1值、均方误差(MAE)和皮尔逊相关系数(Corr)。
2 实验设置与基准方法
实验设置: 在实验中,模型使用 CMU-MOSEI 数据集进行预训练,并在 CMU-MOSI、IEMOCAP 和 CH-SIMS 数据集上进行评估。所有实验在不同的缺失模态情况下进行,模型在训练过程中模拟缺失模态,测试时分别考察不同模态缺失的情况。
基准方法: 本文将提出的方法与多个现有的基准方法进行比较,基准方法包括:
Lower Bound (LB):使用不同模态组合训练的模型。
Modality Substitution (MS):将缺失的模态用默认值或占位符代替。
Modality Dropout (MD):在训练过程中随机丢弃某些模态。
MCTN:通过在模态间进行转换学习来增强模型对缺失模态的鲁棒性。
MMIN:学习稳健的联合表示,能够根据可用模态预测缺失模态的表示。
MPMM:使用缺失感知提示来指导模型应对缺失模态问题。
3 实验结果
总体结果: 实验结果表明,本文提出的方法在所有数据集和评估指标上均优于上述基准方法。在测试时面对不同模态缺失的情况时,提出的方法始终表现出色。
在 CMU-MOSI 数据集上,提出的方法比基准方法提高了约5%-13%的准确率,尤其在文本模态缺失时,表现最为突出。
在 CMU-MOSEI 数据集上,提出的方法同样优于所有基准方法,并且在缺失模态的情况下,能够大幅提高模型的鲁棒性。
不同模型的性能比较: 在将提示学习方法应用于不同的基础模型(如 MISA、MMIM 和 UniMSE)后,结果表明,无论是基于何种模型,加入提示学习方法都能显著提升其对缺失模态的适应能力。
对于 MISA、MMIM 和 UniMSE 等模型,加入生成提示和缺失类型提示后,模型在缺失模态的情况下,准确率普遍提升了3%-5%。
不同缺失模态情况的表现: 通过实验还发现,提出的方法能够有效应对不同模态缺失的情况,特别是在多模态缺失的复杂场景下,模型依然能够保持较高的性能。
4 消融实验
本文还进行了消融实验,探讨了三种提示(生成提示、缺失信号提示和缺失类型提示)的贡献,以及缺失模态的缺失率和提示长度的影响。
三种提示的贡献: 实验结果表明,三种提示在提升模型性能方面互为补充,缺失信号提示和缺失类型提示对于模型应对缺失模态至关重要。
缺失模态的缺失率: 随着缺失模态的比例增加,传统模型性能下降较为明显,而提出的方法能够在缺失模态较多的情况下仍保持较高的准确率。
提示长度的影响: 实验还表明,适当增加提示长度有助于模型更好地学习模态间和模态内的关系,从而进一步提升性能。
5 结果分析
鲁棒性与适应性: 提出的方法在面对不同模态缺失时表现出了良好的鲁棒性,能够有效适应不同的缺失模态情况,尤其在文本模态缺失时,性能提升最为显著。
计算效率: 由于提示学习显著减少了可训练参数,模型的计算效率得到了提升,使得该方法在实际应用中更具可行性。
5 结论
本文提出了一种新型的多模态Transformer框架,通过提示学习解决缺失模态问题。我们提出了三种类型的提示:生成提示、缺失信号提示和缺失类型提示。生成提示有助于生成缺失的信息;缺失信号提示是模态特定的,而缺失类型提示是模态共享的,分别帮助模型学习模态内和模态间的关系。通过提示学习,我们可以显著减少可训练参数数量,提升计算效率。大量实验和消融研究证明了我们方法的有效性和鲁棒性。


















 841
841

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









