







 本文介绍了如何简化在Jetson Xavier NX上安装CUDA和CUDNN的过程。现在可以通过NVIDIA的SDKManager直接烧录CUDA到设备,避免复杂的手动安装步骤。同时提醒注意,在安装时不要勾选Jetson OS以防止重装系统。如果设备之前未安装CUDA,可能是因为系统烧录时未选择。此外,还提供了之前的老版安装CUDA 10.2和CUDNN 8.0的详细步骤,包括下载、配置环境和文件拷贝等。
本文介绍了如何简化在Jetson Xavier NX上安装CUDA和CUDNN的过程。现在可以通过NVIDIA的SDKManager直接烧录CUDA到设备,避免复杂的手动安装步骤。同时提醒注意,在安装时不要勾选Jetson OS以防止重装系统。如果设备之前未安装CUDA,可能是因为系统烧录时未选择。此外,还提供了之前的老版安装CUDA 10.2和CUDNN 8.0的详细步骤,包括下载、配置环境和文件拷贝等。
2022.6.16更新
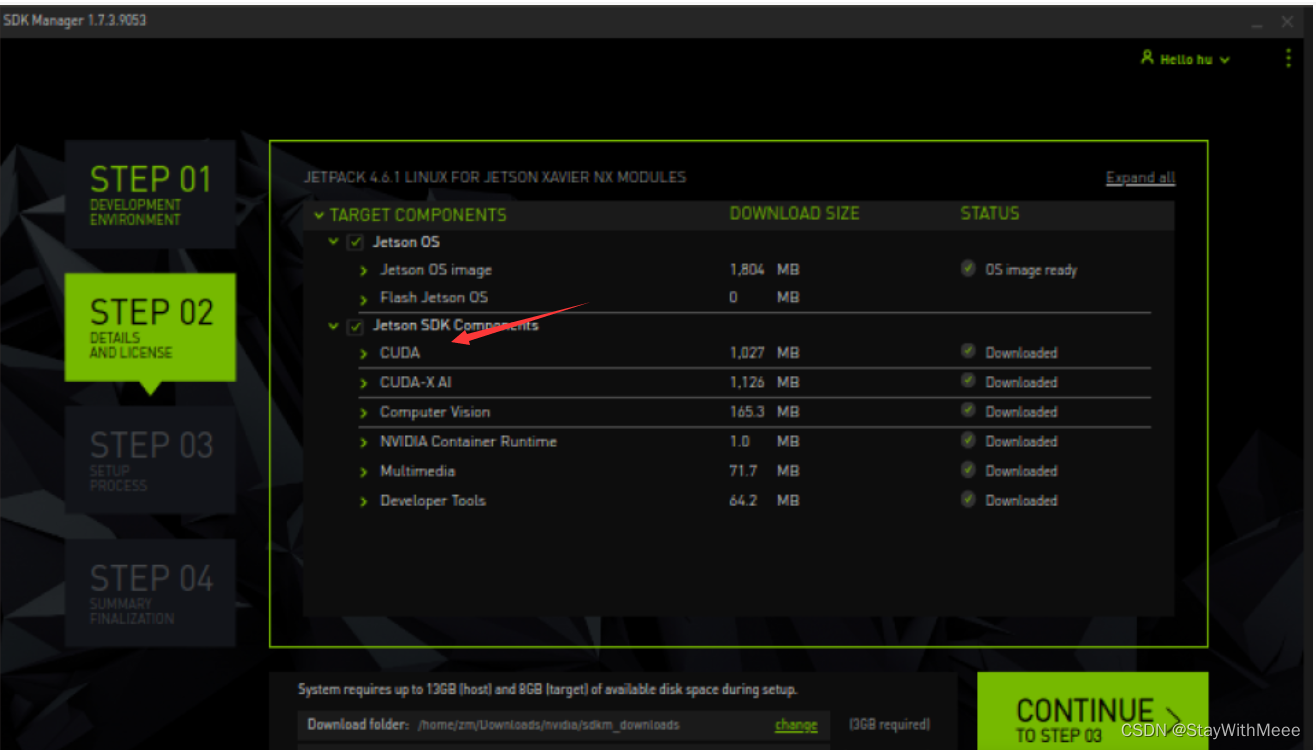
现在Jetson xavier nx 安装CUDA和CUDNN不需要下面那么复杂了,可以直接通过刷机将其安装到设备上。在官网下载SDK Manager可以直接将CUDA烧录进设备(特别注意,如果只安装CUDA,不要勾选下图中Jetson OS,否则会重装系统!!!!)。Jetson设备没有CUDA一般都是烧录系统时没有选择CUDA,如下图所示。我的设备是14G + 128G,系统烧录在核心中(14G),如果同时烧录系统和CUDA内存会不够。
刷机可以参考:NVIDIA JETSON XAVIER NX烧录(emmc版本)_dazzlingn的博客-优快云博客_jetson nx烧录
以下是原答案:
我的Jetson xavier nx 在跑程序时出现以下错误:OSERROR:libcudnn.so.8: cannot open shared object file: No such file or directory 和libcurand1.so.10 cannot open shared object file: No such file or directory
原因是在设备中未发现cuda和cudnn,所以需要重装, 折腾了很久终于可以跑起来。
安装CUDA10.2
1、首先下载cuda
第一种方法:直接输入安装cuda10.2
sudo apt-get update
sudo apt-get install cuda-toolkit-10-2
第二种:也可使用百度网盘下载:
链接:https://pan.baidu.com/s/1AlsKa2esktaFxwUI768BSQ
提取码:1998
2、下载好后配置环境
针对第一种方法:
sudo gedit ~/.bashrc
将以下内容复制到最后一行
export PATH=/usr/local/cuda-10.2/bin${PATH:+:${PATH}}
export LD_LIBRARY_PATH=/usr/local/cuda-10.2/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
export CUDA_ROOT=/usr/local/cuda保存,然后
source ~/.bashrc
针对第二种方法:
参考:https://blog.youkuaiyun.com/qq_30841655/article/details/120527741
安装CUDNN8.0
这个比较复杂,因为官网提供的是基于Linux , amd类型的,而我们jetson需要下载arm架构的文件,所以只有在运行jetpack安装包后才会有arm类型的版本。
需要

官网提供

首先进入官网https://developer.nvidia.com/jetpack-sdk-451-archive下载对应版本的文件,下载SDK Manager(需要科学上网,注册账号),或者用我下载的版本(上面百度网盘)

首先 需要一台Ubuntu系统的电脑,运行上面下载好的软件
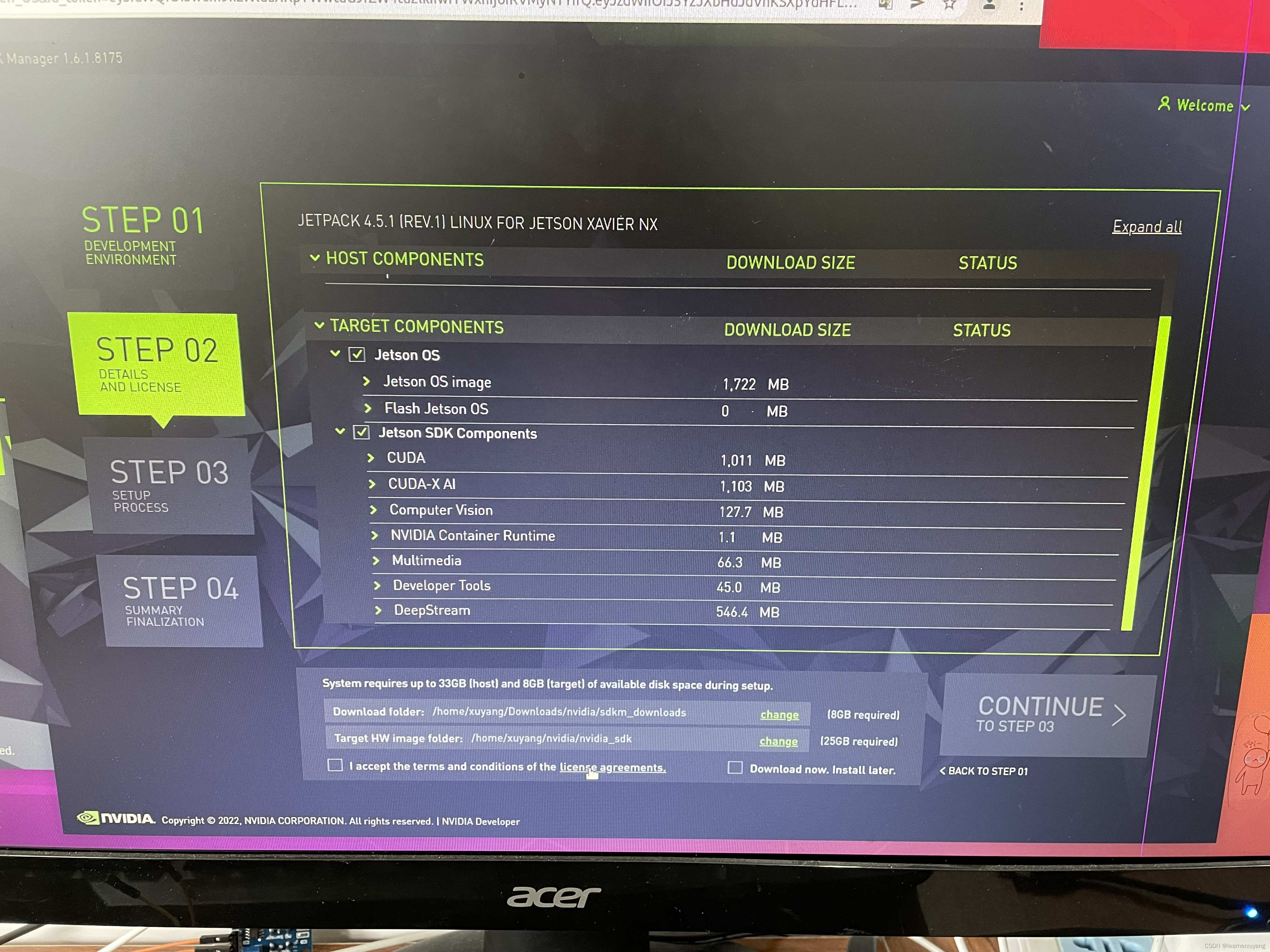
sudo dpkg -i sdkmanager_1.6.1-8175_amd64.deb按照官方教程:https://docs.nvidia.com/sdk-manager/install-with-sdkm-jetson/index.html 得到如下界面,一路默认,直到文件下载好,下载过程中可能会报错,不用理会,我们的目的是得到cudnn8.0安装包。
找到下载的文件(下图三个),下面在jetson 上面操作。

将3个文件拷贝到jetson设备上,运行:
sudo dpkg -i libcudnn8_8.0.0.180-1+cuda10.2_arm64.deb
sudo dpkg -i libcudnn8-dev_8.0.0.180-1+cuda10.2_arm64.deb
sudo dpkg -i libcudnn8-doc_8.0.0.180-1+cuda10.2_arm64.deb安装完成后,其实是直接安装到了默认安装路径usr/include和usr/lib下的,因此需要将其拷贝到cuda安装路径下:
sudo cp /usr/include/cudnn.h /usr/local/cuda/include/
sudo cp /usr/lib/aarch64-linux-gnu/libcudnn* /usr/local/cuda/lib64/
至此cuda10.2和cudnn8.0 安装就完成了


















 4816
4816

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











