






***AI领域非常重要的模型,按自己的理解讲解一下原理***
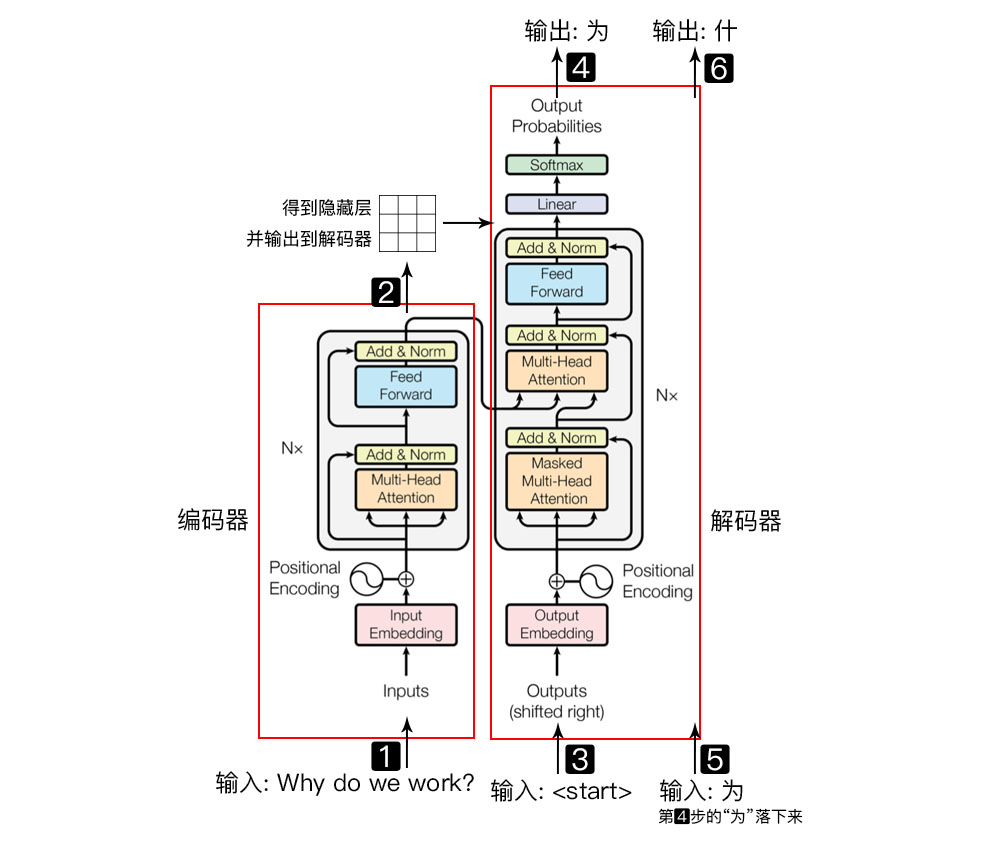
与seq2seq不同,transformer里没有用到任何循环神经网络,而只用到了self-attention自注意力机制,这也导致词嵌入方式和encoder以及decoder的工作方式有了一些改变。
首先明确一点,transformer模型就是由一堆encoder和一堆decoder连在一起构成的,在原文中两个coder都是6个,且都是线性连接的即当前输入得到一个输出,该输出成为下一个新输入以此类推。
1.Encoder
1.1 Positional Encoding
我们看上图的第一步,词嵌入步骤,首先根据embedding方式将why do we work ?这句话转换成向量格式即每个单词由一组数字来表示,之后有一个很重要的步骤是positional encoding,这个东西的作用是记录下来每个词的位置信息,因为RNN或者LSTM的输入形式都是按照时间步顺序一个字一个字输入,但这里没有任何RNN和LSTM,所以单词的位置信息无法表示,需要通过一个写死的函数计算一下各个位置单词的位置信息,最终也会得到一个和embedding维数相同的矩阵,二者相加即可得到最终的输入数据。
1.2 Self-attention
接下来讲一下最重要的自注意力机制,因为encoder和decoder的核心部分都是self-attention,transformer中的自注意力机制属于多头自注意力机制,与单个还是有点区别后面会提及,但原理是一样的。首先如下图所示
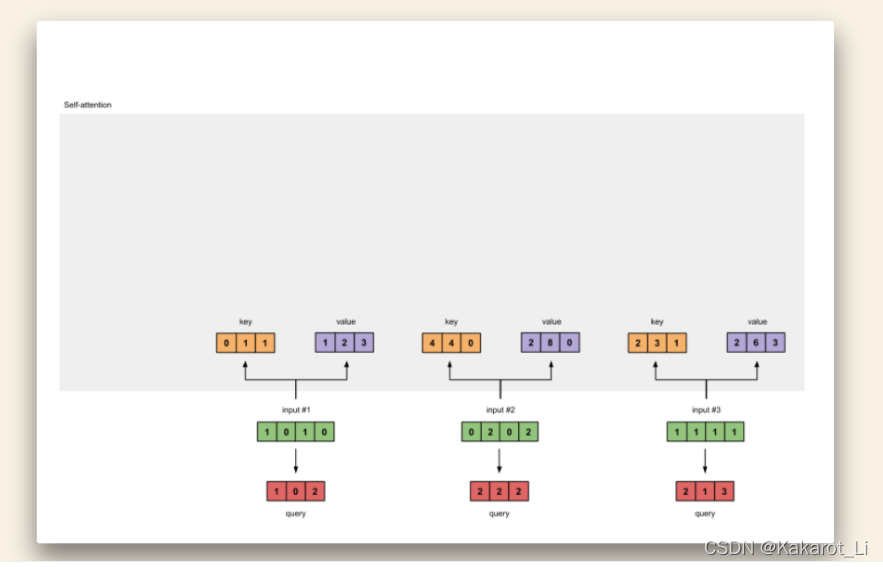
三个绿色的框是input,对应三个单词,我们会定义三个矩阵WQ WK WV分别去乘input向量(这三个矩阵就是需要去训练的参数)得到三个q、k、v矩阵也就是上图的红、黄、紫框对应的内容。
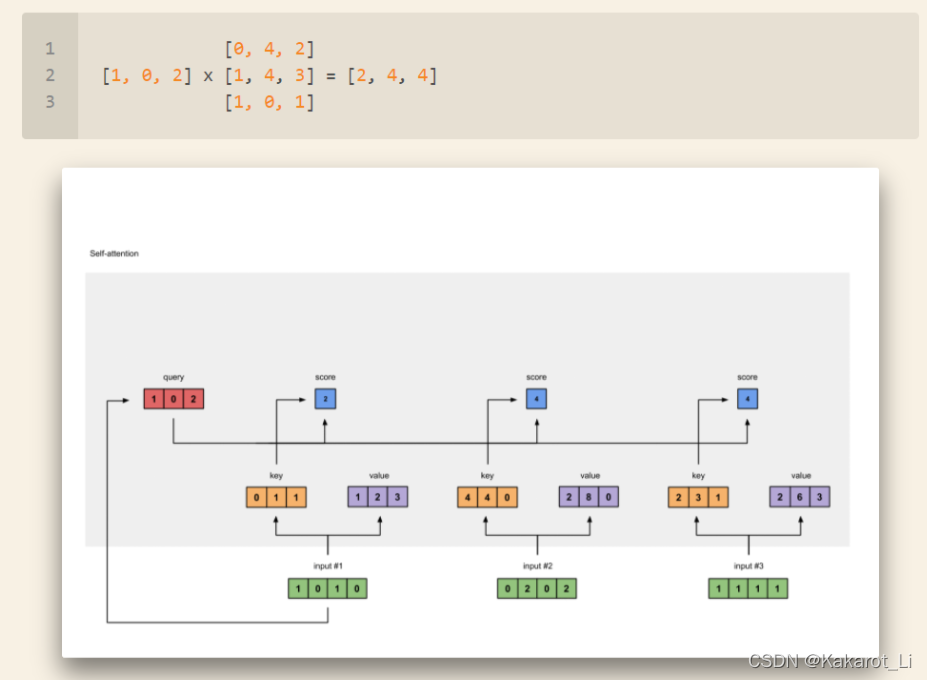
为了得到第一个字的注意力权重,需要用第一个字的q1去乘以所有单词的k向量的转置,如上图所示得到[2,4,4]。
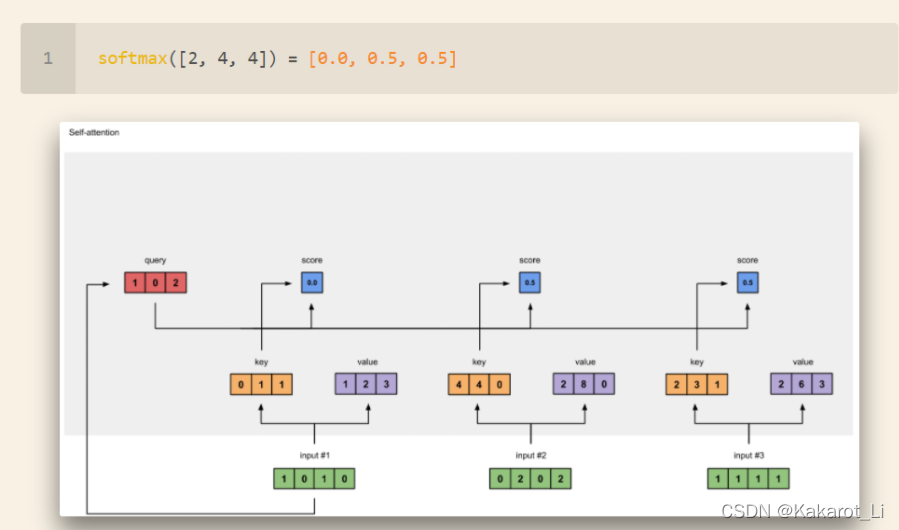
再经过softmax操作得到和为1的[0.0634, 0.4683, 0.4683]。
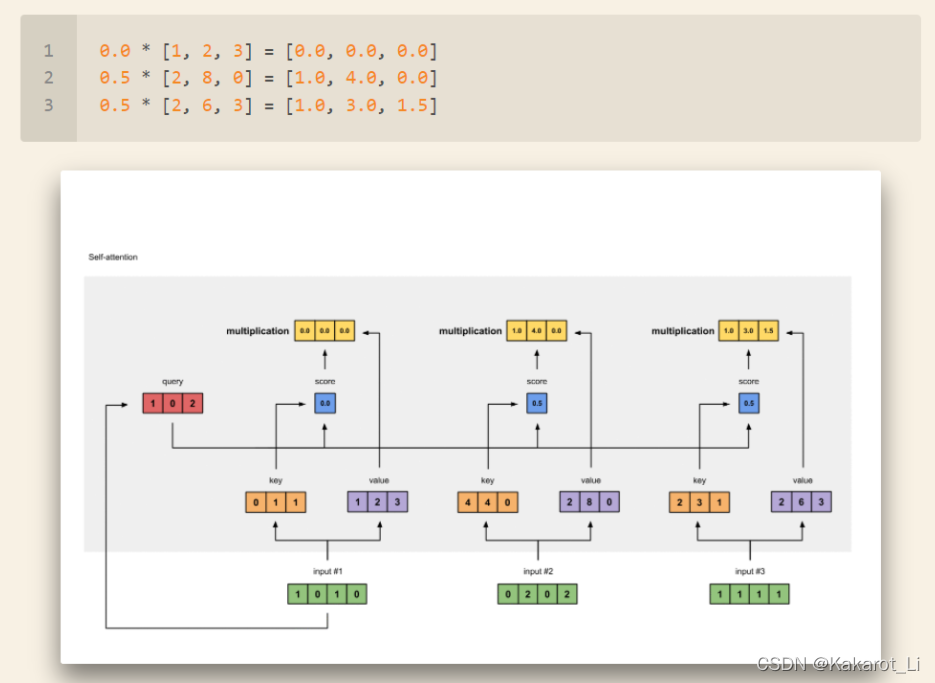
有了注意力权重后用这些权重分别去成对应字的值向量v得到上图所示结果
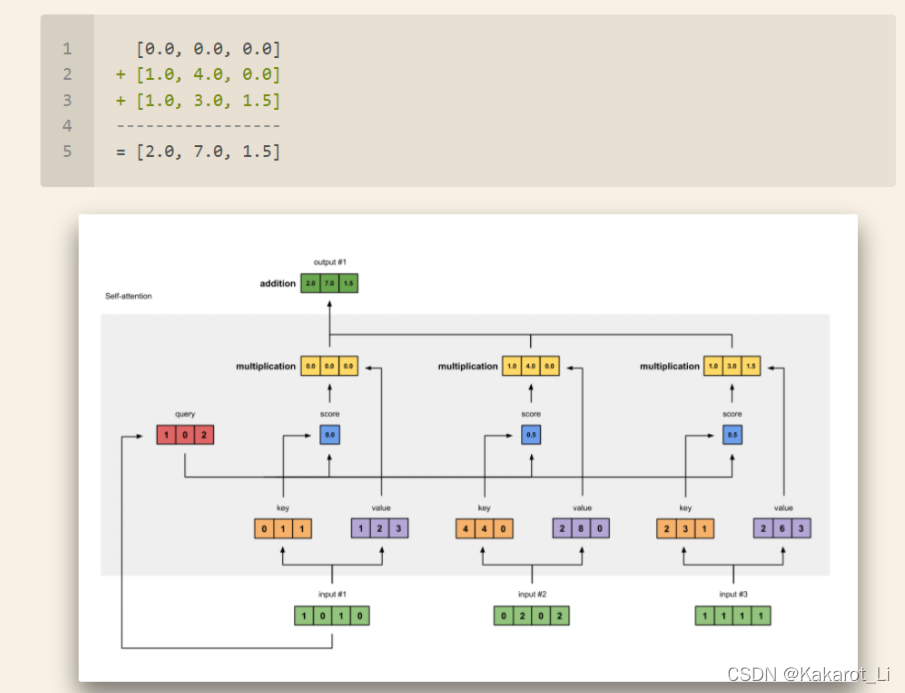
再将权重化后的值向量相加得到第一个字的输出,其他input操作相同,即可得到所有字的self-attention输出
1.3 Multi-Head attention
多头其实就是并行几组WQ WK WV矩阵,对文章的不同上下文进行注意力获取得到更好的输出结果,举个例子:tom gave roses to susan . 这句话中tom是给花的,花表示的是被给,susan是接收花的,每个词之前顺序不同意义也不同,如果是单个注意力会导致如果句子变为susan gave roses to tom .虽然句子的含义是完全不同的但输出是跟以前一样的,所以需要多头来对上下文进行不同角度的理解。
1.4 残差连接和 Layer Normalization
也就是将原始输入与注意力输出加起来做残差连接(随着深度网络层数的加深,带来了一系列问题,如梯度消失,梯度爆炸,模型容易过拟合,计算资源的消耗等问题,对应的也有解决方式,但随着层数的增加,之前的方法优化能力有限,可以用残差连接来进行优化)。
Layer Normalization综合考虑一层所有维度的输入,计算该层的平均输入值和输入方差,然后用同一个规范化操作来转换各个维度的输入。它的作用是把神经网络中隐藏层归一为标准正态分布,可以起到加快训练速度,缓解梯度消失/爆炸、加速训练、正则化、加速收敛的作用。
1.5 Feed-Forward
FeedForward,其实就是两层线性映射并用激活函数激活。
2. Decoder
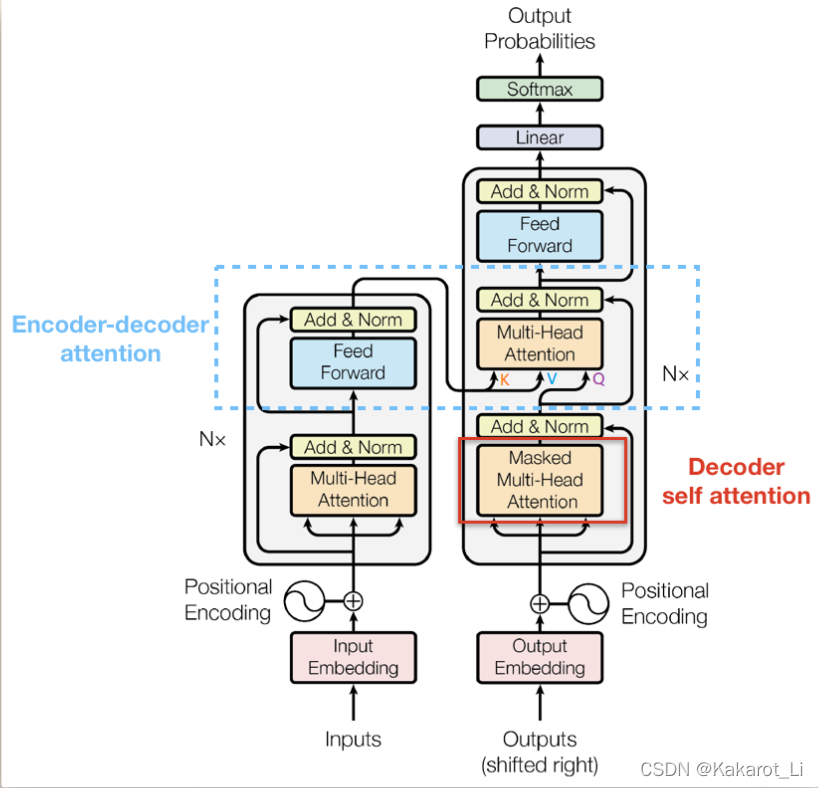
2.1 Masked Self-Attention
在seq2seq中的decoder用到的是rnn,即输出是按照时间步一个一个给出的,而transformer的是没有rnn的,这就导致输出会一次性输出所有单词,显然是不对的。
举个例子,若Decoder 的 ground truth 为 "<start> I am fine",我们将这个句子输入到 Decoder 中,经过 WordEmbedding 和 Positional Encoding 之后,将得到的矩阵做三次线性变换。然后进行 self-attention 操作,首先得到 Scaled Scores,接下来非常关键,我们要对 Scaled Scores 进行 Mask,举个例子,当我们输入 "I" 时,模型目前仅知道包括 "I" 在内之前所有字的信息,即 "<start>" 和 "I" 的信息,不应该让其知道 "I" 之后词的信息。道理很简单,我们做预测的时候是按照顺序一个字一个字的预测,怎么能这个字都没预测完,就已经知道后面字的信息了呢?Mask 非常简单,首先生成一个下三角全 0,上三角全为负无穷的矩阵,然后将其与 Scaled Scores 相加即可
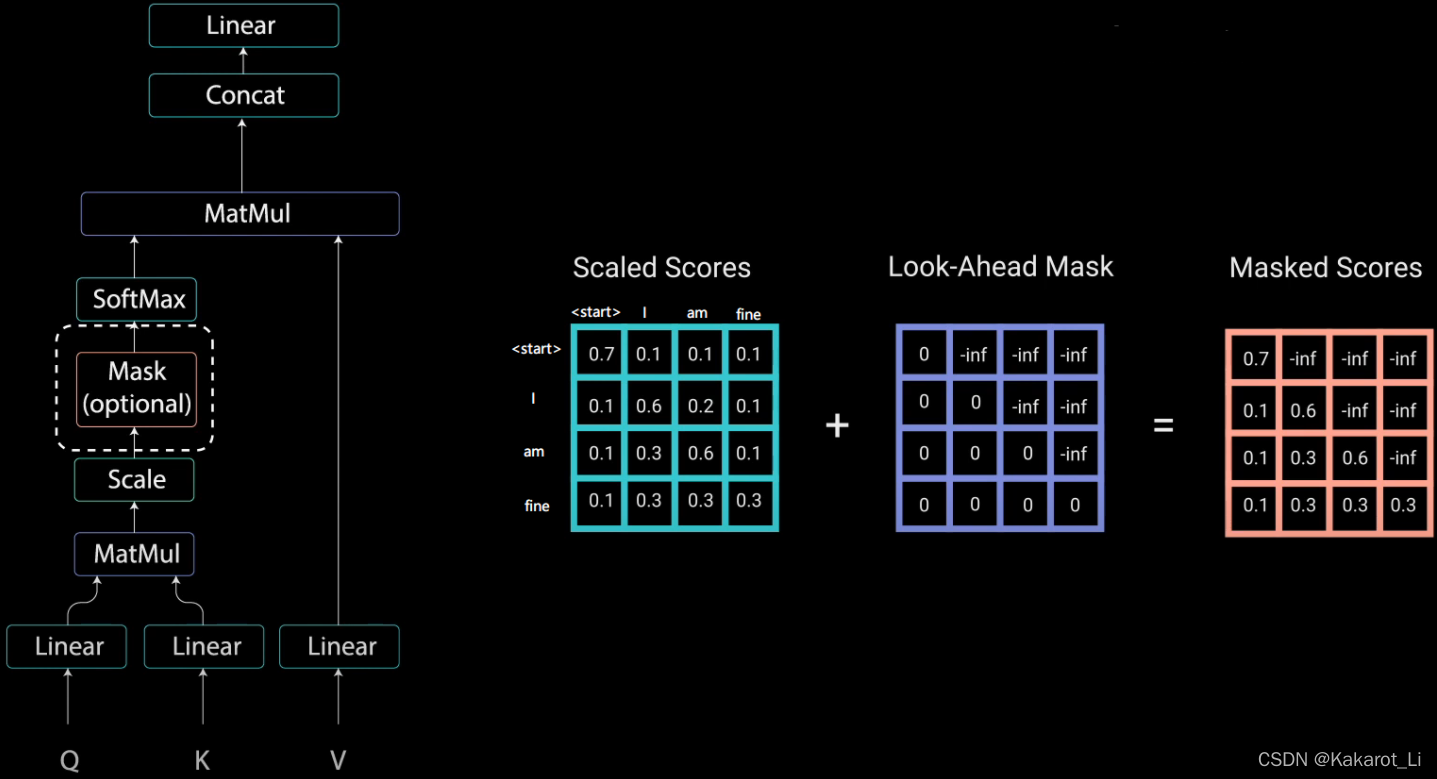
之后再做 softmax,就能将 - inf 变为 0,得到的这个矩阵即为每个字之间的权重。
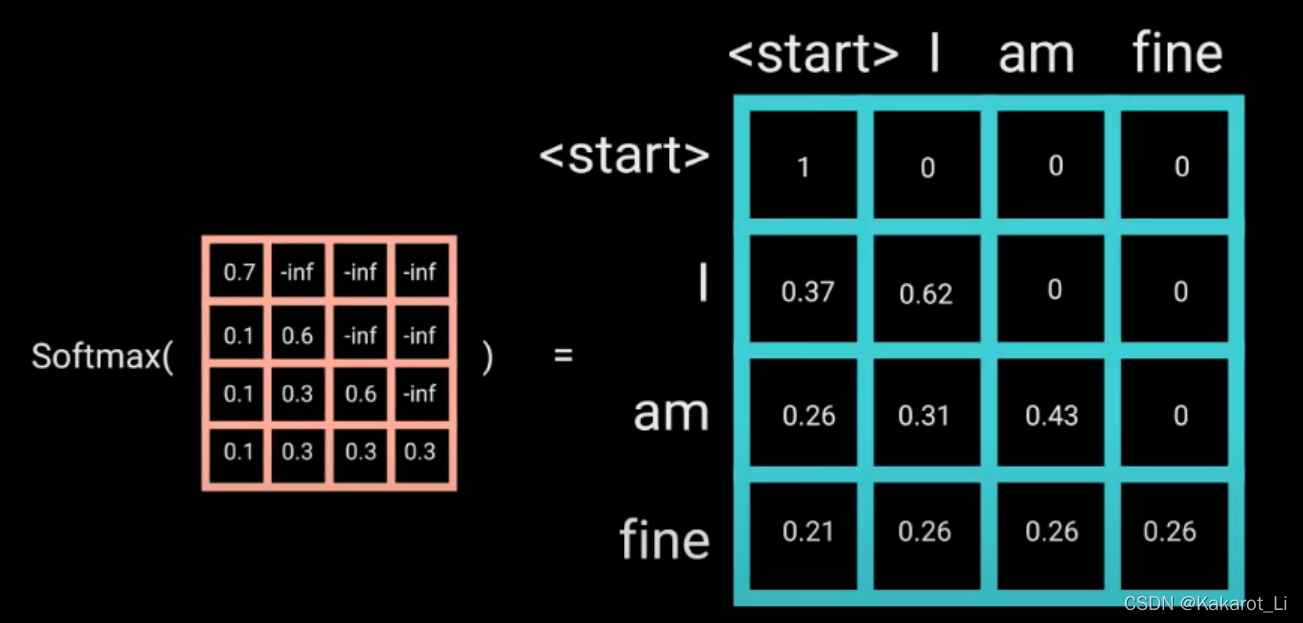
多头与encoder同理。
2.2 Multi-Head self-attention
这里需要注意的是Decoder的K和V是由Encoder来提供的,Q则是由Decoder自己提供,后面的部分与Encoder是一样的。
总结
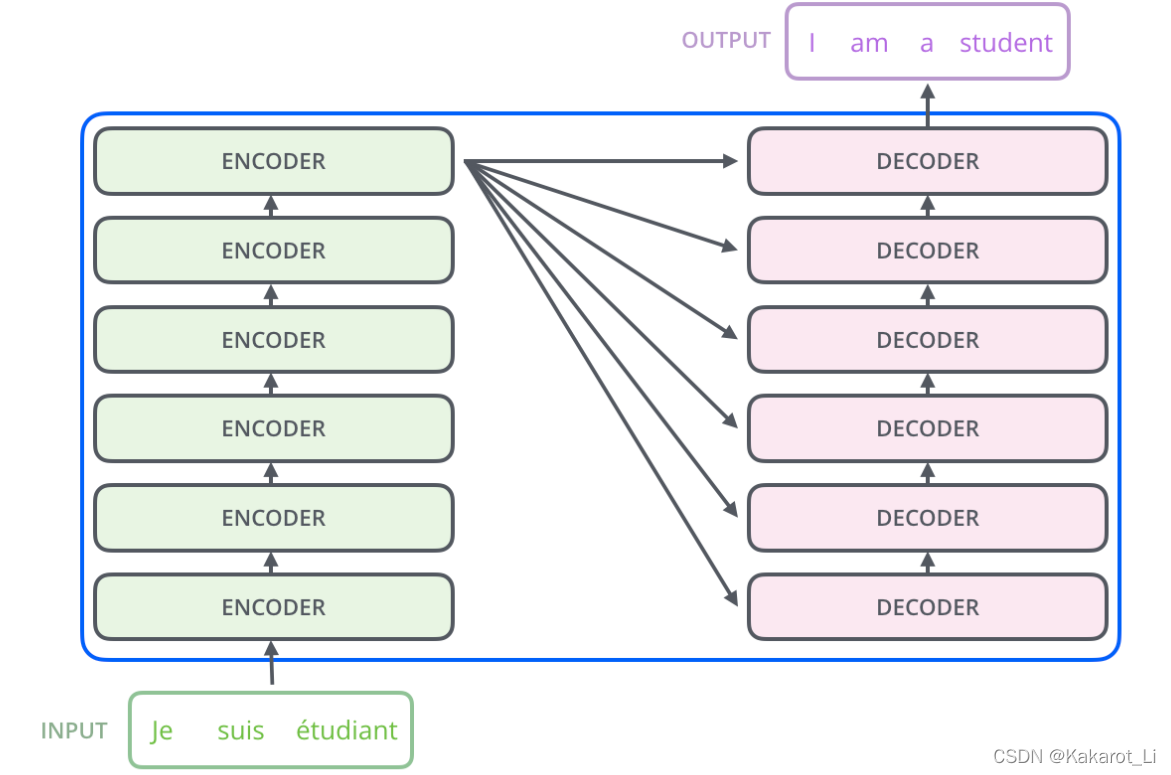
这个就是整体的流程,输入内容逐一通过每个encoder,decoder也是如此,除了每一步都需要encoder的输出做为输入。
更加详细的介绍可以看这里:Transformer详解 - mathor

















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









