






目标检测
一、YOLO系列
YOLOv1:
将图片划分为7*7网格,每个网格预测2个bbox(no_anchor) ,损失包含三部分:bounding box损失、confidence损失和classes损失。
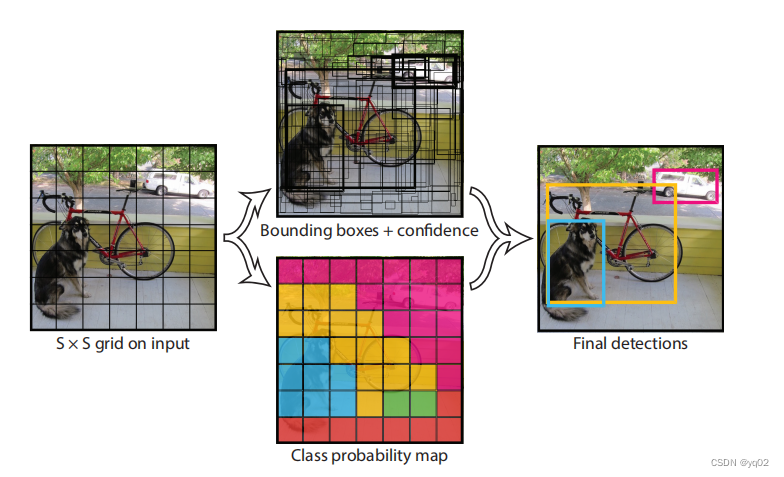
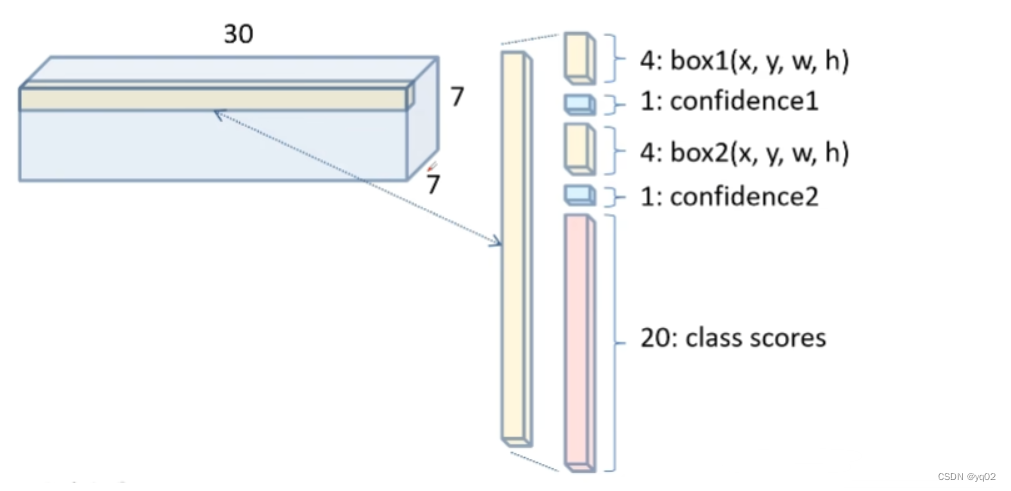
对于一个预测20个类别的网络,每个网格预测2个bounding box,每个bounding box预测包括位置(x,y,w,h)和一个置信度confidence,加上20个类别的分数。网络最后输出7x7、深度为30的特征矩阵。

YOLOV2

YOLOv2 在YOLOv1的基础上做了许多改进:
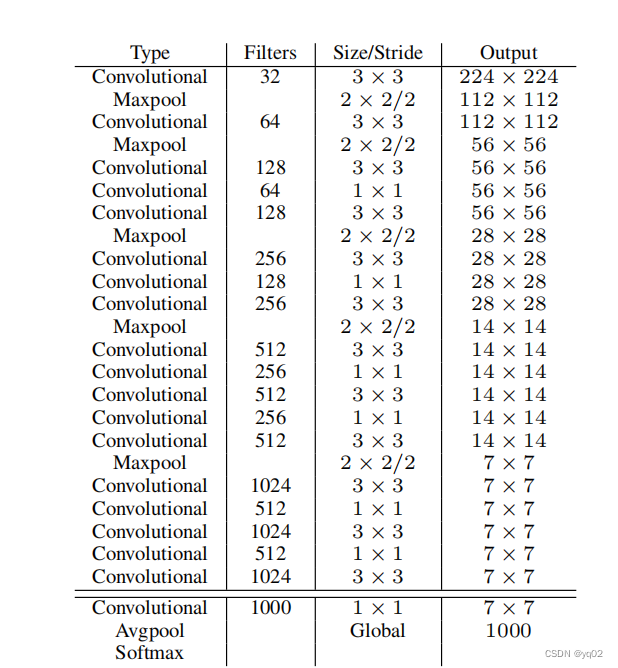
Backbone使用Darknet-19,包含19个卷积层,6个池化和一个Softmax。
Batch Normalization有助于解决反向传播过程中的梯度消失和梯度爆炸问题,降低对一些超参数(比如学习率、网络参数的大小范围、激活函数的选择)的敏感性,并且每个batch分别进行归一化的时候,起到了一定的正则化效果(YOLOv2不再使用dropout),从而能够获得更好的收敛速度和收敛效果
在YOLOv1中时直接预测边界框的中心坐标、宽度和高度的方式定位效果比较差,所以在YOLOv2中作者采用anchor进行目标框的预测,采用anchor也可以使网络更容易的去学习和收敛。
使用K-means算法聚类得到先验框。
直接是使用anchor进行预测时发现,在训练模型的时候训练不稳定,通过观察发现大部分不稳定因素来自中心坐标的预测部分导致,所以采用如下anchor预测方式。
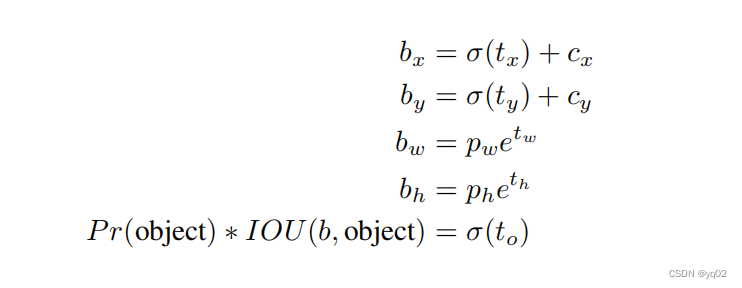
YOLOV3
YOLOv3在YOLOv2的基础上改进了Backbone.采用Darknet53作为Backbone.
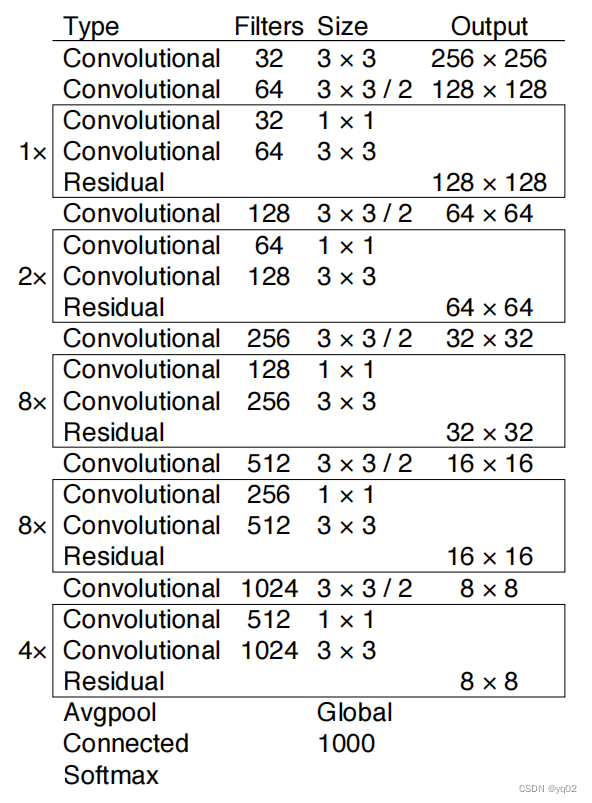
使用步长为2 的卷积层代替池化层
正负样本的匹配
针对每一个bounding box 都会分配一个bounding box prior,即针对每一个ground truth 都会分配一个正样本,一张图像中有几个ground truth就有几个正样本,分配原则其实也很简单,就是将与ground truth重合程度最大的bounding box prior作为正样本,如果与ground truth重合程度不是最大的但是又超过了某个阈值的bounding box prior,就直接丢弃,将最后剩下的样本作为负样本。
YOLOV4
-
Bag of Freebies:指的是不增加模型复杂度,也不增加推理的计算量的用来提高模型的准确度训练的方法技巧。
-
Bag-of-Specials:指的是增加少许模型复杂度或计算量,但可以显著提高模型准确度的训练技巧。
BoF指的是1)数据增强:图像几何变换(随机缩放,裁剪,旋转),Cutmix,Mosaic等 2)网络正则化:Dropout,Dropblock等 3)损失函数的设计:边界框回归的损失函数的改进 CIOUBoS指的是
1)增大模型感受野:SPP、ASPP等 2)引入注意力机制:SE、SAM 3)特征集成:PAN,BiFPN 4)激活函数改进:Swish、Mish 5)后处理方法改进:soft NMS、DIoU NMS
Backbone
采用的主干网络为 CSPDarknet53,CSPDarknet53是在Yolov3主干网络Darknet53的基础上,借鉴2019年CSPNet的经验,产生的Backbone结构,其中包含了5个CSP(跨阶段部分连接)模块。
FPN+PAN
FPN层自顶向下,将高层的特征信息通过上采样的方式进行传递融合,传达强语义特征,而PAN则自底向上传达强定位特征,提高特征提取的能力。两者从不同的主干层对不同的检测层进行参数聚合,加速了不同尺度特征的融合,进一步提高特征提取的能力。
SPP模块
采用1×1,5×5,9×9,13×13的最大池化的方式,进行多尺度融合。
IOU总结
IOU -> GIOU->DIOU->CIOU
IOU_Loss:主要考虑检测框和目标框重叠面积。
GIOU_Loss:在IOU的基础上,解决边界框不重合时的问题。
DIOU_Loss:在IOU和GIOU的基础上,考虑边界框中心点距离的信息。
CIOU_Loss:在DIOU的基础上,考虑边界框宽高比的尺度信息。
YOLOv4中采用了CIOU_Loss的回归方式,使得预测框回归的速度和精度更高一些。


















 5162
5162

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









