






- 🍨 本文為🔗365天深度學習訓練營 中的學習紀錄博客
- 🍖 原作者:K同学啊 | 接輔導、項目定制
一、前期准备
1. 导入数据
# Import the required libraries
import numpy as np
import PIL,pathlib
from PIL import Image
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers, models, Input
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Dense, Flatten, Dropout
from tqdm import tqdm
import tensorflow.keras.backend as K
from datetime import datetime
# load the data
data_dir = './data/365-7-data/'
data_dir = pathlib.Path(data_dir)
data_paths = list(data_dir.glob('*'))
classeNames = [str(path).split("\\")[2] for path in data_paths]
classeNames

2. 查看数据
image_count = len(list(data_dir.glob('*/*')))
print("图片总数为:",image_count)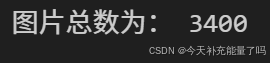
二、数据预处理
1. 加载数据
# Data loading and preprocessing
batch_size = 8
img_height = 224
img_width = 224
"""
关于image_dataset_from_directory()的详细介绍可以参考文章:https://mtyjkh.blog.youkuaiyun.com/article/details/117018789
"""
train_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="training",
seed=12,
image_size=(img_height, img_width),
batch_size=batch_size)
"""
关于image_dataset_from_directory()的详细介绍可以参考文章:https://mtyjkh.blog.youkuaiyun.com/article/details/117018789
"""
val_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="validation",
seed=12,
image_size=(img_height, img_width),
batch_size=batch_size)
class_names = train_ds.class_names
print(class_names)
2. 可视化数据
# Visualize the data
plt.figure(figsize=(15, 10))
for images, labels in train_ds.take(1):
for i in range(8):
ax = plt.subplot(5, 8, i + 1)
plt.imshow(images[i].numpy().astype("uint8"))
plt.title(class_names[np.argmax(labels[i])])
plt.axis("off")
# Check the shape of the data
for image_batch, labels_batch in train_ds:
print(image_batch.shape)
print(labels_batch.shape)
break
3. 配置数据集
AUTOTUNE = tf.data.AUTOTUNE
def preprocess_image(image,label):
return (image/255.0,label)
# Normalize the data
train_ds = train_ds.map(preprocess_image, num_parallel_calls=AUTOTUNE)
val_ds = val_ds.map(preprocess_image, num_parallel_calls=AUTOTUNE)
train_ds = train_ds.cache().shuffle(1000).prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
三、训练模型
1. 构建VGG-16网络模型
VGG优缺点分析:
- VGG优点
VGG的结构非常简洁,整个网络都使用了同样大小的卷积核尺寸(3x3)和最大池化尺寸(2x2)。
- VGG缺点
1)训练时间过长,调参难度大。2)需要的存储容量大,不利于部署。例如存储VGG-16权重值文件的大小为500多MB,不利于安装到嵌入式系统中。
结构说明:
- 13个卷积层(Convolutional Layer),分别用
blockX_convX表示
- 3个全连接层(Fully connected Layer),分别用
fcX与predictions表示
- 5个池化层(Pool layer),分别用
blockX_pool表示
VGG-16包含了16个隐藏层(13个卷积层和3个全连接层),故称为VGG-16
# Define the model
def VGG16(nb_classes, input_shape):
input_tensor = Input(shape=input_shape)
# 1st block
x = Conv2D(64, (3,3), activation='relu', padding='same',name='block1_conv1')(input_tensor)
x = Conv2D(64, (3,3), activation='relu', padding='same',name='block1_conv2')(x)
x = MaxPooling2D((2,2), strides=(2,2), name = 'block1_pool')(x)
# 2nd block
x = Conv2D(128, (3,3), activation='relu', padding='same',name='block2_conv1')(x)
x = Conv2D(128, (3,3), activation='relu', padding='same',name='block2_conv2')(x)
x = MaxPooling2D((2,2), strides=(2,2), name = 'block2_pool')(x)
# 3rd block
x = Conv2D(256, (3,3), activation='relu', padding='same',name='block3_conv1')(x)
x = Conv2D(256, (3,3), activation='relu', padding='same',name='block3_conv2')(x)
x = Conv2D(256, (3,3), activation='relu', padding='same',name='block3_conv3')(x)
x = MaxPooling2D((2,2), strides=(2,2), name = 'block3_pool')(x)
# 4th block
x = Conv2D(512, (3,3), activation='relu', padding='same',name='block4_conv1')(x)
x = Conv2D(512, (3,3), activation='relu', padding='same',name='block4_conv2')(x)
x = Conv2D(512, (3,3), activation='relu', padding='same',name='block4_conv3')(x)
x = MaxPooling2D((2,2), strides=(2,2), name = 'block4_pool')(x)
# 5th block
x = Conv2D(512, (3,3), activation='relu', padding='same',name='block5_conv1')(x)
x = Conv2D(512, (3,3), activation='relu', padding='same',name='block5_conv2')(x)
x = Conv2D(512, (3,3), activation='relu', padding='same',name='block5_conv3')(x)
x = MaxPooling2D((2,2), strides=(2,2), name = 'block5_pool')(x)
# full connection
x = Flatten()(x)
x = Dense(4096, activation='relu', name='fc1')(x)
x = Dense(4096, activation='relu', name='fc2')(x)
output_tensor = Dense(nb_classes, activation='softmax', name='predictions')(x)
model = Model(input_tensor, output_tensor)
return model
model=VGG16(1000, (img_width, img_height, 3))
model.summary()Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 224, 224, 3)] 0
block1_conv1 (Conv2D) (None, 224, 224, 64) 1792
block1_conv2 (Conv2D) (None, 224, 224, 64) 36928
block1_pool (MaxPooling2D) (None, 112, 112, 64) 0
block2_conv1 (Conv2D) (None, 112, 112, 128) 73856
block2_conv2 (Conv2D) (None, 112, 112, 128) 147584
block2_pool (MaxPooling2D) (None, 56, 56, 128) 0
block3_conv1 (Conv2D) (None, 56, 56, 256) 295168
block3_conv2 (Conv2D) (None, 56, 56, 256) 590080
block3_conv3 (Conv2D) (None, 56, 56, 256) 590080
block3_pool (MaxPooling2D) (None, 28, 28, 256) 0
block4_conv1 (Conv2D) (None, 28, 28, 512) 1180160
block4_conv2 (Conv2D) (None, 28, 28, 512) 2359808
block4_conv3 (Conv2D) (None, 28, 28, 512) 2359808
block4_pool (MaxPooling2D) (None, 14, 14, 512) 0
block5_conv1 (Conv2D) (None, 14, 14, 512) 2359808
block5_conv2 (Conv2D) (None, 14, 14, 512) 2359808
block5_conv3 (Conv2D) (None, 14, 14, 512) 2359808
block5_pool (MaxPooling2D) (None, 7, 7, 512) 0
flatten (Flatten) (None, 25088) 0
fc1 (Dense) (None, 4096) 102764544
fc2 (Dense) (None, 4096) 16781312
predictions (Dense) (None, 1000) 4097000
=================================================================
Total params: 138357544 (527.79 MB)
Trainable params: 138357544 (527.79 MB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________
2. 编译模型
model.compile(optimizer="adam",
loss ='sparse_categorical_crossentropy',
metrics =['accuracy'])
3. 训练模型
epochs = 10
lr = 1e-4
# 记录训练数据,方便后面的分析
history_train_loss = []
history_train_accuracy = []
history_val_loss = []
history_val_accuracy = []
for epoch in range(epochs):
train_total = len(train_ds)
val_total = len(val_ds)
"""
total:预期的迭代数目
ncols:控制进度条宽度
mininterval:进度更新最小间隔,以秒为单位(默认值:0.1)
"""
with tqdm(total=train_total, desc=f'Epoch {epoch + 1}/{epochs}',mininterval=1,ncols=100) as pbar:
lr = lr*0.92
K.set_value(model.optimizer.lr, lr)
for image,label in train_ds:
"""
训练模型,简单理解train_on_batch就是:它是比model.fit()更高级的一个用法
想详细了解 train_on_batch 的同学,
可以看看我的这篇文章:https://www.yuque.com/mingtian-fkmxf/hv4lcq/ztt4gy
"""
history = model.train_on_batch(image,label)
train_loss = history[0]
train_accuracy = history[1]
pbar.set_postfix({"loss": "%.4f"%train_loss,
"accuracy":"%.4f"%train_accuracy,
"lr": K.get_value(model.optimizer.lr)})
pbar.update(1)
history_train_loss.append(train_loss)
history_train_accuracy.append(train_accuracy)
print('开始验证!')
with tqdm(total=val_total, desc=f'Epoch {epoch + 1}/{epochs}',mininterval=0.3,ncols=100) as pbar:
for image,label in val_ds:
history = model.test_on_batch(image,label)
val_loss = history[0]
val_accuracy = history[1]
pbar.set_postfix({"loss": "%.4f"%val_loss,
"accuracy":"%.4f"%val_accuracy})
pbar.update(1)
history_val_loss.append(val_loss)
history_val_accuracy.append(val_accuracy)
print('结束验证!')
print("验证loss为:%.4f"%val_loss)
print("验证准确率为:%.4f"%val_accuracy)结束验证!
验证loss为:0.6983
验证准确率为:0.6250
Epoch 2/10: 100%|███████| 340/340 [59:46<00:00, 10.55s/it, loss=0.6899, accuracy=0.7500, lr=8.46e-5]
开始验证!
Epoch 2/10: 100%|█████████████████████| 85/85 [03:52<00:00, 2.73s/it, loss=0.5358, accuracy=0.8750]
结束验证!
验证loss为:0.5358
验证准确率为:0.8750
Epoch 3/10: 100%|███████| 340/340 [59:18<00:00, 10.47s/it, loss=0.1574, accuracy=0.8750, lr=7.79e-5]
开始验证!
Epoch 3/10: 100%|█████████████████████| 85/85 [03:43<00:00, 2.63s/it, loss=0.1224, accuracy=1.0000]
结束验证!
验证loss为:0.1224
验证准确率为:1.0000
Epoch 4/10: 100%|███████| 340/340 [59:20<00:00, 10.47s/it, loss=0.0489, accuracy=1.0000, lr=7.16e-5]
开始验证!
Epoch 4/10: 100%|█████████████████████| 85/85 [03:45<00:00, 2.65s/it, loss=0.0128, accuracy=1.0000]
结束验证!
验证loss为:0.0128
验证准确率为:1.0000
Epoch 5/10: 100%|█████| 340/340 [1:00:16<00:00, 10.64s/it, loss=0.0108, accuracy=1.0000, lr=6.59e-5]
开始验证!
Epoch 5/10: 100%|█████████████████████| 85/85 [03:59<00:00, 2.82s/it, loss=0.0025, accuracy=1.0000]
结束验证!
验证loss为:0.0025
验证准确率为:1.0000
Epoch 6/10: 100%|█████| 340/340 [1:01:55<00:00, 10.93s/it, loss=0.0179, accuracy=1.0000, lr=6.06e-5]
开始验证!
Epoch 6/10: 100%|█████████████████████| 85/85 [04:09<00:00, 2.94s/it, loss=0.0350, accuracy=1.0000]
结束验证!
验证loss为:0.0350
验证准确率为:1.0000
Epoch 7/10: 100%|█████| 340/340 [1:05:16<00:00, 11.52s/it, loss=0.0148, accuracy=1.0000, lr=5.58e-5]
开始验证!
Epoch 7/10: 100%|█████████████████████| 85/85 [04:04<00:00, 2.87s/it, loss=0.0038, accuracy=1.0000]
结束验证!
验证loss为:0.0038
验证准确率为:1.0000
Epoch 8/10: 100%|█████| 340/340 [1:04:58<00:00, 11.47s/it, loss=0.0001, accuracy=1.0000, lr=5.13e-5]
开始验证!
Epoch 8/10: 100%|█████████████████████| 85/85 [04:25<00:00, 3.12s/it, loss=0.0061, accuracy=1.0000]
结束验证!
验证loss为:0.0061
验证准确率为:1.0000
Epoch 9/10: 100%|█████| 340/340 [1:04:31<00:00, 11.39s/it, loss=0.4471, accuracy=0.8750, lr=4.72e-5]
开始验证!
Epoch 9/10: 100%|█████████████████████| 85/85 [03:53<00:00, 2.75s/it, loss=0.0003, accuracy=1.0000]
结束验证!
验证loss为:0.0003
验证准确率为:1.0000
Epoch 10/10: 100%|████| 340/340 [1:01:31<00:00, 10.86s/it, loss=0.1917, accuracy=0.8750, lr=4.34e-5]
开始验证!
Epoch 10/10: 100%|██████████████████| 85/85 [1:30:36<00:00, 63.96s/it, loss=0.0221, accuracy=1.0000]结束验证!
验证loss为:0.0221
验证准确率为:1.0000四、模型评估
1. Loss与Accuracy图
urrent_time = datetime.now() # 获取当前时间
epochs_range = range(epochs)
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, history_train_accuracy, label='Training Accuracy')
plt.plot(epochs_range, history_val_accuracy, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.xlabel(current_time) # 打卡请带上时间戳,否则代码截图无效
plt.subplot(1, 2, 2)
plt.plot(epochs_range, history_train_loss, label='Training Loss')
plt.plot(epochs_range, history_val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()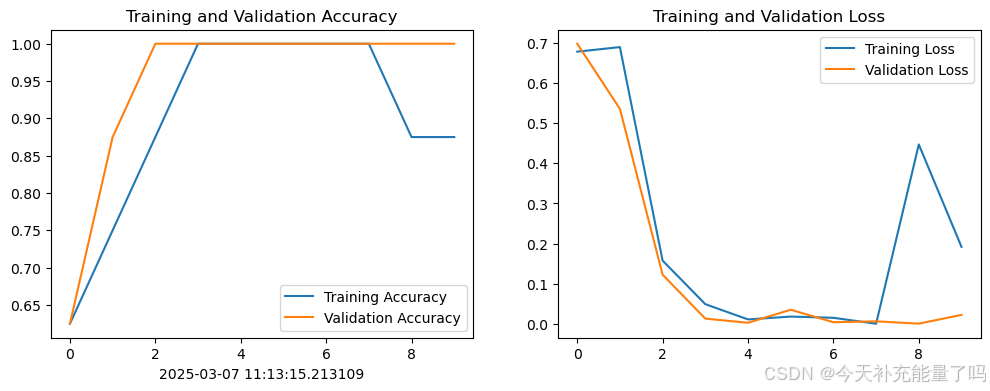
2. 预测
# 采用加载的模型(new_model)来看预测结果
plt.figure(figsize=(18, 3)) # 图形的宽为18高为5
plt.suptitle("预测结果展示")
for images, labels in val_ds.take(1):
for i in range(8):
ax = plt.subplot(1,8, i + 1)
# 显示图片
plt.imshow(images[i].numpy())
# 需要给图片增加一个维度
img_array = tf.expand_dims(images[i], 0)
# 使用模型预测图片中的人物
predictions = model.predict(img_array)
plt.title(class_names[np.argmax(predictions)])
plt.axis("off")

五、Bug修改
之前的代码中有几处需要修改的地方:
1. Class数量
在调用VGG时,class数量设为了1000,可能会导致模型很难收敛,应改为
model=VGG16(len(class_names), (img_width, img_height, 3))2. Learning Update
Learning rate decay在更新时函数没有被正确调用,应改为
K.set_value(model.optimizer.learning_rate, lr)3. 预测结果返回
model.predict(img_array) 总是返回 (batch_size, num_classes),必须使用 predictions[0] 取出第一张图片的预测结果,应该修改为
plt.title(class_names[np.argmax(predictions[0])]) # 取第一个 batch 元素
















 1151
1151

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









