






- 🍨 本文為🔗365天深度學習訓練營 中的學習紀錄博客
- 🍖 原作者:K同学啊 | 接輔導、項目定制
一、前期准备
1. 导入数据
# load the data
data_dir = './data/46-data/'
data_dir = pathlib.Path(data_dir)
data_paths = list(data_dir.glob('*'))
classeNames = [str(path).split("\\")[2] for path in data_paths]
classeNames![]()
2. 查看数据
image_count = len(list(data_dir.glob('*/*/*.jpg')))
print("图片总数为:",image_count)![]()
shoes = list(data_dir.glob('train/nike/*.jpg'))
PIL.Image.open(str(shoes[0]))

二、数据预处理
1. 加载数据
# Data loading and preprocessing
batch_size = 32
img_height = 224
img_width = 224
"""
关于image_dataset_from_directory()的详细介绍可以参考文章:https://mtyjkh.blog.youkuaiyun.com/article/details/117018789
"""
train_ds = tf.keras.preprocessing.image_dataset_from_directory(
'./data/46-data/train',
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)![]()
val_ds = tf.keras.preprocessing.image_dataset_from_directory(
'./data/46-data/test',
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)![]()
class_names = train_ds.class_names
print(class_names)
![]()
2. 可视化数据
# Visualize the data
plt.figure(figsize=(20, 10))
for images, labels in train_ds.take(1): # take()方法用于从数据集中取出一批数据
for i in range(20):
ax = plt.subplot(5, 10, i + 1)
plt.imshow(images[i].numpy().astype("uint8"))
plt.title(class_names[labels[i]])
plt.axis("off")
# Check the shape of the data
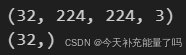
for image_batch, labels_batch in train_ds:
print(image_batch.shape)
print(labels_batch.shape)
break
3. 配置数据集
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().shuffle(1000).prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)三、训练模型
1. 构建CNN网络模型
model = models.Sequential([
layers.experimental.preprocessing.Rescaling(1./255, input_shape=(img_height, img_width, 3)),
layers.Conv2D(16, (3, 3), activation='relu', input_shape=(img_height, img_width, 3)), # 卷积层1,卷积核3*3
layers.AveragePooling2D((2, 2)), # 池化层1,2*2采样
layers.Conv2D(32, (3, 3), activation='relu'), # 卷积层2,卷积核3*3
layers.AveragePooling2D((2, 2)), # 池化层2,2*2采样
layers.Dropout(0.3),
layers.Conv2D(64, (3, 3), activation='relu'), # 卷积层3,卷积核3*3
layers.Dropout(0.3),
layers.Flatten(), # Flatten层,连接卷积层与全连接层
layers.Dense(128, activation='relu'), # 全连接层,特征进一步提取
layers.Dense(len(class_names)) # 输出层,输出预期结果
])
model.summary() # 打印网络结构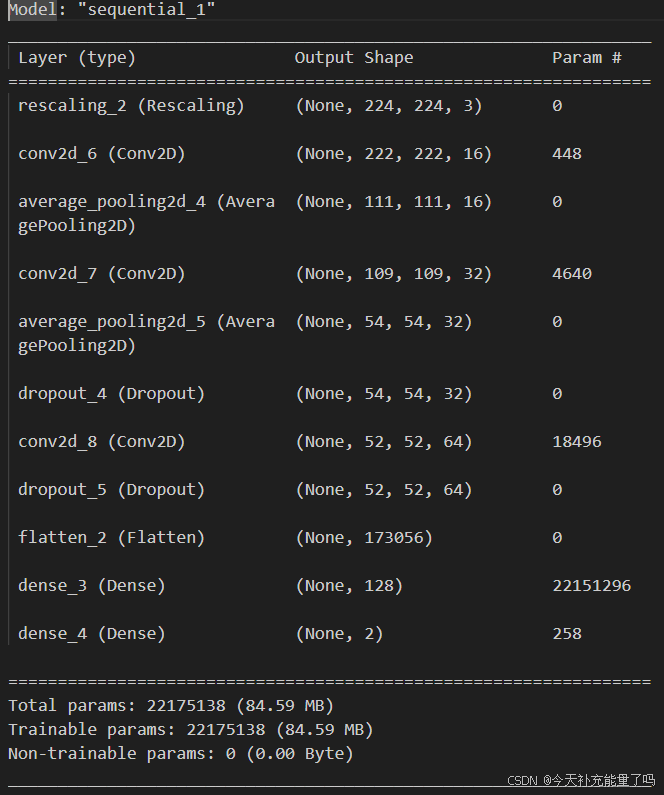
2. 设置动态学习率
📮 ExponentialDecay函数:
tf.keras.optimizers.schedules.ExponentialDecay是 TensorFlow 中的一个学习率衰减策略,用于在训练神经网络时动态地降低学习率。学习率衰减是一种常用的技巧,可以帮助优化算法更有效地收敛到全局最小值,从而提高模型的性能。🔎 主要参数:
- initial_learning_rate(初始学习率):初始学习率大小。
- decay_steps(衰减步数):学习率衰减的步数。在经过 decay_steps 步后,学习率将按照指数函数衰减。例如,如果 decay_steps 设置为 10,则每10步衰减一次。
- decay_rate(衰减率):学习率的衰减率。它决定了学习率如何衰减。通常,取值在 0 到 1 之间。
- staircase(阶梯式衰减):一个布尔值,控制学习率的衰减方式。如果设置为 True,则学习率在每个 decay_steps 步之后直接减小,形成阶梯状下降。如果设置为 False,则学习率将连续衰减。
# 设置初始学习率
initial_learning_rate = 0.1
lr_schedule = tf.keras.optimizers.schedules.ExponentialDecay(
initial_learning_rate,
decay_steps=10, # 敲黑板!!!这里是指 steps,不是指epochs
decay_rate=0.92, # lr经过一次衰减就会变成 decay_rate*lr
staircase=True)
# 将指数衰减学习率送入优化器
optimizer = tf.keras.optimizers.Adam(learning_rate=lr_schedule)
model.compile(optimizer=optimizer,
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])学习率大与学习率小的优缺点分析:
学习率大
- 优点:1、加快学习速率。
- 2、有助于跳出局部最优值。
- 缺点:
- 1、导致模型训练不收敛。
- 2、单单使用大学习率容易导致模型不精确。
学习率小
- 优点:
- 1、有助于模型收敛、模型细化。
- 2、提高模型精度。
- 缺点:
- 1、很难跳出局部最优值。
- 2、收敛缓慢。
3.早停与保存最佳模型参数
EarlyStopping()参数说明:
monitor: 被监测的数据。
min_delta: 在被监测的数据中被认为是提升的最小变化, 例如,小于 min_delta 的绝对变化会被认为没有提升。
patience: 没有进步的训练轮数,在这之后训练就会被停止。
verbose: 详细信息模式。
mode: {auto, min, max} 其中之一。 在 min 模式中, 当被监测的数据停止下降,训练就会停止;在 max 模式中,当被监测的数据停止上升,训练就会停止;在 auto 模式中,方向会自动从被监测的数据的名字中判断出来。
baseline: 要监控的数量的基准值。 如果模型没有显示基准的改善,训练将停止。
estore_best_weights: 是否从具有监测数量的最佳值的时期恢复模型权重。 如果为 False,则使用在训练的最后一步获得的模型权重。
epochs = 50
# 保存最佳模型参数
checkpointer = ModelCheckpoint('best_model.h5',
monitor='val_accuracy',
verbose=1,
save_best_only=True,
save_weights_only=True)
# 设置早停
earlystopper = EarlyStopping(monitor='val_accuracy',
min_delta=0.001,
patience=20,
verbose=1)4. 模型训练
history = model.fit(train_ds,
validation_data=val_ds,
epochs=epochs,
callbacks=[checkpointer, earlystopper])Epoch 1/50
16/16 [==============================] - ETA: 0s - loss: 31799.8164 - accuracy: 0.5239
Epoch 1: val_accuracy improved from -inf to 0.50000, saving model to best_model.h5
16/16 [==============================] - 21s 1s/step - loss: 31799.8164 - accuracy: 0.5239 - val_loss: 0.6935 - val_accuracy: 0.5000
Epoch 2/50
16/16 [==============================] - ETA: 0s - loss: 0.7005 - accuracy: 0.4801
Epoch 2: val_accuracy did not improve from 0.50000
16/16 [==============================] - 17s 1s/step - loss: 0.7005 - accuracy: 0.4801 - val_loss: 0.7035 - val_accuracy: 0.5000
Epoch 3/50
16/16 [==============================] - ETA: 0s - loss: 0.6982 - accuracy: 0.5040
Epoch 3: val_accuracy did not improve from 0.50000
16/16 [==============================] - 21s 1s/step - loss: 0.6982 - accuracy: 0.5040 - val_loss: 0.6957 - val_accuracy: 0.5000
Epoch 4/50
16/16 [==============================] - ETA: 0s - loss: 0.6992 - accuracy: 0.4841
Epoch 4: val_accuracy did not improve from 0.50000
16/16 [==============================] - 21s 1s/step - loss: 0.6992 - accuracy: 0.4841 - val_loss: 0.6942 - val_accuracy: 0.5000
Epoch 5/50
16/16 [==============================] - ETA: 0s - loss: 0.6992 - accuracy: 0.5120
Epoch 5: val_accuracy did not improve from 0.50000
16/16 [==============================] - 21s 1s/step - loss: 0.6992 - accuracy: 0.5120 - val_loss: 0.6991 - val_accuracy: 0.5000
Epoch 6/50
16/16 [==============================] - ETA: 0s - loss: 0.7017 - accuracy: 0.4363
Epoch 6: val_accuracy did not improve from 0.50000
16/16 [==============================] - 26s 2s/step - loss: 0.7017 - accuracy: 0.4363 - val_loss: 0.6937 - val_accuracy: 0.5000
Epoch 7/50
16/16 [==============================] - ETA: 0s - loss: 0.6970 - accuracy: 0.4761
Epoch 7: val_accuracy did not improve from 0.50000
16/16 [==============================] - 35s 2s/step - loss: 0.6970 - accuracy: 0.4761 - val_loss: 0.6952 - val_accuracy: 0.5000
Epoch 8/50
16/16 [==============================] - ETA: 0s - loss: 0.6957 - accuracy: 0.4641
Epoch 8: val_accuracy did not improve from 0.50000
16/16 [==============================] - 31s 2s/step - loss: 0.6957 - accuracy: 0.4641 - val_loss: 0.6934 - val_accuracy: 0.5000
Epoch 9/50
16/16 [==============================] - ETA: 0s - loss: 0.6942 - accuracy: 0.4920
Epoch 9: val_accuracy did not improve from 0.50000
16/16 [==============================] - 27s 2s/step - loss: 0.6942 - accuracy: 0.4920 - val_loss: 0.6933 - val_accuracy: 0.5000
Epoch 10/50
16/16 [==============================] - ETA: 0s - loss: 0.6958 - accuracy: 0.4841
Epoch 10: val_accuracy did not improve from 0.50000
16/16 [==============================] - 24s 1s/step - loss: 0.6958 - accuracy: 0.4841 - val_loss: 0.6932 - val_accuracy: 0.5000
Epoch 11/50
16/16 [==============================] - ETA: 0s - loss: 0.6962 - accuracy: 0.4562
Epoch 11: val_accuracy did not improve from 0.50000
16/16 [==============================] - 21s 1s/step - loss: 0.6962 - accuracy: 0.4562 - val_loss: 0.6932 - val_accuracy: 0.5000
Epoch 12/50
16/16 [==============================] - ETA: 0s - loss: 0.6960 - accuracy: 0.4920
Epoch 12: val_accuracy did not improve from 0.50000
16/16 [==============================] - 23s 1s/step - loss: 0.6960 - accuracy: 0.4920 - val_loss: 0.6940 - val_accuracy: 0.5000
Epoch 13/50
16/16 [==============================] - ETA: 0s - loss: 0.6928 - accuracy: 0.5120
Epoch 13: val_accuracy did not improve from 0.50000
16/16 [==============================] - 27s 2s/step - loss: 0.6928 - accuracy: 0.5120 - val_loss: 0.6934 - val_accuracy: 0.5000
Epoch 14/50
16/16 [==============================] - ETA: 0s - loss: 0.6944 - accuracy: 0.5000
Epoch 14: val_accuracy did not improve from 0.50000
16/16 [==============================] - 27s 2s/step - loss: 0.6944 - accuracy: 0.5000 - val_loss: 0.6934 - val_accuracy: 0.5000
Epoch 15/50
16/16 [==============================] - ETA: 0s - loss: 0.6934 - accuracy: 0.5000
Epoch 15: val_accuracy did not improve from 0.50000
16/16 [==============================] - 24s 1s/step - loss: 0.6934 - accuracy: 0.5000 - val_loss: 0.6932 - val_accuracy: 0.5000
Epoch 16/50
16/16 [==============================] - ETA: 0s - loss: 0.6982 - accuracy: 0.5000
Epoch 16: val_accuracy did not improve from 0.50000
16/16 [==============================] - 20s 1s/step - loss: 0.6982 - accuracy: 0.5000 - val_loss: 0.6940 - val_accuracy: 0.5000
Epoch 17/50
16/16 [==============================] - ETA: 0s - loss: 0.6958 - accuracy: 0.4681
Epoch 17: val_accuracy did not improve from 0.50000
16/16 [==============================] - 21s 1s/step - loss: 0.6958 - accuracy: 0.4681 - val_loss: 0.6935 - val_accuracy: 0.5000
Epoch 18/50
16/16 [==============================] - ETA: 0s - loss: 0.6937 - accuracy: 0.5000
Epoch 18: val_accuracy did not improve from 0.50000
16/16 [==============================] - 23s 1s/step - loss: 0.6937 - accuracy: 0.5000 - val_loss: 0.6933 - val_accuracy: 0.5000
Epoch 19/50
16/16 [==============================] - ETA: 0s - loss: 0.6939 - accuracy: 0.4880
Epoch 19: val_accuracy did not improve from 0.50000
16/16 [==============================] - 32s 2s/step - loss: 0.6939 - accuracy: 0.4880 - val_loss: 0.6932 - val_accuracy: 0.5000
Epoch 20/50
16/16 [==============================] - ETA: 0s - loss: 0.6938 - accuracy: 0.5000
Epoch 20: val_accuracy did not improve from 0.50000
16/16 [==============================] - 30s 2s/step - loss: 0.6938 - accuracy: 0.5000 - val_loss: 0.6931 - val_accuracy: 0.5000
Epoch 21/50
16/16 [==============================] - ETA: 0s - loss: 0.6936 - accuracy: 0.4960
Epoch 21: val_accuracy did not improve from 0.50000
16/16 [==============================] - 22s 1s/step - loss: 0.6936 - accuracy: 0.4960 - val_loss: 0.6932 - val_accuracy: 0.5000
Epoch 21: early stopping
四、模型评估
1. Loss与Accuracy图
# Evaluate the model
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(len(loss))
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()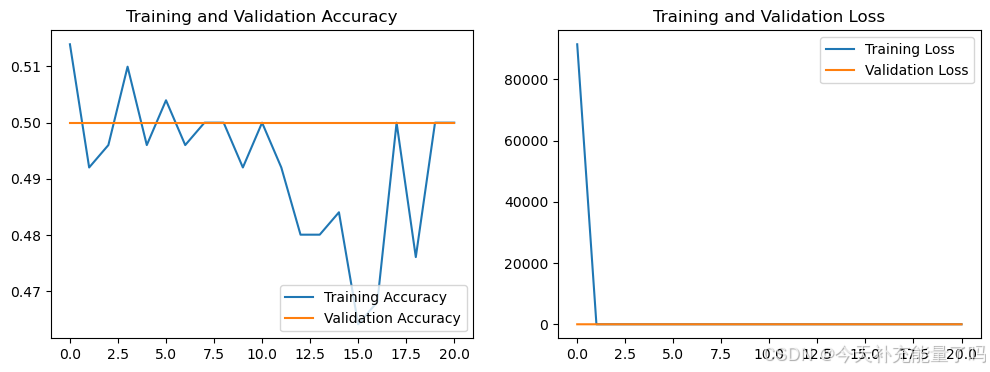
2. 指定图片进行预测
# 加载效果最好的模型权重
model.load_weights('best_model.h5')
img = Image.open("./data/46-data/test/nike/1.jpg") #这里选择你需要预测的图片
image = tf.image.resize(img, [img_height, img_width])
img_array = tf.expand_dims(image, 0)
predictions = model.predict(img_array) # 这里选用你已经训练好的模型
print("预测结果为:",class_names[np.argmax(predictions)])
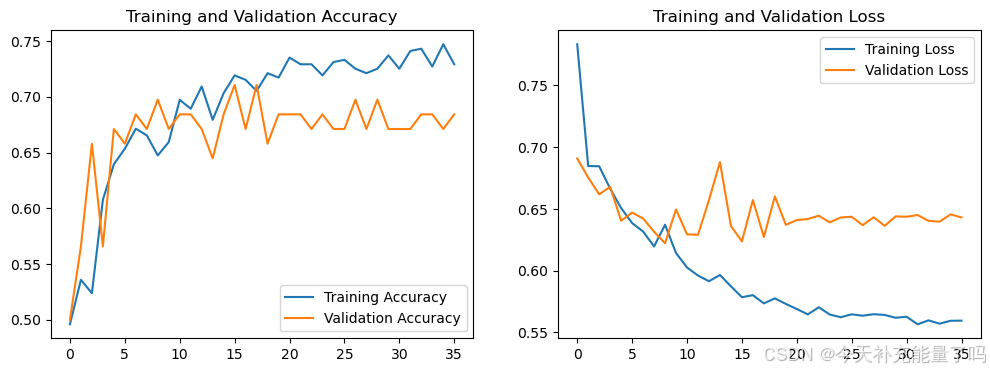
3. 优化初始学习率
initial_learning_rate = 1e-4Epoch 1/50
16/16 [==============================] - ETA: 0s - loss: 0.7834 - accuracy: 0.4960
Epoch 1: val_accuracy improved from -inf to 0.50000, saving model to best_model.h5
16/16 [==============================] - 21s 1s/step - loss: 0.7834 - accuracy: 0.4960 - val_loss: 0.6909 - val_accuracy: 0.5000
Epoch 2/50
16/16 [==============================] - ETA: 0s - loss: 0.6848 - accuracy: 0.5359
Epoch 2: val_accuracy improved from 0.50000 to 0.56579, saving model to best_model.h5
16/16 [==============================] - 24s 2s/step - loss: 0.6848 - accuracy: 0.5359 - val_loss: 0.6755 - val_accuracy: 0.5658
Epoch 3/50
16/16 [==============================] - ETA: 0s - loss: 0.6846 - accuracy: 0.5239
Epoch 3: val_accuracy improved from 0.56579 to 0.65789, saving model to best_model.h5
16/16 [==============================] - 28s 2s/step - loss: 0.6846 - accuracy: 0.5239 - val_loss: 0.6619 - val_accuracy: 0.6579
Epoch 4/50
16/16 [==============================] - ETA: 0s - loss: 0.6665 - accuracy: 0.6076
Epoch 4: val_accuracy did not improve from 0.65789
16/16 [==============================] - 37s 2s/step - loss: 0.6665 - accuracy: 0.6076 - val_loss: 0.6680 - val_accuracy: 0.5658
Epoch 5/50
16/16 [==============================] - ETA: 0s - loss: 0.6508 - accuracy: 0.6394
Epoch 5: val_accuracy improved from 0.65789 to 0.67105, saving model to best_model.h5
16/16 [==============================] - 38s 2s/step - loss: 0.6508 - accuracy: 0.6394 - val_loss: 0.6405 - val_accuracy: 0.6711
Epoch 6/50
16/16 [==============================] - ETA: 0s - loss: 0.6386 - accuracy: 0.6534
Epoch 6: val_accuracy did not improve from 0.67105
16/16 [==============================] - 35s 2s/step - loss: 0.6386 - accuracy: 0.6534 - val_loss: 0.6471 - val_accuracy: 0.6579
Epoch 7/50
16/16 [==============================] - ETA: 0s - loss: 0.6318 - accuracy: 0.6713
Epoch 7: val_accuracy improved from 0.67105 to 0.68421, saving model to best_model.h5
16/16 [==============================] - 37s 2s/step - loss: 0.6318 - accuracy: 0.6713 - val_loss: 0.6423 - val_accuracy: 0.6842
Epoch 8/50
16/16 [==============================] - ETA: 0s - loss: 0.6197 - accuracy: 0.6653
Epoch 8: val_accuracy did not improve from 0.68421
16/16 [==============================] - 30s 2s/step - loss: 0.6197 - accuracy: 0.6653 - val_loss: 0.6316 - val_accuracy: 0.6711
Epoch 9/50
16/16 [==============================] - ETA: 0s - loss: 0.6372 - accuracy: 0.6474
Epoch 9: val_accuracy improved from 0.68421 to 0.69737, saving model to best_model.h5
16/16 [==============================] - 26s 2s/step - loss: 0.6372 - accuracy: 0.6474 - val_loss: 0.6222 - val_accuracy: 0.6974
Epoch 10/50
16/16 [==============================] - ETA: 0s - loss: 0.6143 - accuracy: 0.6594
Epoch 10: val_accuracy did not improve from 0.69737
16/16 [==============================] - 31s 2s/step - loss: 0.6143 - accuracy: 0.6594 - val_loss: 0.6497 - val_accuracy: 0.6711
Epoch 11/50
16/16 [==============================] - ETA: 0s - loss: 0.6027 - accuracy: 0.6972
Epoch 11: val_accuracy did not improve from 0.69737
16/16 [==============================] - 36s 2s/step - loss: 0.6027 - accuracy: 0.6972 - val_loss: 0.6295 - val_accuracy: 0.6842
Epoch 12/50
16/16 [==============================] - ETA: 0s - loss: 0.5961 - accuracy: 0.6892
Epoch 12: val_accuracy did not improve from 0.69737
16/16 [==============================] - 38s 2s/step - loss: 0.5961 - accuracy: 0.6892 - val_loss: 0.6291 - val_accuracy: 0.6842
Epoch 13/50
16/16 [==============================] - ETA: 0s - loss: 0.5915 - accuracy: 0.7092
Epoch 13: val_accuracy did not improve from 0.69737
16/16 [==============================] - 32s 2s/step - loss: 0.5915 - accuracy: 0.7092 - val_loss: 0.6571 - val_accuracy: 0.6711
Epoch 14/50
16/16 [==============================] - ETA: 0s - loss: 0.5966 - accuracy: 0.6793
Epoch 14: val_accuracy did not improve from 0.69737
16/16 [==============================] - 30s 2s/step - loss: 0.5966 - accuracy: 0.6793 - val_loss: 0.6880 - val_accuracy: 0.6447
Epoch 15/50
16/16 [==============================] - ETA: 0s - loss: 0.5874 - accuracy: 0.7032
Epoch 15: val_accuracy did not improve from 0.69737
16/16 [==============================] - 36s 2s/step - loss: 0.5874 - accuracy: 0.7032 - val_loss: 0.6362 - val_accuracy: 0.6842
Epoch 16/50
16/16 [==============================] - ETA: 0s - loss: 0.5786 - accuracy: 0.7191
Epoch 16: val_accuracy improved from 0.69737 to 0.71053, saving model to best_model.h5
16/16 [==============================] - 29s 2s/step - loss: 0.5786 - accuracy: 0.7191 - val_loss: 0.6238 - val_accuracy: 0.7105
Epoch 17/50
16/16 [==============================] - ETA: 0s - loss: 0.5802 - accuracy: 0.7151
Epoch 17: val_accuracy did not improve from 0.71053
16/16 [==============================] - 18s 1s/step - loss: 0.5802 - accuracy: 0.7151 - val_loss: 0.6572 - val_accuracy: 0.6711
Epoch 18/50
16/16 [==============================] - ETA: 0s - loss: 0.5736 - accuracy: 0.7052
Epoch 18: val_accuracy did not improve from 0.71053
16/16 [==============================] - 21s 1s/step - loss: 0.5736 - accuracy: 0.7052 - val_loss: 0.6273 - val_accuracy: 0.7105
Epoch 19/50
16/16 [==============================] - ETA: 0s - loss: 0.5776 - accuracy: 0.7211
Epoch 19: val_accuracy did not improve from 0.71053
16/16 [==============================] - 25s 2s/step - loss: 0.5776 - accuracy: 0.7211 - val_loss: 0.6602 - val_accuracy: 0.6579
Epoch 20/50
16/16 [==============================] - ETA: 0s - loss: 0.5731 - accuracy: 0.7171
Epoch 20: val_accuracy did not improve from 0.71053
16/16 [==============================] - 25s 2s/step - loss: 0.5731 - accuracy: 0.7171 - val_loss: 0.6372 - val_accuracy: 0.6842
Epoch 21/50
16/16 [==============================] - ETA: 0s - loss: 0.5690 - accuracy: 0.7351
Epoch 21: val_accuracy did not improve from 0.71053
16/16 [==============================] - 22s 1s/step - loss: 0.5690 - accuracy: 0.7351 - val_loss: 0.6410 - val_accuracy: 0.6842
Epoch 22/50
16/16 [==============================] - ETA: 0s - loss: 0.5647 - accuracy: 0.7291
Epoch 22: val_accuracy did not improve from 0.71053
16/16 [==============================] - 22s 1s/step - loss: 0.5647 - accuracy: 0.7291 - val_loss: 0.6418 - val_accuracy: 0.6842
Epoch 23/50
16/16 [==============================] - ETA: 0s - loss: 0.5704 - accuracy: 0.7291
Epoch 23: val_accuracy did not improve from 0.71053
16/16 [==============================] - 19s 1s/step - loss: 0.5704 - accuracy: 0.7291 - val_loss: 0.6446 - val_accuracy: 0.6711
Epoch 24/50
16/16 [==============================] - ETA: 0s - loss: 0.5646 - accuracy: 0.7191
Epoch 24: val_accuracy did not improve from 0.71053
16/16 [==============================] - 18s 1s/step - loss: 0.5646 - accuracy: 0.7191 - val_loss: 0.6392 - val_accuracy: 0.6842
Epoch 25/50
16/16 [==============================] - ETA: 0s - loss: 0.5624 - accuracy: 0.7311
Epoch 25: val_accuracy did not improve from 0.71053
16/16 [==============================] - 15s 939ms/step - loss: 0.5624 - accuracy: 0.7311 - val_loss: 0.6431 - val_accuracy: 0.6711
Epoch 26/50
16/16 [==============================] - ETA: 0s - loss: 0.5647 - accuracy: 0.7331
Epoch 26: val_accuracy did not improve from 0.71053
16/16 [==============================] - 18s 1s/step - loss: 0.5647 - accuracy: 0.7331 - val_loss: 0.6437 - val_accuracy: 0.6711
Epoch 27/50
16/16 [==============================] - ETA: 0s - loss: 0.5636 - accuracy: 0.7251
Epoch 27: val_accuracy did not improve from 0.71053
16/16 [==============================] - 22s 1s/step - loss: 0.5636 - accuracy: 0.7251 - val_loss: 0.6369 - val_accuracy: 0.6974
Epoch 28/50
16/16 [==============================] - ETA: 0s - loss: 0.5648 - accuracy: 0.7211
Epoch 28: val_accuracy did not improve from 0.71053
16/16 [==============================] - 23s 1s/step - loss: 0.5648 - accuracy: 0.7211 - val_loss: 0.6433 - val_accuracy: 0.6711
Epoch 29/50
16/16 [==============================] - ETA: 0s - loss: 0.5642 - accuracy: 0.7251
Epoch 29: val_accuracy did not improve from 0.71053
16/16 [==============================] - 23s 1s/step - loss: 0.5642 - accuracy: 0.7251 - val_loss: 0.6363 - val_accuracy: 0.6974
Epoch 30/50
16/16 [==============================] - ETA: 0s - loss: 0.5619 - accuracy: 0.7371
Epoch 30: val_accuracy did not improve from 0.71053
16/16 [==============================] - 22s 1s/step - loss: 0.5619 - accuracy: 0.7371 - val_loss: 0.6440 - val_accuracy: 0.6711
Epoch 31/50
16/16 [==============================] - ETA: 0s - loss: 0.5628 - accuracy: 0.7251
Epoch 31: val_accuracy did not improve from 0.71053
16/16 [==============================] - 20s 1s/step - loss: 0.5628 - accuracy: 0.7251 - val_loss: 0.6437 - val_accuracy: 0.6711
Epoch 32/50
16/16 [==============================] - ETA: 0s - loss: 0.5566 - accuracy: 0.7410
Epoch 32: val_accuracy did not improve from 0.71053
16/16 [==============================] - 17s 1s/step - loss: 0.5566 - accuracy: 0.7410 - val_loss: 0.6451 - val_accuracy: 0.6711
Epoch 33/50
16/16 [==============================] - ETA: 0s - loss: 0.5598 - accuracy: 0.7430
Epoch 33: val_accuracy did not improve from 0.71053
16/16 [==============================] - 16s 1s/step - loss: 0.5598 - accuracy: 0.7430 - val_loss: 0.6404 - val_accuracy: 0.6842
Epoch 34/50
16/16 [==============================] - ETA: 0s - loss: 0.5571 - accuracy: 0.7271
Epoch 34: val_accuracy did not improve from 0.71053
16/16 [==============================] - 19s 1s/step - loss: 0.5571 - accuracy: 0.7271 - val_loss: 0.6397 - val_accuracy: 0.6842
Epoch 35/50
16/16 [==============================] - ETA: 0s - loss: 0.5595 - accuracy: 0.7470
Epoch 35: val_accuracy did not improve from 0.71053
16/16 [==============================] - 22s 1s/step - loss: 0.5595 - accuracy: 0.7470 - val_loss: 0.6456 - val_accuracy: 0.6711
Epoch 36/50
16/16 [==============================] - ETA: 0s - loss: 0.5596 - accuracy: 0.7291
Epoch 36: val_accuracy did not improve from 0.71053
16/16 [==============================] - 23s 1s/step - loss: 0.5596 - accuracy: 0.7291 - val_loss: 0.6432 - val_accuracy: 0.6842
Epoch 36: early stopping


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









