







 文章介绍了TensorFlow中创建全0、全1和自定义数值的向量矩阵方法,强调了使用tf.Variable()区分需计算梯度的张量和不需要的张量的原因,以及其属性如name和trainable的作用。同时,文章还展示了张量的切片、维度变换、广播机制等基本操作。
文章介绍了TensorFlow中创建全0、全1和自定义数值的向量矩阵方法,强调了使用tf.Variable()区分需计算梯度的张量和不需要的张量的原因,以及其属性如name和trainable的作用。同时,文章还展示了张量的切片、维度变换、广播机制等基本操作。
# 全0向量矩阵
tf.zeros([2,2,2]), tf.zeros_like(a)
# 全1向量矩阵
tf.ones([2,2,2]), tf.ones_like(a)
# 全50向量矩阵
tf.fill([3,4],50)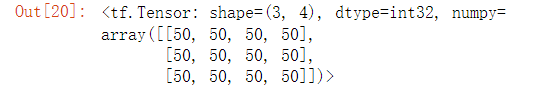
为了区分需要计算梯度信息的张量和不需要计算梯度信息的张量。tensorflow中增加了一种专门的数据类型来支持梯度信息的记录:tf.Variable()。
那么为什么要区分需要计算梯度信息的张量和不需要计算梯度信息的张量呢?由于梯度运算会消耗大量的计算资源,而且会自动更新相关参数,对于不需要优化的张量,如神经网络的输入X不需要通过tf.Variable封装;相反,需要计算梯度并优化的张量,如神经网络层的W和b,需要通过tf.Variable封装以便TensorFlow跟踪相关梯度信息。
tf.Variable()类型在普通张量类型的基础上添加了name、trainable等属性来支持计算图的构建。
name:用来命名计算图中的变量,这套命名体系是tensorflow内部维护的,一般不需要用户关注
trainable:表征当前张量是否需要被优化。创建Variable对象时默认启用优化标志,也可以设置trainable=False来设置张量不需要优化
tf.Variable()函数可以将普通张量转换为待优化的张量:
a=tf.constant([1,-5,0,5,9])aa=tf.Variable(a)aa.name,aa.trainable输出为:
('Variable:0',True)也可以直接创建Variale()张量
a=tf.Variable([[1,2],[3,4]])a输出为:
<tf.Variable'Variable:0'shape=(2,2)dtype=int32,numpy=array([[1,2],[3,4]])>待优化张量是普通张量的特殊类型,普通张量其实也可以通过GradientTape.watch()方法临时加入跟踪梯度信息的列表,从而支持自动求导功能。
参数张量
# 切片
x = tf.random.normal([2,3,3,2])
x[0]
x[0,:,:,1].shape
x# 改变维度
x=tf.range(12)
x=tf.reshape(x,[3,4])
x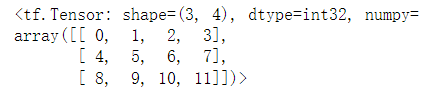
# 交换维度
x = tf.random.normal([2,32,32,3])
tf.transpose(x,perm=[0,3,1,2])# 广播机制
x = tf.random.normal([2,4])
w = tf.random.normal([4,3])
b = tf.random.normal([3])
y = x@w+b
print("x:" ,x)
print("w:" ,w)
print("b:" ,b)
print("y:" ,y)


















 438
438

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









