







 本文介绍了神经网络中的全连接层创建,数据加载与预处理,包括MNIST数据集的使用,one_hot编码,数据迭代器的构建,以及数据的打散和归一化。此外,还探讨了不同的输出方式,如激活函数的作用,以及误差计算方法,如MSE和交叉熵在损失函数中的应用。
本文介绍了神经网络中的全连接层创建,数据加载与预处理,包括MNIST数据集的使用,one_hot编码,数据迭代器的构建,以及数据的打散和归一化。此外,还探讨了不同的输出方式,如激活函数的作用,以及误差计算方法,如MSE和交叉熵在损失函数中的应用。
神经网络与全连接层
本篇博客会记录数据加载,全连接层,输出方式,误差计算的相关知识点
常用数据集及数据集加载

数据集加载:
(x,y),(x_test,y_test) = keras.datasets.mnist.load_data()
注意 此时加载进来后 y不是one_hot编码,x和y都是ndarray类型
one_hot编码:
y_onehot = tf.one_hot(y,depth=10)
depth 代表了 种类的多少onehot编码的长度
迭代器构造:
db1 = tf.data.Dataset.from_tensor_slices((x_test,y_test))
将x_test和y_test打包在一起 并且构成一个迭代器
此时 db1 每次返还一个元组 里面 0 是 x ,1 是 y
并且数据类型被转换为了 tensor
打散:
db1.shuffle(n)
将前n张图片打乱 神经网络是记录特征的网络,如果不打散
可能会导致 数据间的排序有规律 导致网络走捷径
数据处理:
def preprocess(x,y):
x = tf.cast(x,dtype=tf.float32)/255
y = y[0]
y = tf.cast(y,dtype=tf.int32)
y = tf.one_hot(y,depth=10)
return x,y
利用map
db2 = db1.map(preprocess)
对db1内的数据进行处理 如归一化 数据类型的转换
batch的构造
db3 = db2.batch(n)
将n个数据 组成一个矩阵 可以成组进行训练全连接层
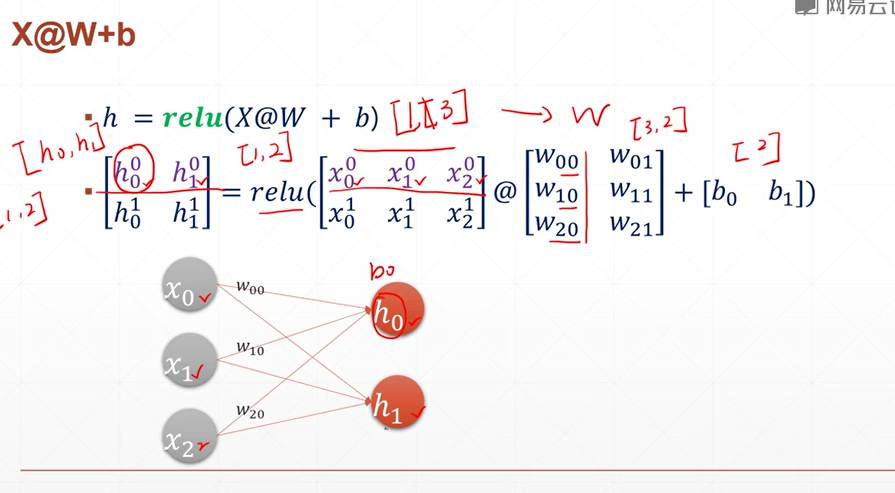
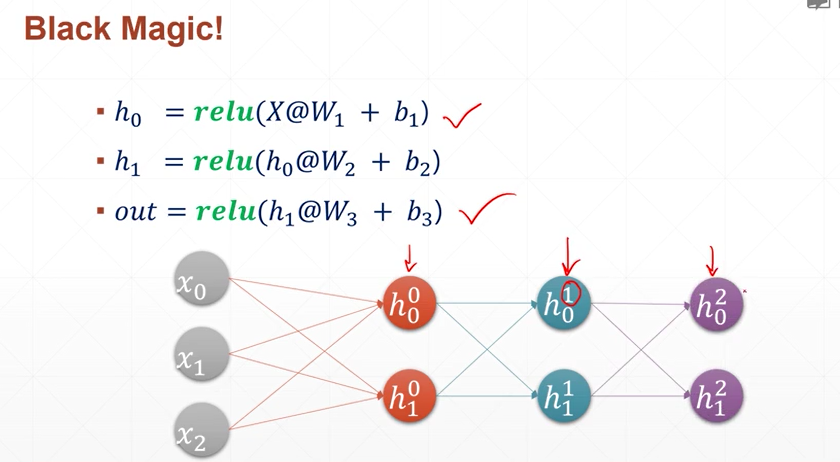
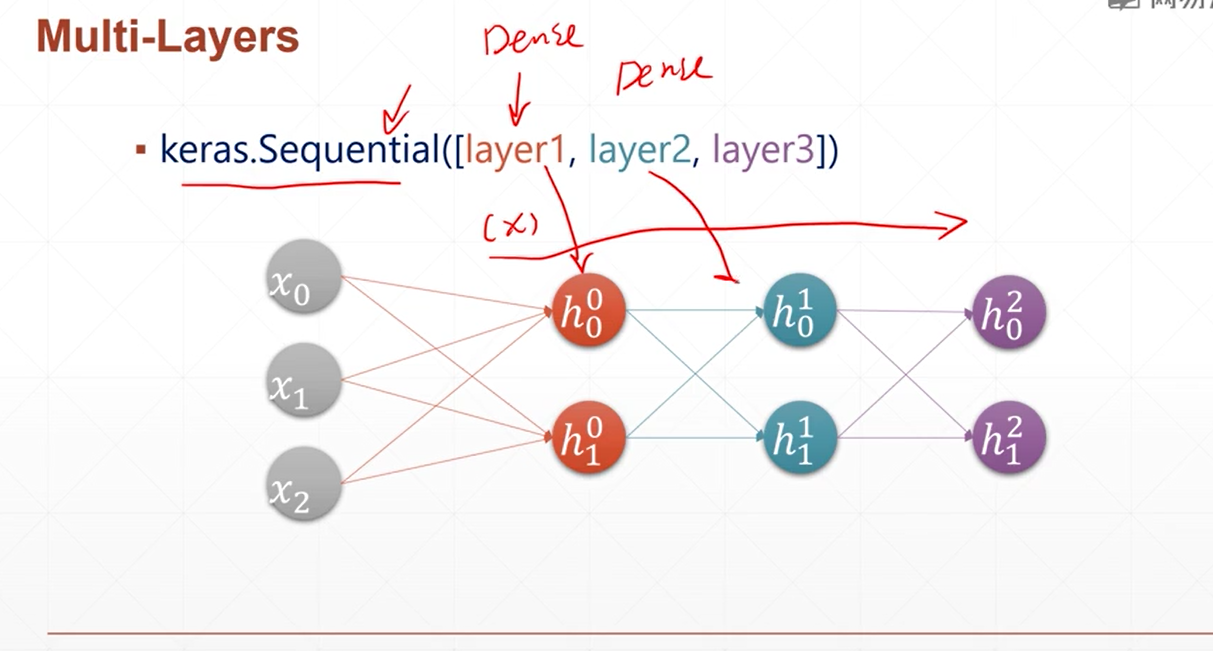
利用keras创建全连接层
model = tf.keras.Sequential()
创建一个空网络
layer1 = tf.keras.layers.Dense(n,activation="relu")
创建一个激活函数为relu的 节点为n的全连接层
model.build(input_shape=[])
设置输入的 shape
batch为32 的 28*28的图片 应该为 [32,784]
model.summary()
可以查看网络的结构
model.trainable_variables 一个网络参数的迭代器
可以循环查看网络参数的值 w,b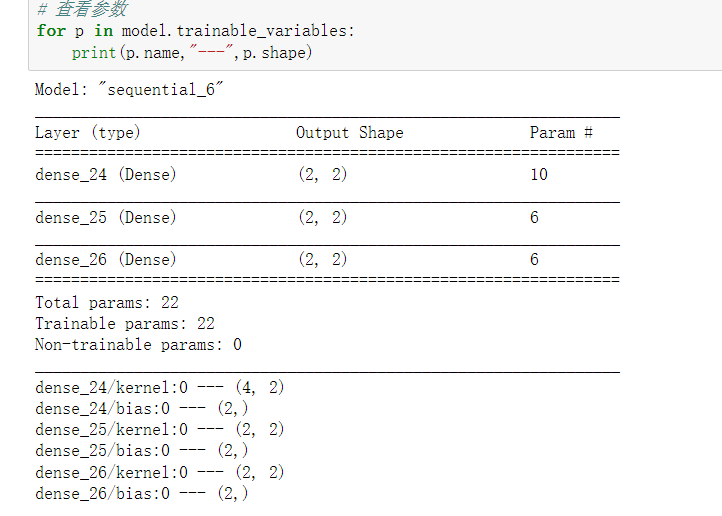
输出方式
就是各种激活函数和原始输出的联系和作用
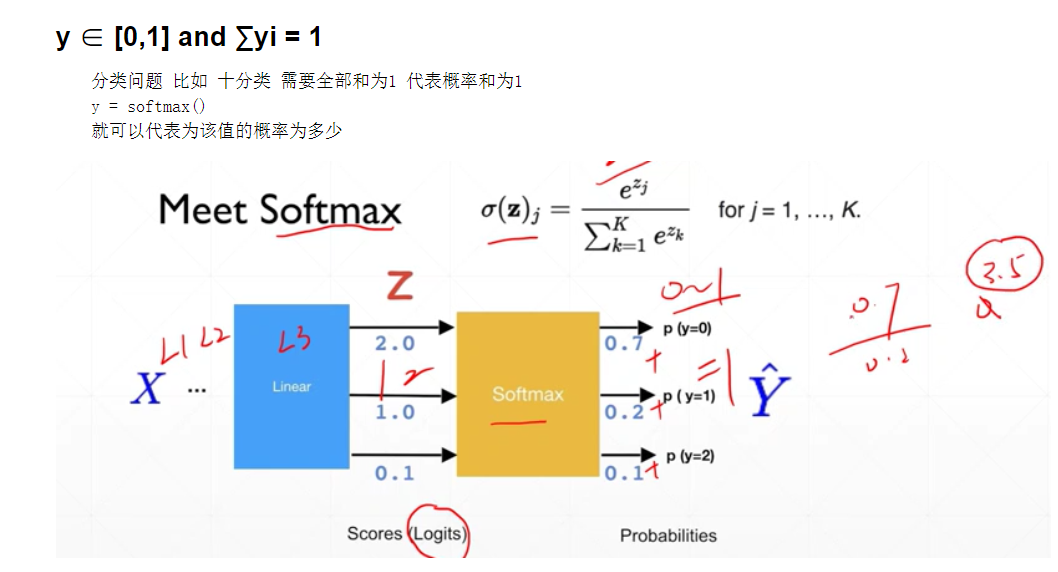
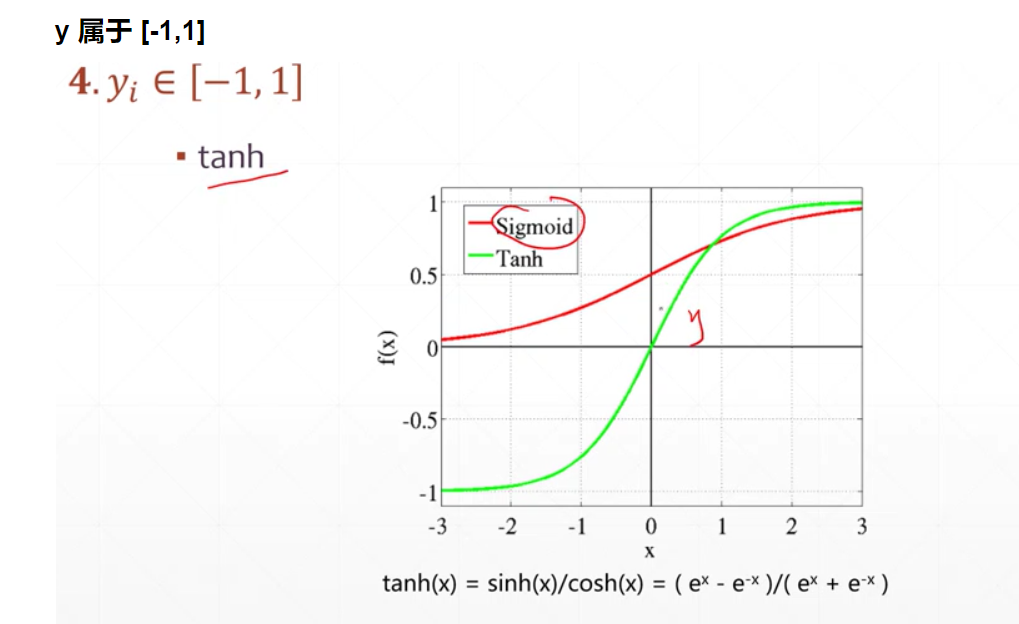
这些函数一般在 tf.nn.模块内
res = tf.nn.softmax(res)误差计算
MSE 和 交叉熵 计算loss

y = tf.constant([1,2,1,3,0])
y = tf.one_hot(y,depth=4)
y = tf.cast(y,dtype=tf.float32)
print(y)
out = tf.random.normal([5,4])
print(out)
out = tf.nn.softmax(out)
print(out)
loss1 = tf.reduce_mean(tf.square(y-out))
print("标准MSE",loss1)
loss2 = tf.norm(y-out)
print("L2-norm",loss2)
loss3 = tf.losses.MSE(y,out)
# 输出的是 shape 为 b的 tensor 即batch中每一个的MSE print("MSE函数:",loss3)
loss3 = tf.reduce_mean(loss3)
print("MSE函数:",loss3)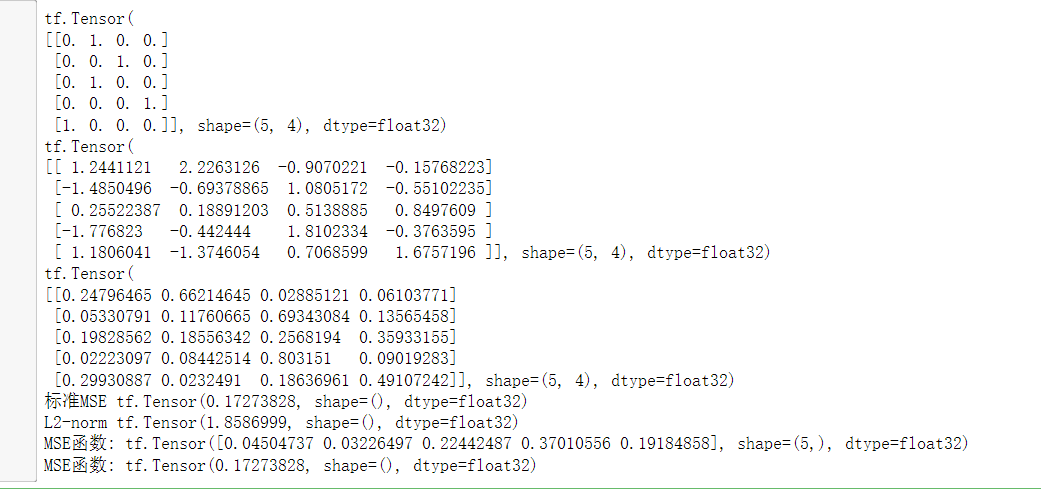
信息熵 和 交叉熵

交叉熵 取决于 prob 和 真实结果 的差别 和 结果的信息熵 当两个结果完全相同时,交叉熵 就是 信息熵 信息熵: 是结果的信息量 Dkl: 是和正确结果的差别 正确结果的信息熵最小 信息量最大
当预测结果完全等于正确结果的时候: 交叉熵 最小为0 因为正确结果的信息熵为0,距离也为0
大小取决于预测的肯定度 和 正确度
信息量越大 和正确结果 距离越小 交叉熵越小
信息量越小 和正确结果 距离越大 交叉熵越大
正确的结果的 概率越大 交叉熵越小
所以完全用交叉熵 来作为loss交叉熵的计算

由上图可以看出,当正确结果处的概率越大 则信息熵越小,信息量越大 最大为1,交叉熵为0
res = tf.losses.categorical_crossentropy(y,out)
# 输出的是 shape 为 b的 tensor 即batch中每一个的交叉熵
print(res)
注意:
理论上来说 我们先对logits进行softmax 再计算交叉熵
的结果 就是我们需要的交叉熵的结果.但是在实际应用过程中,这种操作会造成数据的不稳定,比如交叉熵该为0的时候,为0.0000...n
tensorflow提供了函数 内部有对这种情况的优化
res = tf.losses.categorical_crossentropy(y,out,from_logits=true)
即不使用softmax计算交叉熵,而是将logits带入,然后将from_logits改为true
















 3084
3084

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









