







概述
k-means属于一种无监督学习(supervised learning)也就是在训练样本是不带标签的,通过对无标签对样本进行训练学习其中的规律,其中Kmeans中的K代表要聚成k个簇(cluster)个数(可以由用户指定),Means代表均值,均值的意味着簇点是由,目标是使得簇内相似度高,簇与簇之间相似度低。
K-Means算法常用于,音乐、电影、兴趣爱好的推荐系统等。
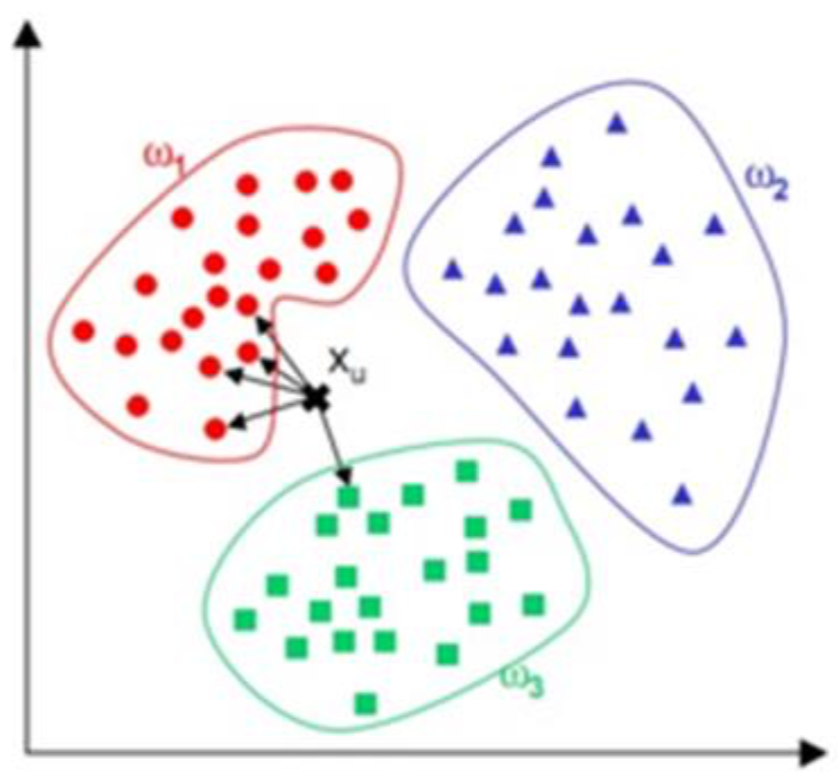
分类和聚类的区别
- 分类是明确知道数据集是有哪些类别
- 聚类是不知道数据如何去划分,不知道有几个类别,通过算法进行相似度划分
基本流程
Kmeans的流程主要划分如下
- 从样本中随机确定K个簇的初始中心,作为"质心点"(初始点Centroid)。
- 将数据集中的每个点分配到一个簇中,具体来讲,就是为每个点找到距离其最近的“质心点”所对应的簇。
- 此时质点必然不是中心点,需要计算每个质点区域内的中心点并update质点
- 将每个簇的“质心点”更新为该簇所有点的平均值
- 迭代上述几步
- 最终返回K个中心点
其中主要探讨的两个问题,第一个问题是如何选择K值,第二个问题是如何度量距离。
选择K值常见的方法:误差平方和(sum of the squared errors)、轮廓分析(Silhouette Coefficient)
选择K值在K-means中使用的指标是误差平方和(Sum of Squared Error,SSE),SSE参数计算的内容为当前迭代得到的中心位置到各自中心点簇的欧式距离总和,反映每个样本各观测值的离散状况,这个值越小表示当前的分类效果越好。
Ci是第i个簇,p是Ci中的样本点,mi是Ci的质心(Ci中所有样本的均值),SSE是所有样本的聚类误差,代表了聚类效果的好坏。
S
S
E
=
∑
i
=
1
k
∑
p
∈
c
i
∣
p
−
m
i
∣
2
SSE = \sum_{i=1}^{k}\sum_{p\in c_i}|p-m_i|^2
SSE=i=1∑kp∈ci∑∣p−mi∣2
选择度量距离常见的可以使用欧式距离、曼哈顿距离、切比雪夫距离等
- 欧式距离(Euclidean Distance)
欧式距离又称欧几里得距离或欧几里得度量(Euclidean Metric),以空间为基准计算两点之间的最短距离。
二维空间计算欧式距离
d ( x , y ) = ( x 2 − x 1 ) 2 + ( y 2 − y 1 ) 2 d(x,y) = \sqrt{(x_2-x_1)^2+(y_2-y_1)^2} d(x,y)=(x2−x1)2+(y2−y1)2
三维空间计算欧式距离
d ( x , y ) = ( x 2 − x 1 ) 2 + ( y 2 − y 1 ) 2 + ( z 2 − z 1 ) 2 d(x,y) = \sqrt{(x_2-x_1)^2+(y_2-y_1)^2+(z_2-z_1)^2} d(x,y)=(x2−x1)2+(y2−y1)2+(z2−z1)2
n维空间计算欧式距离
d ( x , y ) = ∑ n = 1 n ( x i − y i ) 2 d(x,y) = \sqrt{\sum_{n=1}^n(x_i-y_i)^2} d(x,y)=n=1∑n(xi−yi)2 - 曼哈顿距离
曼哈顿距离就像曼哈顿街道一样,街道类似横平竖直的棋盘,计算两点的距离不能像欧式距离一样,斜挎棋盘计算两点间距离。这里使用百度百科的一张图来说明,红色属于曼哈顿距离,绿色属于欧式距离
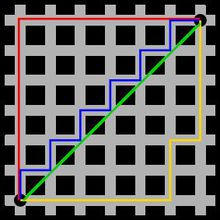
二维空间计算曼哈顿距离
d ( x , y ) = ∣ x 1 − x 2 ∣ + ∣ y 1 − y 2 ∣ d(x,y) = |x_1-x_2|+|y_1-y_2| d(x,y)=∣x1−x2∣+∣y1−y2∣
k-means的优缺点:
k-means的优点有:
- 原理简单,实现方便,收敛速度快;
- 超参数少
k-means的缺点有:
- K值怎么定,初始点怎么放,初始点放得不好影响收敛
- 噪点和异常敏感(因为means是取平均值)
- 如果数据的类型不平衡,比如数据量严重失衡或者类别的方差不同,则聚类效果不佳;
代码实现
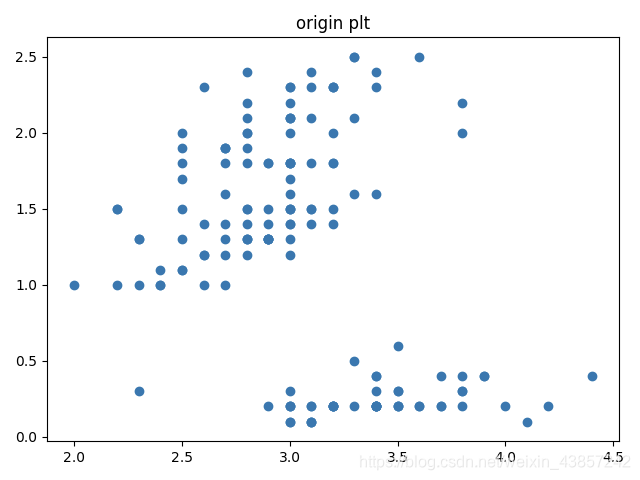
通过sklearn读取鸢尾花数据集150条数据,4个特征# 萼片长度,萼片宽度,花瓣长度,花瓣宽度,这里使用后两个特征维度。
#!/usr/bin/python
# -*- coding: utf-8 -*-
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.datasets import load_iris
def load_data():
iris = load_iris()
# print(iris.data.shape, iris.target.shape)
plt.scatter(iris.data[:, 1], iris.data[:, -1])
plt.legend(loc=2)
plt.title("origin plt")
plt.show()
return iris.data[:, 2:], iris.target
使用散点图绘制的原始150个数据分布情况
构造Kmeans模型,假设使用3个质点来进行聚类数据
def Kmeans_model(X):
k = KMeans(n_clusters=3)
k.fit_transform(X)
cluster0 = X[k.labels_ == 0]
cluster1 = X[k.labels_ == 1]
cluster2 = X[k.labels_ == 2]
plt.scatter(cluster0[:, 0], cluster0[:, 1], c="red", marker='o', label='cluster0')
plt.scatter(cluster1[:, 0], cluster1[:, 1], c="green", marker='*', label='cluster1')
plt.scatter(cluster2[:, 0], cluster2[:, 1], c="blue", marker='+', label='cluster2')
plt.legend(loc=2)
plt.title("kmeans plt")
plt.show()
if __name__ == '__main__':
data, target = load_data()
Kmeans_model(data)
可以观察到被分成了三类样本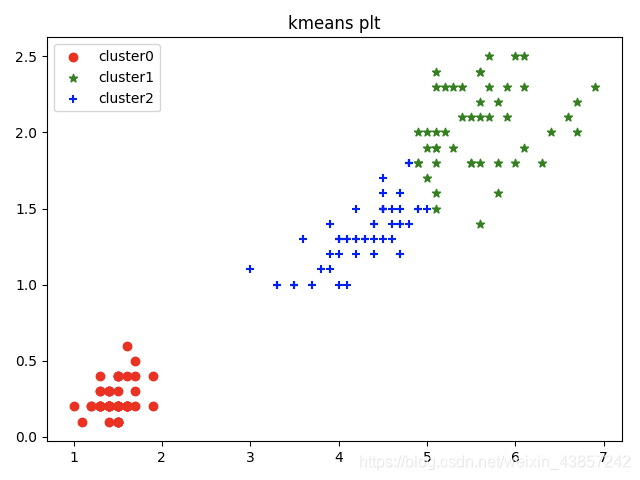
参考文献
- Deep Learning
- Machine Learning
最后
本人工作原因文章更新不及时或有错误可以私信我,另外有安全行业在尝试做机器学习+web安全的小伙伴可以一起交流



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









