







 本文深入讲解KNN算法,包括其工作原理、优缺点及实际应用。探讨K值选择、距离度量方法和决策规则,介绍KDTree和BruteForce优化算法,并通过Python代码示例展示如何实现鸢尾花分类预测。
本文深入讲解KNN算法,包括其工作原理、优缺点及实际应用。探讨K值选择、距离度量方法和决策规则,介绍KDTree和BruteForce优化算法,并通过Python代码示例展示如何实现鸢尾花分类预测。
KNN算法概述
K近邻(K-Nearest Neighbor,KNN)Cover和Hart在1968年提出了最初的邻近算法。
所谓KNN,就是K个最近邻居的意思。说的是每个样本都可以用它最接近的k个邻居来代表。
KNN是一种有监督的分类(Classification)算法,属于懒惰学习(lazy learning)即KNN没有显式的学习过程,也就是没有训练数据的阶段,所以也代表了该阶段的时间开销为零,数据集事先已有了分类和特征值,待收到新样本后直接进行处理。
KNN在做回归和分类的时候的主要区别在于在最后做预测的时候决策方式不同,在分类预测的时候一般采用多数表决法;在做回归预测时候,一般采用平均值法。
KNN算法思想
KNN核心思想在于,如果一个新样本在特征空间中的K个最相邻的样本中的大多数属于某一类别,则该样本也属于这个类别。所选择的邻居都是已经正确分类的对象。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。
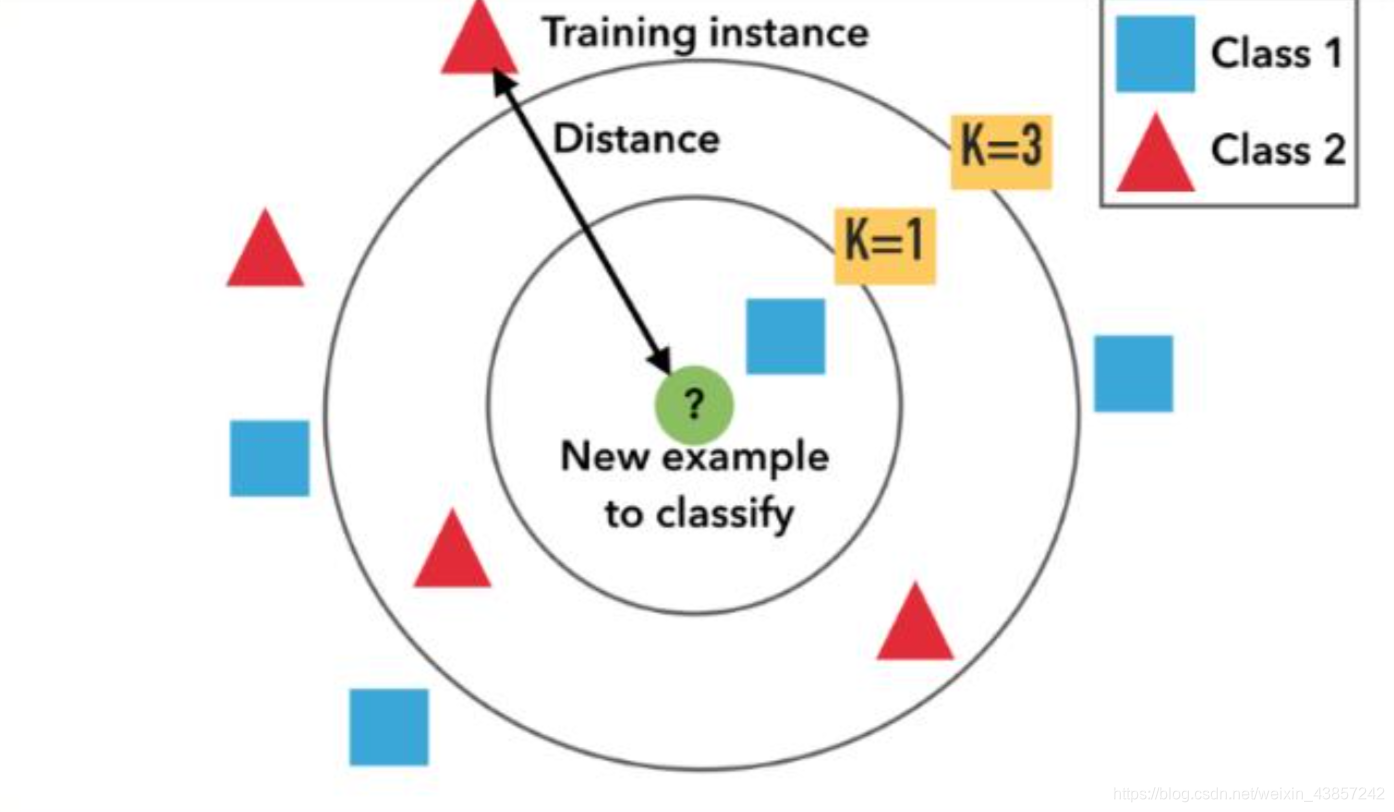
KNN工作原理
K近邻模型有三个主要因素,K值的选择、距离度量的方法、分类决策规则。
- K值的选择
K值如果过小,表示使用较小邻域中的样本进行预测,训练误差会减少,但是模型会变得复杂,容易过拟合,学习的估计误差会增大,预测结果对近邻的实例点非常敏感。
K值如果过大,表示使用较大邻域中的样本进行预测,这种情况会降低估计误差,但是会增加近似误差。 - 距离的度量
一般来说衡量距离常见的方法有:欧几里得度量(euclidean metric)(也称欧氏距离)、曼哈顿距离(Manhattan distance)等等。在K临近算法中使用较多的是欧几里得距离。 - 决策规则
分类模型中,使用多数表决法、加权多数表决法(距离与权重成反比)
回归模型中,使用平均值法、加权平均值法
KNN算法优化
当如果有大量的数据输入的时候为了加快检索,引入了优化算法,相当于是使用了特殊的结构来保存数据,以减少数据的检索次数。
- KD Tree(k-dimenstion tree)
- 是一种二叉树,构造kd树相当于不断垂直与坐标轴的超平面奖K维空间分割。 KD树采用从m个样本的n维特征中,分别计算n个特征取值的方差,用方差最大的第k维特征nk作为根节点。
- 对于这个特征,升序排列后选择取值的中位数nkv作为样本的划分点,对于小于该值的样本划分到左子树,对于大于等于该值的样本划分到右子树,对左右子树采用同样的方式找方差最大的特征作为根节点。
- Brute Force(暴力实现)
- 计算预测样本到所有训练集样本的距离,然后选择最小的k个距离即可得到K个最邻近点。缺点在于当特征数比较多、样本数比较多的时候,算法的执行效率比较低
KNN优缺点
优点
- 使用简单,理论成熟
- 训练时间开销为零(Lazy)
- 对异常数据不敏感
缺点
- 大数据量预测的时候需要大量计算所有K点距离,性能开销变大
- 样本容量小或样本分布不均衡时,容易分类错误
KNN算法模型的实际应用
实现目标
- 使用KNN(K近邻算法)实现对IRIS鸢尾花的分类预测
- 通过迭代的方式找到最合适的K值
#!/usr/bin/python
# -*- coding: utf-8 -*-
import numpy as np
from sklearn import datasets
import matplotlib.pyplot as plt
from sklearn.externals import joblib
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import PolynomialFeatures
from sklearn.model_selection import cross_val_score
"""
1. 使用KNN(K近邻算法)实现对IRIS鸢尾花的分类预测
2. 通过迭代的方式找到最合适的K值
"""
class iris:
def __init__(self):
"""
初始化iris数据
x 鸢尾花特征
y 各种花的类别
scores 所有邻居的得分
range 测试所有的邻居
"""
self.iris = datasets.load_iris()
self.x = self.iris.data
self.y = self.iris.target
self.k_scores = []
self.k_range = range(1, 31)
self.best_n_neighbors = int
self.knn_fit = object
def GenerateFeature(self):
"""
项式特征构造
将原始特征增加,3阶多项式
:return: x特征数组
"""
poly = PolynomialFeatures(3)
x_extend = poly.fit_transform(self.x)
return x_extend
def DrawTestModel(self, x):
for k in self.k_range:
knn = KNeighborsClassifier(n_neighbors=k)
scores = cross_val_score(knn, self.x, self.y, cv=5, scoring="accuracy")
self.k_scores.append(scores.mean())
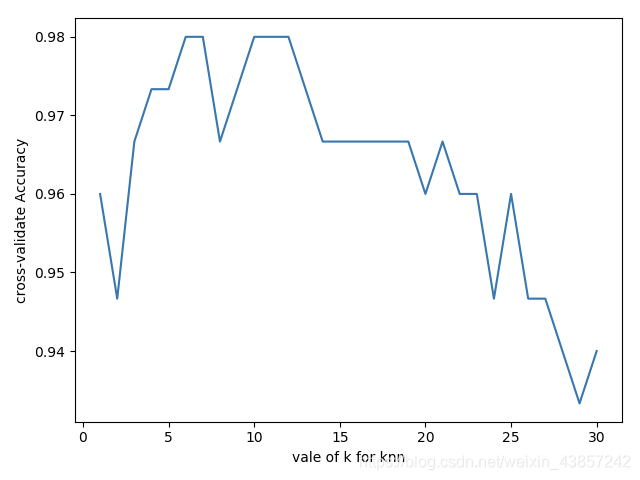
plt.plot(self.k_range, self.k_scores)
plt.xlabel("vale of k for knn")
plt.ylabel("cross-validate Accuracy")
plt.show()
print("最大得分在邻居数为:{max} , 最小得分在邻居数为:{min}".format(max=str(np.argmax(self.k_scores)),
min=str(np.argmin(self.k_scores))))
self.best_n_neighbors = np.argmax(self.k_range)
"""
训练模型
"""
def TrainModel(self):
knn = KNeighborsClassifier(n_neighbors=self.best_n_neighbors)
x_train, x_test, y_train, y_test = train_test_split(self.x, self.y, random_state=4)
self.knn_fit = knn.fit(x_train, y_train)
result = knn.score(x_test, y_test)
print("训练结果得分:{:.2f}%".format(result * 100))
"""
保存训练后的模型
"""
def SaveModel(self):
joblib.dump(self.knn_fit, 'dump_model.pkl')
"""
读取训练后的模型
"""
def LoadModel(self):
model = joblib.load('dump_model.pkl')
return model
if __name__ == "__main__":
i = iris()
x = i.GenerateFeature()
i.DrawTestModel(x)
i.TrainModel()
i.SaveModel()
model = i.LoadModel()
print ("model",model)
r = model.predict([[6.4, 2.8, 5.6, 2.1]])
print("预测分类:{rtype} - {name} ".format(rtype=r, name=i.iris["target_names"][r]))
"""
x_test [[6.4 2.8 5.6 2.1]
[5.7 3.8 1.7 0.3]
[7.4 2.8 6.1 1.9]
[7.6 3. 6.6 2.1]
[5. 2.3 3.3 1. ]
[6.7 3.3 5.7 2.5]
[7.2 3.2 6. 1.8]
[5.8 2.6 4. 1.2]]
"""
K值的迭代上来看在K值等于10的时候交叉验证分数最高
参考文献
- Deep Learning
- Machine Learning
最后
本人工作原因文章更新不及时或有错误可以私信我,另外有安全行业在尝试做机器学习+web安全的小伙伴可以一起交流


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









