







人工智能的流派
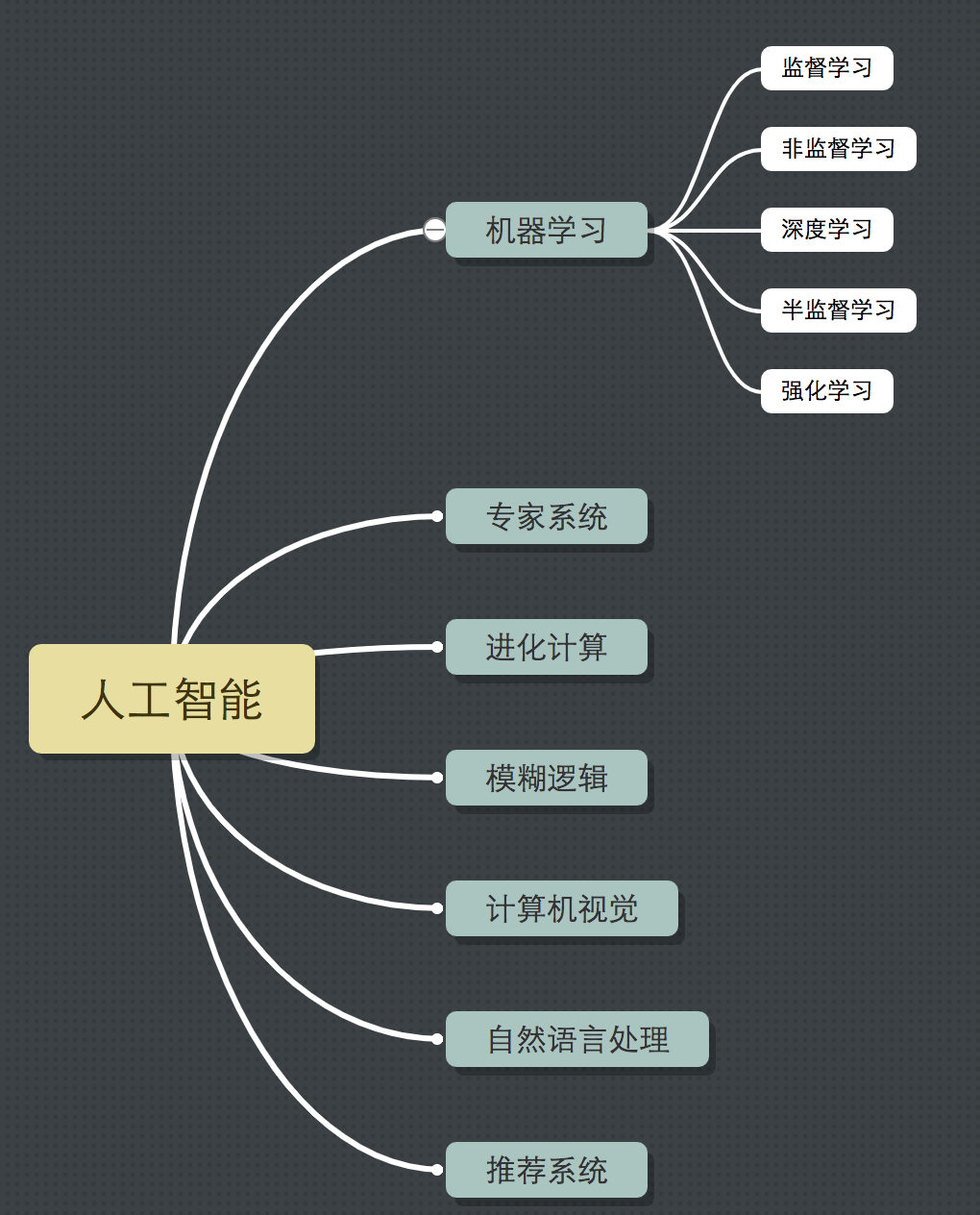
说到机器学习就不得不先说一下人工智能(Artificial Intelligence),可以把任何智能活动的都笼统的称为人工智能,而机器学习(Machine Learning)只是人工智能的一个分支,深度学习(Deep Learning)则是机器学习的分支。本系列主要学习传统的机器学习和深度学习。
什么是机器学习
机器学习类似数据挖掘,是通过利用概率学、统计学等学科进行学习,对用户的输入作出预测或者判断。与传统的程序的主要区别在与机器学习是通过大量“训练”数据,通过各种概率、统计从训练数据中得到的结果。
| 算法分类 | 解决问题 |
|---|---|
| 分类算法 | 是什么 |
| 回归算法 | 是多少 |
| 聚类算法 | 怎么分 |
| 数据降维 | 怎么压 |
| 强化学习 | 怎么做 |
机器学习在当下为了与深度学习区分开来,我们也称机器学习为传统的机器学习,其中包含的算法主要包括:
- 支持向量机(SVM)
- 线性回归(Linear Regression)
- 逻辑回归(Logistic egression)
- 朴素贝叶斯(Naive Bayesian)
- K近邻(K Nearset Neighbor)
- 随机森林(Descision Tree and Random Forests)
监督学习 Supervised Learning
有监督学习简单来说就是在训练模型过程中,用来训练的数据事先已标记好标签(Labels),然后再让机器来学习。
举例来说一个有监督的入侵检测模型,训练的前就明确清晰的对每个请URL求标记上是正常请求还是恶意异常请求,这样的训练方式我们称为有监督的训练。
- 常见的监督学习任务
模型主要分为二类即分为回归模型、分类模型
分类(Classification)模型,分类模型就是对标签进行分类,可以是二分类(喜欢/不喜欢、正常/恶意),也可以是多分类问题。
分类与回归的区别在于,分类问题的输出是离散的,回归的输出是连续的。
分类与聚类的区别在于,分类的标签训练前已知,而聚类在训练前没有划分标签。
举例来说假设你有一个屌丝模型分类器,在训练模型前就会把每个训练数据打好标签,这样在预测的时候投入一个人他就会得到这个人对应的类别标签。
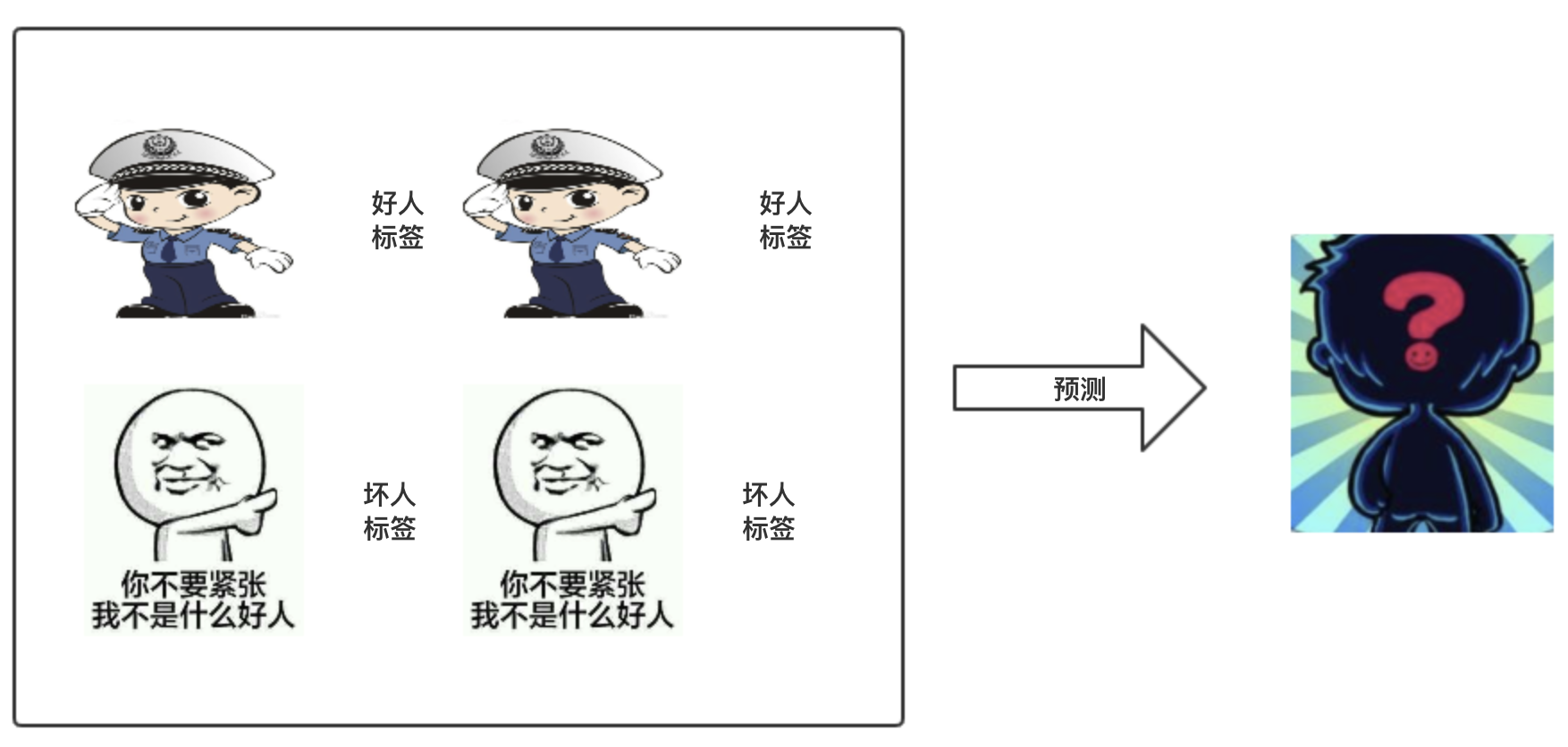
- 回归(Regression),简单来说就是关于预测数量的问题,回归的输出是连续型的,好比说还是上边这个屌丝模型的例子,我们预测他是坏人和好人的概率,这样就从类别问题变为了回归问题,可以理解为因为输出的概率是连续值。
无监督学习 unSupervised Learning
无监督学习顾名思义就是训练数据的时候没有带上标签,系统在预测前不知道正确答案,完全靠系统自动探索数据内在结构联系。
举例来说最常见的无监督例子就是聚类了,聚类的目的是把相似的东西聚在一起,比如说什么样的顾客群体购买力更强更有购物趋势,可以与普通消费群体进行区分。在聚类前并不知道有要划分多少类群体。
半监督学习
半监督学习同时使用了标签和无标签数据进行训练-通常情况下是少量的标记的数据与大量的未标记的数据(因为未标记的数据并不昂贵,且只需要较少的努力就可获得)。
这种类型的学习可以使用的方法,如分类,回归和预测。当一个完全标记的培训过程,其相关标签的成本太高时,就要用到半监督学习。其中早期的例子包括在网络摄像头上识别一个人的脸。
强化学习经常被用于机器人,游戏和导航。通过强化学习,该算法通过试验和错误发现行动产生的最大回报。这种类型的学习有三个主要组成部分:代理(学习者或决策者),环境(一切的代理交互)和行动(什么是代理可以做的)。
其目标是代理选择的行动,可以在一个给定的时间内最大化预期奖励。通过一个好的策略,代理将更快地达到目标。因此,强化学习的目标是学习最好的策略。
深度学习
深度学习也是人工智能的一个领域最大的区别在于像个黑匣子可是解释性降低了,深度学习具有层的概念(输入层、隐含层、输出层),通过堆叠多个隐含层来学习对数据有意义的表征。
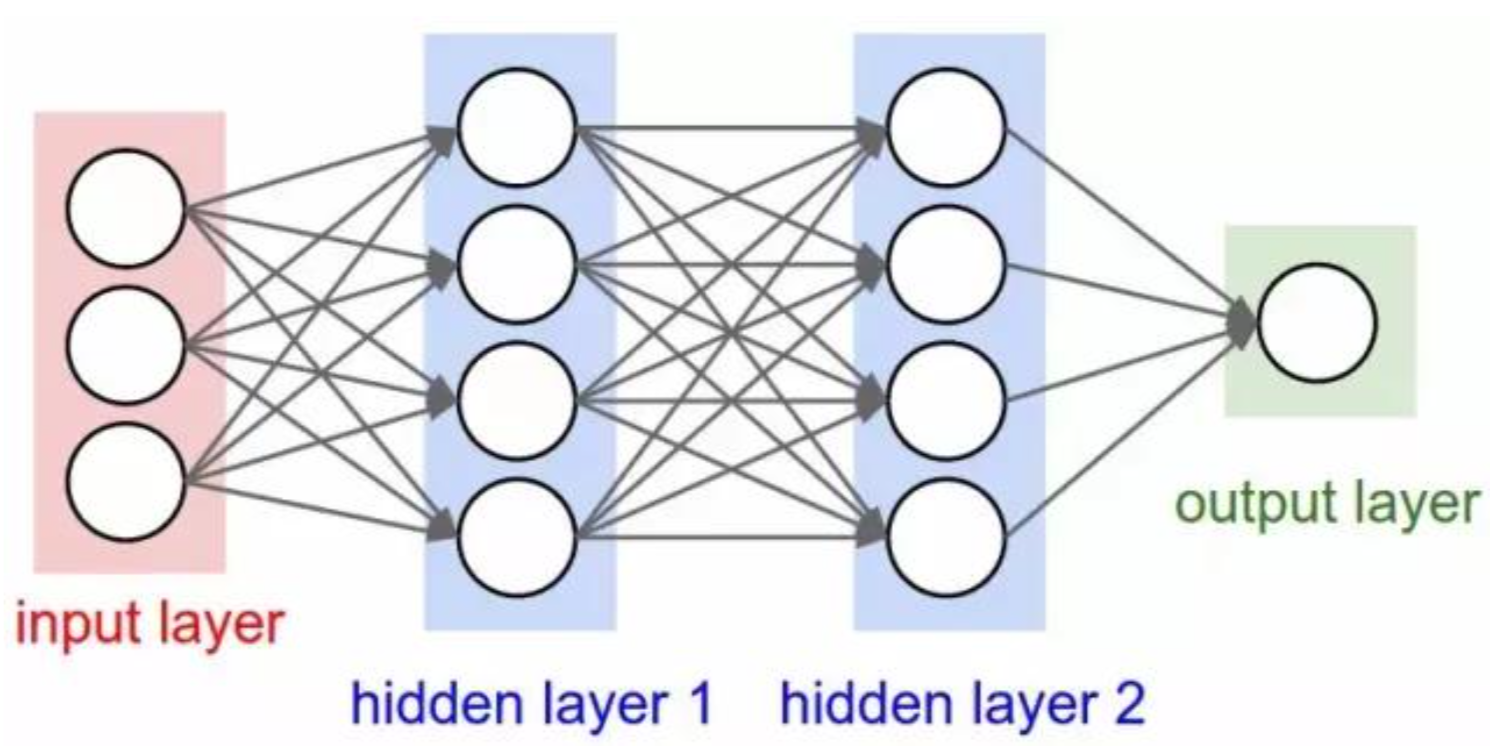
同样的深度学习也分为有监督和无监督,比如我们常说的卷积神经网络(CNN)就属于深度学习中有监督的学习模型。
深度学习是一类端到端的学习方法。基于多层的非线性神经网络,深度学习可以从原始数据直接学习,自动抽取特征并逐层抽象,最终实现回归、分类或排序等目的。
机器学习优势
大数据分析与机器学习一直是最佳配合,单独用机器学习来做评判标准是不可行的,机器学习发展到当前阶段在安全领域的最佳实践大多是静态规则+机器学习互补遗漏,静态规则可以做精准的匹配,而机器学习可以用来做误报、漏报交叉验证。
效率上使用模型预测要比使用正则匹配效率要高很多,但是缺点也很明显训练数据需要大数据的支撑、人工标注又是一个持续繁重的工作的,业界不是有那么一句话么"有多少智能,就有多少人工"。
参考资料
- 《Deep Leanring with Python》
最后
本人工作原因文章更新不及时或有错误可以私信我,另外有安全行业在尝试做机器学习+web安全的小伙伴可以一起交流



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









