






说明:在Linux中一般不喜欢称任务,而是叫做进程/线程,但在其他操作系统如ucos中就是一个个任务,本人目前还是比较习惯叫任务,等细讲进程时会在严格区分进程和线程
上下文,context;上下文切换,context_switch;把这个概念放第1节讲解是很有必要的,因为Linux操作系统归根结底就是个纯软件东西,脱离硬件(芯片)是无法运行起来的;
在芯片(开发板)这个硬件器件上,厂商通过统一编址规划了每个器件的内存,让SPI、DDR、DMA、CAN等等有各自的地址空间,这样才能保证程序操作某器件,就往相应地址范围操作就行,划分地址空间的方法使得器件与器件之间有边界感;
操作系统这种软件一样,其管理的是一个又一个任务(附带控制内存的使用,以及驱动模块的管理),而系统运行起来时,宏观上给人们的感觉是“多任务并行”,其实本质无外乎操作系统控制每个任务的时间片(允许任务执行的一段时间),让CPU在短周期内来回切换任务执行。这里就存在一个问题,操作系统是如何做到切换任务,而在其他任务做完切回本任务时,能继续上次没做完的地方接着做。所以这就需要我的了解上下文切换时,操作系统干了啥。
对于单核系统而言,永远也没有并行,最多只有并发。并行是指:一段时间内,多个CPU分别执行不同的任务,那么这多个任务是并行的;而单CPU系统,由于只有一个核,顶多是在一段时间内来回快速切换多个任务执行,这多个任务间是并发的
我们这里需要从函数调用过程开始讲起(毕竟一个个任务说白了还是一个个函数,当任务切换时,肯定是执行到某个任务的某个函数里了,这时候要切出去的话,系统得先保存当前函数执行的相关信息)
先看一幅简图:
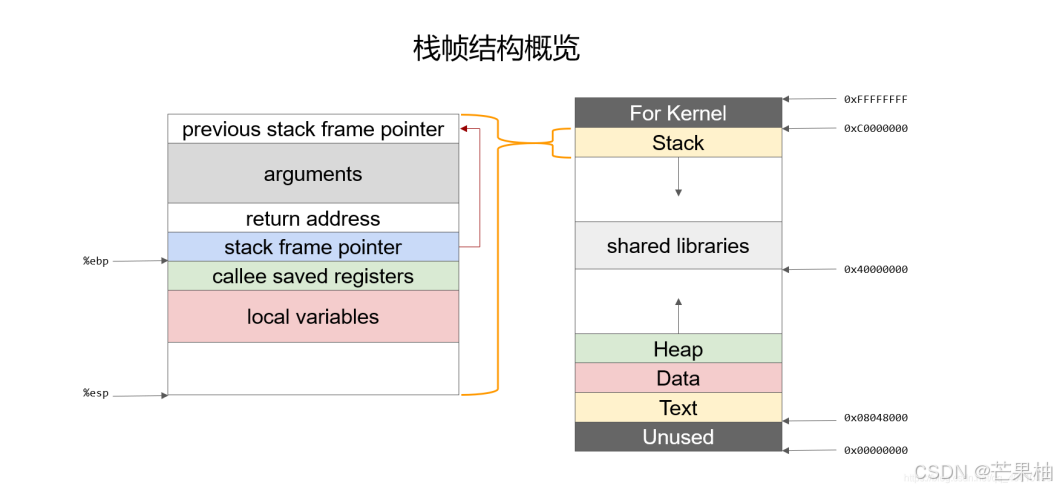
图中右列是通用的芯片内存空间,一般包括指令区(text,即代码)、数据区(data,还会细分常量区和静态区(包含全局变量与静态变量))、堆区(heap,一般是malloc申请的内存,在DDR上)、栈区(函数执行时所会占据的区域,一般在cache,毕竟是CPU正在运行的函数代码,肯定要让其处于一块速率较快的内存上;其他没运行的函数不会加载过来,等使用时自然加载上来了),还有共享区(shared,这个可能不同系统不同规划,Linux该块反而是mmap内存映射区,如文件映射等)。
我们重点关注栈,每当需要执行一个函数,肯定会把一些信息压入栈(由于栈也不是无限大,所以写递归时,注意递归次数,如果递归非常多或者无限次会撑爆栈);
再接着看图中左列,它就是很形象地描述了函数调用时,栈中增加的信息;
假如一个父函数调用子函数时,需要:
(1)子函数所需的参数依次入栈;
(2)返回地址入栈;
(3)根据子函数名找到相应函数,准备执行
(4)ebp入栈(指向父函数栈底,因为子函数执行完毕,需要接着父函数执行)
(5)esp定位到ebp指向的位置(栈中子函数栈帧开始的地方)
(6)分配子函数栈空间(存放局部变量什么的)
等子函数执行完毕,其返回时,
(1)把运算结果存到EAX
(2)ebp出栈(esp指向的是栈的位置,在子函数执行完,编译器把代码转成汇编时,会自己追加跳转到ebp所指向的位置,也即定位到子函数栈底),此时里面存放的是指向父函数栈底,而esp自动上涨到压入的返回地址;也即此时ebp指向的是父函数栈帧的栈底,而esp指向上次父函数没执行完的地方;
esp,ebp等寄存器是x86结构的相关寄存器,我会在该系列第2期出一个关于CPU通用寄存器的说明
可能上述流程我讲的不是很细致,但从这里可以看出:一个函数的栈空间肯定包含入参信息、返回地址、局部变量等等;而关键信息栈底和栈顶分别在ebp和esp寄存器中,还有其他通用寄存器也保存一些值(比如在arm架构中,r14保存返回地址);虽然上述是函数调用时栈发生的一些变化,但任务切换时,肯定是某个任务正在执行到其函数某一句后发生的切换,所以最关键的还是记录这些和函数相关的内容、其次可能附加一些任务相关的信息就够了
其实CPU通用寄存器以及esp程序计数器等就是CPU上下文,CPU上下文切换:把前一个任务的CPU上下文保存起来,加载新任务的CPU上下文到这些寄存器和程序计数器,最后跳转到程序计数器所指的新位置,运行新任务。
保存的上下文会存储在系统内核中,在任务重新调度执行时,在加载进来,保证原任务状态不受影响,看起来任务是连续运行。
CPU上下文会保存在进程的内核空间中,OS在给每个进程分配虚拟内存空间时,还会有个内核空间,这部分内存只能由内核代码保存。CPU在切换上下文前,会把当前的CPU通用寄存器、esp等进程现场信息保存在内核空间,等下次切回来时,再重新把上下文加载到CPU上,以恢复任务执行
根据任务运行不同,可分为三中类型:进程上下文切换-线程上下文切换-中断上下文切换
1 进程上下文
先简单介绍些进程相关的信息
(1)Linux按照特权等级,将进程运行空间分为内核空间和用户空间。
内核空间(Ring0)具有最高权限,可直接访问所有资源;
用户空间(Ring3)只能访问受限资源,必须通过系统调用陷入内核中才能访问这些特权资源
(2)系统调用
进程在用户空间运行称为进程的用户态,陷入内核空间运行称为进程的内核态
用户态到内核态的转变需要系统调用来完成,如对文件的操作,open(), read(), write(), close()等操作。该过程即发生CPU上下文切换:
1、保存用户态CPU寄存器相关信息;
2、为了执行内核态代码,CPU寄存器需要更新为内核态指令的位置;
3、跳转到内核态运行内核任务;
4、系统调用结束后,CPU寄存器需要恢复原先保存的用户态指令,然后切换到用户空间,继续运行进程。
所以,一次系统调用发生两次CPU上下文切换:用户态-内核态-用户态。
不过需要注意的是,系统调用并不会涉及虚拟内存等进程用户态的资源,也不会切换进程。跟常说的进程上下文切换是不同的:进程上下文切换是指从一个进程切换到另一个进程,系统调用一直在一个进程中运行。
所以,系统调用一般称为特权模式切换,而不是上下文切换,其属于同进程内的CPU上下文切换。
(3)进程上下文切换与系统调用的区别
进程是由内核来管理和调度的,进程切换只能发生在内核态。所以,进程上下文切换不仅包括虚拟内存,栈,全局变量等用户态资源,还包括内核堆栈,寄存器等内核态资源。
进程上下文切换比系统调用多了一步:在保存内核态资源(当前进程的内核状态和CPU寄存器)之前,需要把该进程的用户态资源(虚拟内存,栈等)保存下来;且加载下一个进程内核态后,需要刷新进程的虚拟内存和用户栈。
(4)潜在性能问题
根据Tsuna测试报告,每次上下文切换都要花费几十纳秒到数微秒的CPU时间,这个时间还是相当可观的,特别是进程上下文切换比较多的情况下,很容易导致CPU将大量时间耗费在寄存器,内核栈,虚拟内存等资源的保存和恢复上。
此外,Linux通过TLB(Translation Lookside Buffer,后备缓冲区)来管理虚拟内存到物理内存的映射关系。当虚拟内存刷新后,TLB也要刷新,内存访问也会随之变慢。
(5)进程上下文切换的场景
1、自然调度,为了保证公平调度,CPU时间被划为一段段时间片,这些时间片被轮流分给各个进程。当某个进程时间片耗尽了,就会被系统挂起,CPU去执行其他等待被执行的进程;
2、进程通过sleep睡眠函数主动将自己挂起;
3、系统资源不足时(如内存不足),会被挂起,系统运行其他进程,等资源满足时在运行该进程;
4、高优先级进程抢占运行;
5、发生硬件中断时,当前进程会被中断挂起,CPU转而执行内核中的中断服务程序
2 线程上下文
与进程最大的区别在于:线程是调度的基本单位,进程是资源分配的基本单位。内核中的任务调度,实际调度对象是线程;进程只是为线程提供了虚拟内存,全局变量等资源。
进程只有一个线程时,进程即等于线程;
进程拥有多个线程时,这些线程共享相同的虚拟内存和全局变量等资源;这些资源在上下文切换时是不需要修改的;
另外,线程也有自己的私有数据,栈和寄存器等,这些在上下文切换时是需要保存的。
前后两个线程不属于同一进程,因为资源不共享,则与进程上下文切换一样;前后两线程属于同一进程,虚拟内存等资源共享,所以只需切换线程的私有数据、寄存器等资源
3 中断上下文
为了快速响应硬件事件,中断处理会打断进程的正常调度和执行,转而调用中断处理程序,响应设备事件。在打断其他进程时,需要先保存进程的当前状态保存下来,中断处理完成后,能及时恢复原进程状态执行。
和进程上下文切换不同的是,中断上下文切换不涉及进程的用户态。所以,即便中断过程打断了一个处在用户态的进程,也不会切换进程的虚拟内存,全局变量等资源;中断上下文,只包括内核态中断服务程序所需的状态,如CPU寄存器,内核中断,硬件参数等。
对同一个CPU来讲,中断处理比进程拥有更高的优先级,所以中断上下文切换不会与进程上下文切换同时发生。由于中断会打断进程的正常调度和执行,所以中断处理程序都短小精悍,以便尽可能快地执行结束。

















 685
685

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









