



背景需求
因为做了24套交叉样式的动物数独PDF
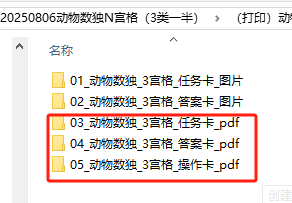
我想直接给客户发送24套样式,自选,但是连我自己的都没有耐心把一个PDF从头拉到尾,所以我觉得不需要交叉合并,只需要提供三个文件夹
1.操作卡(0图、1图、2图、6图 )
2.任务卡(1图、2图、6图 )
3.答案卡(1图、2图、6图 )
修改过程:
花了两天时间,反复测试,修改参数。终于获取了三个文件夹样式。
# -*- coding:utf-8 -*-
'''
制作动物/脸谱数独N宫格通用版(3-10的黏贴关卡 A4 1图2图6图的所有组合 还有一个限定A4大小的0图(3-6宫格)
1.无答案:9种3:3,两两组合
2.有答案:27种 3:3:3,三三组合(实际需要其中9种)
3.横竖两个不能都是空格,空格尽量分散排列,如9格,目前1-5可以分散,空额不相连,6-9不行)
4.奇数宫格:(奇数*奇数+1)/2;偶数宫格:(偶数*偶数+1)/2
5.一次性生成3-6宫格,计算总时长
6.不需要24套,只要做3个文件夹操作卡(0,1,2,6图)、任务卡(1,2,6图)、答案卡(1,2,6图)
作者:AI对话大师,deepseek、阿夏
时间:2025年08月06日
'''
import os,math
import time
from docx import Document
from docx.shared import Cm, Pt, RGBColor
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
from docx.enum.text import WD_ALIGN_PARAGRAPH
from docx.oxml.ns import qn
from docxtpl import DocxTemplate
import pandas as pd
from docx2pdf import convert
from win32com.client import constants, gencache
from win32com.client.gencache import EnsureDispatch
from datetime import datetime
import random
import shutil
import xlwt
import xlrd
from PyPDF2 import PdfMerger
from docx.shared import Pt, Cm, RGBColor
from docx.oxml.shared import qn
start_time = datetime.now()
# 改为循环处理多个宫格数
hsall_list = list(range(8,9)) # 要生成的宫格数列表
for hsall in hsall_list:
start = 0
end = hsall
hs = hsall
# 为每个宫格数创建独立的文件夹
path = fr'C:\Users\jg2yXRZ\OneDrive\桌面\20250806动物数独N宫格(3类一半)'
os.makedirs(path, exist_ok=True)
# 原有的A4尺寸等设置保持不变
A4size = [6.5, 4.88, 3.9, 3.25, 2.79, 2.44, 2.17]
A4gz = [3, 4, 5, 6, 7, 8, 9]
A4pg=[3,4,5,6,7,8,9]
A4gzs=[3,4,5,6,7,8,9]
psize=[19.6,14.1,9.39]
gzsize=[6.4,4.8,3.84,3.2,2.74,2.39,2.12,1.91]
gzsgg=list(range(3, 10))
pg=[1,2,6]
gzs=[1,2,2]
print('-----第一板块、动物操作卡(大图片卡一页1图、1页2图 一页6图)-------')
# Get page settings based on hs value
for w in range(len(A4gz)):
if hs == A4gz[w]:
psize.append(A4size[w])
pg = [1, 2, 6, A4pg[w]]
gzs = [1, 2, 2, A4gzs[w]]
k = ['1图关卡', '2图关卡', '6图关卡', f'A4的{hs}图卡片']
print(k)
for pt in range(len(pg)):
# Create temp folders
temp_word_path = os.path.join(path, '零时Word')
temp_pdf_path = os.path.join(path, f'05_动物数独_{hs}宫格_操作卡_pdf')
os.makedirs(temp_word_path, exist_ok=True)
os.makedirs(temp_pdf_path, exist_ok=True)
# Load template document
doc = Document(os.path.join(path, f'动物数独({k[pt]}).docx'))
table = doc.tables[0]
# Get animal images
pic_folder = os.path.join(path, '02动物图片')
pic_list = [os.path.join(pic_folder, f) for f in os.listdir(pic_folder)][start:end] * hs
# Group images based on layout
group_size = pg[pt]*pg[pt] if pt == 3 else pg[pt]
groups = [pic_list[i:i + group_size] for i in range(0, len(pic_list), group_size)]
for group_idx, group in enumerate(groups):
doc = Document(os.path.join(path, f'动物数独({k[pt]}).docx'))
table = doc.tables[0]
for cell_idx, img_file in enumerate(group):
row = int(cell_idx / gzs[pt])
col = cell_idx % gzs[pt]
cell = table.cell(row, col)
cell.paragraphs[0].clear()
if os.path.exists(img_file):
run = cell.paragraphs[0].add_run()
run.add_picture(img_file, width=Cm(psize[pt]), height=Cm(psize[pt]))
cell.paragraphs[0].alignment = 1
# Add title for A4 layout
if pt == 3:
title_table = doc.tables[1]
title_cell = title_table.cell(0, 0)
title_cell.text = f'动物数独 {hs}*{hs} 操作卡'
para = title_cell.paragraphs[0]
para.alignment = WD_ALIGN_PARAGRAPH.CENTER
run = para.runs[0]
run.font.name = '黑体'
run.font.size = Pt(35)
run.font.color.rgb = RGBColor(0, 0, 0)
run._element.rPr.rFonts.set(qn('w:eastAsia'), '黑体')
# Save and convert to PDF
doc.save(os.path.join(temp_word_path, f'{group_idx+1:02d}页.docx'))
convert(os.path.join(temp_word_path, f'{group_idx+1:02d}页.docx'),
os.path.join(temp_word_path, f'{group_idx+1:02d}页.pdf'))
time.sleep(3)
# Merge PDFs
pdf_files = sorted([os.path.join(temp_word_path, f) for f in os.listdir(temp_word_path) if f.endswith('.pdf')])
merger = PdfMerger()
for pdf in pdf_files:
merger.append(pdf)
output_name = f"01_动物数独_{hs}宫格_操作卡_1页{hs*hs}图(一图{A4size[pt]}CM,只要打印1张A4).pdf" if pt == 3 else f"01_动物数独_{hs}宫格_操作卡_1页{k[pt][:-2]}(一图{psize[pt]}CM).pdf"
merger.write(os.path.join(temp_pdf_path, output_name))
merger.close()
# Clean up
print('-----第二板块、动物任务卡和答案卡一套,只要JPG-------')
import random
from win32com.client import constants, gencache
from win32com.client import genpy
from win32com.client.gencache import EnsureDispatch
from docx import Document
from docx.shared import Pt, RGBColor
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
from docx.oxml.ns import qn
from docx.enum.text import WD_ALIGN_PARAGRAPH
import docxtpl
import pandas as pd
from docx2pdf import convert
from docx.oxml.ns import nsdecls
from docx.oxml import parse_xml
import copy
print('------3-1、生成指定数量的关卡(按最大空缺数限制)------')
n = hsall # 宫格数(例如3)
g = n * n # 总格子数(例如9)
# 根据宫格数确定最大空缺数
if n % 2 == 1: # 奇数宫格
max_empty = (g + 1) // 2 # 例如3宫格:(9+1)/2=5
else: # 偶数宫格
max_empty = g // 2 # 例如4宫格:16/2=8
# 只生成1到max_empty关(例如3宫格只生成5关)
a = []
for empty in range(1, max_empty + 1): # 直接按空缺数生成
# 计算对应的百分比(四舍五入)
percentage = round(empty * 100 / g)
print(f'{n}宫格,难度{percentage:03d},抽取{percentage:03d}%:实际有{empty:03d}空,已有图案{g-empty:03d}')
a.append(f'{n}宫格,难度{percentage:03d},抽取{percentage:03d}%:实际有{empty:03d}空,已有图案{g-empty:03d}')
# 去重和排序(虽然现在应该已经是有序且不重复的)
b = []
for element in a:
parts = element.split(":")
info = parts[1]
b.append(info)
b = list(set(b))
b.sort(reverse=False)
f = []
for d in range(len(b)):
for c in a:
if c[-15:] == b[d]:
f.append(c)
break
# 移除第一个(空0的无效项)如果有的话
if f and int(f[0][20:23]) == g: # 检查是否全满(空0)
f.pop(0)
print(f'实际生成关卡数:{len(f)}')
# 提取空缺数和已有图案数
empty_counts = []
filled_counts = []
for p in f:
empty_counts.append(int(p[20:23]))
filled_counts.append(int(p[12:15]))
print('空缺数序列:', empty_counts)
print('已有图案数:', filled_counts)
print('------2、制作宫格随机数字------')
def generate_non_adjacent_blanks(hs, num_blanks):
"""生成不连续的空格位置"""
max_blanks = (hs*hs + 1)//2 if hs % 2 == 1 else (hs*hs)//2
num_blanks = min(num_blanks, max_blanks) # 确保不超过最大空格数
positions = list(range(hs*hs))
blanks = []
# 尝试生成不连续的空格
max_attempts = 1000
attempts = 0
while len(blanks) < num_blanks and attempts < max_attempts:
temp_blanks = []
remaining_positions = positions.copy()
while len(temp_blanks) < num_blanks and remaining_positions:
pos = random.choice(remaining_positions)
row = pos // hs
col = pos % hs
# 检查是否与已有空格相邻
valid = True
for blank in temp_blanks:
blank_row = blank // hs
blank_col = blank % hs
# 检查是否在同一行或同一列且相邻
if (row == blank_row and abs(col - blank_col) == 1) or \
(col == blank_col and abs(row - blank_row) == 1):
valid = False
break
if valid:
temp_blanks.append(pos)
# 移除相邻位置
adjacent_positions = []
if col > 0: adjacent_positions.append(pos-1)
if col < hs-1: adjacent_positions.append(pos+1)
if row > 0: adjacent_positions.append(pos-hs)
if row < hs-1: adjacent_positions.append(pos+hs)
for adj_pos in adjacent_positions:
if adj_pos in remaining_positions:
remaining_positions.remove(adj_pos)
remaining_positions.remove(pos) if pos in remaining_positions else None
if len(temp_blanks) == num_blanks:
blanks = temp_blanks
break
attempts += 1
# 如果无法生成不连续的空格,则返回随机空格
if len(blanks) < num_blanks:
blanks = random.sample(positions, num_blanks)
return blanks
# 修改这里 - 使用empty_counts而不是g
for kk in range(len(empty_counts)): # 遍历每个空缺数
ll=['{}'.format(hs)]
mm=['11']
nn=['36']
for r in range(len(ll)):
if hs ==int(ll[r]):
db=int(mm[r][0])
cb=int(mm[r][1])
size=int(nn[r])
imagePath=path+r'\\零时Word'
os.makedirs(imagePath,exist_ok=True)
imagePatha=path+fr'\02_动物数独_{hs}宫格_答案卡_图片'
imagePathq=path+fr'\01_动物数独_{hs}宫格_任务卡_图片'
os.makedirs(imagePatha,exist_ok=True)
os.makedirs(imagePathq,exist_ok=True)
db_size = hs*db
cb_size= hs*cb
print('{}宫格排列底{}侧{}共{}套,底边格子数{}'.format(hs,db,cb,db*cb,db_size))
print('{}宫格排列底{}侧{}共{}套,侧边格子数{}'.format(hs,db,cb,db*cb,cb_size))
bgszm=[]
for a in range(0,cb_size,hs):
for b in range(0,db_size,hs):
bgszm.append('{}{}'.format('%02d'%a,'%02d'%b))
print(bgszm)
start_coordinates = [(int(s[0:2]), int(s[2:4])) for s in bgszm]
cell_coordinates = []
for start_coord in start_coordinates:
i, j = start_coord
subgrid_coordinates = []
for x in range(hs):
for y in range(hs):
subgrid_coordinates.append((i + x, j + y))
cell_coordinates.append(subgrid_coordinates)
bg=[]
for coordinates in cell_coordinates:
for c in coordinates:
print(c)
s = ''.join(str(num).zfill(2) for num in c)
print(str(s))
bg.append(s)
print(bg)
num =1
P=[]
for z in range(num):
P.clear()
for j in range(db*cb):
# python
def generate_sudoku_board():
board = [[0] * hs for _ in range(hs)]
def filling_board(row, col):
if row == hs:
return True
next_row = row if col < hs-1 else row + 1
next_col = (col + 1) % hs
# Only apply box constraints for 4×4 and 9×9
apply_box_constraints = hs in [4, 9]
if apply_box_constraints:
box_size = int(math.sqrt(hs))
box_row = row // box_size
box_col = col // box_size
available_numbers = random.sample(range(1, hs+1), hs)
for num in available_numbers:
# Always check row and column
valid = (num not in board[row] and
all(board[i][col] != num for i in range(hs)))
# Additional box check for 4×4 and 9×9
if valid and apply_box_constraints:
valid = all(num != board[i][j]
for i in range(box_row*box_size, (box_row+1)*box_size)
for j in range(box_col*box_size, (box_col+1)*box_size))
if valid:
board[row][col] = num
if filling_board(next_row, next_col):
return True
board[row][col] = 0
return False
filling_board(0, 0)
return board
board1 = generate_sudoku_board()
def create_board1():
return board1
def create_board2():
global board1
board2 = copy.deepcopy(board1)
# 使用empty_counts[kk]获取当前关卡的空缺数
num_blanks = empty_counts[kk]
# 使用新方法生成不连续的空格
blanks = generate_non_adjacent_blanks(hs, num_blanks)
for i in blanks:
row = i // hs
col = i % hs
board2[row][col] = 0
return board2
v1 = create_board1()
v2 = create_board2()
v=v1+v2
print(v)
P = ['' if a2 == 0 else a2 for a1 in v for a2 in a1]
print(P)
print(len(P))
half_len = int(len(P) // 2)
Q = [P[i:i+half_len] for i in range(0, len(P), half_len)]
print(Q)
time.sleep(3)
print('------答案卡和题目卡------')
title=['答案卡','任务卡']
imagePath1=path+r'\答案卡1'
imagePath2=path+r'\任务卡1'
os.makedirs(imagePath1,exist_ok=True)
os.makedirs(imagePath2,exist_ok=True)
ti=[path+r'\答案卡1',path+r'\任务卡1']
for tt in range(len(Q)):
doc = Document(path+fr'\动物数独(横板{hs}宫格).docx')
table = doc.tables[0]
for b1 in range(0,1):
cell_00 = table.cell(0, b1)
cell_00_paragraph = cell_00.paragraphs[0]
cell_00_paragraph.text =f"动物数独 {hs}*{hs} 第 {kk+1} 关 {title[tt]}"
cell_00_paragraph.style.font.bold = True
cell_00_paragraph.style.font.size = Pt(24)
cell_00_paragraph.style.font.name = "黑体"
cell_00_paragraph.alignment = WD_PARAGRAPH_ALIGNMENT.CENTER
table = doc.tables[1]
for t in range(0,len(bg)):
pp=int(bg[t][0:2])
qq=int(bg[t][2:4])
k=str(Q[tt][t])
print(pp,qq,k)
run=table.cell(pp,qq).paragraphs[0].add_run(k)
run.font.name = '黑体'
run.font.size = Pt(size)
run.font.color.rgb = RGBColor(0,0,0)
run.bold=True
r = run._element
r.rPr.rFonts.set(qn('w:eastAsia'), '黑体')
table.cell(pp,qq).paragraphs[0].alignment = WD_PARAGRAPH_ALIGNMENT.CENTER
doc.save(ti[tt]+fr'\{z+1:02d}.docx')
time.sleep(3)
print('------4、每张word转为pdf----')
from docx import Document
from docx.shared import Cm
animal_path = path+r'\02动物图片'
file_paths = [os.path.join(animal_path, file_name) for file_name in os.listdir(animal_path)]
print(file_paths)
file_paths=file_paths[start:end]
doc = Document(ti[tt]+fr'\{z+1:02d}.docx')
tables = doc.tables
for table in tables:
for i, row in enumerate(table.rows):
for j, cell in enumerate(row.cells):
cell_text = cell.text
for x in range(0,hs):
if cell_text == f'{x+1}':
cell.text = ''
run = cell.paragraphs[0].add_run()
for n in range(len(gzsgg)):
if hs==gzsgg[n]:
run.add_picture(file_paths[x], width=Cm(gzsize[n]), height=Cm(gzsize[n]))
run.alignment = WD_PARAGRAPH_ALIGNMENT.CENTER
cell.vertical_alignment = WD_ALIGN_PARAGRAPH.CENTER
cell.paragraphs[0].alignment = WD_ALIGN_PARAGRAPH.CENTER
doc.save(ti[tt]+fr'\{z+1:02d}.docx')
time.sleep(3)
from docx2pdf import convert
inputFile = ti[tt]+fr'\{z+1:02d}.docx'
outputFile =ti[tt]+fr'\{z+1:02d}.pdf'
f1 = open(outputFile, 'w')
f1.close()
convert(inputFile, outputFile)
time.sleep(3)
print('----------更改pdf新名字------------')
tii=[path+fr'\02_动物数独_{hs}宫格_答案卡_图片',path+fr'\01_动物数独_{hs}宫格_任务卡_图片']
for t3 in range(len(tii)):
pdf_lst = [f for f in os.listdir(ti[t3]) if f.endswith('.pdf')]
pdf_path = os.path.join(ti[t3], pdf_lst[0])
print(pdf_path)
# 修改这里 - 使用empty_counts[kk]而不是w[kk]
new_file_name = f"{(t3+1):02}_动物数独_{hs}宫格_{title[t3]}_难度{kk+1:02d}_空{empty_counts[kk]:03d}格({db}乘{cb}等于{num}份{db*cb}张).pdf"
output_path = os.path.join(tii[t3], new_file_name)
print(output_path)
os.rename(pdf_path, output_path)
time.sleep(3)
shutil.rmtree(ti[t3])
time.sleep(3)
print('----------第4步:把都有16管PDF关卡变png------------')
from win32com.client import Dispatch
import os
import re
import fitz
wdFormatPDF = 17
zoom_x=2
zoom_y=2
rotation_angle=0
li=[path+fr'\02_动物数独_{hs}宫格_答案卡_图片',path+fr'\01_动物数独_{hs}宫格_任务卡_图片']
for l in li:
for root, dirs, files in os.walk(l):
for file in files:
if re.search('\.pdf$', file):
filename = os.path.abspath(root + "\\" + file)
print(filename)
pdf = fitz.open(filename)
for pg in range(0, pdf.pageCount):
page = pdf[pg]
trans = fitz.Matrix(zoom_x, zoom_y).preRotate(rotation_angle)
pm = page.getPixmap(matrix=trans, alpha=True)
pm.writePNG(filename.replace('.pdf', '') + str(pg+1) + ".png")
pdf.close()
for parent, dirnames, filenames in os.walk(l):
for fn in filenames:
if fn.lower().endswith('.pdf'):
os.remove(os.path.join(parent, fn))
print('-----第三板块、把动物任务卡和答案卡一套分别做成1页1份,1页2份,1页6份的pdf-------')
psize=[9.39,9.39,14.1,14.1,19.6,19.6]
pg=[6,6,2,2,1,1]
gzs=[2,2,2,2,1,1]
nh=[1,2,1,2,1,2]
for x in range(len(pg)):
imagePath11=path+fr'\04_动物数独_{hs}宫格_答案卡_pdf'
imagePath22=path+fr'\03_动物数独_{hs}宫格_任务卡_pdf'
os.makedirs(imagePath11,exist_ok=True)
os.makedirs(imagePath22,exist_ok=True)
tiii=[path+fr'\04_动物数独_{hs}宫格_答案卡_pdf',path+fr'\03_动物数独_{hs}宫格_任务卡_pdf',path+fr'\04_动物数独_{hs}宫格_答案卡_pdf',path+fr'\03_动物数独_{hs}宫格_任务卡_pdf',path+fr'\04_动物数独_{hs}宫格_答案卡_pdf',path+fr'\03_动物数独_{hs}宫格_任务卡_pdf']
tii=[path+fr'\02_动物数独_{hs}宫格_答案卡_图片',path+fr'\01_动物数独_{hs}宫格_任务卡_图片',path+fr'\02_动物数独_{hs}宫格_答案卡_图片',path+fr'\01_动物数独_{hs}宫格_任务卡_图片',path+fr'\02_动物数独_{hs}宫格_答案卡_图片',path+fr'\01_动物数独_{hs}宫格_任务卡_图片']
title=['答案卡','任务卡','答案卡','任务卡','答案卡','任务卡']
imagePath=path+r'\\零时Word'
os.makedirs(imagePath,exist_ok=True)
doc = Document(path +fr'\动物数独({pg[x]}图关卡).docx')
tables = doc.tables[0]
file_paths = [os.path.join(tii[x], file) for file in os.listdir(tii[x])]
pic_list_six = [file_paths[i:i+int(pg[x])] for i in range(0, len(file_paths), int(pg[x]))]
print(pic_list_six)
print(len(pic_list_six))
for group_index, group in enumerate(pic_list_six):
doc = Document(path + fr'\动物数独({pg[x]}图关卡).docx')
for cell_index, image_file in enumerate(group):
cc=float(psize[x])
table = doc.tables[0]
cell = table.cell(int(cell_index /gzs[x]), cell_index % gzs[x])
cell_paragraph = cell.paragraphs[0]
cell_paragraph.clear()
run = cell_paragraph.add_run()
run.add_picture(os.path.join(image_file), width=Cm(cc), height=Cm(cc))
cell_paragraph.alignment = 1
doc.save(imagePath + fr'\{group_index + 1:02d}页.docx')
inputFile = imagePath + fr'\{group_index + 1:02d}页.docx'
outputFile = imagePath + fr'\{group_index + 1:02d}页.pdf'
convert(inputFile, outputFile)
time.sleep(3)
pdf_lst = [f for f in os.listdir(imagePath) if f.endswith('.pdf')]
pdf_lst = [os.path.join(imagePath, filename) for filename in pdf_lst]
pdf_lst.sort()
file_merger = PdfMerger()
for pdf in pdf_lst:
print(pdf)
file_merger.append(pdf)
file_merger.write(tiii[x]+ fr"\{nh[x]:02} _动物数独_{hs}宫格_{title[x]}_1页{pg[x]}关(一关卡{psize[x]}CM).pdf")
time.sleep(1)
file_merger.close()
shutil.rmtree(imagePath)
# print('-----第四板块、交叉合并有答案6套,无答案6套(1-1-1、1-1,1-2-2,1-2,2-1-1,2-1……----')
newgz=path+fr'\(打印)动物数独{hs}宫格 共{len(empty_counts)}关'
os.makedirs(newgz,exist_ok=True)
# 在代码的最后部分,替换原有的删除文件夹操作为移动文件夹操作
# 定义要移动的文件夹列表
folders_to_move = [
path+fr'\04_动物数独_{hs}宫格_答案卡_pdf',
path+fr'\03_动物数独_{hs}宫格_任务卡_pdf',
path+fr'\02_动物数独_{hs}宫格_答案卡_图片',
path+fr'\01_动物数独_{hs}宫格_任务卡_图片',
path+fr'\05_动物数独_{hs}宫格_操作卡_pdf'
]
# 移动文件夹到newgz目录
for folder in folders_to_move:
if os.path.exists(folder):
dest_folder = os.path.join(newgz, os.path.basename(folder))
# 如果目标文件夹已存在,先删除
if os.path.exists(dest_folder):
shutil.rmtree(dest_folder)
shutil.move(folder, newgz)
print(f"已移动文件夹: {folder} -> {newgz}")
# end_time = datetime.now()
# elapsed_time = end_time - start_time
# print(f"动物数独{hs}宫格程序开始时间:{start_time}")
# print(f"动物数独{hs}宫格程序结束时间:{end_time}")
# print("程序运行时间:", elapsed_time)
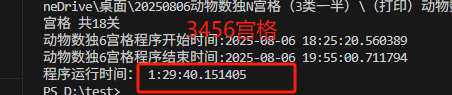
end_time = datetime.now()
elapsed_time = end_time - start_time
print(f"动物数独{hs}宫格程序开始时间:{start_time}")
print(f"动物数独{hs}宫格程序结束时间:{end_time}")
print("程序运行时间:", elapsed_time)
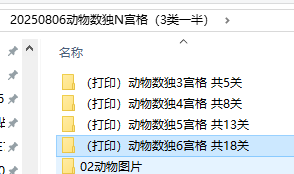
生成的文件夹样式
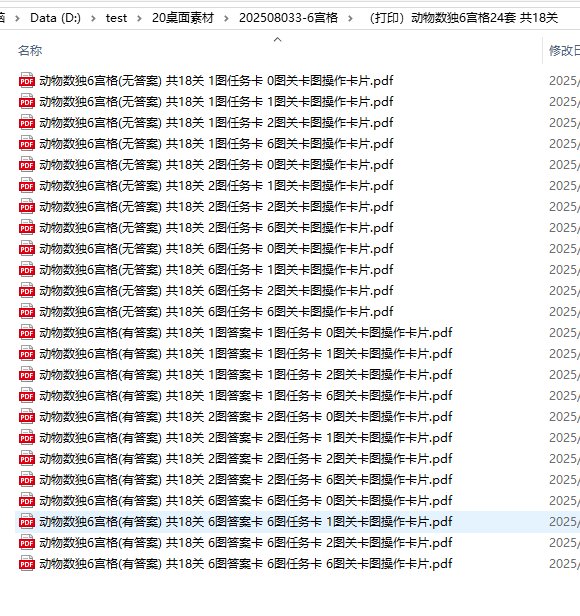
文件夹内部的内容


打印用的任务卡,任选尺寸
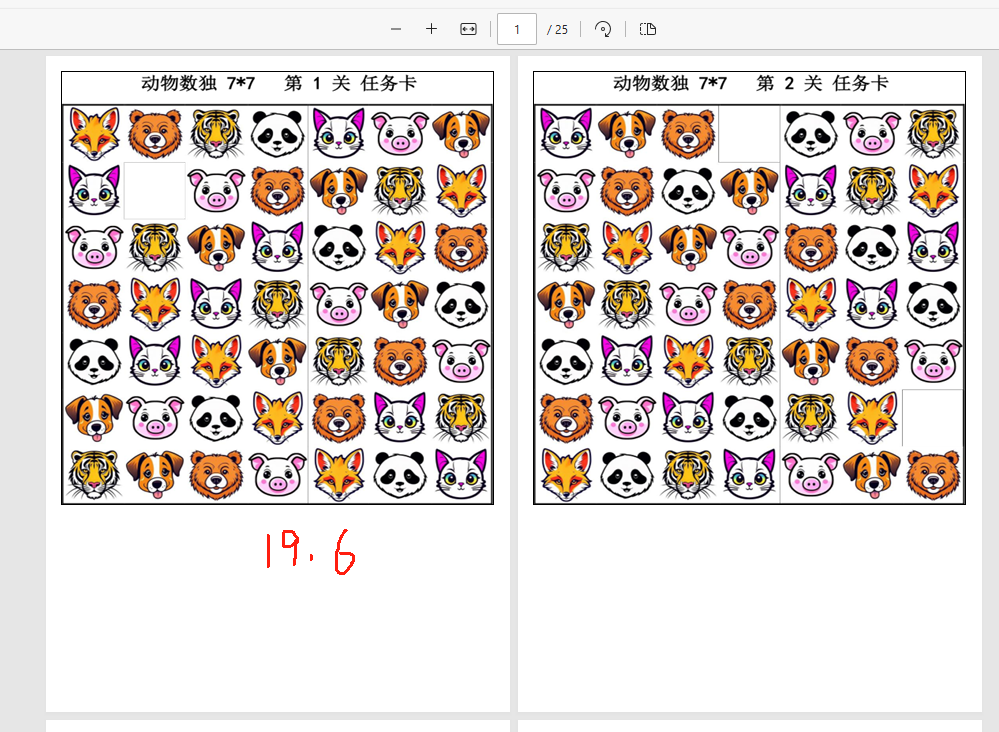
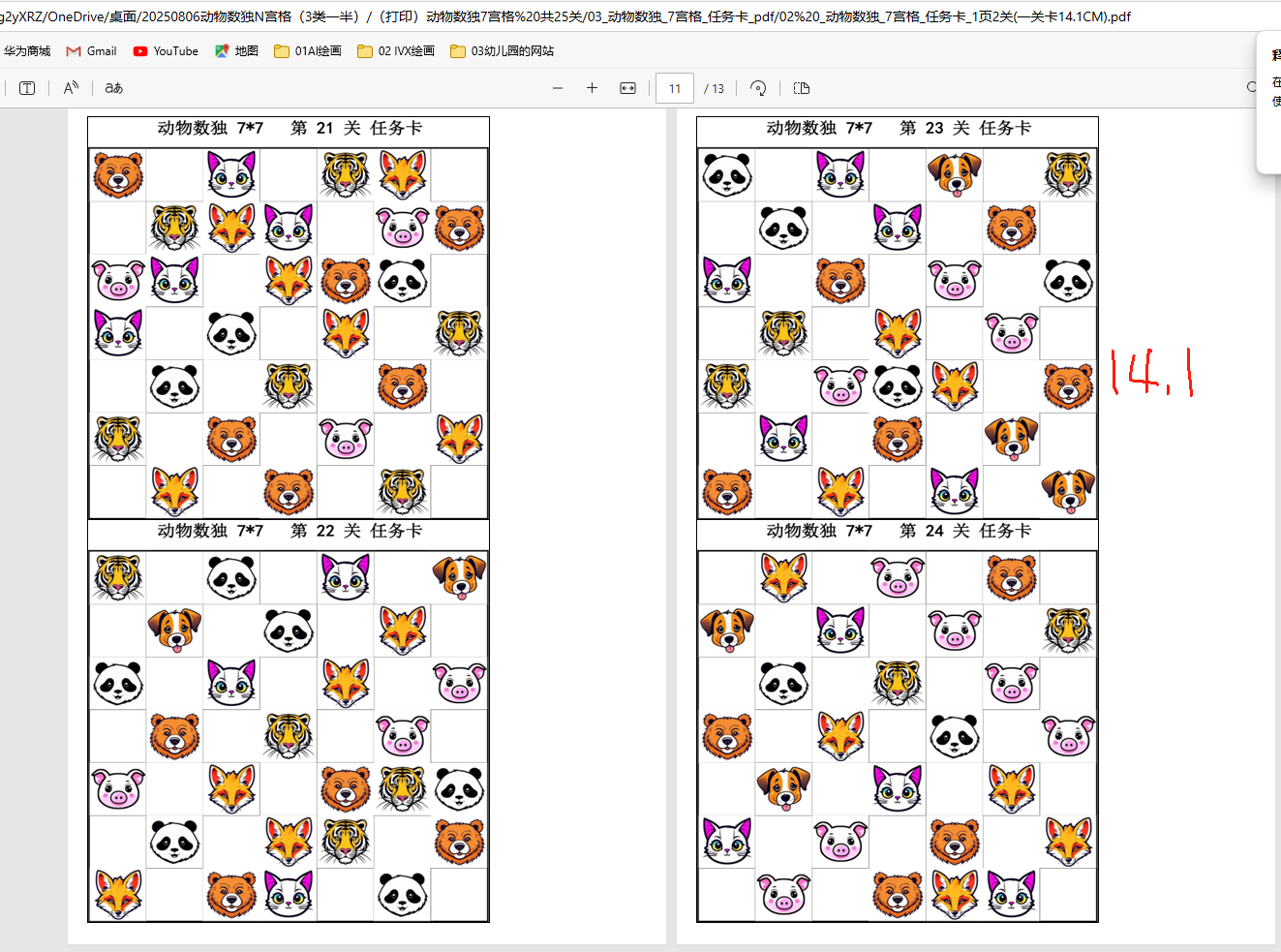
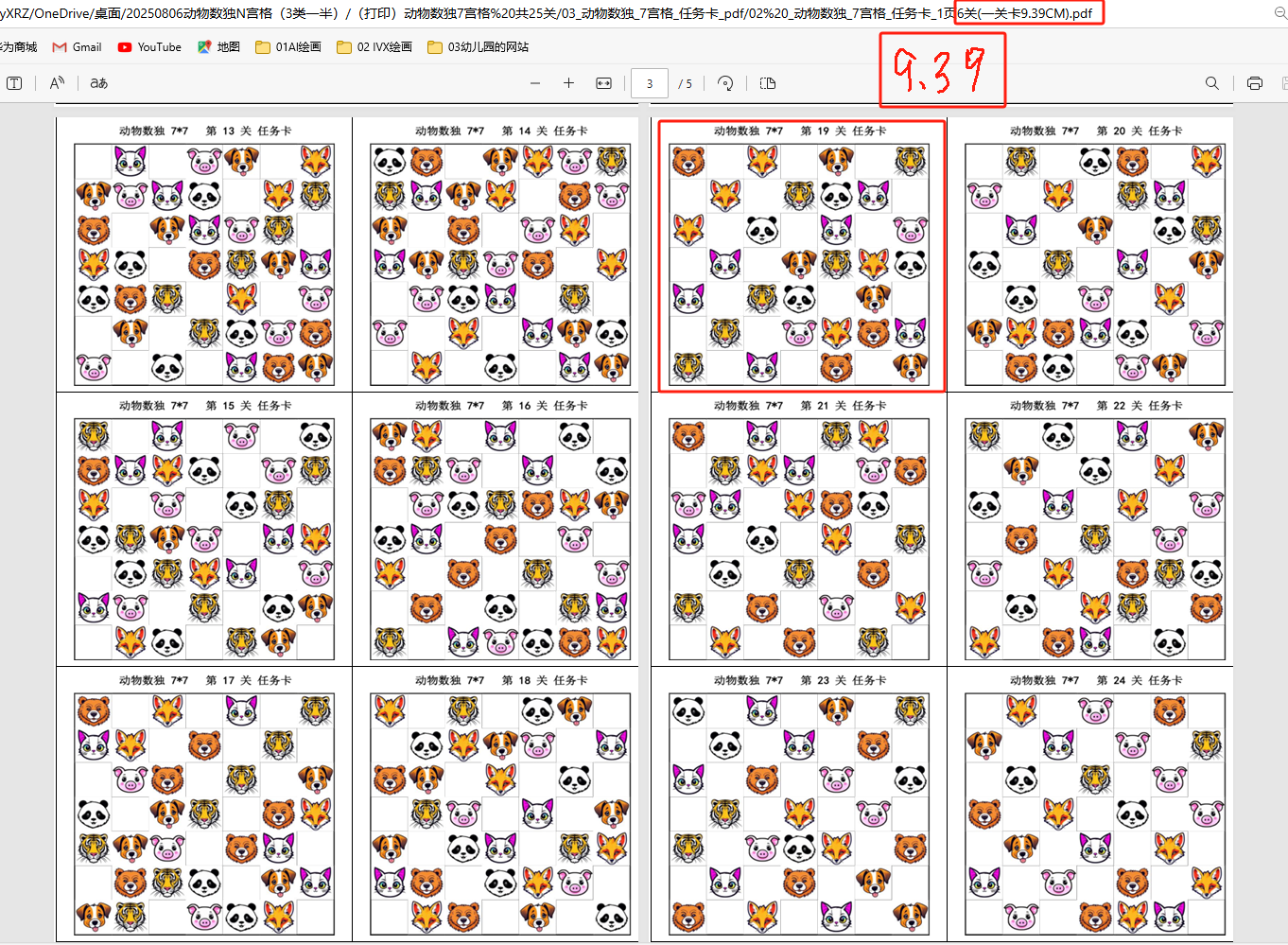
打印用的答案卡,任选尺寸
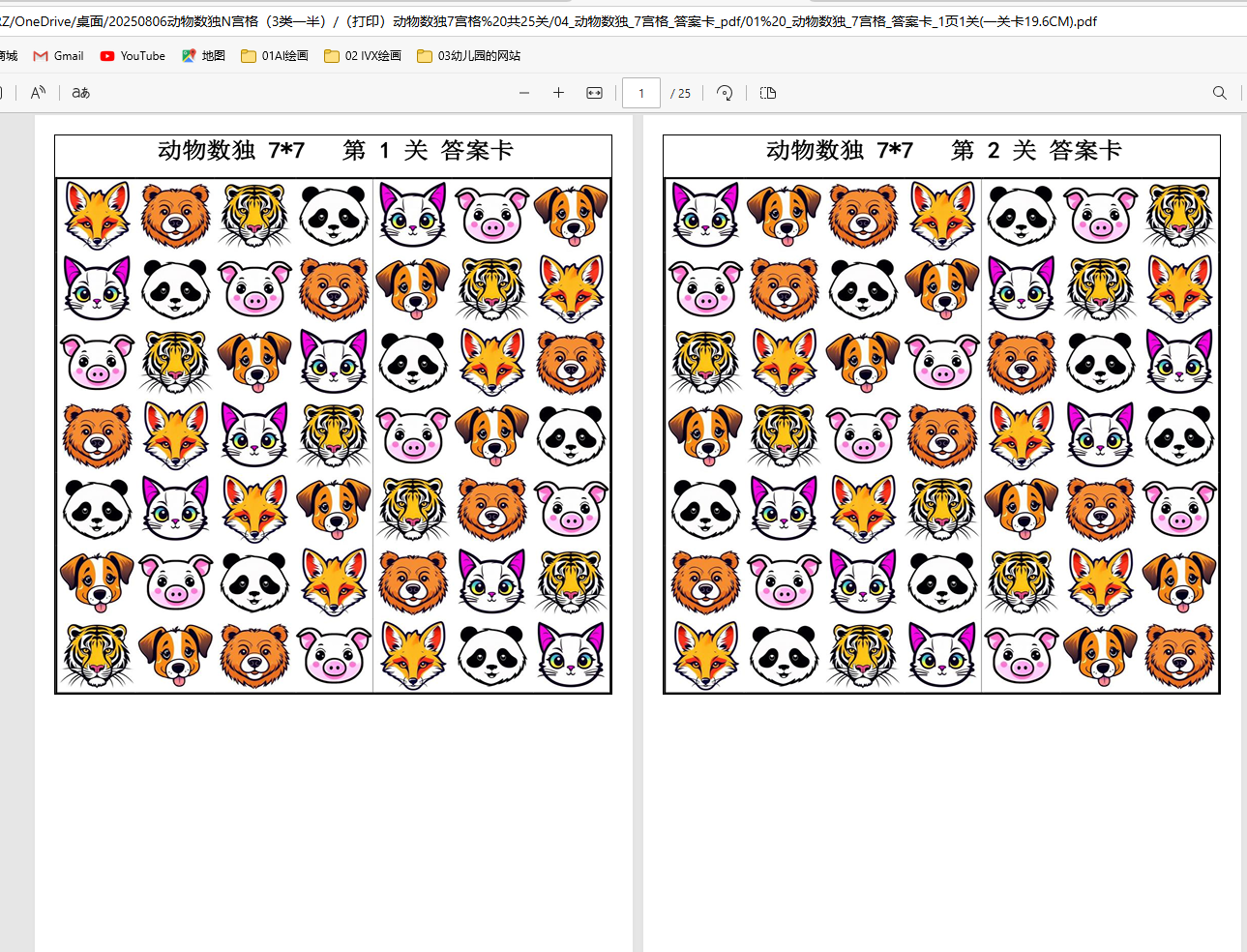
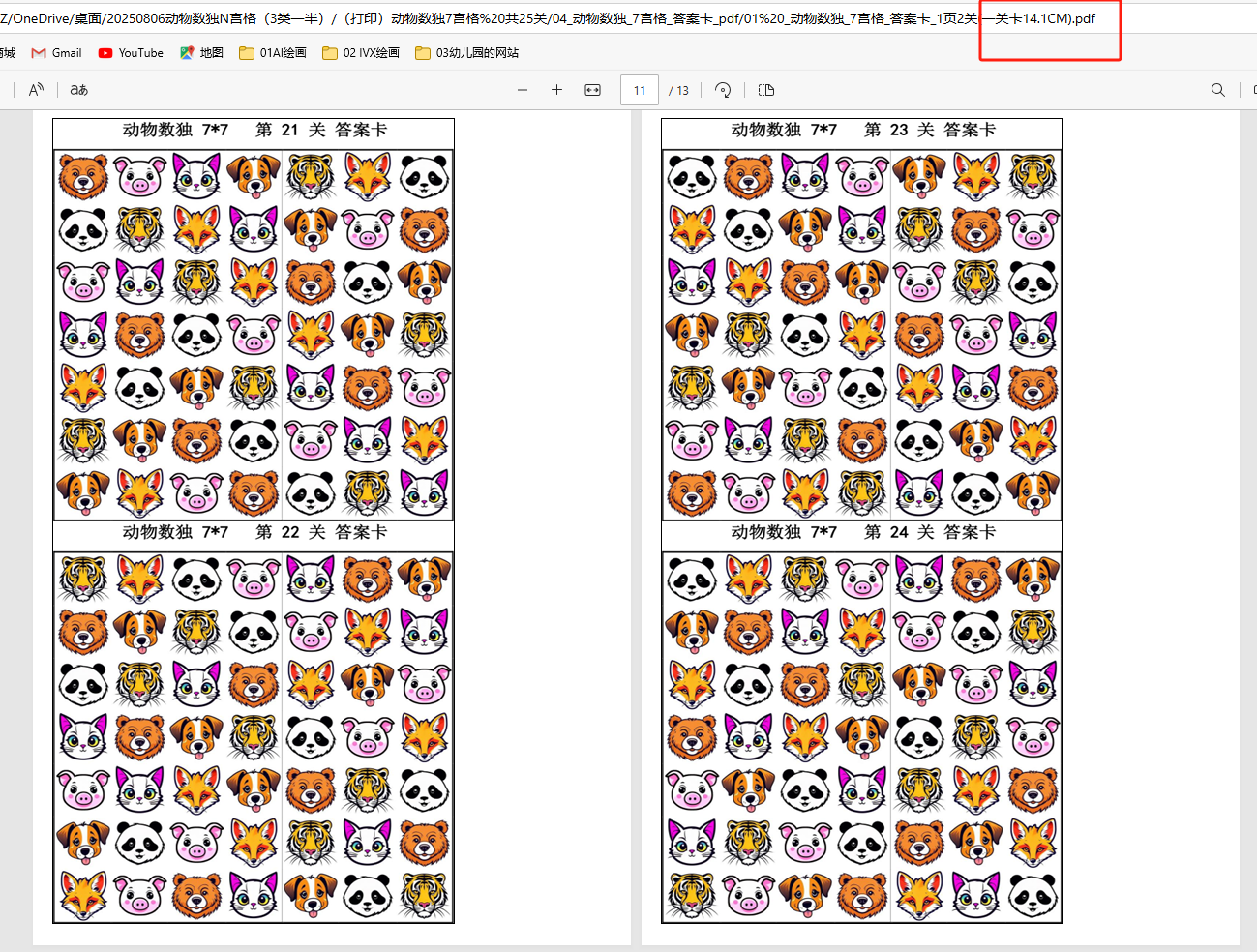

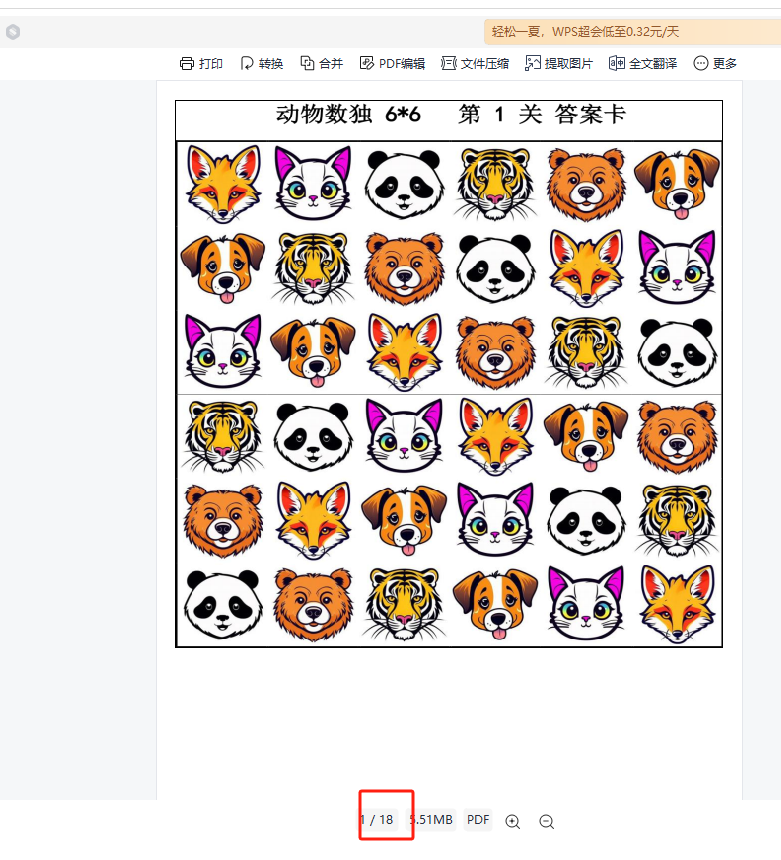
打印用的操作卡,任选尺寸

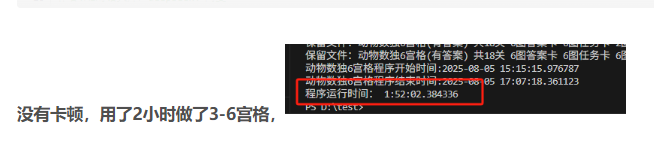
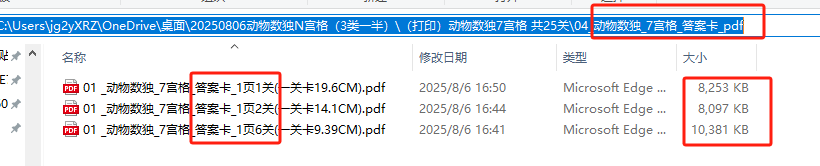
结果发现这些pdf包含了任务卡、答案卡,操作卡(还是合并的。)因为用时还是很长。
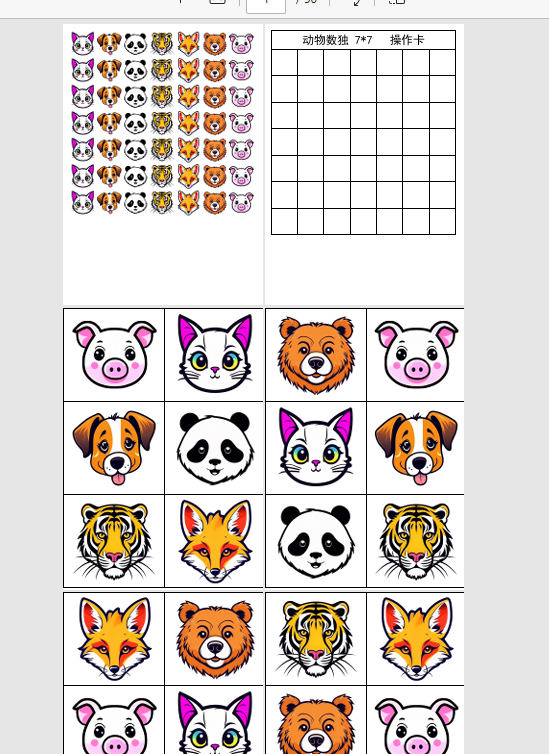
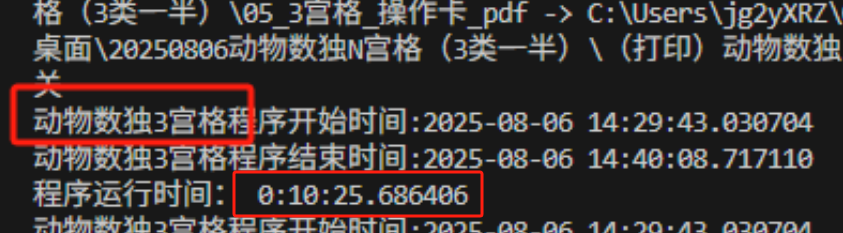

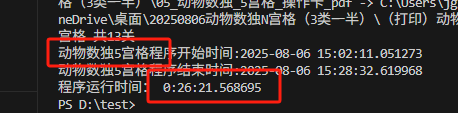
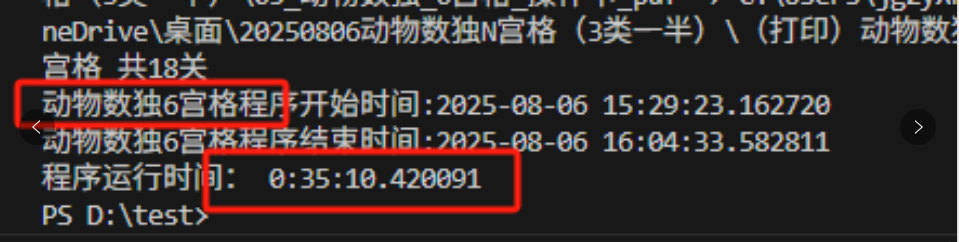
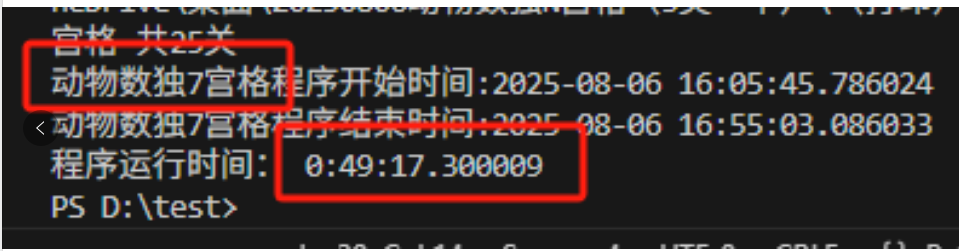

重新修改代码,发现问题出在,没有删除零时文件夹,当第一次生成1图(9个pd),第二次生成5个文件夹替换了1-5个,但6-9个还是1图的。就这样导致了文件很多。
最终代码
# -*- coding:utf-8 -*-
'''
制作动物/脸谱数独N宫格通用版(3-10的黏贴关卡 A4 1图2图6图的所有组合 还有一个限定A4大小的0图(3-6宫格)
1.无答案:9种3:3,两两组合
2.有答案:27种 3:3:3,三三组合(实际需要其中9种)
3.横竖两个不能都是空格,空格尽量分散排列,如9格,目前1-5可以分散,空额不相连,6-9不行)
4.奇数宫格:(奇数*奇数+1)/2;偶数宫格:(偶数*偶数+1)/2
5.一次性生成3-6宫格,计算总时长
6.不需要24套,只要做3个文件夹操作卡(0,1,2,6图)、任务卡(1,2,6图)、答案卡(1,2,6图)
作者:AI对话大师,deepseek、阿夏
时间:2025年08月06日
'''
import os,math
import time
from docx import Document
from docx.shared import Cm, Pt, RGBColor
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
from docx.enum.text import WD_ALIGN_PARAGRAPH
from docx.oxml.ns import qn
from docxtpl import DocxTemplate
import pandas as pd
from docx2pdf import convert
from win32com.client import constants, gencache
from win32com.client.gencache import EnsureDispatch
from datetime import datetime
import random
import shutil
import xlwt
import xlrd
from PyPDF2 import PdfMerger
from docx.shared import Pt, Cm, RGBColor
from docx.oxml.shared import qn
start_time = datetime.now()
# 改为循环处理多个宫格数
hsall_list = list(range(3,7)) # 要生成的宫格数列表
for hsall in hsall_list:
start = 0
end = hsall
hs = hsall
# 为每个宫格数创建独立的文件夹
path = fr'C:\Users\jg2yXRZ\OneDrive\桌面\20250806动物数独N宫格(3类一半)'
os.makedirs(path, exist_ok=True)
# 原有的A4尺寸等设置保持不变
A4size = [6.5, 4.88, 3.9, 3.25, 2.79, 2.44, 2.17]
A4gz = [3, 4, 5, 6, 7, 8, 9]
A4pg=[3,4,5,6,7,8,9]
A4gzs=[3,4,5,6,7,8,9]
psize=[19.6,14.1,9.39]
gzsize=[6.4,4.8,3.84,3.2,2.74,2.39,2.12,1.91]
gzsgg=list(range(3, 10))
pg=[1,2,6]
gzs=[1,2,2]
print('-----第一板块、动物操作卡(大图片卡一页1图、1页2图 一页6图)-------')
# Get page settings based on hs value
for w in range(len(A4gz)):
if hs == A4gz[w]:
psize.append(A4size[w])
pg = [1, 2, 6, A4pg[w]]
gzs = [1, 2, 2, A4gzs[w]]
k = ['1图关卡', '2图关卡', '6图关卡', f'A4的{hs}图卡片']
print(k)
for pt in range(len(pg)):
# Create temp folders
temp_word_path = os.path.join(path, '零时Word')
temp_pdf_path = os.path.join(path, f'05_动物数独_{hs}宫格_操作卡_pdf')
os.makedirs(temp_word_path, exist_ok=True)
os.makedirs(temp_pdf_path, exist_ok=True)
# Load template document
doc = Document(os.path.join(path, f'动物数独({k[pt]}).docx'))
table = doc.tables[0]
# Get animal images
pic_folder = os.path.join(path, '02动物图片')
pic_list = [os.path.join(pic_folder, f) for f in os.listdir(pic_folder)][start:end] * hs
# Group images based on layout
group_size = pg[pt]*pg[pt] if pt == 3 else pg[pt]
groups = [pic_list[i:i + group_size] for i in range(0, len(pic_list), group_size)]
for group_idx, group in enumerate(groups):
doc = Document(os.path.join(path, f'动物数独({k[pt]}).docx'))
table = doc.tables[0]
for cell_idx, img_file in enumerate(group):
row = int(cell_idx / gzs[pt])
col = cell_idx % gzs[pt]
cell = table.cell(row, col)
cell.paragraphs[0].clear()
if os.path.exists(img_file):
run = cell.paragraphs[0].add_run()
run.add_picture(img_file, width=Cm(psize[pt]), height=Cm(psize[pt]))
cell.paragraphs[0].alignment = 1
# Add title for A4 layout
if pt == 3:
title_table = doc.tables[1]
title_cell = title_table.cell(0, 0)
title_cell.text = f'动物数独 {hs}*{hs} 操作卡'
para = title_cell.paragraphs[0]
para.alignment = WD_ALIGN_PARAGRAPH.CENTER
run = para.runs[0]
run.font.name = '黑体'
run.font.size = Pt(35)
run.font.color.rgb = RGBColor(0, 0, 0)
run._element.rPr.rFonts.set(qn('w:eastAsia'), '黑体')
# Save and convert to PDF
doc.save(os.path.join(temp_word_path, f'{group_idx+1:02d}页.docx'))
convert(os.path.join(temp_word_path, f'{group_idx+1:02d}页.docx'),
os.path.join(temp_word_path, f'{group_idx+1:02d}页.pdf'))
time.sleep(3)
# Merge PDFs
pdf_files = sorted([os.path.join(temp_word_path, f) for f in os.listdir(temp_word_path) if f.endswith('.pdf')])
merger = PdfMerger()
for pdf in pdf_files:
merger.append(pdf)
output_name = f"01_动物数独_{hs}宫格_操作卡_1页{hs*hs}图(一图{A4size[pt]}CM,只要打印1张A4).pdf" if pt == 3 else f"01_动物数独_{hs}宫格_操作卡_1页{k[pt][:-2]}(一图{psize[pt]}CM).pdf"
merger.write(os.path.join(temp_pdf_path, output_name))
merger.close()
# Clean up
# Clean up
shutil.rmtree(temp_word_path)
print('-----第二板块、动物任务卡和答案卡一套,只要JPG-------')
import random
from win32com.client import constants, gencache
from win32com.client import genpy
from win32com.client.gencache import EnsureDispatch
from docx import Document
from docx.shared import Pt, RGBColor
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
from docx.oxml.ns import qn
from docx.enum.text import WD_ALIGN_PARAGRAPH
import docxtpl
import pandas as pd
from docx2pdf import convert
from docx.oxml.ns import nsdecls
from docx.oxml import parse_xml
import copy
print('------3-1、生成指定数量的关卡(按最大空缺数限制)------')
n = hsall # 宫格数(例如3)
g = n * n # 总格子数(例如9)
# 根据宫格数确定最大空缺数
if n % 2 == 1: # 奇数宫格
max_empty = (g + 1) // 2 # 例如3宫格:(9+1)/2=5
else: # 偶数宫格
max_empty = g // 2 # 例如4宫格:16/2=8
# 只生成1到max_empty关(例如3宫格只生成5关)
a = []
for empty in range(1, max_empty + 1): # 直接按空缺数生成
# 计算对应的百分比(四舍五入)
percentage = round(empty * 100 / g)
print(f'{n}宫格,难度{percentage:03d},抽取{percentage:03d}%:实际有{empty:03d}空,已有图案{g-empty:03d}')
a.append(f'{n}宫格,难度{percentage:03d},抽取{percentage:03d}%:实际有{empty:03d}空,已有图案{g-empty:03d}')
# 去重和排序(虽然现在应该已经是有序且不重复的)
b = []
for element in a:
parts = element.split(":")
info = parts[1]
b.append(info)
b = list(set(b))
b.sort(reverse=False)
f = []
for d in range(len(b)):
for c in a:
if c[-15:] == b[d]:
f.append(c)
break
# 移除第一个(空0的无效项)如果有的话
if f and int(f[0][20:23]) == g: # 检查是否全满(空0)
f.pop(0)
print(f'实际生成关卡数:{len(f)}')
# 提取空缺数和已有图案数
empty_counts = []
filled_counts = []
for p in f:
empty_counts.append(int(p[20:23]))
filled_counts.append(int(p[12:15]))
print('空缺数序列:', empty_counts)
print('已有图案数:', filled_counts)
print('------2、制作宫格随机数字------')
def generate_non_adjacent_blanks(hs, num_blanks):
"""生成不连续的空格位置"""
max_blanks = (hs*hs + 1)//2 if hs % 2 == 1 else (hs*hs)//2
num_blanks = min(num_blanks, max_blanks) # 确保不超过最大空格数
positions = list(range(hs*hs))
blanks = []
# 尝试生成不连续的空格
max_attempts = 1000
attempts = 0
while len(blanks) < num_blanks and attempts < max_attempts:
temp_blanks = []
remaining_positions = positions.copy()
while len(temp_blanks) < num_blanks and remaining_positions:
pos = random.choice(remaining_positions)
row = pos // hs
col = pos % hs
# 检查是否与已有空格相邻
valid = True
for blank in temp_blanks:
blank_row = blank // hs
blank_col = blank % hs
# 检查是否在同一行或同一列且相邻
if (row == blank_row and abs(col - blank_col) == 1) or \
(col == blank_col and abs(row - blank_row) == 1):
valid = False
break
if valid:
temp_blanks.append(pos)
# 移除相邻位置
adjacent_positions = []
if col > 0: adjacent_positions.append(pos-1)
if col < hs-1: adjacent_positions.append(pos+1)
if row > 0: adjacent_positions.append(pos-hs)
if row < hs-1: adjacent_positions.append(pos+hs)
for adj_pos in adjacent_positions:
if adj_pos in remaining_positions:
remaining_positions.remove(adj_pos)
remaining_positions.remove(pos) if pos in remaining_positions else None
if len(temp_blanks) == num_blanks:
blanks = temp_blanks
break
attempts += 1
# 如果无法生成不连续的空格,则返回随机空格
if len(blanks) < num_blanks:
blanks = random.sample(positions, num_blanks)
return blanks
# 修改这里 - 使用empty_counts而不是g
for kk in range(len(empty_counts)): # 遍历每个空缺数
ll=['{}'.format(hs)]
mm=['11']
nn=['36']
for r in range(len(ll)):
if hs ==int(ll[r]):
db=int(mm[r][0])
cb=int(mm[r][1])
size=int(nn[r])
imagePath=path+r'\\零时Word'
os.makedirs(imagePath,exist_ok=True)
imagePatha=path+fr'\02_动物数独_{hs}宫格_答案卡_图片'
imagePathq=path+fr'\01_动物数独_{hs}宫格_任务卡_图片'
os.makedirs(imagePatha,exist_ok=True)
os.makedirs(imagePathq,exist_ok=True)
db_size = hs*db
cb_size= hs*cb
print('{}宫格排列底{}侧{}共{}套,底边格子数{}'.format(hs,db,cb,db*cb,db_size))
print('{}宫格排列底{}侧{}共{}套,侧边格子数{}'.format(hs,db,cb,db*cb,cb_size))
bgszm=[]
for a in range(0,cb_size,hs):
for b in range(0,db_size,hs):
bgszm.append('{}{}'.format('%02d'%a,'%02d'%b))
print(bgszm)
start_coordinates = [(int(s[0:2]), int(s[2:4])) for s in bgszm]
cell_coordinates = []
for start_coord in start_coordinates:
i, j = start_coord
subgrid_coordinates = []
for x in range(hs):
for y in range(hs):
subgrid_coordinates.append((i + x, j + y))
cell_coordinates.append(subgrid_coordinates)
bg=[]
for coordinates in cell_coordinates:
for c in coordinates:
print(c)
s = ''.join(str(num).zfill(2) for num in c)
print(str(s))
bg.append(s)
print(bg)
num =1
P=[]
for z in range(num):
P.clear()
for j in range(db*cb):
# python
def generate_sudoku_board():
board = [[0] * hs for _ in range(hs)]
def filling_board(row, col):
if row == hs:
return True
next_row = row if col < hs-1 else row + 1
next_col = (col + 1) % hs
# Only apply box constraints for 4×4 and 9×9
apply_box_constraints = hs in [4, 9]
if apply_box_constraints:
box_size = int(math.sqrt(hs))
box_row = row // box_size
box_col = col // box_size
available_numbers = random.sample(range(1, hs+1), hs)
for num in available_numbers:
# Always check row and column
valid = (num not in board[row] and
all(board[i][col] != num for i in range(hs)))
# Additional box check for 4×4 and 9×9
if valid and apply_box_constraints:
valid = all(num != board[i][j]
for i in range(box_row*box_size, (box_row+1)*box_size)
for j in range(box_col*box_size, (box_col+1)*box_size))
if valid:
board[row][col] = num
if filling_board(next_row, next_col):
return True
board[row][col] = 0
return False
filling_board(0, 0)
return board
board1 = generate_sudoku_board()
def create_board1():
return board1
def create_board2():
global board1
board2 = copy.deepcopy(board1)
# 使用empty_counts[kk]获取当前关卡的空缺数
num_blanks = empty_counts[kk]
# 使用新方法生成不连续的空格
blanks = generate_non_adjacent_blanks(hs, num_blanks)
for i in blanks:
row = i // hs
col = i % hs
board2[row][col] = 0
return board2
v1 = create_board1()
v2 = create_board2()
v=v1+v2
print(v)
P = ['' if a2 == 0 else a2 for a1 in v for a2 in a1]
print(P)
print(len(P))
half_len = int(len(P) // 2)
Q = [P[i:i+half_len] for i in range(0, len(P), half_len)]
print(Q)
time.sleep(3)
print('------答案卡和题目卡------')
title=['答案卡','任务卡']
imagePath1=path+r'\答案卡1'
imagePath2=path+r'\任务卡1'
os.makedirs(imagePath1,exist_ok=True)
os.makedirs(imagePath2,exist_ok=True)
ti=[path+r'\答案卡1',path+r'\任务卡1']
for tt in range(len(Q)):
doc = Document(path+fr'\动物数独(横板{hs}宫格).docx')
table = doc.tables[0]
for b1 in range(0,1):
cell_00 = table.cell(0, b1)
cell_00_paragraph = cell_00.paragraphs[0]
cell_00_paragraph.text =f"动物数独 {hs}*{hs} 第 {kk+1} 关 {title[tt]}"
cell_00_paragraph.style.font.bold = True
cell_00_paragraph.style.font.size = Pt(24)
cell_00_paragraph.style.font.name = "黑体"
cell_00_paragraph.alignment = WD_PARAGRAPH_ALIGNMENT.CENTER
table = doc.tables[1]
for t in range(0,len(bg)):
pp=int(bg[t][0:2])
qq=int(bg[t][2:4])
k=str(Q[tt][t])
print(pp,qq,k)
run=table.cell(pp,qq).paragraphs[0].add_run(k)
run.font.name = '黑体'
run.font.size = Pt(size)
run.font.color.rgb = RGBColor(0,0,0)
run.bold=True
r = run._element
r.rPr.rFonts.set(qn('w:eastAsia'), '黑体')
table.cell(pp,qq).paragraphs[0].alignment = WD_PARAGRAPH_ALIGNMENT.CENTER
doc.save(ti[tt]+fr'\{z+1:02d}.docx')
time.sleep(3)
print('------4、每张word转为pdf----')
from docx import Document
from docx.shared import Cm
animal_path = path+r'\02动物图片'
file_paths = [os.path.join(animal_path, file_name) for file_name in os.listdir(animal_path)]
print(file_paths)
file_paths=file_paths[start:end]
doc = Document(ti[tt]+fr'\{z+1:02d}.docx')
tables = doc.tables
for table in tables:
for i, row in enumerate(table.rows):
for j, cell in enumerate(row.cells):
cell_text = cell.text
for x in range(0,hs):
if cell_text == f'{x+1}':
cell.text = ''
run = cell.paragraphs[0].add_run()
for n in range(len(gzsgg)):
if hs==gzsgg[n]:
run.add_picture(file_paths[x], width=Cm(gzsize[n]), height=Cm(gzsize[n]))
run.alignment = WD_PARAGRAPH_ALIGNMENT.CENTER
cell.vertical_alignment = WD_ALIGN_PARAGRAPH.CENTER
cell.paragraphs[0].alignment = WD_ALIGN_PARAGRAPH.CENTER
doc.save(ti[tt]+fr'\{z+1:02d}.docx')
time.sleep(3)
from docx2pdf import convert
inputFile = ti[tt]+fr'\{z+1:02d}.docx'
outputFile =ti[tt]+fr'\{z+1:02d}.pdf'
f1 = open(outputFile, 'w')
f1.close()
convert(inputFile, outputFile)
time.sleep(3)
print('----------更改pdf新名字------------')
tii=[path+fr'\02_动物数独_{hs}宫格_答案卡_图片',path+fr'\01_动物数独_{hs}宫格_任务卡_图片']
for t3 in range(len(tii)):
pdf_lst = [f for f in os.listdir(ti[t3]) if f.endswith('.pdf')]
pdf_path = os.path.join(ti[t3], pdf_lst[0])
print(pdf_path)
# 修改这里 - 使用empty_counts[kk]而不是w[kk]
new_file_name = f"{(t3+1):02}_动物数独_{hs}宫格_{title[t3]}_难度{kk+1:02d}_空{empty_counts[kk]:03d}格({db}乘{cb}等于{num}份{db*cb}张).pdf"
output_path = os.path.join(tii[t3], new_file_name)
print(output_path)
os.rename(pdf_path, output_path)
time.sleep(3)
shutil.rmtree(ti[t3])
time.sleep(3)
print('----------第4步:把都有16管PDF关卡变png------------')
from win32com.client import Dispatch
import os
import re
import fitz
wdFormatPDF = 17
zoom_x=2
zoom_y=2
rotation_angle=0
li=[path+fr'\02_动物数独_{hs}宫格_答案卡_图片',path+fr'\01_动物数独_{hs}宫格_任务卡_图片']
for l in li:
for root, dirs, files in os.walk(l):
for file in files:
if re.search('\.pdf$', file):
filename = os.path.abspath(root + "\\" + file)
print(filename)
pdf = fitz.open(filename)
for pg in range(0, pdf.pageCount):
page = pdf[pg]
trans = fitz.Matrix(zoom_x, zoom_y).preRotate(rotation_angle)
pm = page.getPixmap(matrix=trans, alpha=True)
pm.writePNG(filename.replace('.pdf', '') + str(pg+1) + ".png")
pdf.close()
for parent, dirnames, filenames in os.walk(l):
for fn in filenames:
if fn.lower().endswith('.pdf'):
os.remove(os.path.join(parent, fn))
print('-----第三板块、把动物任务卡和答案卡一套分别做成1页1份,1页2份,1页6份的pdf-------')
psize=[9.39,9.39,14.1,14.1,19.6,19.6]
pg=[6,6,2,2,1,1]
gzs=[2,2,2,2,1,1]
nh=[1,2,1,2,1,2]
for x in range(len(pg)):
imagePath11=path+fr'\04_动物数独_{hs}宫格_答案卡_pdf'
imagePath22=path+fr'\03_动物数独_{hs}宫格_任务卡_pdf'
os.makedirs(imagePath11,exist_ok=True)
os.makedirs(imagePath22,exist_ok=True)
tiii=[path+fr'\04_动物数独_{hs}宫格_答案卡_pdf',path+fr'\03_动物数独_{hs}宫格_任务卡_pdf',path+fr'\04_动物数独_{hs}宫格_答案卡_pdf',path+fr'\03_动物数独_{hs}宫格_任务卡_pdf',path+fr'\04_动物数独_{hs}宫格_答案卡_pdf',path+fr'\03_动物数独_{hs}宫格_任务卡_pdf']
tii=[path+fr'\02_动物数独_{hs}宫格_答案卡_图片',path+fr'\01_动物数独_{hs}宫格_任务卡_图片',path+fr'\02_动物数独_{hs}宫格_答案卡_图片',path+fr'\01_动物数独_{hs}宫格_任务卡_图片',path+fr'\02_动物数独_{hs}宫格_答案卡_图片',path+fr'\01_动物数独_{hs}宫格_任务卡_图片']
title=['答案卡','任务卡','答案卡','任务卡','答案卡','任务卡']
imagePath=path+r'\\零时Word'
os.makedirs(imagePath,exist_ok=True)
doc = Document(path +fr'\动物数独({pg[x]}图关卡).docx')
tables = doc.tables[0]
file_paths = [os.path.join(tii[x], file) for file in os.listdir(tii[x])]
pic_list_six = [file_paths[i:i+int(pg[x])] for i in range(0, len(file_paths), int(pg[x]))]
print(pic_list_six)
print(len(pic_list_six))
for group_index, group in enumerate(pic_list_six):
doc = Document(path + fr'\动物数独({pg[x]}图关卡).docx')
for cell_index, image_file in enumerate(group):
cc=float(psize[x])
table = doc.tables[0]
cell = table.cell(int(cell_index /gzs[x]), cell_index % gzs[x])
cell_paragraph = cell.paragraphs[0]
cell_paragraph.clear()
run = cell_paragraph.add_run()
run.add_picture(os.path.join(image_file), width=Cm(cc), height=Cm(cc))
cell_paragraph.alignment = 1
doc.save(imagePath + fr'\{group_index + 1:02d}页.docx')
inputFile = imagePath + fr'\{group_index + 1:02d}页.docx'
outputFile = imagePath + fr'\{group_index + 1:02d}页.pdf'
convert(inputFile, outputFile)
time.sleep(3)
pdf_lst = [f for f in os.listdir(imagePath) if f.endswith('.pdf')]
pdf_lst = [os.path.join(imagePath, filename) for filename in pdf_lst]
pdf_lst.sort()
file_merger = PdfMerger()
for pdf in pdf_lst:
print(pdf)
file_merger.append(pdf)
file_merger.write(tiii[x]+ fr"\{nh[x]:02} _动物数独_{hs}宫格_{title[x]}_1页{pg[x]}关(一关卡{psize[x]}CM).pdf")
time.sleep(1)
file_merger.close()
shutil.rmtree(imagePath)
# print('-----第四板块、交叉合并有答案6套,无答案6套(1-1-1、1-1,1-2-2,1-2,2-1-1,2-1……----')
newgz=path+fr'\(打印)动物数独{hs}宫格 共{len(empty_counts)}关'
os.makedirs(newgz,exist_ok=True)
# 在代码的最后部分,替换原有的删除文件夹操作为移动文件夹操作
# 定义要移动的文件夹列表
folders_to_move = [
path+fr'\04_动物数独_{hs}宫格_答案卡_pdf',
path+fr'\03_动物数独_{hs}宫格_任务卡_pdf',
path+fr'\02_动物数独_{hs}宫格_答案卡_图片',
path+fr'\01_动物数独_{hs}宫格_任务卡_图片',
path+fr'\05_动物数独_{hs}宫格_操作卡_pdf'
]
# 移动文件夹到newgz目录
for folder in folders_to_move:
if os.path.exists(folder):
dest_folder = os.path.join(newgz, os.path.basename(folder))
# 如果目标文件夹已存在,先删除
if os.path.exists(dest_folder):
shutil.rmtree(dest_folder)
shutil.move(folder, newgz)
print(f"已移动文件夹: {folder} -> {newgz}")
# imagePath11=path+r'\08答案卡pdf'
# imagePath22=path+r'\09任务卡pdf'
# imagePatha=path+r'\06答案卡'
# imagePathq=path+r'\07任务卡'
# imagePathpaste=path+r'\05操作卡pdf'
# shutil.rmtree(imagePath11)
# shutil.rmtree(imagePath22)
# shutil.rmtree(imagePatha)
# shutil.rmtree(imagePathq)
# shutil.rmtree(imagePathpaste)
# end_time = datetime.now()
# elapsed_time = end_time - start_time
# print(f"动物数独{hs}宫格程序开始时间:{start_time}")
# print(f"动物数独{hs}宫格程序结束时间:{end_time}")
# print("程序运行时间:", elapsed_time)
end_time = datetime.now()
elapsed_time = end_time - start_time
print(f"动物数独{hs}宫格程序开始时间:{start_time}")
print(f"动物数独{hs}宫格程序结束时间:{end_time}")
print("程序运行时间:", elapsed_time)
end_time = datetime.now()
elapsed_time = end_time - start_time
print(f"动物数独{hs}宫格程序开始时间:{start_time}")
print(f"动物数独{hs}宫格程序结束时间:{end_time}")
print("程序运行时间:", elapsed_time)

 ,
,


















 927
927

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











