






最近在看莫烦的torch入门讲解,记一下笔记,以后训练网络可以根据具体情况进行优化。
'''
调包
'''
import torch
import torch.utils.data as Data
import torch.nn.functional as F
import matplotlib.pyplot as plt
import numpy as np
'''
随机生成数据
'''
LR = 0.01
batch_size = 32
#因为生成的是数字数据,维度小,数量少,所以batch_size大些,如果真要用,尤其是训练图片,不要设这么大。但要是你电脑配置足够高,请随意...
Epoch = 12
x = torch.unsqueeze(torch.linspace(-1,1,1000),dim=1)
y = x.pow(2) + 0.1*torch.normal(torch.zeros(*x.size()))
#plt.scatter(x.numpy(), y.numpy())
#plt.show() #show不show的看你自己丫...
'''
begin...
'''
torch_dataset = Data.TensorDataset(x,y)
loader = Data.DataLoader(dataset=torch_dataset, batch_size=batch_size,
shuffle=True, num_workers=2)
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.hidden = torch.nn.Linear(1,20)
self.predict = torch.nn.Linear(20,1)
def forward(self,x):
x = F.relu(self.hidden(x))
x = self.predict(x)
return x
if __name__ == '__main__':
net_SGD = Net()
net_Momentum = Net()
net_RMSprop = Net()
net_Adam = Net()
nets = [net_SGD,net_Momentum,net_RMSprop,net_Adam]
opt_SGD = torch.optim.SGD(net_SGD.parameters(),lr=LR)
opt_Momentum = torch.optim.SGD(net_Momentum.parameters(), lr=LR,momentum=0.5)
opt_RMSprop = torch.optim.RMSprop(net_RMSprop.parameters(),lr=LR,alpha=0.9)
opt_Adam = torch.optim.Adam(net_Adam.parameters(),lr=LR,betas=(0.9,0.99))
optimizers = [opt_SGD,opt_Momentum,opt_RMSprop,opt_Adam]
loss_func = torch.nn.MSELoss()
losses_his = [[],[],[],[]]
for epoch in range(Epoch):
print('Epoch:', epoch)
for step,(b_x,b_y) in enumerate(loader):
for net,opt,l_his in zip(nets,optimizers,losses_his):
output = net(b_x)
loss = loss_func(output,b_y)
opt.zero_grad()
loss.backward()
opt.step()
l_his.append(loss.data.numpy())
labels = ['SGD','Momentum','RMSprop','Adam']
for i,l_his in enumerate(losses_his):
plt.plot(l_his, label=labels[i])
plt.legend(loc='best')
plt.xlabel('Steps')
plt.ylabel('Loss')
plt.ylim(0,0.2)
plt.show()看一下结果吧
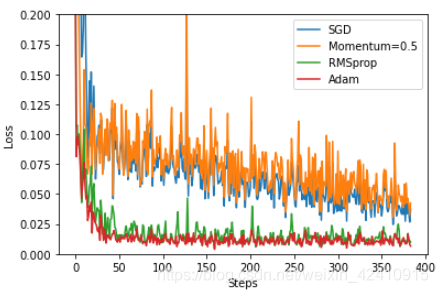
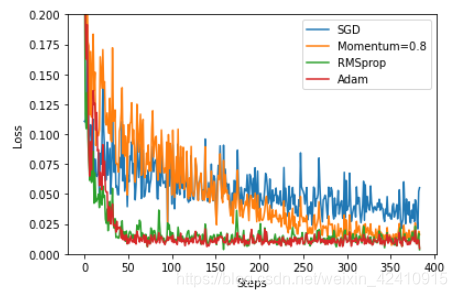
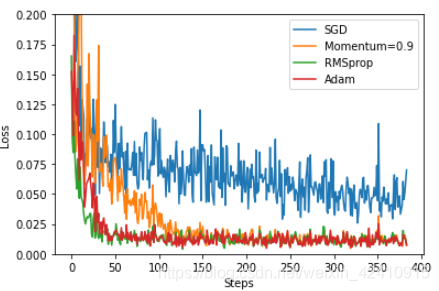
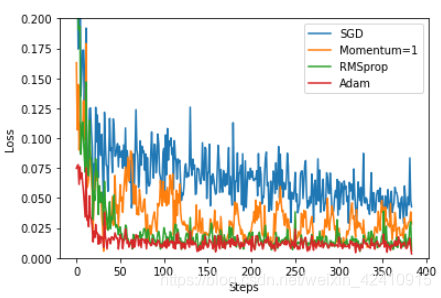
可以看出当Momentum越大时,收敛速度越快。但是当为1的时候上下波动情况太大。Momentum可以加快Stochastic Gradient Descent(随机梯度下降),而且可以抑制震荡。原因:使得梯度方向不变的维度上速度变快,梯度方向有所改变的维度上的更新速度变慢,这样就可以加快收敛并减小震荡。
RMSprop 是 Geoff Hinton 提出的一种自适应学习率方法。允许使用更大的学习率。
Adam计算每个参数的自适应学习率的方法。相当于 RMSprop + Momentum。
三.如何选择优化算法
如果数据是稀疏的,就用自适用方法,即 Adagrad, Adadelta, RMSprop, Adam。
RMSprop, Adadelta, Adam 在很多情况下的效果是相似的。
Adam 就是在 RMSprop 的基础上加了 bias-correction 和 momentum,
随着梯度变的稀疏,Adam 比 RMSprop 效果会好。
整体来讲,Adam 是最好的选择。
很多论文里都会用 SGD,没有 momentum 等。SGD 虽然能达到极小值,但是比其它算法用的时间长,而且可能会被困在鞍点。
如果需要更快的收敛,或者是训练更深更复杂的神经网络,需要用一种自适应的算法。


















 8193
8193

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









