







文章目录
han_attention(双向GRU+attention)
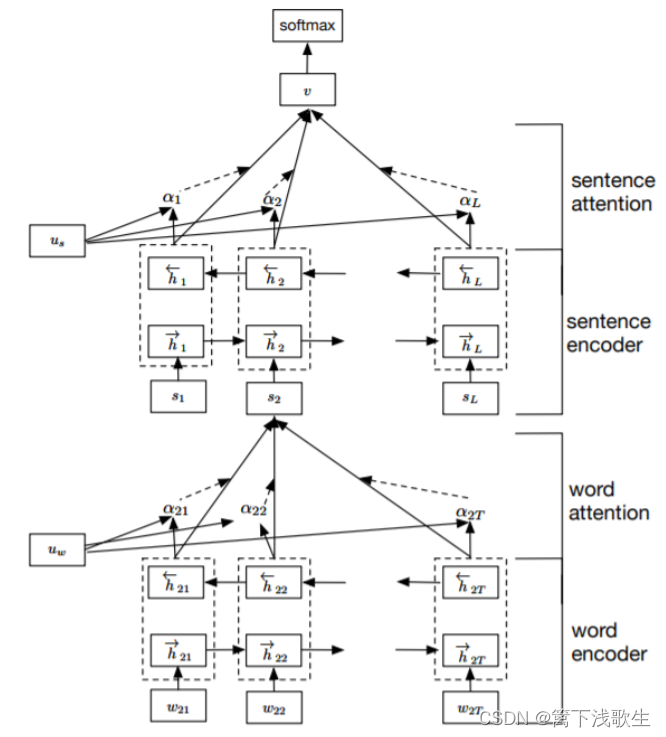
词编码:

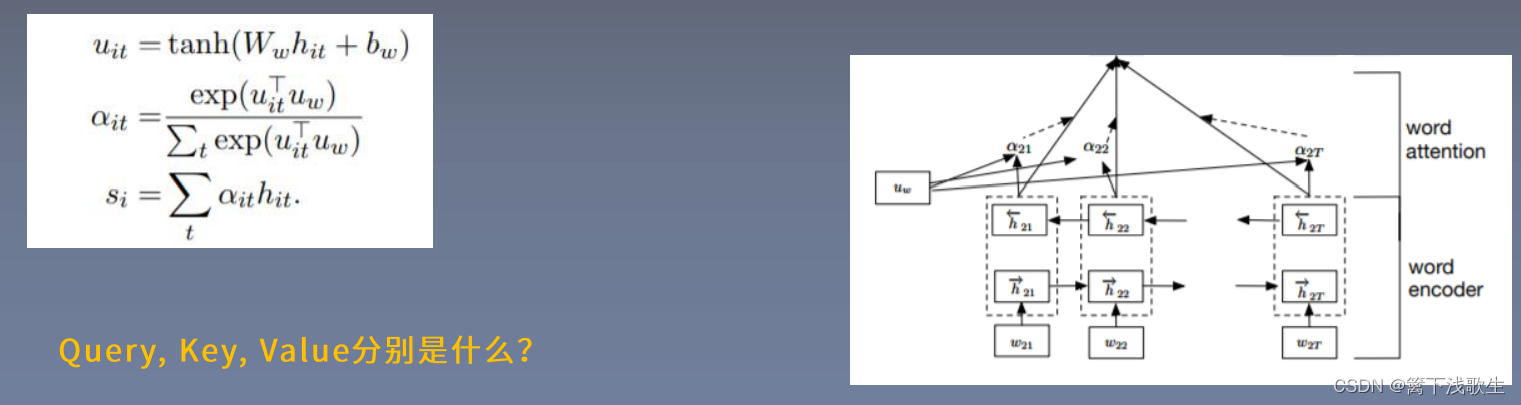
词级别的注意力机制:
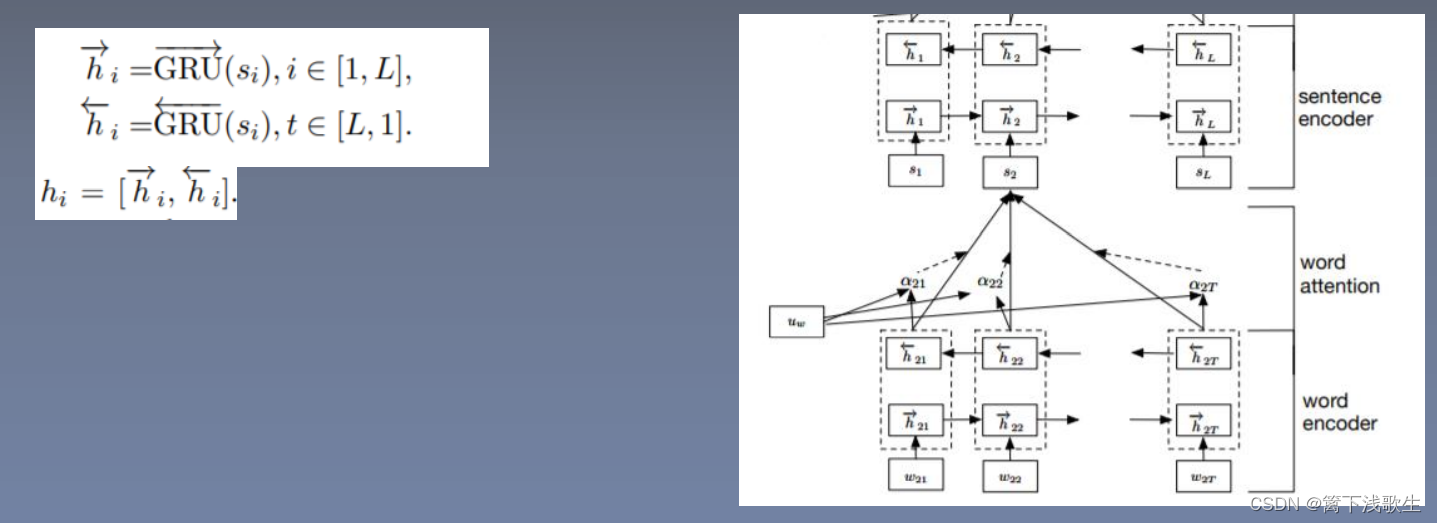
句子编码:
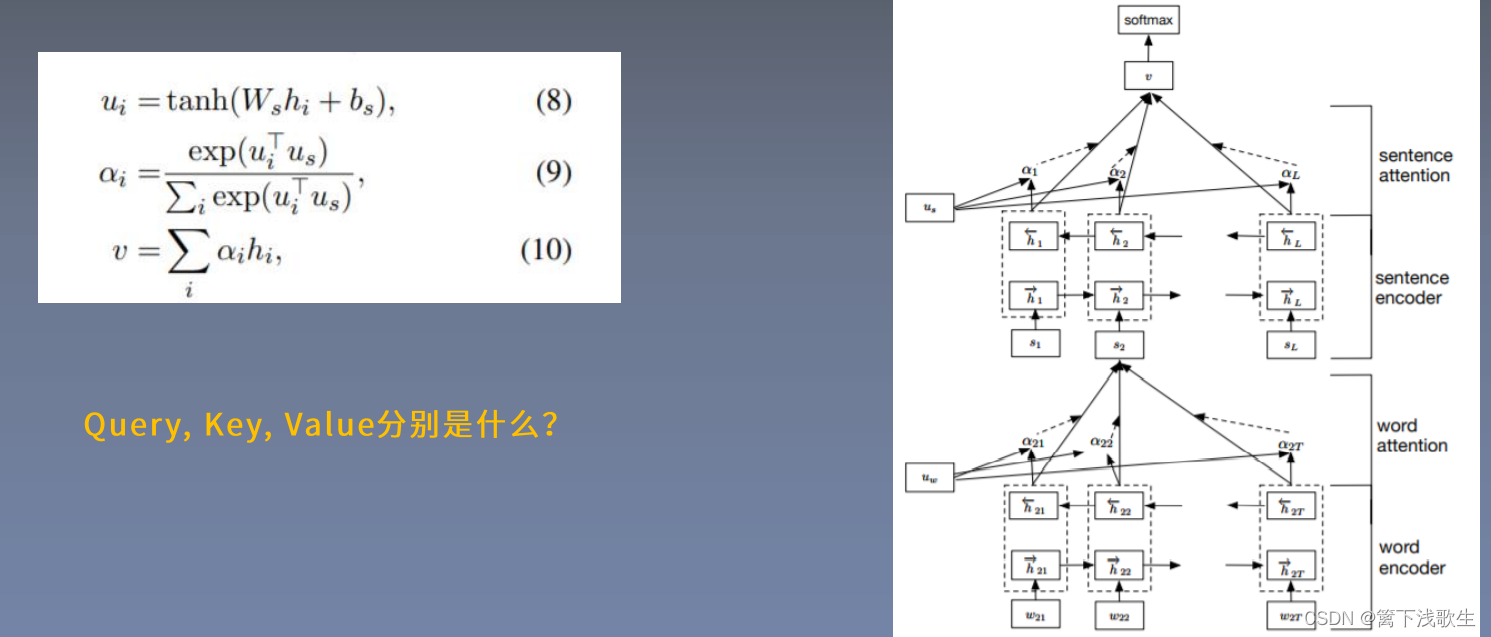
句子级别的注意力机制:
一、文件目录

二、语料集
数据集: http://ir.hit.edu.cn/~dytang/paper/emnlp2015/emnlp-2015-data.7z
三、数据处理(IMDB_Data_Loader.py)
1.数据集加载(排序,分句)
2.读取标签和数据
3.创建word2id(源语言和目标语言)
3.1统计词频
3.2加入 pad:0,unk:1创建word2id
4.将数据转化成id(源语言和目标语言)
5.添加目标数据的输入(target_data_input)
from gensim.models import KeyedVectors
from torch.utils import data
import os
import torch
import numpy as np
class IMDB_Data(data.DataLoader):
def __init__(self,data_name,min_count,word2id=None,max_sentence_length=100,batch_size=64,is_pretrain=True):
self.path = os.path.abspath(".")
if "data" not in self.path:
self.path += "/data"
self.data_name = "/imdb/"+data_name
self.min_count = min_count
self.word2id = word2id
self.max_sentence_length = max_sentence_length
self.batch_size =batch_size
self.datas,self.labels = self.load_data()
if is_pretrain:
self.get_word2vec()
else:
self.weight = None
for i in range(len(self.datas)):
self.datas[i] = np.array(self.datas[i])
# 数据集加载
def load_data(self):
datas = open(self.path+self.data_name,encoding="utf-8").read().splitlines()
datas = [data.split(" ")[-1].split() + [data.split(" ")[2]] for data in datas] # 取出数据并分词+标签
# 根据长度排序
datas = sorted(datas, key=lambda x: len(x), reverse=True)
labels = [int(data[-1]) - 1 for data in datas]
datas = [data[0:-1] for data in datas]
if self.word2id == None:
self.get_word2id(datas)
# 分句
for i, data in enumerate(datas):
datas[i] = " ".join(data).split("<sssss>")
for j, sentence in enumerate(datas[i]):
datas[i][j] = sentence.split()
datas = self.convert_data2id(datas)
return datas,labels
# word2id
def get_word2id(self, datas):
word_freq = {
}
for data in datas:
for word in data:
word_freq[word] = word_freq.get(word, 0) + 1
word2id = {
"<pad>": 0, "<unk>": 1}
for word in word_freq:
if word_freq[word] < self.min_count:
continue
else:
word2id[word] = 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 704
704

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









