







 该博客介绍了使用TextCNN进行情感分析的详细步骤,包括数据预处理、模型构建、防止过拟合的策略以及训练和测试过程。通过加载预训练的词向量,构建词2id映射,并对数据进行padding,实现模型训练。TextCNN模型结合了卷积神经网络和LSTM,用于处理文本数据。在验证集上应用早停策略以防止过拟合,最终在测试集上评估模型性能。
该博客介绍了使用TextCNN进行情感分析的详细步骤,包括数据预处理、模型构建、防止过拟合的策略以及训练和测试过程。通过加载预训练的词向量,构建词2id映射,并对数据进行padding,实现模型训练。TextCNN模型结合了卷积神经网络和LSTM,用于处理文本数据。在验证集上应用早停策略以防止过拟合,最终在测试集上评估模型性能。
文章目录
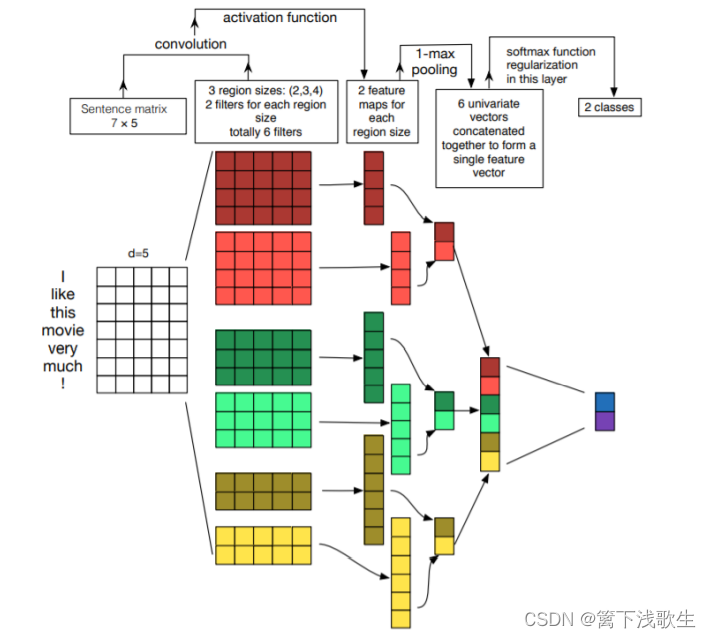
TextCNN
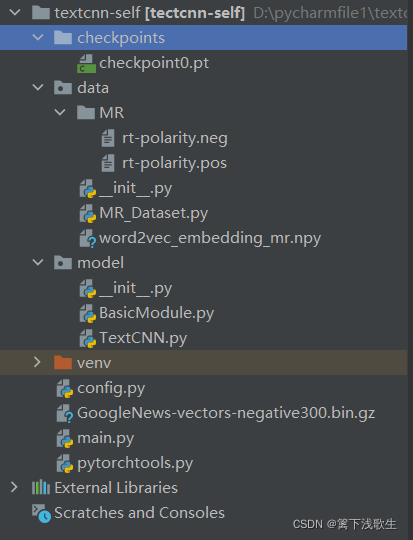
一、文件目录
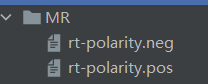
二、语料库(MR)
MR数据集(电影评论):
1.积极评论
2.消极评论
三、数据处理(MR_Dataset.py)
1.词向量导入
2.数据集加载
3.构建word2id并pad成相同的长度
4.求词向量均值和方差
5.生成词向量
6.生成训练集,验证集和测试集
from torch.utils import data
import os
import random
import numpy as np
from gensim.test.utils import datapath, get_tmpfile
from gensim.models import KeyedVectors
class MR_Dataset(data.Dataset):
def __init__(self, state="train",k=0,embedding_type="word2cec"):
self.path = os.path.abspath('.')
if "data" not in self.path:
self.path+="/data"
# 加载MR数据集
pos_samples = open(self.path+"/MR/rt-polarity.pos", errors="ignore").readlines()
neg_samples = open(self.path+"/MR/rt-polarity.neg", errors="ignore").readlines()
datas = pos_samples + neg_samples
datas = [data.split() for data in datas]
labels = [1] * len(pos_samples) + [0] * len(neg_samples) # 区分积极,消极的标签
# 构建word2id并pad成相同长度
max_sample_length = max([len(sample) for sample in datas])
word2id = {
"<pad>": 0}
for i, data in enumerate(datas):
for j, word in enumerate(data):
if word2id.get(word) == None:
word2id[word] = len(word2id)
datas[i][j] = word2id[word]
datas[i] = datas[i] + [0] * (max_sample_length - len(datas[i])) # 将所有句子pad成max_sample_length的长度 [10662,59]
self.n_vocab = len(word2id)
self.word2id = word2id
if embedding_type=="word2vec":
self.get_word2vec()
# 将数据和标签打包一起打乱
c = list(zip(datas, labels))
random.seed(1)
random.shuffle(c)
datas[:], labels[:] = zip(*c)
if state == "train":
# [0 : 9]->[1 : 9]
self.datas = datas[:int(k * len(datas) / 10)] + datas[int((k + 1) * len(datas) / 10):]
self.labels = labels[:int(k * len(datas) / 10)] + labels[int((k + 1) * len(labels) / 10):]
# [1 : 9]->[0 : 0.9*[1,9]]
self.datas = np.array(self.datas[0:int(0.9 * len(self.datas))])
self.labels = np.array(self.labels[0:int(0.9 * len(self.labels))])
elif state == "valid"</ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2499
2499

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









