




随着《Attention Is All You Need》这篇文章的发表,基于注意力机制的Transformer模型火遍了世界,开始Transformer主要应用在自然语言处理领域,慢慢的拓展到了计算机视觉领域,一直到现在的大模型ChatGPT等等,其实背后的底层技术都用到了Transformer。而把Transformer应用到计算机视觉领域的重要代表性模型就是ViT。
第一个具有重大影响力的使用纯Transformer结构进行图像分类的模型就是VIT。VIT全名VisionTransformer,是2020年Google团队提出的将Transformer应用在图像分类的模型,虽然不是第一篇将transformer应用在视觉任务的论文,但是因为其模型“简单”且效果好,可扩展性强(scalable,模型越大效果越好),成为了transformer在CV领域应用的里程碑著作,也引爆了后续相关研究。ViT原论文中最核心的结论是,当拥有足够多的数据进行预训练的时候,ViT的表现就会超过CNN,突破transformer缺少归纳偏置的限制,可以在下游任务中获得较好的迁移效果。
ViT将输入图片分为多个patch(16x16),再将每个patch投影为固定长度的向量送入Transformer,后续encoder的操作和原始Transformer中完全相同。但是因为对图片分类,因此在输入序列中加入一个特殊的token,该token对应的输出即为最后的类别预测结果。ViT网络结构如下所示:
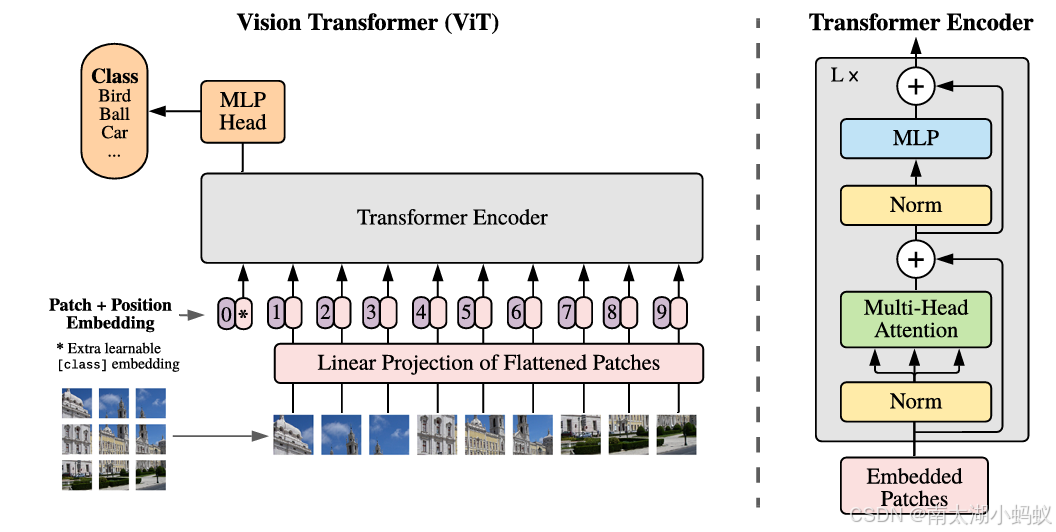
按照上面的流程图,ViT可以分为以下几个步骤:
(1) patch embedding:例如输入图片大小为224x224,将图片分为固定大小的patch,patch大小为16x16,则每张图像会生成224x224/16x16=196个patch,即输入序列长度为196,每个patch维度16x16x3=768,线性投射层的维度为768xN(N=768),因此输入通过线性投射层之后的维度依然为196x768,即一共有196个token,每个token的维度是768。这里还需要加上一个特殊字符cls,因此最终的维度是197x768。到目前为止,已经通过patchembedding将一个视觉问题转化为了一个seq2seq问题。
(2) positional encoding(standardlearnable 1D position embeddings):ViT同样需要加入位置编码,位置编码可以理解为一张表,表一共有N行,N的大小和输入序列长度相同,每一行代表一个向量,向量的维度和输入序列embedding的维度相同(768)。注意位置编码的操作是sum,而不是concat。加入位置编码信息之后,维度依然是197x768。
其中,前两个步骤是对输入数据的处理,后两个步骤是一个编码器Transformer Encoder。
(3) LN/multi-head attention/LN:LN(层归一化)输出维度依然是197x768。多头自注意力时,先将输入映射到q,k,v,如果只有一个头,qkv的维度都是197x768,如果有12个头(768/12=64),则qkv的维度是197x64,一共有12组qkv,最后再将12组qkv的输出拼接起来,输出维度是197x768,然后再经过
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1302
1302

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









