







 本文介绍了如何使用Python进行网络数据的爬取和解析,包括浏览器的使用、HTTP请求、HTML和JSON文件的处理。通过浏览器的网络模块、解析HTML的lxml和beautifulsoup4库、以及处理JSON数据的内置模块,实现数据的自动化获取和存储。同时,文章提及了反爬虫策略,强调在爬虫实践中需遵守法律和道德规范。
本文介绍了如何使用Python进行网络数据的爬取和解析,包括浏览器的使用、HTTP请求、HTML和JSON文件的处理。通过浏览器的网络模块、解析HTML的lxml和beautifulsoup4库、以及处理JSON数据的内置模块,实现数据的自动化获取和存储。同时,文章提及了反爬虫策略,强调在爬虫实践中需遵守法律和道德规范。
众里寻她千百度,蓦然回首,那人依旧对我不屑一顾。
我们每天都需要获取和过滤大量数据和信息。
比如一个产品运营人员,每天都需要了解:
- 互联网热点,从微博、微信、知乎、头条等平台了解当天的热点内容;
- App和小程序榜单,看看有哪些冒出来的热门应用;
- 从业内常关注的微信号中寻找选题素材,建立自己的素材库;
- 跟踪媒体数据,阅读率、打开率、转化率、分享裂变率等;
- 跟踪用户数据,用户新增、留存、活跃等;
- 拆解和复盘爆款案例,从中学习亮点……
获取和过滤数据的能力,决定了每个人的效率。
日常工作中,我们会用各类软件来处理数据。
其中使用频率最高、数量最多的,就是浏览器。
浏览器
历史上曾发生过3次浏览器大战:
- 90年代微软的IE用捆绑免费策略打败了网景付费的Netscape。
- 2004年网景核心团队成立Mozilla开源组织,推出Firefox打破微软IE垄断。
- 2008年Google以简洁、安全、免费的Chrome向IE发起挑战。
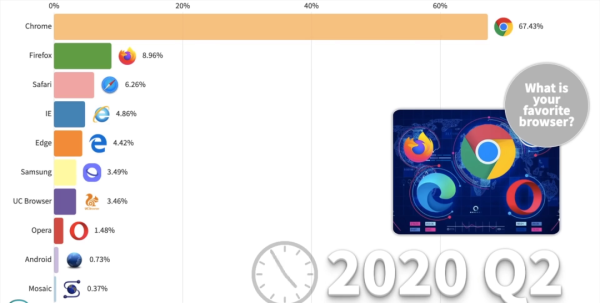
目前Chrome浏览器已占有7成PC端市场,1/3移动端市场,成为行业老大。
互联网诞生之初只能显示文本信息,应用非常有限。
随着技术标准化和商业化推进,浏览器慢慢把图片、音频、视频、动画等元素带入互联网,成了如今的模样。
浏览器,最基本的3大核心模块:
- 网络模块,处理网络连接和数据传送。
- 渲染模块,解析数据后展示成图像,即浏览器内核。
- JS模块,执行JavaScript程序。
当然,浏览器工作远不止这些,它还得管人机交互、多进程资源分配、数据存储以及插件扩展等等。
但只要具备3大核心模块的功能,我们就能处理互联网上的数据。
处理互联网数据
就像Word软件,可以把一个装着XML和图片等文件的“压缩包”,显示为一篇文档;
浏览器,则是把HTML、CSS、JS、JSON和图像等文件,显示为可浏览的页面。
简单看下浏览器的工作流程:
-
首先,浏览器根据我们给出的网址,发出网络请求,获取网址背后对应的资源文件。
-
其次,内核根据文件内容进行渲染,JS模块负责执行脚本,在屏幕上输出可视的页面。
-
最后,我们通过和页面上元素的交互,“通知”浏览器发出进一步的数据请求。
对于获取数据而言,我们不必太关心浏览器内核渲染页面的过程。
结构化的数据主要包含在HTML和JSON这两类文本文件中。
二进制文件,如图片、音视频等,其访问地址都会包含在以上两类文本文件中。
处理互联网数据的关键,是获取结构化文本,并从中提取所需内容。
-
通过访问地址从网络端获取HTML或JSON文件
-
从文件中解析出所需的文本内容,或其他文件访问地址
-
继续第1步操作。
这也就是“爬虫”的基本工作原理。
网络文件下载
和自动办公系列相比,处理文件多了一步,那就是得先从网上下载文件。
网络分很多层,互联网属于应用层,用HTTP协议规定了客户端和服务器间的通信格式。
浏览器就是一种客户端,服务器就是网页和文件存放的地方。
当我们输入某个网址按下回车:
- 首先,浏览器会通过网络模块帮我们找到那台服务器。
- 接着,它会向服务器发出HTTP格式请求,比如
GET /index.html。 - 然后,服务器会按约定的HTTP格式响应,返回数据。
- 最后,浏览器按内部流程开始渲染,等待我们下一个操作指令。
最常用HTTP请求动作就2个:
GET:用来下载数据,比如页面、各类文件等。POST:用来上传数据,比如表单、文件等。
Python用于处理HTTP协议的模块中,requests门槛最低,简单易用。
比如用它来获取头条的首页:
import requests
r = requests.get('https://www.toutiao.com/')
print(r.content)
只不过,打印出来的内容没有经过排版,看起来比较乱。
当然,我们也可以用它上传数据,比如上传图片:
import time
import pathlib
import requests
path = list(pathlib.Path.cwd().parents)[1].joinpath('data/dataproc/002dataget')
img_path = path.joinpath('tifa.jpg')
url = 'https://zh-cn.imgbb.com/json'
data = {
'type': 'file',
'action': 'upload',
'timestamp': int(time.time()*1000),
}
files = [('source', (img_path.stem, open(img_path, 'rb')))]
r = requests.post(url, data=data, files=files)
j = r.json()
url = j['image']['url']
print(url)
POST操作中需要指定提交的数据,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









