







知识给你力量,无知会给你更强大无畏,且无法预测的力量。
前两节内容已介绍如何清理数据,以及常用的分析模型。
本文会重点介绍pandas分析功能应用,包括:
多层索引、结构重塑、合并关联、交叉透视、分组聚合、时间序列。
然后以一个完整门店型业务项目,演示如何应用功能完成数据分析任务。
行和列的多层索引
在介绍功能前,先通过案例快速理解一个关键概念:多层索引。
在新媒体运营工作中,我们需要记录每篇文章的阅读量,而阅读量主要由标题和发送渠道有关。
我们可以用两种形式来记录数据:
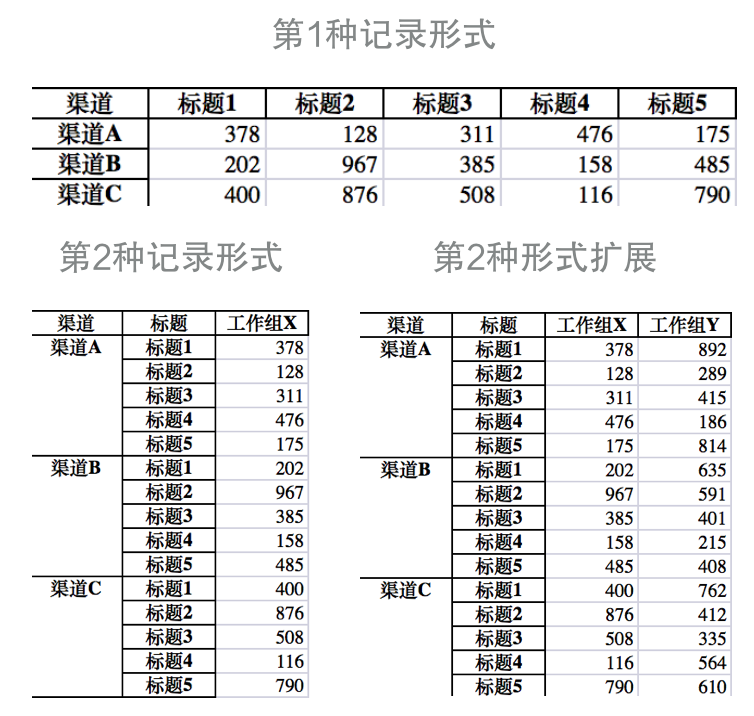
其中第1种更简洁,也经常是首先;第二种比较臃肿,标题名被重复记录。
但如果在此基础上,增加工作组维度,即X、Y、Z三个组分别做同样的事,该如何记录?
第1种形式中已经无法用单个表格表示,只能增加第2、第3张表来表示不同工作组;
但第2种形式可以完美解决,只需要增加一列“工作组”即可,如上图右下所示。
如果再想增加更多维度,比如增加多个自媒体账号;或者想再增加更多数据,比如点赞和转发等,该如何记录呢?
可以参考第2种形式,把工作组和账号从列改成行,用3列记录阅读、点赞、转发数据;
也可以把现有列扩充成2个维度:工作组和账号,一个工作组下分为多个账号,然后在各个账号下增加阅读、点赞、转发的数据。
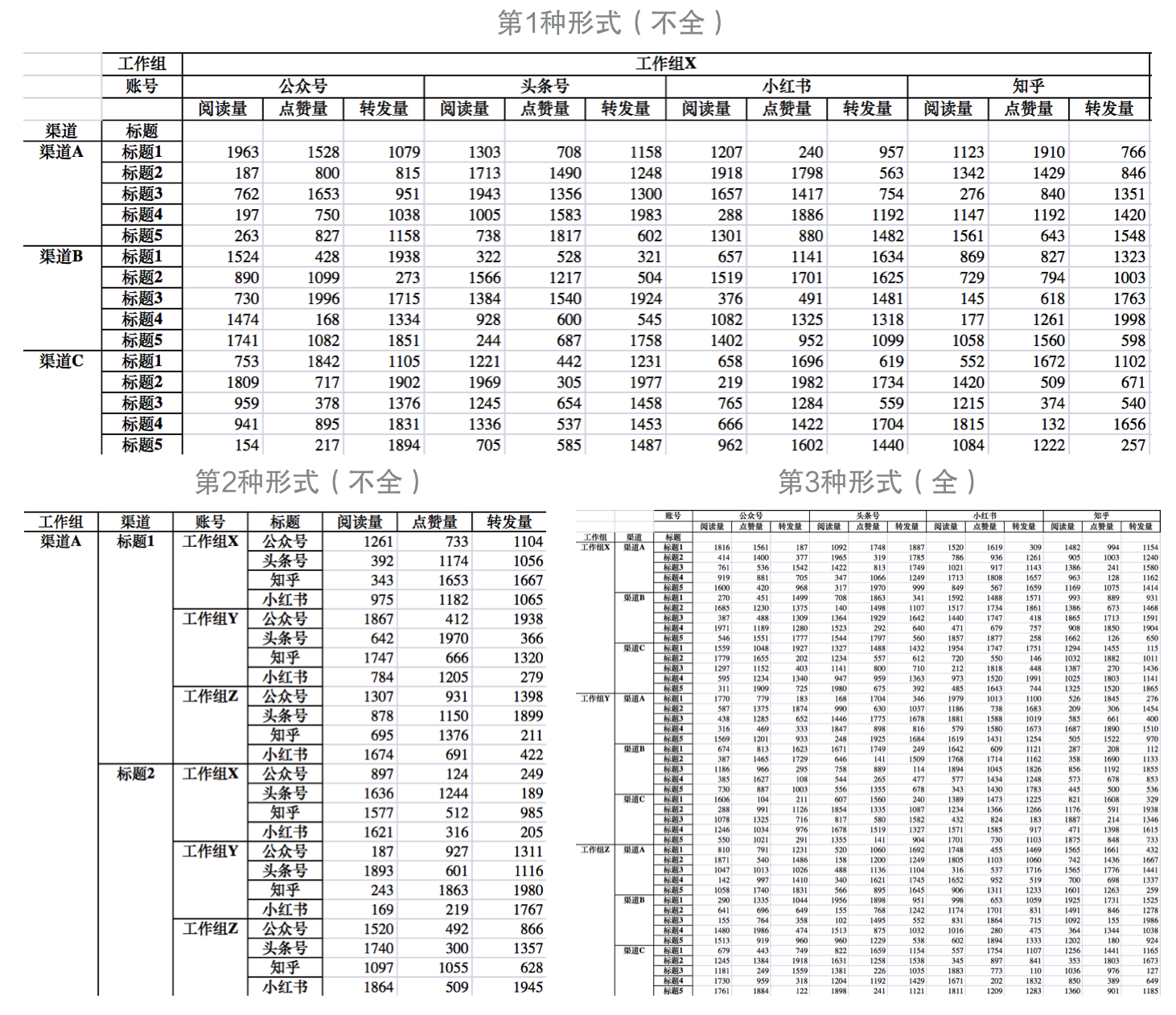
可以看到,同样的数据,可以通过行和列之间转换,呈现出不同的形态。
在数据分析过程中,常需汇总不同维度的数据,或关联对比多维度数据间的关系。
Pandas分析核心功能
pandas提供了多层次索引结构,处理多维度数据非常方便。
上面演示的多维度表格数据,就是用pandas随机生成和处理。
import pathlib
import numpy as np
import pandas as pd
from pandas import MultiIndex as MI
path = list(pathlib.Path.cwd().parents)[1].joinpath('data/dataproc/006analysis')
excel_A_path = path.joinpath('testA.xlsx')
excel_B_path = path.joinpath('testB.xlsx')
excel_C_path = path.joinpath('testC.xlsx')
excel_D_path = path.joinpath('testD.xlsx')
excel_E_path = path.joinpath('testE.xlsx')
excel_F_path = path.joinpath('testF.xlsx')
excel_G_path = path.joinpath('testG.xlsx')
# 定义维度列表
channel_list = ['渠道A','渠道B','渠道C']
title_list = ['标题1','标题2','标题3','标题4','标题5']
group_list = ['工作组X','工作组Y','工作组Z']
account_list = ['公众号','头条号','知乎','小红书']
# 定义某个新媒体工作组在多个渠道下多篇文章标题测试数据
team1 = pd.Series(np.random.randint(100,1000,15),
index=MI.from_product([channel_list,title_list],
names=['渠道','标题']),
name='工作组X')
# 导出Excel表
team1.unstack().to_excel(excel_A_path)
team1.to_excel(excel_B_path)
# 定义更多工作组
team2 = pd.Series(np.random.randint(100,1000,15),
index=MI.from_product([channel_list,title_list],
names=['渠道','标题']),
name='工作组Y')
# 合并两个Series到DataFrame
df = pd.concat([team1, team2], axis=1)
df.to_excel(excel_C_path)
# 增加账号维度,和工作组一起并入行内
df = pd.DataFrame(np.random.randint(100,2000,(180,3)),
index=MI.from_product([channel_list, title_list, group_list,account_list],
names=['渠道','标题','工作组','账号']),
columns=['阅读量','点赞量','转发量'])
df.to_excel(excel_D_path)
# 把工作组和账号放到列
df.stack().unstack('工作组').unstack('账号').unstack().to_excel(excel_E_path)
# 只把账号维度放到列
df_result = df.stack().unstack('账号').unstack()
df_result.to_excel(excel_F_path)
# 调整下行内各维度顺序
df_result.index=MI.from_product([group_list,channel_list,title_list],
names=['工作组','渠道','标题'])
df_result.to_excel(excel_G_path)
其中,用到了2个核心功能:结构重塑、合并关联,此外通过to_excel导出xlsx文件方便截图。
结构重塑
pandas中,Series是1维结构,包含1维的索引;DataFrame是2维结构,包含行和列两个维度索引。DataFrame可以看成是由多个Series共享行索引后的组合体,如上述案例中用concat方法把两个Series合并成1个DataFrame。
DataFrame在行和列维度,都可以有多层索引,并且可以用stack和unstack方法转换行列维度。
还有4个常用方法用于设置行列索引:reset_index、set_index、T、melt。
# 把所有行索引转为列索引
df = df_result.reset_index()
# 设置行索引
df.set_index(['工作组','渠道','标题'])
# melt选择部分id列,其他列转为行数据放在id列后
df.melt(id_vars=['工作组','渠道','标题'])
# 行和列转换
df.T
固定数据结构后,就可以用索引、筛选、切片等方式访问数据了。
# 获取行索引
df.index
# 获取列索引
df.columns
# 按列索引
print(df[('头条号','阅读量')])
# 按列的某个level索引
print(df['头条号'])
# 按列索引,效果相同
print(df['头条号']['阅读量'])
# 按行level索引
df.loc['工作组X']
# 按行多层索引
df.loc[('工作组X','渠道A')]
df.loc[('工作组X','渠道A','标题1')]
# 按行列索引
df.loc[('工作组X','渠道A','标题1')][('头条号')]
df.loc[('工作组X','渠道A','标题1')][('头条号','阅读量')]
# 指明某个维度索引
# 按行索引
df.loc(axis=0)['工作组X',:,['标题1','标题3']]
# 按列索引
df.loc(axis=1)[['公众号','头条号'],['阅读量','转发量']]
# 借助切片器索引
idx = pd.IndexSlice
df.loc[idx['工作组X', :, ['标题1', '标题3']], idx['公众号':,'阅读量']]
# 借助xs交叉选取,任意选取某个层级索引
# 按行
df.xs('标题1',level='标题')
# 按列
df.xs('阅读量',level=1,axis=1)
# 行列交叉
df.xs('渠道A',level='渠道').xs('阅读量',level=1,axis=1)
合并关联
pandas用于合并关联数据的操作主要有4种:
concat,可以在行和列上拼接数据,支持inner和outer两种连接模式,支持不同维度数据连接;append,concat的简化版,方便向列和行尾部追加数据;merge,在列维度按某个key合并数据,和SQL数据库的JOIN操作相似,支持inner、outer、right和left4种连接模式;join,当key正好是索引时merge方法的特例,其内部用merge实现。
import numpy as np
import pandas as pd
df1 = pd.DataFrame({
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']},
index=range(4))
df2 = pd.DataFrame({
'A': ['A4', 'A5', 'A6', 'A7'],
'B': ['B4', 'B5', 'B6', 'B7'],
'C': ['C4', 'C5', 'C6',  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









