







 本文介绍了使用Python操作数据库,从Sqlite3的基本使用,到Django ORM的快速体验,以及如何创建Django项目和命令行工具。通过Django的ORM,可以简化SQL操作,提升开发效率。同时,推荐了TablePlus作为数据库管理工具,为个人或小团队的数据存储和管理提供方便。
本文介绍了使用Python操作数据库,从Sqlite3的基本使用,到Django ORM的快速体验,以及如何创建Django项目和命令行工具。通过Django的ORM,可以简化SQL操作,提升开发效率。同时,推荐了TablePlus作为数据库管理工具,为个人或小团队的数据存储和管理提供方便。
你以为男朋友是取款机,结果是十台机器,有九台半是存款机。
如果仅仅是临时获取一些数据,保存到本地csv文件后,用Excel等软件处理即可。
但长期积累数据后,会发现文件多到难以管理,数据库就是为此而生。
不少人听到数据库就怕,主要有3个原因;
- 不少教程一上来就介绍原理,各种概念、模式、范式;
- 入门难,常被推荐MySQL,从下载安装,到建库写数据,还得装管理工具;
- 操作门槛高,得掌握SQL语言才能操作数据。
如何能把数据库的使用门槛再降低些?
- 首先,分析工作主要在Python,而非数据库本身,数据库承担存储作用;
- 其次,数据库的读写场景分离,分析时读数据,获取数据时写数据,互不影响;
- 最后,只考虑个人或小团队快速作战,不考虑大规模共享数据平台搭建。
这么一来,我们就可以选择一套适合快速作战的技术组合了。
sqlite3:一种小型嵌入式数据库,整个数据库就一个文件,包含在Python标准模块中。django:著名Python一站式Web框架,包含MVC和ORM等设计模式实现,利用ORM模块可用Python对象操作数据库,减少SQL使用。TablePlus:一个功能和性能都强大的数据库管理工具,支持大部分关系和非关系型主流数据库。
用Sqlite3操作数据库
使用程序操作数据库的基本流程包括4步:
- 创建数据库链接,比如网络或本地文件;
- 获取
Cursor对象,用于执行SQL和获取数据; - 提交数据修改到数据库,完成事务;
- 关闭链接。
sqlite3数据库不需要安装即可以使用,基本使用如下:
import pathlib
import sqlite3
SQL_CREATE_TABLE = 'create table article \
(id varchar(32) primary key, title varchar(64), url varchar(256))'
SQL_INSERT_DATA = 'insert into article (id, title, url) values \
("1", "办公自动化系列", "https://mp.weixin.qq.com/s/JFEASRL17bnr6fRJfezixA")'
path = list(pathlib.Path.cwd().parents)[1].joinpath('data/dataproc/003storage')
db_path = path.joinpath('test.sqlite3')
# 打开数据库,并获取一个
conn = sqlite3.connect(db_path)
cursor = conn.cursor()
# 查看当前数据库有哪些表
cursor.execute('select name from sqlite_master where type="table" order by name')
tables = cursor.fetchall()
table_names = [t[0] for t in tables]
if 'article' not in table_names:
# 创建数据库,插入一条数据
cursor.execute(SQL_CREATE_TABLE)
cursor.execute(SQL_INSERT_DATA)
cursor.close()
conn.commit() # 提交数据修改
# 查询数据
cursor = conn.cursor()
cursor.execute('select * from article where id=?', ('1',))
values = cursor.fetchall()
print(values)
cursor.close()
conn.close()
上面的案例中:
- 首先定义了数据库位置和名称,其实就是一个文件,可以用任何名字和扩展名。
- 其次获取一个数据库链接
Connection,负责和数据库通信,如提交数据修改,用完需要关闭。 - 然后从链接中获取
Cursor对象,用execute等方法执行SQL语句。 - 最后,通过
Cursor的fetchall等方法获取SQL执行结果数据。
其中,最关键两个对象是Connection和Cursor,操作数据靠SQL语句。
常用的SQL语句主要有2类:
- 结构类对象操作:如数据库、表、索引,用
CREATE创建、用ALTER修改、用DROP删除; - 表数据相关操作:用
INSERT插入、用UPDATE修改、用DELETE删除、用SELECT查询。
其中,SELECT使用频率最高,也是功能最丰富、结构最复杂的主要语句。
如果擅长SQL语法,直接用上面案例结构,就能完成大部分数据库操作。
但如果完全不了解SQL语法,则会有一定学习门槛。
好在,ORM设计模式,可以帮助我们减少SQL的直接使用。
Django的ORM
ORM,Object Relational Mapping(对象关系映射),是软件工程中的一种设计模式,建立了关系数据库与面向对象间的映射。
于是,我们可以通过程序对象管理数据库的数据。
Python生态中主要有3个ORM模块:
django,一站式框架,除了ORM还提供MVC(Model–View–Controller)设计模式实现,被广泛应用于Web开发项目,降低组件间耦合度,提高项目可控性。sqlalchemy,独立ORM模块,适合与其他模块一起组成Web项目完整开发框架,比如由flask模块提供MVC模式的实现。peewee,独立ORM模块,代码精巧简洁,接口类似django的ORM模块,支持3种数据库:postgresql、mysql、sqlite。
这里选择djangoORM模块的原因有3个:
django的ORM模块封装度更高,即可以更少关注数据库操作层面的细节。这对于新手而言更有益处,当然在极度复杂项目中也可能会成为劣势,但大部分情况下够用,而且简单易用。django是一站式的Web开发框架,它自带admin管理模块,以及命令行框架,更容易扩展功能。- 大量项目实践让
django的技术栈选型更可靠,文档也更丰富,入门门槛更低,非常适合常规项目。
django模块安装:pip install django
快速体验Django的ORM模块
我们以之前创建的数据库test.sqlite3为基础,在Notebook中快速体验django的ORM模块。
import os
import pathlib
import django
from django.conf import settings
from django.db import models
path = list(pathlib.Path.cwd().parents)[1].joinpath('data/dataproc/003storage')
db_path = path.joinpath('test.sqlite3')
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.sqlite3',
'NAME': str(db_path),
}
}
if not settings.configured:
# 采用手动配置过程
settings.configure(DATABASES=DATABASES, DEBUG=True)
# Django3中,ORM操作被标记为异步不安全,会被阻止
os.environ['DJANGO_ALLOW_ASYNC_UNSAFE'] = 'true'
django.setup()
# 建立数据表映射类
class Article(models.Model):
title = models.CharField(max_length=64)
url = models.CharField(max_length=256)
class Meta:
# 指明在INSTALLED_APPS之外的App名
app_label = 'python1024'
# 指明对应表名,默认为App.Model
db_table = 'article'
# 获取Article(对应article表)的所有数据
articles = Article.objects.all()
for article in articles:
print(article.id, article.title, article.url)
# 添加数据
article = Article(id=2, title='文件处理的本质', url='https://mp.weixin.qq.com/s/HYfXLmLAJcikRMFWcDbebA')
article.save()
print(f'插入一篇文章: {article.title}')
# 获取当前一共有多少篇文章
cnt_articles = Article.objects.count()
print(f'当前一共有 {cnt_articles} 篇文章')
# 更新最新一篇文章的标题
article = Article.objects.last()
article.title += '-已更新'
article.save()
# 删除最新一篇文章
article = Article.objects.last()
print(f'删除最新一篇文章: {article.title}')
article.delete()
print(f'当前一共有 {Article.objects.count()} 篇文章')
一些简单说明:
- 独立运行
django需要手动配置参数,可在环境变量中指定DJANGO_SETTINGS_MODULE或调用settings.configure方法,然后调用django.setup方法完成配置。 - 所有用于映射数据库的类,都继承自
django.db.models,并定义好字段(对应数据库中的列)。 - 创建的映射类,会自带
objects这个Manager类对象,通过调用它的方法能完成数据“增删查改”等操作,其中查询操作通过QuerySet接口执行。
上述代码可以在Notebook中正常执行,方便快速体验。
实战中,更建议按官方手册创建完整django项目,这样就能充分利用到其ORM模块提供的特性,如根据Model类更新数据库表结构。
创建Django项目
在安装完django后,就可以通过命令行创建项目了。
比如我们创建一个python1024项目,只需2步:
-
在命令行中,进入某个目录
-
运行:
django-admin startproject python1024
# yichu @ ichengplus in ~/dev/python/python1024/code/django on git:master o [10:51:44]
$ django-admin startproject python1024
# yichu @ ichengplus in ~/dev/python/python1024/code/django on git:master x [10:51:56]
$ cd python1024
# yichu @ ichengplus in ~/dev/python/python1024/code/django/python1024 on git:master x [10:52:02]
$ ls
manage.py python1024
# yichu @ ichengplus in ~/dev/python/python1024/code/django/python1024 on git:master x [10:52:03]
$ ls python1024
wsgi.py urls.py settings.py asgi.py __init__.py
这样我们就创建了一个名为python1024的django项目。
我们可以用VSCode打开python1024文件夹。
django命令会自动帮我们创建一些文件:
manage.py,提供了用于管理django项目命令行工具。python1024/__init__.py,Python包必需文件。python1024/wsgi.py,用于配置WSGI规范的Web应用。python1024/asgi.py,用于配置ASGI规范的Web应用。python1024/urls.py,用于配置Web应用的路径分发。python1024/settings.py,包含整个项目的配置信息。
其中,我们会用到manage.py和python1024/settings.py这两个文件。
因为django是一站式Web开发框架,可以用一行命令来开启开发服务器:
python manage.py runserver
接着用浏览器访问:“http://127.0.0.1:8000/”,就能看到欢迎界面。
顺着官方提示就可以开始学习如何开发Web应用。
当然,我们的重点并不是开发Web应用,而是利用django来方便地操作数据库。
比如,我们来创建一个收集文章的应用。
Django存储应用案例
在manage.py所在的目录中,我们先用一行命令创建一个应用datapool:
python manage.py startapp datapool
# yichu @ ichengplus in ~/dev/python/python1024/code/django/python1024 on git:master x [11:12:17]
$ python manage.py startapp datapool
# yichu @ ichengplus in ~/dev/python/python1024/code/django/python1024 on git:master x [11:12:23]
$ ls datapool
__init__.py admin.py apps.py migrations models.py tests.py views.py
django会自动帮我们创建datapool文件夹,其中包含几个文件:
admin.py,用于配置应用在django自带admin管理后台的参数。apps.py,用于配置应用模块信息。migrations,里面包含着多版本的数据表结构变更,可由django命令生成。models.py,用于映射数据库表的Python模型类。tests.py,用于应用代码的单元测试。views.py,用于存放Web应用的控制器代码。
其中,我们最关心的就是modes.py文件。
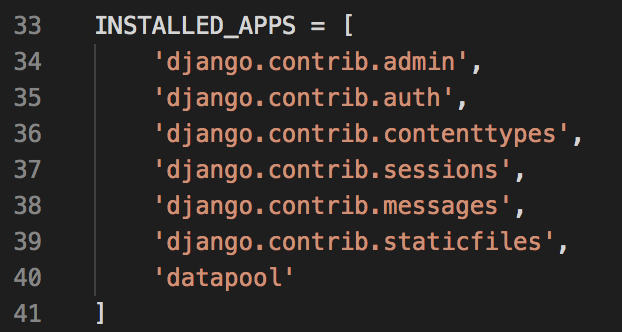
我们先把这个应用“注册”到项目中,打开python1024/settings.py,在第39行代码下增加一行’datapool’,就像这样:
接着定义一个文章类Article,打开datapool/models.py,修改代码:
from django.db import models
class Article(models.Model):
"""
文章模型类
"""
title = models.CharField(max_length=64)
url = models.CharField(max_length=256)
接着,利用manage.py,2行命令就能生成模型对应的数据库表:
python manage.py makemigrationspython manage.py migrate
# yichu @ ichengplus in ~/dev/python/python1024/code/django/python1024 on git:master x [11:23:00]
$ python manage.py makemigrations
Migrations for 'datapool':
datapool/migrations/0001_initial.py
- Create model Article
# yichu @ ichengplus in ~/dev/python/python1024/code/django/python1024 on git:master x [11:34:08]
$ python manage.py migrate
Operations to perform:
Apply all migrations: admin, auth, contenttypes, datapool, sessions
Running migrations:
Applying contenttypes.0001_initial... OK
……
一些简单说明:
- 第一行命令在
migrations文件夹下生成了0001_initial.py文件,它用于更新数据表结构,打开文件可以注意到django为我们自动添加了id列(对应数据库中的主键)。 - 第二行命令执行数据表更新,如果是第一次执行,会发现除了
datapool应用,还有一些其他应用数据表创建,那些都是django自带应用,如admin管理后台、基本用户权限和认证等。 django默认的数据库是Sqlite3,在根目录的db.sqlite3文件。
至此,我们已准备好数据库、表结构及其对应的Python模型类。
接下来,就可以和上面一样,开始用Python模型类来操作数据:
# 在notebook中运行已定义的django项目
import os, sys
import pathlib
import django
path = list(pathlib.Path.cwd().parents)[1].joinpath('code/django')
django_path = path.joinpath('python1024')
# 把项目加入到Python模块路径中
sys.path.insert(0, str(django_path))
# 设置系统环境变量
os.environ['DJANGO_SETTINGS_MODULE'] = 'python1024.settings'
os.environ['DJANGO_ALLOW_ASYNC_UNSAFE'] = 'true'
# 完成django配置
django.setup()
# 当项目在Python模块路径可找到时,才能引入项目内模块
from datapool.models import Article
# 添加2篇文章
article1 = Article(title='自动办公系列', url='https://mp.weixin.qq.com/s/JFEASRL17bnr6fRJfezixA')
article2 = Article(title='文件处理的本质', url='https://mp.weixin.qq.com/s/HYfXLmLAJcikRMFWcDbebA')
article1.save()
article2.save()
# 查找所有文章
articles = Article.objects.all()
for article in articles:
print(article.id, article.title, article.url)
# 更新最新文章
article = Article.objects.last()
article.title += '-已更新'
article.save()
print(f'一共有 {Article.objects.count()} 篇文章')
# 删除第一篇文章
article = Article.objects.first()
print(f'删除文章:{article.id, article.title}')
article.delete()
print(f'一共有 {Article.objects.count()} 篇文章')
简单说明和之前独立运行djangoORM模块的2点主要区别:
- 这次通过创建完整的
django项目,并把项目加入到Python模块查找路径中,通过外部的settings.py文件来配置django项目参数。 - 通过
manage.py工具生成数据库表,会默认帮我们增加一个自增的id字段(对应数据库表里的id列),当我们添加数据时,django会自动帮我们添加id值。
到这里,我们已经能结合上一章的内容,把文章信息从网络上抓取回来,再保存到数据库。
创建Django的命令行工具
最后,介绍下如何利用django编写类似manage.py的命令行工具,方便我们直接用命令抓取文章,而不用每次都打开代码编辑。
在datapool应用目录下,创建management文件夹,再在里面创建commands文件夹,再创建一个Python代码文件,文件名即后续调用的命令名。
比如我们创建一个提取所有文章链接的命令行工具article.py,整个项目结构如下:
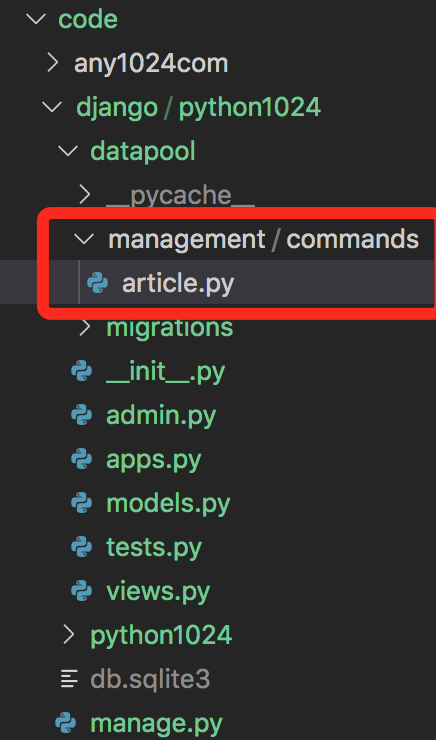
根据django命令行框架编写代码,参考如下:
from django.core.management.base import BaseCommand
import requests
from lxml import etree
from datapool.models import Article
def extract_articles(url):
"""
从链接中抽取文章,保存到数据库
"""
r = requests.get(url)
root = etree.HTML(r.content)
link_list = root.xpath('//*[@id="js_content"]//a')
articles = [Article(title=link.xpath('.//text()')[0],
url=link.get('href')) for link in link_list]
for article in articles:
article.save()
print(f'一共发现 {len(articles)} 篇文章,数据库共 {Article.objects.count()} 篇文章。')
class Command(BaseCommand):
"""
继承Django提供的命令行基本类
https://mp.weixin.qq.com/s/JFEASRL17bnr6fRJfezixA
"""
help = '文章抓取'
def add_arguments(self, parser):
"""接收命令行参数"""
parser.add_argument(
'-u', '--url', type=str, help='汇总类文章链接')
def handle(self, *args, **kwargs):
"""命令行处理入口"""
# 获取参数
url = kwargs['url']
if url:
extract_articles(url)
else:
print('请输入包含文章链接的访问地址')
一些简单说明:
Command作为入口,继承django的BaseCommand命令行基本类。add_arguments方法用于添加命令行工具的参数,比如-u是缩写,--url是全写。handle方法是命令行的执行主体,一般会把功能实现放在外部独立函数。
然后在manage.py所在项目根目录下,运行命令:
python manage.py article -u https://mp.weixin.qq.com/s/JFEASRL17bnr6fRJfezixA
这样每次运行命令,就可以开始抓取文章和链接了。
这里只根据微信公众号文章结构抽取文章链接,可以根据所需内容结构修改代码。
掌握了django命令行写法,就可以创建自己的命令行工具集了。
用TablePlus查看数据
最后,介绍一个功能和性能都很强大,同时使用便捷的本地客户端:TablePlus。
它支持MacOS和Windows两个操作系统,支持十几种主流的数据库,包括关系和非关系型。
下载打开后,我们只需要链接到对应数据库,即可开始用图形化界面管理数据库。
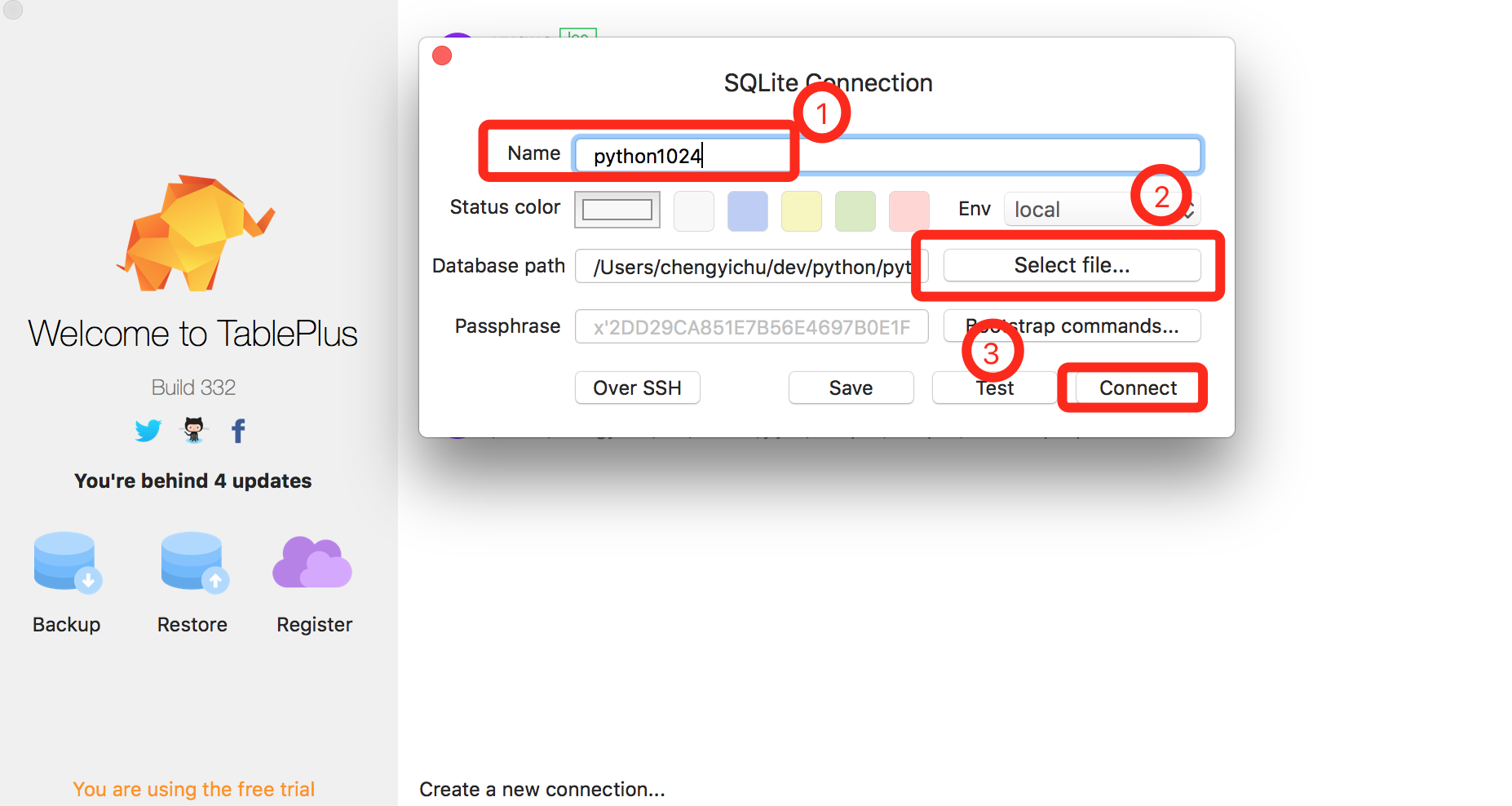
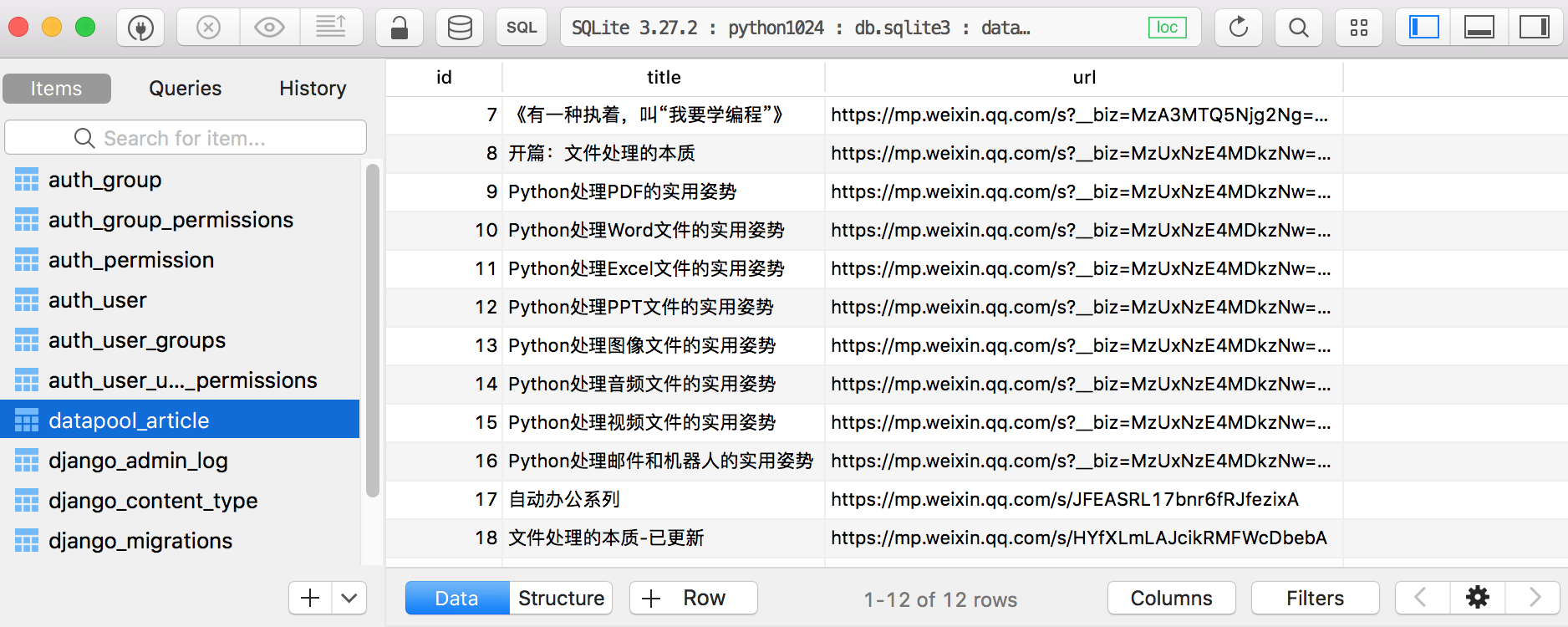
打开后,我们可以点击左边选择数据库表,在右边浏览数据。
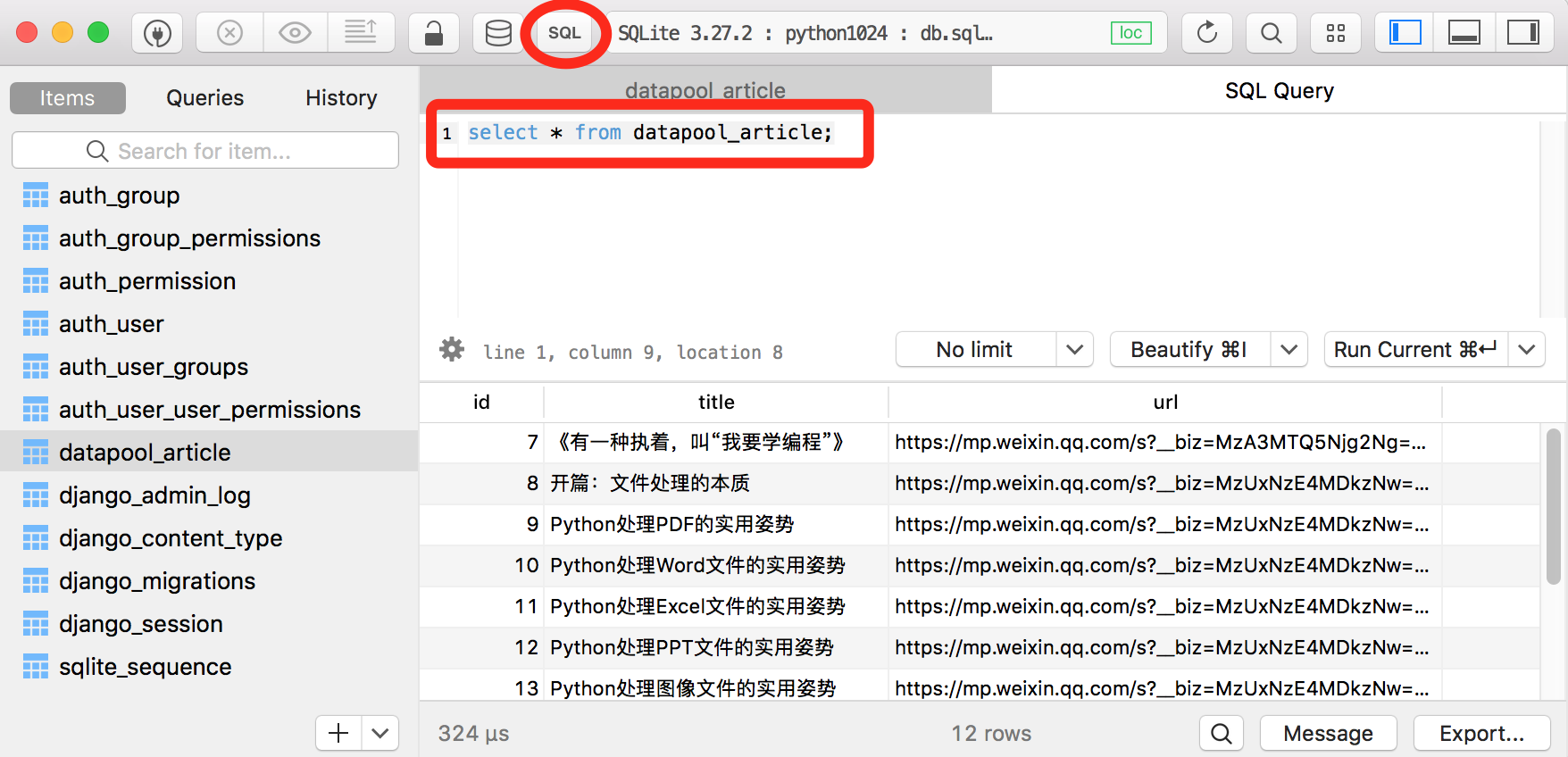
它也支持通过SQL查询数据:
最后补充下,软件本身是付费的,但也有提供免费试用。
试用版本有一些限制,比如只能在里面开2个窗口、查询条件不超过2个,但用于预览查询数据足够。
总结
本文介绍了用sqlite3和djangoORM模块存取数据的方法。
通过django的ORM模块,我们可以借助Python接口存取数据,减少使用SQL的门槛。
同时,我们可以通过django的命令行框架,编写属于自己的命令行工具集。
django模块的最大好处,就是开箱即用,通过简单配置和少许代码就可以创建简单应用。
至此,我们已具备爬取数据、存取数据的能力,下一章开始介绍用Python分析数据。
扫码加入学习群,前100名免费。


















 2992
2992

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









